

Список працюючих жінок
№ п/п |
Прізвище |
Вік |
Сімейний стан |
Оклад |
Кількість дітей |
Для формування полів вихідного рядка введемо для них позначення (відповідно до послідовності полів): i, FI01, VIK, CIM1, OKL1, DIT1. Крім того, позначимо поточний рік — GOD. Побудуємо алгоритм формування та друкування списку (рис. 6.7).
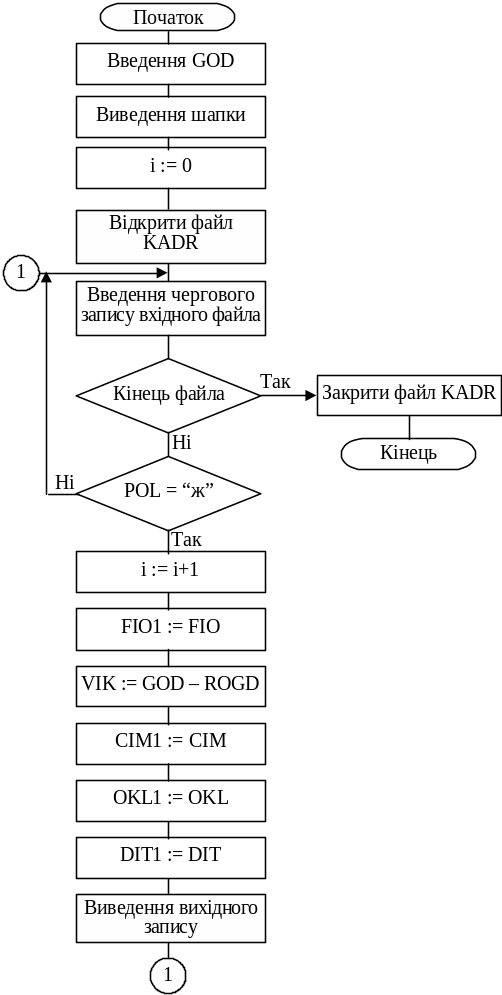
Рис. 6.7. Алгоритм прикладу формування списку за окремими записами (6.4)
6.1.5. Розрахунки підсумків на основі всіх записів (6.5)
Обробка запитів з використанням усіх записів файла зазвичай містить накопичення значень деяких полів для всіх записів. Ясно, що ці поля мають числові значення.
Після вводу всіх записів файла і накопичення необхідних підсумків виконуються операції їх обробки. Результати обробки у певній формі виводяться під шапкою у вигляді одного або декількох рядків.
Отже, необхідно визначити, які підсумкові величини треба знайти у процесі зчитування записів файла, задати їм початкові значення, тобто підготувати до входу в циклічний процес обробки записів файла.
Треба зазначити, що вивід шапки вихідного документа може здійснюватись як до входу в циклічний процес обробки, так і після нього.
Алгоритм обробки запиту з використанням усіх записів файла для розрахунків підсумків у загальному вигляді зображено на рис. 6.8.
Приклад 4. Надати інформацію про середню заробітну плату чоловіків та жінок. Для обробки цього запиту скористаємося файлом KADR, що був створений у першому прикладі.
Проведемо аналіз запиту та побудуємо вихідний документ. Він може бути представлений, наприклад, у такій формі:
Д О В І Д К А
Про середню заробітну плату
-
Працюючі
Середня з/п
Чоловіки Жінки
Щоб обчислити середню зарплату, необхідно встановити кількість чоловіків та жінок (два лічильники — К1 та К2) та їх сумарні заробітні плати (дві суми — S1 та S2).
