

Архитектура odbc
Архитектура ODBC представлена четырьмя компонентами Рис. 75:
Приложение-клиент, выполняющее вызов функций ODBC.
Менеджер драйверов, загружающий и освобождающий ODBC-драйверы, которые требуются для приложений-клиентов. Менеджер драйверов обрабатывает вызовы ODBC-функций или передает их драйверу.
ODBC-драйвер, обрабатывающий вызовы SQL-функций, передавая SQL-серверу выполняемый SQL-оператор, а приложению-клиенту - результат выполнения вызванной функции.
Источник данных, определяемый как конкретная локальная или удаленная база данных.
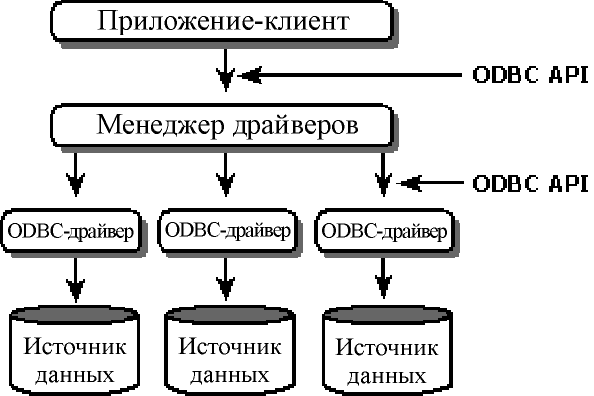
Рис. 75. Архитектура ODBC
Основное назначение менеджера драйверов - загрузка драйвера, соответствующего подключаемому источнику данных, и инкапсуляция взаимодействия с различными типами источников данных посредством применения различных ODBC-драйверов.
ODBC-драйверы, принимая вызовы функций, взаимодействуют с приложением-клиентом, выполняя следующие задачи:
управление коммуникационными протоколами между приложением-клиентом и источником данных;
управление запросами к СУБД;
выполнение передачи данных от приложения-клиента в СУБД и из базы данных в приложение-клиент;
возвращение приложению-клиенту стандартной информации о выполненном вызове ODBC-функции в виде кода возврата;
поддерживает работу с курсорами и управляет транзакциями.
Приложение-клиент одновременно может устанавливать соединения с несколькими различными источниками данных, используя разные ODBC-драйверы, а также несколько соединений с одним и тем же источником данных, используя один и тот же ODBC-драйвер.
Функции odbc api
Все функции ODBC API условно можно разделить на четыре группы:
основные функции ODBC, обеспечивающие взаимодействие с источником данных;
функции установки (setup DLL);
функции инсталляции (installer DLL) ODBC и источников данных;
функции преобразования данных (translation DLL).
Объявления всех функций и используемых ими типов данных содержатся в заголовочных файлах. Группа основных функций ODBC API разбита на три уровня:
функции ядра ODBC;
функции 1 уровня;
функции 2 уровня.
Интерфейс ODBC API реализован как набор расслоенных DLL-функций для Windows. Динамическая библиотека ODBC.DLL – это основная библиотека управления драйверами ODBC, которая содержит функции вызовов специализированных драйверов для разных поддерживаемых системой баз данных. Каждый драйвер совместим со своим уровнем и относится к одной из двух категорий: одноуровневые или многоуровневые драйверы.
Одноуровневые драйверы предназначены для использования при работе с теми источниками данных, которые не могут быть прямо обработаны с использованием ANSI SQL. Обычно это локальные базы данных на персональных компьютерах, такие как dBase, Paradox, FoxPro и Excel. Драйверы, соответствующие этим базам данных, производят компиляцию ANSI SQL в наборы инструкций более низкого уровня, которые непосредственно обрабатывают составляющие базу данных файлы.
Многоуровневые драйверы используют сервер СУБД для обработки SQL-предложений и предназначены для работы в среде клиент-сервер. Помимо обработки ANSI SQL, они также могут поддерживать и собственные конструкции конкретной РСУБД, поскольку ODBC может без трансляции передавать SQL-операторы источникам данных (механизм "passthrough"). Драйверы ODBC для баз данных, поддерживаемым в технологии клиент-сервер реализованы для практически для всех промышленных серверов БД.
Существует 4 важных этапа (шага) процедуры запроса данных через ODBC API.
Шаг 1 - установление соединения. Первый шаг состоит в размещении указателей (handle) среды ODBC, которые выделяют оперативную память под ODBC драйверы и библиотеки. Затем происходит выделение памяти для указателей соединения, и соединение устанавливается.
Шаг 2 - выполнение оператора SQL. Выделяется указатель оператора, локальные переменные связываются со столбцами в SQL-выражении (это необязательное действие), и выражение представляется главному ODBC-драйверу для обработки.
Шаг 3 - извлечение данных. Перед извлечением данных возвращается информация о результирующем наборе, в частности, число столбцов в наборе. Исходя из этого числа, результирующий набор помещается в буфер записей, выполняется цикл его просмотра и содержимое каждого столбца помещается в соответствующую локальную переменную. Этот шаг необязателен, если используется связывание столбцов с локальными переменными.
Шаг 4 - освобождение ресурсов. После того, как данные получены, ресурсы освобождаются путем вызова функций освобождения указателей оператора, соединения и среды. Указатели оператора и соединения могут быть использованы в процессе обработки.
Технология ODBC разрабатывалась как общий, независимый от источников данных, способ доступа к данным. Применение технологии должно было также обеспечить переносимость приложений в среду различных баз данных без потребности переработки самих приложений. В этом смысле технология ODBC уже стала промышленным стандартом, ее поддерживают практически все производители СУБД и средств разработки.
Однако универсальность стоит дорого. Если при разработке приложений одним из основных критериев является переносимость на различные СУБД, то использование ODBC является оправданным. Для увеличения производительности и эффективности приложения активно применяют специфические для данной СУБД расширения языка SQL, используют хранимые на сервере процедуры и функции. В этом случае теряется роль ODBC как общего метода доступа к данным. Тем более, что для разных СУБД драйверы ODBC поддерживают разные уровни совместимости. Поэтому многие производители средств разработки, помимо поддержки ODBC, поставляют "прямые" драйверы к основным СУБД.