

3.3.4. Правила проверки значений и значения по умолчанию
При формировании колонок таблицы на странице с описанием параметров СУБД в полях Valid и Default можно задать правила проверки значений и значение по умолчанию (рисунок 3.3.4.1). При нажатии кнопок с троеточием вызываются соответствующие мастера (рисунки 3.3.4.2; 3.3.4.3).
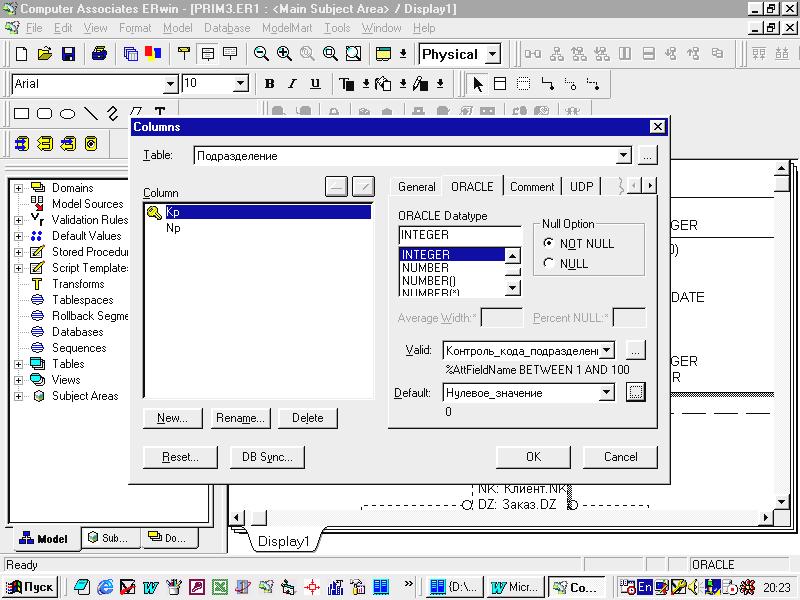 Рисунок 3.3.4.1.
Страница параметров настройки СУБД
окна свойств колонок
Рисунок 3.3.4.1.
Страница параметров настройки СУБД
окна свойств колонок
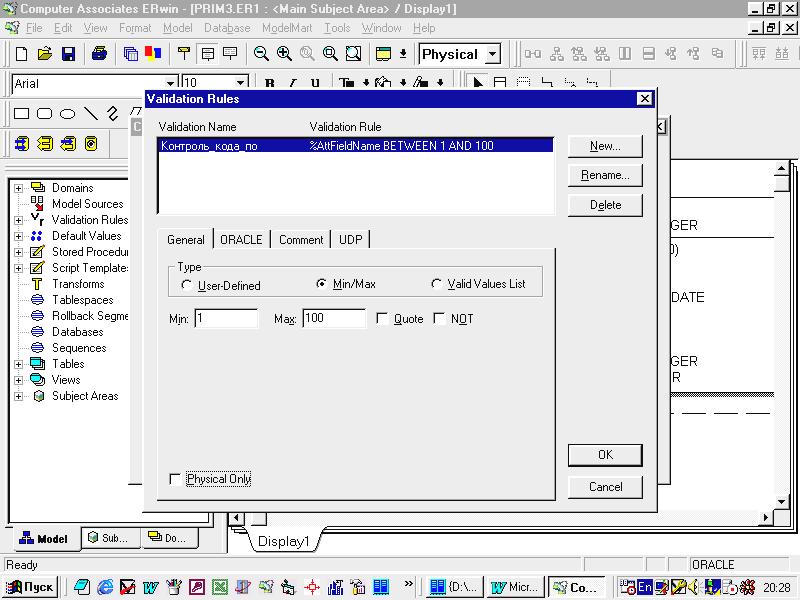 Рисунок
3.3.4.2. Окно задания правил проверки
значений колонок
Рисунок
3.3.4.2. Окно задания правил проверки
значений колонок
Используя переключатели User‑Defined, Min/Max и Valid Values List, можно задать условие, диапазон или список допустимых значений соответственно (рисунок 3.3.4.2).
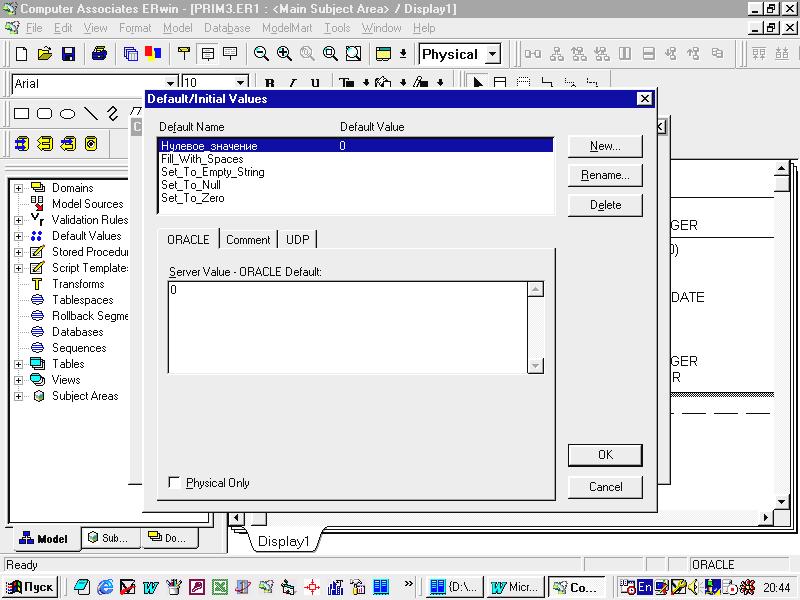 Сформированные
правила проверки значений (валидации)
и значений по умолчанию можно
присвоить одной или нескольким колонкам
или доменам.