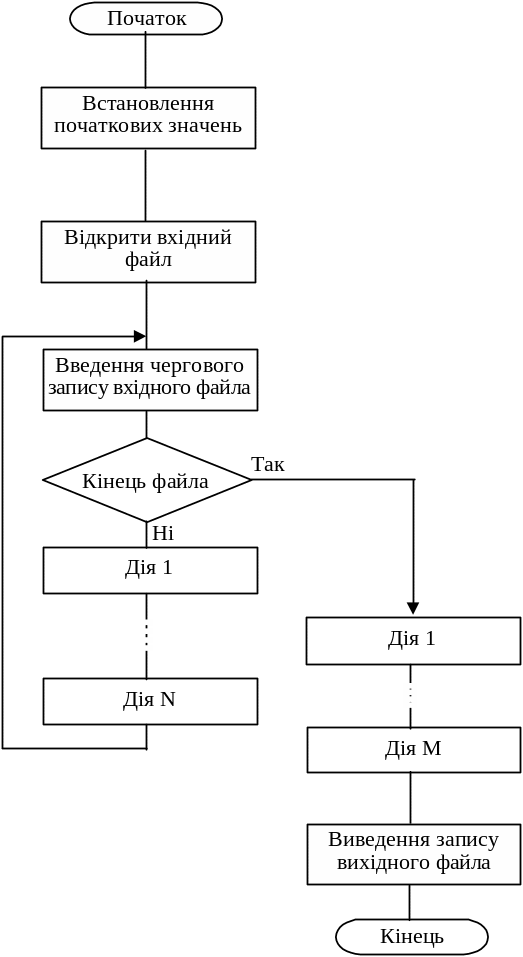
Рис. 6.8. Загальний алгоритм 6.5 обробки запиту з використанням усіх записів файла
Вся потрібна інформація міститься у вхідному файлі. Оскільки значення всіх лічильників накопичуватимуться у процесі послідовного перегляду записів вхідного файла, то їх необхідно обнулити до входу в цикл обробки. Будуємо алгоритм обробки запиту з використанням усіх записів файла (рис. 6.9).
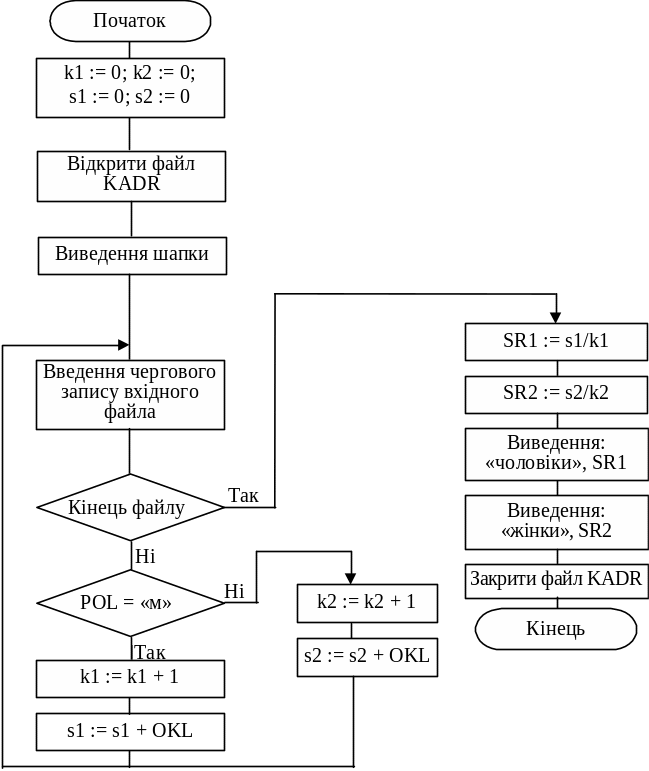
Рис. 6.9. Алгоритм прикладу 4 обробки запиту з використанням усіх записів файла KADR
6.1.6. Розрахунки проміжних підсумків на основі частини записів (6.6)
Записи
файлів за якимись ознаками можуть
впорядковуватись, групуватись,
сортуватись. Ознакою може бути як окреме
значення деякого елемента (поля) запису,
так і його приналежність до деякого
діапазону значень, або змінна, яка не
належить запису, але може бути обчислена
з використанням значень полів запису.
Зауважимо, що будь-які впорядкування
записів файла можуть проводитись за
декількома ознаками одночасно, але
пріоритет цих ознак повинен бути
встановлений з аздалегідь.
Наприклад, якщо це файл співробітників
підприємств, то він може бути впорядкований
за кодами підприємств, потім за внутрішніми
кодами підрозділів, а в підрозділах —
за прізвищами або табельними комерами.
