

Постановка задачи
Используя критерий Колмогорова, проверить, насколько справедливо предположение, что выборка интервалов времени безотказной работы изделий (таблица 2), полученная при их эксплуатации, случайна и взята из непрерывного распределения: Q(t) = 1 - exp(-tб.р./T0)
Сведения из теории
Общая характеристика метода. Статистической гипотезой называют всякое высказывание о генеральной совокупности, проводимое по выборке из этой совокупности. Статистические гипотезы классифицируют на гипотезы о законах распределения и гипотезы о параметрах законов распределения.
В общем виде задача проверки статистической гипотезы формулируется следующим образом. Имеем статистические данные в виде одной или нескольких выборок. Высказывается предположение о параметрах или законе распределения выборок. Это основное предположение называют нулевой гипотезой и обозначают HО. Альтернативой исходной гипотезе HО могут быть одна или две гипотезы H1 и H2. Таким образом, задача проверки гипотезы HО для выборки, состоящей из n наблюдений Х1, ... , Хn случайной величины X, заключается в выработке определенных правил, по которым решаем принять гипотезу HО или H1 (H2). Все возможное множество выборок объема n можно разделить на два непересекающихся подмножества Sn1 и Sn2. Если наша выборка (или ее характеристики, параметры) попадают в область Sn1, то принимается исходная гипотеза HО, если же в область Sn2, то нулевая гипотеза HО отвергается и принимается гипотеза H1 (H2). Подмножество Sn1 называют областью допустимых значений случайной величины, а Sn2 - критической областью. Выбор одной из областей однозначно определяет и другую область. Возникает необходимость формирования критериев, принципов или правил для построения критической области Sn2 или области допустимых значений Sn1.
При выборе критической области и принятии или отклонении гипотезы HО по случайной выборке принятое решение соответствует истине с некоторой доверительной вероятностью.
При
выборе критической области, приняв или
отклонив нулевую гипотезу
HО,
можно допустить ошибки двух видов.
Ошибка первого
рода с
вероятностью α
состоит в том, что отвергается верная
гипотеза HО
и принимается конкурирующая гипотеза
H1
(H2),
что символически можно записать в
следующем виде: α
= P{(x1,
..., xn)![]() Snn2
H0},
то есть
вероятность принятия гипотезы H1
(H2),
когда на самом деле имеет место гипотеза
HО.
Snn2
H0},
то есть
вероятность принятия гипотезы H1
(H2),
когда на самом деле имеет место гипотеза
HО.
Ошибка второго рода с вероятностью β состоит в том, что принимается неверная гипотеза HО, в то время как в действительности верна конкурирующая гипотеза H1 (H2), что символически записывается в виде:
β = P{(x1, ..., xn) Snn1 H1}, то есть вероятность принятия гипотезы HО, когда на самом деле имеет место гипотеза H1(H2).
В технической литературе вероятность α иногда встречается под названием «риск» поставщика, а вероятность β- под названием «риск» заказчика.
Существуют различного рода статистические гипотезы: о сравнении двух вероятностей отказа; об однородности двух выборок; о законе распределения случайной величины.
Вопрос о сравнении двух вероятностей отказа постоянно возникает при сравнении надежности однотипного оборудования, работающего одновременно в различных условиях, или одного и того же оборудования, но за разные периоды эксплуатации. Часто требуется сравнить надежность оборудования, проработавшего одинаковое время.
Задача проверки однородности выборок может возникать уже на начальной стадии исследования надежности изделия с целью их объединения и получения более весомой выборки. Если гипотеза об однородности выборок подтверждается, следовательно, обе выборки извлечены из одной и той же генеральной совокупности, а расхождение статистических данных является случайным и несущественным. Для проверки исходной гипотезы предлагается использовать критерий Смирнова, согласно которому величина наибольшего абсолютного расхождения Dm,n сравнивается с критическим значением этой статистики Dm,n (α) при заданном уровне значимости α.
Если окажется, что Dm,n < Dm,n (α), то гипотеза об однородности двух выборок не бракуется, если же Dm,n ≥ Dm,n (α), то основную гипотезу НО отвергают в пользу альтернативной гипотезы Н1.
Определение законов распределения случайных величин по эксплуатационной информации. Известно, что для полной характеристики любой случайной величины необходимо знать ее закон распределения в виде функции распределения (в нашем случае вероятности отказа) или плотности вероятности. Определение закона распределения отказов (восстановлений) по опытным данным, т.е. по выборке, осуществляется в 3 этапа:
выбор предполагаемого вида закона распределения;
проверка согласия выборки с принятым законом распределения, т.е. согласованности опытного распределения с теоретическим;
оценка параметров выбранного закона распределения.
Выбор вида закона распределения. Подбор для данного статистического ряда теоретической кривой распределения и нахождения ее параметров в статистике называют выравниванием (сглаживанием) статистических рядов. Основой выравнивания является выбор вида теоретической кривой распределения. При принятии гипотезы о виде теоретического распределения главным является понимание характера причин утраты работоспособности данным видом оборудования. Другими словами, вид теоретического распределения, как правило, должен выбираться заранее из соображений, связанных с существом рассматриваемых явлений. Экспериментальными данными подтверждается хорошее соответствие процессов, приводящих к внезапным отказам, экспоненциальному закону распределения, процессов чистого износа — нормальному закону. Процессы усталостного разрушения, а также процессы, представляющие собой совокупность видов разрушения (усталостного, износа внезапных изменений свойств объекта и др.), могут быть описаны распределением Вейбулла. При выборе теоретического закона распределения необходимо помнить, что для выявления статистически значимых различий законов распределения требуется весьма большой объем информации, особенно для использования двух и более параметрических законов. Ориентировочно закон распределения можно выбрать по виду аппроксимации статистического ряда.
