

16. Способы обеспечения и ускорения сходимости
1.Выбор начального распространения весов. Чтобы вывести сеть из равновесия перед обучением выполняют инициализация (заполнение) матрицы весов случайными значениями иначе все произведения от функции ошибки = 0.
Способы изменения весов: ▪Классический подход (учитывая, что функция сигмоида имеет минимальные значения в интервале [-3;3], то случайные величины весов выбирают из интервала [-3/n;3/n], где n размерность сети во входном слое. ▪Инициализация весов по прототипам, полученным из кластеров обучающего множества.
2.Обход локальных минимумов. Для достижения глобального мин поверхности ошибки используется ряд способов:
-
расширение размерности пространства весов за счет увеличения количества скрытых весов и повышения количества нейронов в скрытых слоях.
-
Эвристические подходы оптимизации. Например, использ генетического алгоритма.
3.Упорядочивание примеров. Множество примеров упорядочивают случайным образом («взбалтывание примеров»), что позволяет избавиться от случайно образованной тенденции. Если некоторые примеры представлены в недостаточном объеме, то их подают на сеть чаще остальных.
4. Пакетная обработка. Если модифицировать веса связей после кажд примера, то предъявление кажд класса может приводить к колебаниям сети. Пакетная обработка подразумевает изменение весов связи по усредненному значение по ряду примеров. Минимальная величина ошибки выполняется с помощью градиентных методов:
-
градиент общей ошибки вычисляется после просчета всего обучающего множества (эпохи) w(t+1)=w(t) – τE/W, где E/W – градиент, τ - величиной градиентного шага, задается пользователем.
-
Стохастический градиентный метод. Пересчет выполняется после прохождения всего множества примеров, но используется часть частной производной ошибки для к-го множества. w(t+1)=w(t) – τE/Wк. Если в начале обучения брать небольшие пакеты примеров, а затем их увеличивать до общего количеств, то время обучения снижается, а сходимость к глобальному решению остается. Этот подход используется при большом количестве примеров или при большой их размерности.

5. Импульс. При определении
направления поиска к текущему градиенту
добавляется поправка – это вектор
смещения с пред шага, взятый с некоторым
коэффициентом ![]() ,
где μ определяется пользователем(0,9<1).
Этот метод чувствителен к способу
упорядочивания примеров.
,
где μ определяется пользователем(0,9<1).
Этот метод чувствителен к способу
упорядочивания примеров.
6. Управление величиной шага. При небольшом шаге процесс обучения будет медленней, а при большом – можно проскочить глобальный мин (что плохо). Потому величину шага постоянно снижает в процессе обучения. Если при определенном шаге ошибка сети уменьшилась, то шаг умножают на коэффициент >1 (это поощрение), если ошибка увеличилась то на <1 (наказание).
17. Сеть встречного распространения
Является комбинированной. Основана на идеи о каскадном соединении мозговых структур различной архитектуры. Сеть встре.распр. не яв-ся общей, как сеть Розен блата
М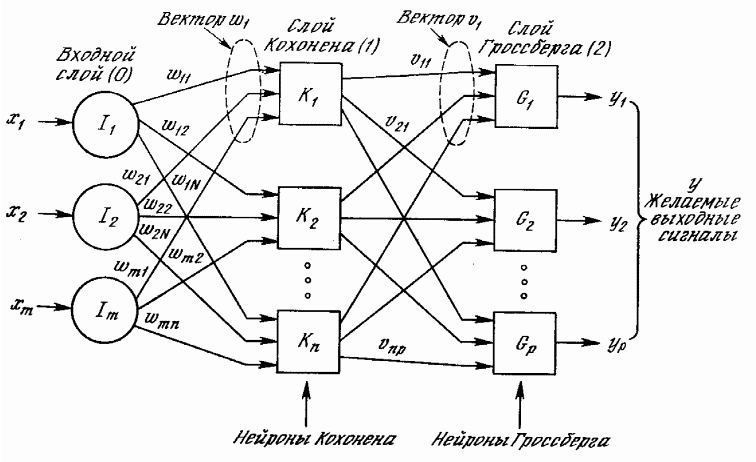 одели
персептрона, но позволяет найти приемлемые
решения при высокой скорости обучения.
В состав модели входит модель
«Самообучающиеся карты» Кохонена и
«Звезда» Гросберга. Выдача сигнала
только при подачи на вход определенного
образа. Входной образ связывается с
определ-м нейроном, а не в результате
взаимодействия нейронов м\д собой. Суть
состоит в следущем: Слой Кохонена
обучается без учителя. При подаче на
входе вектор х формирует некоторое
след. Значение :
одели
персептрона, но позволяет найти приемлемые
решения при высокой скорости обучения.
В состав модели входит модель
«Самообучающиеся карты» Кохонена и
«Звезда» Гросберга. Выдача сигнала
только при подачи на вход определенного
образа. Входной образ связывается с
определ-м нейроном, а не в результате
взаимодействия нейронов м\д собой. Суть
состоит в следущем: Слой Кохонена
обучается без учителя. При подаче на
входе вектор х формирует некоторое
след. Значение :
![]() .
Подстраиваются веса связи того нейрона,
у которого самый большой потенциал.
Потом вычисляется выход нейрона
Гроссберга.
.
Подстраиваются веса связи того нейрона,
у которого самый большой потенциал.
Потом вычисляется выход нейрона
Гроссберга.
![]()
В своей простейшей форме слой Кохонена функционирует в духе «победитель забирает все», т. е. для данного входного вектора один и только один нейрон Кохонена выдает на выходе логическую единицу, все остальные выдают ноль. Нейроны Кохонена не имеют функций активации и победителем считается нейрон, имеющий больший потенциал.
Поскольку один нейрон Кохонена активен, то подстаиваются веса связи, только нейрона Гросберга соедененного с активным нейроном Кохонена.
Обучение Кохонена является самообучением, протекающим без учителя.
В результате веса слоя Гроссберга (обучение с учителем) сходятся к средним значениям от желаемым выходом, по которому он обучается.
Обучающийся без учителя, самоорганизующийся слой Кохонена веса сходятся к средним значениям входов. Они отображаются в желаемые выходы слоем Гроссберга.
Сеть может функционировать в режиме интерполяции, когда в слое Кохонена м.б. несколько нейронов победителей.