аздалегідь.
Наприклад, якщо це файл співробітників
підприємств, то він може бути впорядкований
за кодами підприємств, потім за внутрішніми
кодами підрозділів, а в підрозділах —
за прізвищами або табельними комерами.
Один і той самий файл можна впорядкувати за різними ознаками, якщо це спрощує алгоритм і скорочує час обробки файла.
Якщо файл упорядковано за декількома ознаками, то можна вважати, що його розбито на стільки груп, та угруповань, скільки різних значень мають комбінації цих ознак. По кожній із таких груп та угруповань можна вести будь-які розрахунки. Наприклад, для попереднього вхідного файла можна вести розрахунки для окремих підрозділів, підприємств або для всіх працівників взагалі й по кожний частині записів визначати певні підсумки для вихідного документа або файла. Приналежність запису до певної групи перевіряється порівнянням значення його ознаки зі значенням ознаки поточної групи записів, яке треба зафіксувати при вході до групи. Загальне правило обробки записів окремими частинами — це окреме введення 1-го запису файла, послідовне фіксування значень усіх кодових ознак та запам’ятовування їх у спеціальних полях для подальшого використання у визначенні груп записів.
Загальний алгоритм групової обробки записів зображено на рис. 6.10 (тут КО — кодова ознака).
Приклад 5. На основі запиту обчислити по цехах кількість працівників у розрізі груп загального стажу роботи: до 5 років, від 5 до 10 років, від 10 до 20 років та понад 20 років. Знайдені показники занести у таблицю, складену за наступною формою:
