

24) Критерий Стьюдента (t-критерий) (проверка гипотез о равенстве средних).
Критерий позволяет найти вероятность того, что оба средних значения в выборке относятся к одной и той же совокупности. Данный критерий наиболее часто используется для проверки гипотезы: «Средние двух выборок относятся к одной и той же совокупности».
При использовании критерия можно выделить два случая.
а) случай независимых выборок
Статистика критерия для случая несвязанных, независимых выборок равна:
![]() (1)
(1)
где
![]() ,
,
![]() — средние арифметические в экспериментальной
и контрольной группах,
— средние арифметические в экспериментальной
и контрольной группах,
![]() -
стандартная ошибка разности средних
арифметических. Находится из формулы:
-
стандартная ошибка разности средних
арифметических. Находится из формулы:
![]() , (2)
, (2)
где n1 и n2 соответственно величины первой и второй выборки.
Если n1=n2, то стандартная ошибка разности средних арифметических будет считаться по формуле:
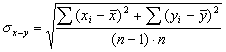 (3)
(3)
где n величина выборки.
Подсчет числа степеней свободы осуществляется по формуле:
k = n1 + n2 – 2. (4)
При численном равенстве выборок k = 2n - 2.
Далее необходимо сравнить полученное значение tэмп с теоретическим значением t—распределения Стьюдента (см. приложение к учебникам статистики). Если tэмп<tкрит, то гипотеза H0 принимается, в противном случае нулевая гипотеза отвергается и принимается альтернативная гипотеза.
б) случай связанных (парных) выборок
В случае связанных выборок с равным числом измерений в каждой можно использовать более простую формулу t-критерия Стьюдента.
Вычисление значения t осуществляется по формуле:
![]() (5)
(5)
где
![]() —
разности между соответствующими
значениями переменной X и переменной
У, а d
- среднее этих разностей;
—
разности между соответствующими
значениями переменной X и переменной
У, а d
- среднее этих разностей;
Sd вычисляется по следующей формуле:
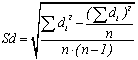 (6)
(6)
Число степеней свободы k определяется по формуле k=n-1. Рассмотрим пример использования t-критерия Стьюдента для связных и, очевидно, равных по численности выборок.
Если tэмп<tкрит, то нулевая гипотеза принимается, в противном случае принимается альтернативная.
27)Методы кластеризации данных
Кластеризация (или кластерный анализ) — это задача разбиения множества объектов на группы, называемые кластерами. Внутри каждой группы должны оказаться «похожие» объекты, а объекты разных группы должны быть как можно более отличны.
Методы кластеризации:
К-средних
Графовые алгоритмы кластеризации
Статистические алгоритмы кластеризации
Алгоритмы семейства FOREL
Иерархическая кластеризация или таксономия
Нейронная сеть Кохенена
Ансамбль кластеризаторов
Алгоритмы семейства KRAB
EM – алгоритм
Алгоритм, основанный на методе просеивания
Формальная постановка задачи кластеризации
Пусть X — множество объектов, Y — множество номеров (имён, меток) кластеров. Задана функция расстояния между объектами. Имеется конечная обучающая выборка объектов.
Требуется разбить выборку на непересекающиеся подмножества, называемые кластерами, так, чтобы каждый кластер состоял из объектов, близких по метрике, а объекты разных кластеров существенно отличались. При этом каждому объекту приписывается номер кластера.
Методы кластерного анализа в пакете STATISTICA
В модуле Cluster Analysis пакета Statistica реализуются следующие методы классификации:
- Объединение ( древовидная кластеризация)
- Метод К – средних
- Двухвходное объединение