

Диаграммы потоков данных (dfd)
Такая диаграмма состоит из трех типов узлов: узлов обработки данных, узлов хранения данных и внешних узлов, представляющих внешние, по отношению к используемой диаграмме, источники или потребители данных. Дуги в диаграмме соответствуют потокам данных, передаваемых от узла к узлу. Они помечены именами соответствующих данных. Описание процесса, функции или системы обработки данных, соответствующих узлу диаграммы, может быть представлено диаграммой следующего уровня детализации, если процесс достаточно сложен.
Для изображения диаграмм потоков данных традиционно используют два вида нотаций: нотации Иордана и Гейна-Сарсона (табл. 4).
Таблица 4
Понятие |
Описание |
Нотация Йордана |
Нотация Гейна-Сарсона |
Внешняя сущность |
Внешний по отношению к системе объект, обменивающийся с нею потоками данных |
|
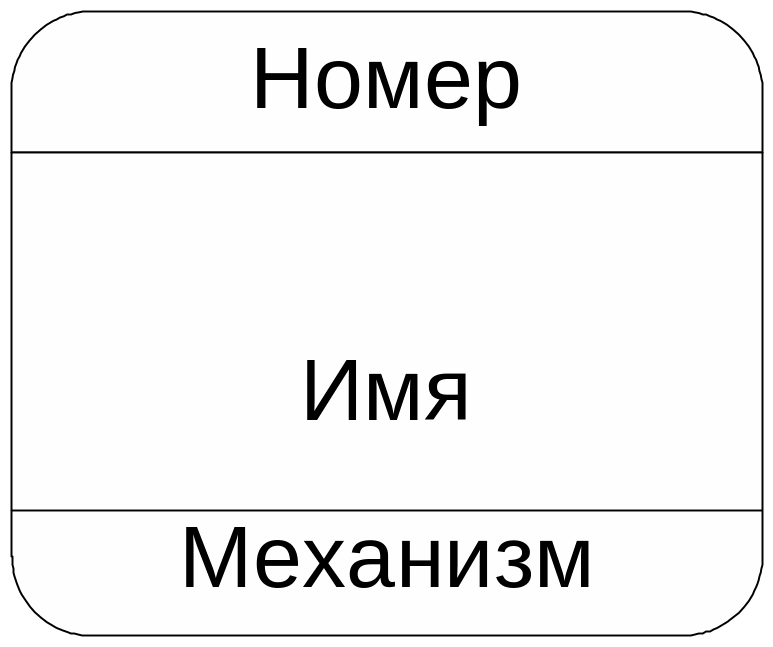
Номер
Имя |
Функция |
Действие, выполняемое моделируемой системой |
|
|
Поток данных |
Объект, над которым выполняется действие. Может быть информационным (логическим) или управляющим. (Управляющие потоки обозначаются пунктирной линией со стрелкой). |
|
|
Хранилище данных |
Структура для хранения информационных объектов |
|
|



Первым шагом при построении иерархии диаграмм потоков данных является построение контекстных диаграмм, показывающих как система будет взаимодействовать с пользователями и другими внешними системами. При проектировании простых систем достаточно одной контекстной диаграммы, имеющей звездную топологию, в центре которой располагается основной процесс, соединенный с источниками и приемниками информации.
Для сложных систем строится иерархия контекстных диаграмм, которая определяет взаимодействие основных функциональных подсистем проектируемой системы как между собой, так и с внешними входными и выходными потоками данных и внешними объектами. При этом контекстная диаграмма верхнего уровня содержит набор подсистем, соединенных потоками данных. Контекстные диаграммы следующего уровня детализируют содержимое и структуру подсистем.
После построения контекстных диаграмм полученную модель следует проверить на полноту исходных данных и отсутствие информационных связей с другими объектами.
Для каждой подсистемы, присутствующей на контекстных диаграммах, выполняется ее детализация при помощи диаграмм потоков данных, при этом необходимо соблюдать следующие правила:
правило балансировки – означает, что при детализации подсистемы можно использовать только те компоненты (подсистемы, процессы, внешние сущности, накопители данных), с которыми она имеет информационную связь на родительской диаграмме;
правило нумерации – означает, что при детализации подсистем должна поддерживаться их иерархическая нумерация. Например, подсистемы, детализирующие подсистему с номером 2, получают номера 2.1, 2.2, 2.3 и т.д.
При построении иерархии диаграмм потоков данных переходить к детализации процессов следует только после определения структур данных, которые описывают содержание всех потоков и накопителей данных. Структуры данных могут содержать альтернативы, условные вхождения и итерации. Условное вхождение означает, что соответствующие компоненты могут отсутствовать в структуре. Альтернатива означает, что в структуру может входить один из перечисленных элементов. Итерация означает, что компонент может повторяться в структуре некоторое указанное число раз. Для каждого элемента данных может указываться его тип (непрерывный или дискретный). Для непрерывных данных может указываться единица измерения (кг, см и т.п.), диапазон значений, точность представления и форма физического кодирования. Для дискретных данных может указываться таблица допустимых значений.
Построенную модель системы необходимо проверить на полноту и согласованность. В полной модели все ее объекты (подсистемы, процессы, потоки данных) должны быть подробно описаны и детализированы. Выявленные недетализированные объекты следует детализировать, вернувшись на предыдущие шаги разработки. В согласованной модели для всех потоков данных и накопителей данных должно выполняться правило сохранения информации: все поступающие куда-либо данные должны быть считаны, а все считываемые данные должны быть записаны.