Р О З П О Д І Л
працівників за загальним стажем робіт
Код підпри- ємства |
Код цеху |
Кількість працівників зі стажем |
|||
до 5 років |
від 5 до 10 років |
від 10 до 20 років |
понад 20 років |
||
Використовуючи створений раніше вхідний файл KADR, проведемо розрахунки. Крім того, необхідно виділити поля для збереження зафіксованого значення коду підприємства (PRED) та коду цеху (ZEX).
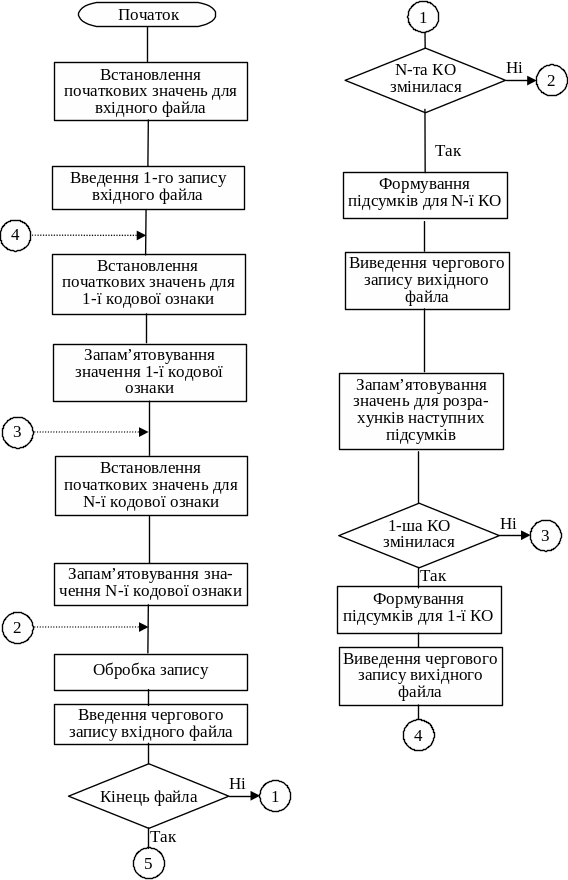
Рис. 6.10. Загальний алгоритм групової обробки записів файла (6.6)
Закінчення рис. 6.10
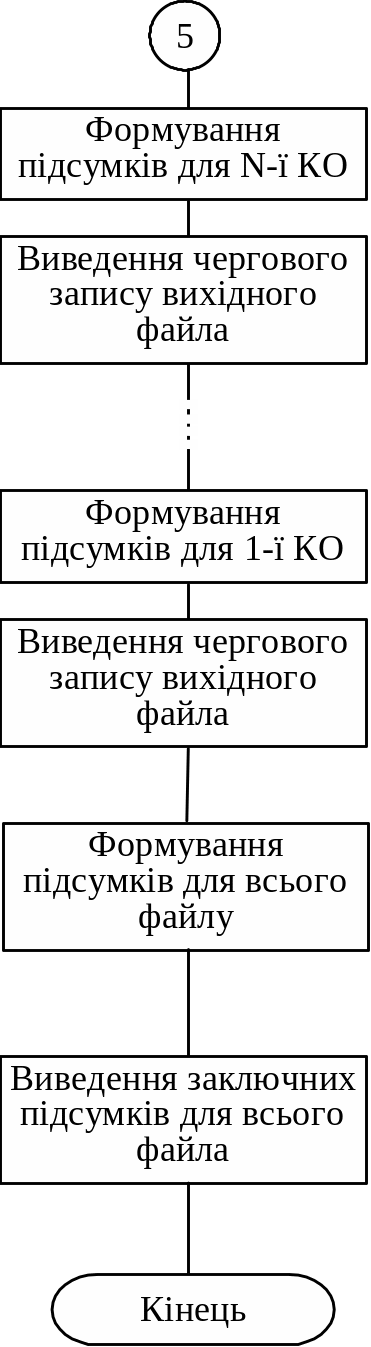
Рис. 6.10. Загальний алгоритм групової обробки записів файла (6.6)
Необхідно зарезервувати по 4 лічильники кількості працівників для цеху (ZEX5, ZEX10, ZEX20, ZEXB), для підприємства (PRED5, PRED10, PRED20, PREDB) та підсумкових значень по усьому файлу. Отже, 12 лічильників, 4 з них обнулюються найчастіше при зміні коду цеху, ще 4 обнулюються тільки при зміні коду підприємства, 4 лічильники підсумкових значень обнулюються до входу в циклічний процес обробки файла.
Побудуємо алгоритм обробки запису, використовуючи загальний алгоритм 6.6 (рис. 6.11):
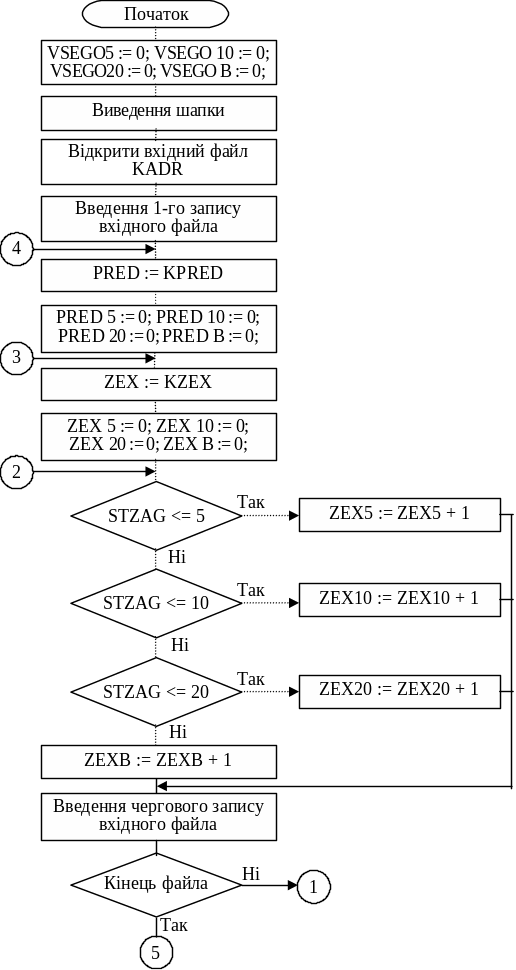
Рис. 6.11. Приклад групової обробки записів файла KADR (6.6)
Закінчення рис. 6.11

Рис. 6.11. Приклад групової обробки записів файла KADR (6.6)