Проверка согласия опытного распределения с теоретическим. Вопрос о согласовании опытного и теоретического распределений является одним из важнейших вопросов проверки статистических гипотез. Между опытным и теоретическим распределениями всегда существуют расхождения. Возникает вопрос: объясняются ли эти расхождения только случайными обстоятельствами, связанными с ограниченностью выборки n, или они существенны и связаны с тем, что подобранная теоретическая кривая плохо выравнивает данное опытное распределение. На практике для ответа на такой вопрос используются так называемые «критерии согласия»: критерий Колмогорова, критерий χ2 критерий ω2 и другие. Критерий Колмогорова может применяться для проверки любого теоретического распределения, однако при этом необходимо, чтобы гипотетическое распределение F(x) было известно заранее.
Алгоритм использования критерия согласия Колмогорова.
Как указывалось ранее, наиболее полной характеристикой надежности элементов является функция распределения времени безотказной работы (функция ненадежности) Q(t). При этом мы не затрагивали вопроса о том, откуда берется, как определяется этот закон. Ответ на этот вопрос один - из статистики отказов изделия, полученной по данным эксплуатации или эксперимента.
Исходным пунктом статистического исследования надежности любого электрооборудования является фиксация времени между отказами. По данным этой статистики составляется статистический (вариационный) ряд: t1< t2 < ... < tk < ... < tn, где n наблюдений случайной величины T (время наступления к-го отказа с момента начала наблюдений).
Имея статистический ряд, нетрудно построить статистическую функцию распределения случайной величины T, определяемую следующими неравенствами:
0 при t < t1;
Q*(t) = { k/n при tk < t < tk+1, 1 , k , n-1;
1 при t > tn, 0
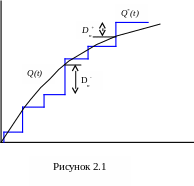
Статистическая вероятность отказа представляет собой прерывистую ступенчатую функцию, скачки которой соответствуют наблюденным значениям случайной величины T и по величине равны частотам этих значений (рис.2.1). Если каждое отдельное значение случайной величины T было наблюдено только один раз, то скачок статистической функции Q*(t) в каждом наблюденном значении равен 1/n, где n - число наблюдений. При увеличении n статистическая функция Q*(t) приближается (сходится по вероятности) к подлинной функции Q(t).
Примечание: Для невосстанавливаемых изделий под T следует понимать случайное время до первого отказа, а для восстанавливаемых - случайное время между отказами.
На практике мы почти никогда не имеем дела с большим числом наблюдений и вынуждены считаться с тем, что статистической функции Q*(t) свойственны в большей или меньшей мере черты случайности.
Поэтому приходится решать вопрос о том, как подобрать для данного статистического ряда теоретическую кривую распределения, выражающую существенные черты данного статистического ряда, но не случайности, связанные с недостаточным объемом экспериментальных данных.
Q(t)
1.0--------------------------------------------
0.9---------------------------------------------
0.8---------------------------------------------
0.7---------------------------------------------
0.6---------------------------------------------
0.5--------------------------------------------
0.4---------------------------------------------
0.3----------------------------------------------
0.2---------------------------------------------
0.1--------------------------------------------- t*10-3
0 1 2 3 4 5 6 7 8 9 10 11 час
Задача о наилучшем выравнивании (сглаживании) статистических рядов есть задача в значительной мере неопределенная, и решение ее зависит от того, что условиться считать "наилучшим". При этом вопрос о том, в каком именно классе функций следует искать наилучшее приближение, решается уже не из математических соображений, а из соображений, связанных с физикой решаемой задачи.
Как бы хорошо ни была подобрана теоретическая кривая Q(t), между нею и статистическим распределением Q*(t) неизбежны некоторые расхождения. Возникает вопрос: объясняются ли эти расхождения только случайными обстоятельствами, связанными с ограниченным числом наблюдений n, или они являются существенными и связаны с тем, что подобранная кривая не адекватна данному статистическому распределению. Для ответа на такой вопрос служат так называемые "критерии согласия".
В качестве примера рассмотрим решение поставленной задачи с помощью критерия Dn Колмогорова.
В качестве меры расхождения между теоретическим и статистическим распределениями А.Н.Колмогоров рассматривает максимальное значение модуля разности между статистической функцией распределения и соответствующей теоретической функцией распределения
Dn = max |Q*(t) - Q(t)|.
Критерий Колмогорова намного проще других критериев, поэтому его весьма часто применяют на практике. При этом следует помнить, что этот критерий основан на индивидуальных значениях непрерывной случайной величины X в выборке объема n, а не группированных, поэтому при построении эмпирической функции распределения Q*(t) недопустимо объединение статистических данных в разряды.
Если фактически найденное наибольшее расхождение Dn окажется больше или равно критическому значению статистики Dn (α), то, согласно критерию Колмогорова, с уровнем значимости α гипотеза HО{M[Q*(t)=Q(t)} должна быть отвергнута.
Критические значения для наибольшего отклонения эмпирического распределения от теоретического Dn(α) для n = 10…20…100 и
α = 0.01; 0.02; 0.05; 0.10 ; 0.20 приведены в табл. 6.2 [6].
Используется критерий по схеме:
1) по данным статистики составляется вариационный (упорядоченный) статистический ряд.
2) по статистическому ряду строится статистический интегральный закон (в виде ломаной кривой) Q*(t).
3) высказывается гипотеза HО о теоретической функции распределения Q(t) и строится ее график.
4)определяется статистика Dn.
5) по табл.6.2 [6] определяется критическое значение статистики Dn(α).
6) если Dn >= Dn (α), то с уровнем значимости α гипотеза HО должна быть отвергнута.