В соответствии с вышесказанным процесс построения модели разбивается на следующие этапы:
Выделение множества требований в основные функциональные группы – процессы.
Выявление внешних объектов, связанных с разрабатываемой системой.
Идентификация основных потоков информации, циркулирующей между системой и внешними объектами.
Предварительная разработка контекстной диаграммы.
Проверка предварительной контекстной диаграммы и внесение в нее изменений.
Построение контекстной диаграммы путем объединения всех процессов предварительной диаграммы в один процесс, а также группирования потоков.
Проверка основных требований контекстной диаграммы.
Декомпозиция каждого процесса текущей DFD с помощью детализирующей диаграммы или спецификации процесса.
Проверка основных требований по DFD соответствующего уровня.
Добавление определений новых потоков в словарь данных при каждом их появлении на диаграммах.
Проверка полноты и наглядности модели после построения каждых двух-трех уровней.
Пример 2. Разработаем иерархию диаграмм потоков данных программы сортировки одномерных массивов.
Для начала построим контекстную диаграмму, для чего определим внешние сущности и потоки данных между программой и внешними сущностями. Внешней сущностью по отношению к программе является Пользователь. Он выбирает метод сортировки и вводит исходные данные, а затем получает от программы описание выбранного метода и отсортированный массив. На рис. 14 представлена контекстная диаграмма данной программы.
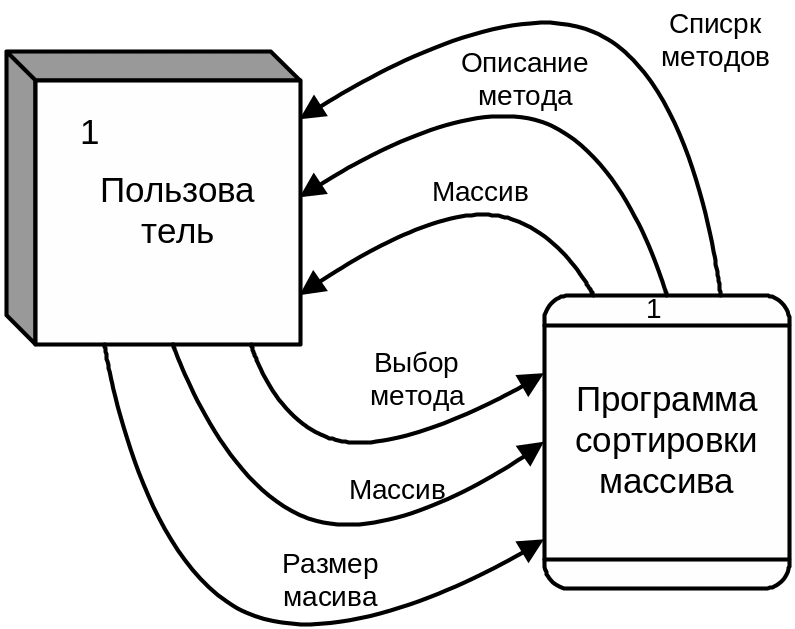
Рис. 14. Контекстная диаграмма программы построения графиков/таблиц функций
После детализации у нас получилось три процесса: Меню, Сортировка, Вывод результата. Для хранения описаний алгоритмов служит Хранилище алгоритмов. Теперь определим потоки данных.
Детализирующая диаграмма потоков данных изображена на рис. 15. Как мы видим, она несколько отличается от функциональной диаграммы (рис. 13), например, на ней показано хранилище данных для хранения описаний алгоритмов. Это отличие является важным при проектировании баз данных.
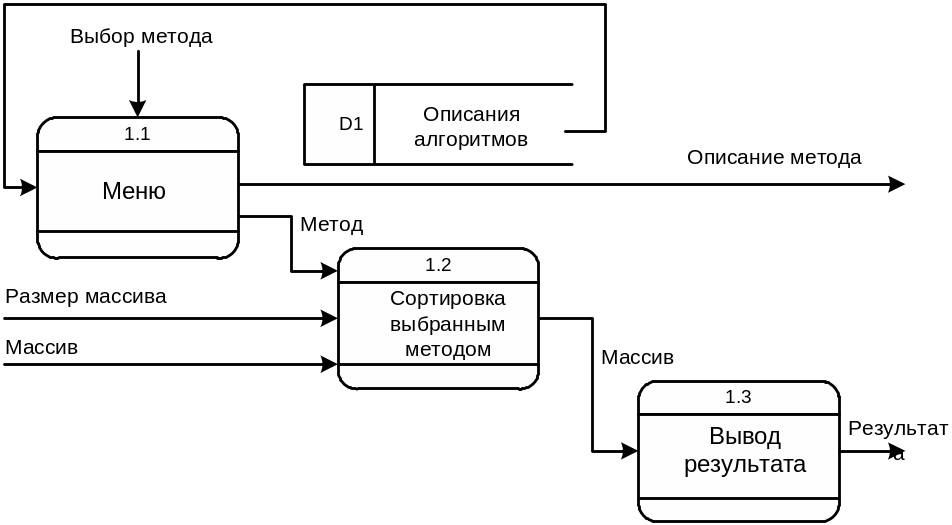
Рис. 15. Детализирующая диаграмма потоков данных программы сортировки одномерного массива (нотация Гейна-Сарсона)