Сформированные
правила проверки значений (валидации)
и значений по умолчанию можно
присвоить одной или нескольким колонкам
или доменам.
Рисунок 3.3.4.3. Окно задания значений по умолчанию
3.3.5. Индексы
Для таблиц создаются индексы (индексированные таблицы). Для некоторых СУБД (FoxPro, dBase, Paradox) индексы могут храниться на диске в отдельных индексных файлах. Индексный файл (таблица, структура) содержит записи, каждая из которых содержит два значения – индекса и адреса записи таблицы со значением данного индекса. Адреса могут быть абсолютными (номер цилиндра, дорожки, сектора), относительными (номер записи в таблице) или символическими. Записи в индексном файле отсортированы по возрастанию или убыванию значения индекса.
Индексом может быть поле или группа полей (составной индекс) или свертка индекса (Hashed Index) в виде хеш‑кода (шифрованное значение ключа). Хеш‑код уменьшает размер индекса, но требуется дополнительное время на шифрование и дешифрование специальными программами (процедурами хеширования или рандомизации).
Наличие индекса позволяет:
обработать таблицу в нужной последовательности (логическая сортировка базы);
осуществить прямой поиск нужной записи по ее индексу путем перебора записей индексного файла и сравнения текущего индекса (свертки) с искомым значением индекса (свертки после ее получения по искомому индексу). После нахождения записи в индексном файле выбирается адрес, и запись таблицы с данным адресом становится текущей. Если используется свертка и имеются синонимы, то дополнительно просматривается цепочка синонимов и выбирается запись с искомым значением индекса. Так как размеры индексных файлов небольшие, они хранятся в оперативной памяти, и поэтому их просмотр ведется в оперативной памяти очень быстро;
связать родительскую таблицу с дочерней таблицей по индексу;
организовать быстрый последовательный поиск группы записей таблицы по условию их отбора путем использования фильтрованного индекса или использовать индексы вместо полей записей таблицы в условиях отбора записей. Например, если имеется индекс по полю «Фамилия» и нужно найти запись о сотруднике Иванове, то будет просматриваться не запись таблицы, а индексный файл, что значительно быстрее.
Процессом просмотра и доступа к базе данных управляет один индексный файл (главный). Однако при изменении информации в таблице обновляются все индексные файлы таблицы. Главный индексный файл можно определить при помощи специальных команд управления индексами (для FoxPro: Set Order, Set Index).
Кластеризованный индекс (Cluster) физически сортирует таблицу, что ускоряет выполнение запросов за счет близкого расположения логически связанных записей на диске (MS SQL Server, MS Access, INFORMIX, DB2, SYBASE, SQLBase, HiRDB). Первичный индекс по умолчанию создается кластеризованным.
При генерации физической схемы ERWin автоматически создает индексы на основе первичных, альтернативных, внешних ключей и инверсионных входов.
Имя индекса имеет вид:
X<имя ключа: PK | IFn | IEn><физическое имя таблицы>
Символы PK, IFn и IEn означают первичный, внешний ключи и инверсионный вход соответственно (n – порядковый номер колонки в составном индексе).
Редактирование индекса реализуется командой Indexes из контекстного меню таблицы. Окно свойств индекса имеет страницы: Members (выбор колонок индекса), <имя типа СУБД> (свойства индекса для выбранной СУБД), Patritions (составная часть), Comment (комментарий), UDP (свойства пользователя) (рисунок 3.3.5.1).
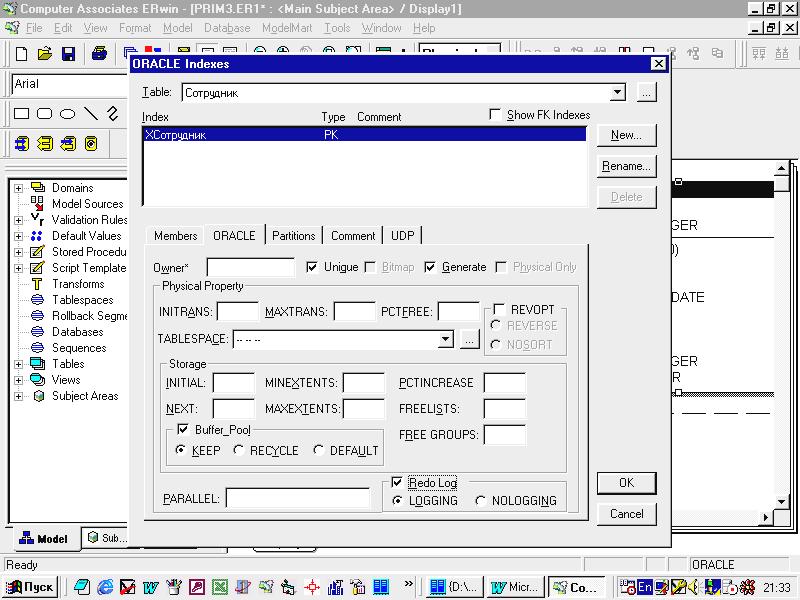 Рисунок 3.3.5.1.
Страница свойств индекса для выбранной
СУБД ORACLE
Рисунок 3.3.5.1.
Страница свойств индекса для выбранной
СУБД ORACLE