

1.2.2.4.Атомарность значений атрибутов, первая нормальная форма отношения
Значения всех атрибутов являются атомарными (вернее, скалярными). Это следует из определения домена как потенциального множества значений скалярного типа данных, т. е. среди значений домена не могут содержаться значения с видимой структурой, в том числе множества значений (отношения). Заметим, что это не противоречит тому, что говорилось в разделе «Основные понятия реляционных баз данных» о потенциальной возможности использования при спецификации атрибутов типов данных, определяемых пользователями. Например, можно было бы добавить в схему отношения СЛУЖАЩИЕ атрибут СЛУ_ФОТО, определенный на домене (или типе данных) ФОТОГРАФИИ. Главное в атомарности значений атрибутов состоит в том, что реляционная СУБД не должна обеспечивать пользователям явной видимости внутренней структуры значения. Со всеми значениями можно обращаться только с помощью операций, определенных в соответствующем типе данных.
Принято говорить, что в реляционных базах данных допускаются только нормализованные отношения, или отношения, представленные в первой нормальной форме.
Пример ненормализованного отношения показан на Рис. 4. Можно сказать, что здесь мы имеем бинарное отношение, в котором значениями атрибута ОТДЕЛЫ являются отношения. Заметим, что исходное отношение СЛУЖАЩИЕ является нормализованным вариантом отношения ОТДЕЛЫ-СЛУЖАЩИЕ. Нормализованный вариант показан на Рис. 5

Рис. 4 Ненормализованное отношение ОТДЕЛЫ-СЛУЖАЩИЕ
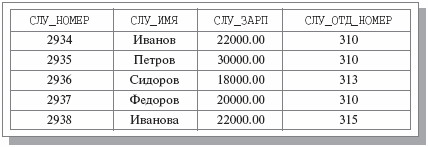
Рис. 5 Отношение СЛУЖАЩИЕ: нормализованный вариант отношения ОТДЕЛЫ-СЛУЖАЩИЕ
Нормализованные отношения составляют основу классического реляционного подхода к организации баз данных. Они обладают некоторыми ограничениями6) (не всякую информацию удобно представлять в виде плоских таблиц), но существенно упрощают манипулирование данными. Рассмотрим, например, два идентичных оператора занесения кортежа:
зачислить служащего Кузнецова (пропуск номер 3000, зарплата 25000.00) в отдел номер 320;
зачислить служащего Кузнецова (пропуск номер 3000, зарплата 25000.00) в отдел номер 310.
Если информация о сотрудниках представлена в виде отношения СЛУЖАЩИЕ, оба оператора будут выполняться одинаково (вставить кортеж в отношение СЛУЖАЩИЕ). Если же работать с ненормализованным отношением ОТДЕЛЫ-СЛУЖАЩИЕ, то первый оператор приведет к простой вставке кортежа, а второй – к добавлению кортежа в значение-отношение атрибута ОТДЕЛ кортежа с первичным ключом 310.
При работе с ненормализованными отношениями аналогичные затруднения возникают при выполнении операций удаления и модификации кортежей.
1.2.3.Реляционная модель данных
Когда в предыдущих разделах мы говорили об основных понятиях реляционных баз данных, мы не опирались на какую-либо конкретную реализацию. Эти рассуждения в равной степени относятся к любой системе, при построении которой использовался реляционный подход.
Другими словами, мы использовали понятия так называемой реляционной модели данных. Модель данных (в контексте области баз данных) описывает некий набор родовых понятий и признаков, которыми должны обладать все конкретные СУБД и управляемые ими базы данных, если они основываются на этой модели. Наличие модели данных позволяет сравнивать конкретные реализации, используя один общий язык.
Хотя понятие модели данных является общим, и можно говорить об иерархической, сетевой, семантической и других моделях данных, нужно отметить, что в области баз данных это понятие было введено Эдгаром Коддом применительно к реляционным системам и наиболее эффективно используется именно в данном контексте. Попытки прямолинейного применения аналогичных моделей к дореляционным организациям показывают, что реляционная модель слишком «велика», а для постреляционных организаций она оказывается «мала».