

2.3.2.Декомпозиция без потерь и функциональные зависимости
Наиболее важные на практике нормальные формы отношений основываются на фундаментальном в теории реляционных баз данных понятии функциональной зависимости. Для дальнейшего изложения нам потребуются несколько определений. (Заметим, что везде ниже под термином "атрибут X (Y, Z, ...)", вообще говоря, понимается некоторое подмножество атрибутов отношения, или "составной" атрибут.)
Определение: Функциональная зависимость
В отношении r
атрибут Y
функционально зависит от атрибута X
(X
и Y
могут быть составными) в том и только в
том случае, если каждому значению X
соответствует в точности одно значение
Y:
r.X![]() r.Y.
r.Y.
Определение: Минимальная (полная) функциональная зависимость
Функциональная зависимость r.X r.Y называется минимальной (или полной), если атрибут Y не зависит функционально от любого точного подмножества X.
Определение: Транзитивная функциональная зависимость
Функциональная зависимость r.X r.Y называется транзитивной, если существует такой атрибут Z, что имеются функциональные зависимости r.X r.Z и r.Z r.Y и отсутствует функциональная зависимость r.Z r.X. (При отсутствии последнего требования мы имели бы "неинтересные" транзитивные зависимости в любом отношении, обладающем несколькими ключами.)
Определение: Неключевой атрибут
Неключевым атрибутом называется любой атрибут отношения, не входящий в состав ключа (в частности, первичного).
Определение: Взаимно независимые атрибуты
Два или более атрибута взаимно независимы, если ни один из этих атрибутов не является функционально зависимым от других.
Дальнейшие понятия и определения (в том числе определение многозначной зависимости и зависимости соединения) будут вводиться по ходу изложения в следующем подразделе.
Как уже отмечалось ранее, в данном разделе рассматривается подход к проектированию реляционных баз данных на основе нормализации, т. е. декомпозиции (разбиения путем проецирования) отношения, находящегося в предыдущей нормальной форме, на два или более отношений, удовлетворяющих требованиям следующей нормальной формы.
Считаются правильными такие декомпозиции отношения, которые обратимы, т. е. имеется возможность собрать исходное отношение из декомпозированных отношений без потери информации. Такие декомпозиции называются декомпозициями без потерь.
Корректные и некорректные декомпозиции отношений. Теорема Хеза
На Рис. 6. приведены две возможные декомпозиции отношения СЛУЖАЩИЕ_ПРОЕКТЫ
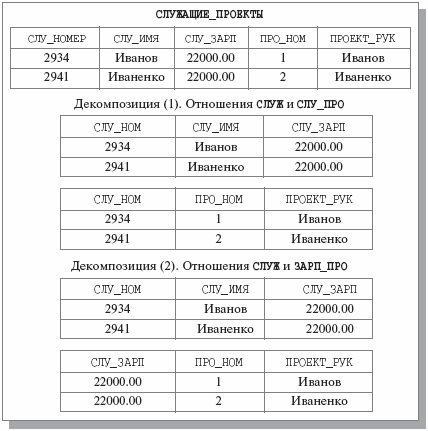
Рис. 6. Две возможные декомпозиции отношения СЛУЖАЩИЕ_ПРОЕКТЫ
Анализ Рис. 6. показывает, что в случае декомпозиции (1) мы не потеряли информацию о служащих – про каждого из них можно узнать имя, размер зарплаты, номер выполняемого проекта и имя руководителя проекта. Вторая декомпозиция не дает возможности получить данные о проекте служащего, поскольку Иванов и Иваненко получают одинаковую зарплату, следовательно, эта декомпозиция приводит к потере информации. Что же привело к тому, что одна декомпозиция является декомпозицией без потерь, а вторая – нет?
Заметим, что при проведении декомпозиции мы использовали операцию взятия проекции. Каждое из отношений СЛУЖ, СЛУ_ПРО и ЗАРП_ПРО является проекцией исходного отношения СЛУЖАЩИЕ_ПРОЕКТЫ. В случае декомпозиции (1) отсутствие потери информации означает, что в результате естественного соединения отношений СЛУЖ и СЛУ_ПРО мы гарантированно получим отношение, заголовок и тело которого совпадают с заголовком и телом отношения СЛУЖАЩИЕ_ПРОЕКТЫ. Следует отметить, что это произойдет для любых допустимых (и согласованных) значений переменных отношений СЛУЖАЩИЕ_ПРОЕКТЫ, СЛУЖ и СЛУ_ПРО, поскольку у всех этих переменных атрибут СЛУ_НОМ является возможным ключом. Однако если выполнить естественное соединение отношений СЛУ и ЗАРП_ПРО, то будет получено отношение, показанное на Рис. 7.
Схема этого отношения, естественно (поскольку соединение – естественное), совпадает со схемой отношения СЛУЖАЩИЕ_ПРОЕКТЫ, но в теле появились лишние кортежи, наличие которых и приводит к утрате исходной информации. Интуитивно понятно, что это происходит потому, что в отношении ЗАРП_ПРО отсутствуют функциональные зависимости СЛУ_ЗАРП ПРО_НОМ и СЛУ_ЗАРП ПРОЕКТ_РУК, но точнее причину потери информации в данном случае мы объясним несколько позже.
Корректность же декомпозиции 1 следует из теоремы Хеза: