

4.2. Алгоритм распознавания однозначности кодирования
Используя нетривиальные разложения элементарных кодов, опишем алгоритм для схемы кодирования Σ.
1. Для каждого элементарного кода выполним всевозможные нетривиальные разложения.
2. Строим множество М следующим образом. В него включаем пустой символ , а также каждое слово типа β, которое встречается в нетривиальных разложениях элементарных кодов как в роли префикса, так и в роли окончания. В разных ролях это слово не обязательно используется в разложении одного и того же элементарного кода.
3. Каждому слову из М сопоставляем вершину графа. Пусть слова , содержатся в М. Выделим среди нетривиальных разложений элементарных кодов схемы Σ разложения вида … . Для каждого из них проведем дугу из в , пометив ее элементарными кодами … . Полученный граф обозначим (Σ).
4. Анализируем граф (Σ), отыскивая в нем ориентированный цикл, содержащий вершину . Если цикл существует, то кодирование не однозначно, иначе кодирование однозначно.
Теорема 4.3. Алфавитное кодирование со схемой кодирования Σ не обладает свойством однозначности, если и только если граф (Σ) содержит ориентированный цикл, проходящий через вершину .
Доказательство приведено в [1].
Для построенных ранее нетривиальных разложений имеем множество М = {, , , }. С этим множеством связаны разложения (рис. 4.1):
= ( )( ),
 =
(
)(
)
=
(
),
=
(
)(
)
=
(
),
 =
(
)(
)(
)
= (
)
.
=
(
)(
)(
)
= (
)
.
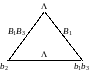
В графе существует ориентированный цикл, проходящий через вершину , то есть кодирование не однозначно. Действительно, слово В = = допускает две расшифровки:
B = ( )( ) = ,
B = ( )( )( )( ) = .
4.3. Свойства однозначных кодов
Дана схема кодирования Σ:
,
…
.
Пусть
q
– число символов алфавита В
(значность алфавита В),
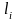 =
l(
).
=
l(
).
Теорема 4.4 (неравенство МакМилана). Если кодирование со схемой Σ обладает свойством однозначности, то выполняется соотношение
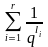
1.
1.
Доказательство. Рассмотрим всевозможные слова в алфавите А, имеющие длину n. Представим их выражением:
(
+…+
)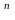 . (1)
. (1)
Произвольное
слово длины n
в алфавите А
можно представить в виде
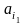 ,
,
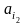 ,…,
,…,
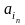 .
Здесь
принадлежит первой из n
скобок,
– второй и т.д. Имея это в виду, запишем
соотношение
.
Здесь
принадлежит первой из n
скобок,
– второй и т.д. Имея это в виду, запишем
соотношение
(
+…+
)
=
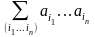 . (2)
. (2)
Сопоставим рассматриваемым словам коды в алфавите В. Коды получаются заменой символов ,…, элементарными кодами ,…, соответственно. Имеем
(
+…+
)
=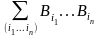 . (3)
. (3)
В
силу однозначности кодирования, если
( ,…,
,…,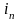 )
(
)
(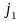 ,…,
,…,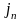 ),
то
),
то
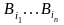
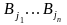 ,
то есть разным словам в алфавите А
соответствуют разные слова в алфавите
В.
,
то есть разным словам в алфавите А
соответствуют разные слова в алфавите
В.
Соотношению (3) соответствует тождество
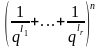 =
=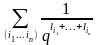 . (4)
. (4)
Слагаемым
правой части, имеющим одинаковые
знаменатели, сопоставляются слова
одинаковой длины t,
t
=
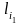 +…+
+…+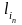 .
Пусть ν(n,
t)
– число слов
из (3), имеющих длину t.
Пусть l
=
.
Пусть ν(n,
t)
– число слов
из (3), имеющих длину t.
Пусть l
=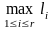 .
Тогда
.
Тогда
=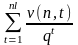 . (5)
. (5)
Из однозначности кодирования следует
ν(n,
t)
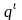 . (6)
. (6)
Действительно, есть число всевозможных слов длины t в алфавите В. Поскольку в (3) все рассматриваемые коды слов длины n в алфавите А различны, то различны и их подмножества – коды одной и той же длины. Следовательно, соотношение (6) выполняется.
Далее имеем
nl.
Тогда получим
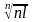 .
.
Это неравенство справедливо для любого n, так как его левая часть не зависит от n. Перейдя к пределу при n, получим неравенство МакМилана
1.
Ч.Т.Д.
Теорема 4.5. Если алфавитное кодирование, заданное схемой Σ, однозначно, Σ:
,
…
,
то
существует алфавитное кодирование,
задаваемое схемой
 :
:
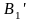 ,
,
…
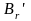 ,
,
обладающее свойством префикса, причем для элементарных кодов ,…, выполняются равенства
l( ) = l( ),
…
l( ) = l( ).
Доказательство.
Пусть
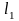 …
…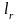 .
Воспользуемся неравенством МакМилана
.
Воспользуемся неравенством МакМилана
1.
Разобьем
числа
,…,
,
представляющие длины элементарных
кодов, на классы равной длины. Пусть μ
– число классов 1
μ
r;
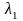 ,…,
,…,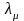 – длины элементов классов;
,…,
– длины элементов классов;
,…,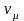 – мощности классов. Перепишем неравенство
МакМилана с учетом введенных обозначений:
– мощности классов. Перепишем неравенство
МакМилана с учетом введенных обозначений:
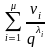
1.
1.
Это неравенство порождает серию вспомогательных неравенств:
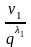
1
или
1
или
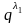 ,
,
+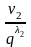
1 или
1 или
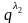 –
–
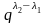 ,
,
…
+
+…+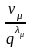
1 или
1 или
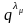 –
–
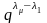 –
–
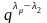 –…–
–…–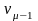
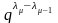 .
.
Рассмотрим
слова в алфавите B,
имеющие длину
.
Так как
,
то можно выбрать из них
слов длины
.
Обозначим выбранные слова через
,…,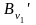 .
Они представляют элементарные коды
схемы кодирования
.
.
Они представляют элементарные коды
схемы кодирования
.
Исключим
из рассмотрения в дальнейшем слова,
начинающиеся с
,…,
.
Выберем слова в алфавите В,
имеющие длину
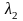 и не начинающиеся со слов
,…,
.
Число таких слов в алфавите В
определяется выражением
и не начинающиеся со слов
,…,
.
Число таких слов в алфавите В
определяется выражением
– .
Так
как
–
,
то имеется возможность выбрать
нужных нам слов. Обозначим их через
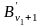 ,…,
,…,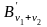 .
Они также представляют элементарные
коды схемы кодирования
.
.
Они также представляют элементарные
коды схемы кодирования
.
Исключим в дальнейшем слова, начинающиеся с уже включенных в схему элементарных кодов. В конце концов мы получим все элементарные коды ,…, схемы . Из построения кодов следует:
l( ) = l( ),
…
l( ) = l( ).
Ч.Т.Д.