

13. Информационные структуры
13.1. Последовательное и связанное распределение данных
Последовательное распределение
С вычислительной точки зрения простейшим представлением [11] конечной последовательности является список ее членов, расположенных по порядку в последовательных ячейках памяти.
d
|
Ячейка памяти |
S1 |
S2 |
S3 |
… |
Sn-1 |
Sn |
|
Адреса ячеек памяти |
g1 |
g2 |
g3 |
|
gn-1 |
gn |
g2 = g1 + d
g3 = g1 + 2d
…
gn = g1 + (n-1) d
Таким образом, представляется последовательное распределение данных S1, S2,…, Sn, для каждого элемента которой требуется объем памяти d, gi — адрес ячейки.
Такое представление имеет ряд преимуществ. Во-первых, оно легко осуществимо и требует небольших расходов памяти. Во-вторых, существует простое соотношение между номером элемента i и адресом ячейки, в которой хранится Si: gi = g1 + (i-1) d. Это соотношение позволяет организовать прямой доступ к любому элементу последовательности. В-третьих, оно имеет широкий диапазон и включает в себя представление многомерных массивов.
Последовательное распределение имеет значительный недостаток. Оно становится неудобным, если требуется изменить последовательность путем включения новых и исключения имеющихся там элементов. Включение между Si и Si+1 нового элемента требует сдвига Si+1, … Sn вправо на одну позицию, а исключение соответственно — сдвиг влево.
С точки зрения времени обработки такое передвижение элементов может оказаться дорогостоящим, и в случае динамических последовательностей лучше использовать технику связанного распределения.
Связанное распределение
Неудобство включения и исключения элементов при последовательном распределении происходит из-за того, что порядок следования элементов задается неявно требованием, чтобы смежные элементы последовательности находились в смежных ячейках памяти. Если это требование опустить, то можно выполнять операции включения и исключения без передвижения элементов последовательности. Конечно, необходимо сохранять информацию о способе упорядочения элементов, но можно это делать явным образом. В частности, при связанном распределении данных каждому Si поставлен в соответствие указатель Рi, отмечающий ячейку, в которой записаны Si+1 и Pi+1 (т.е. переход на следующую ячейку последовательности). Существует также указатель P0, который указывает на начальную ячейку последовательности, т.е. на ячейку с содержимым S1 и P1.
(INFO) (LINK)
|
P0=g1 |
S1 |
P1=g2 |
|
S2 |
P2=g3 |
… |
Sn-1 |
Pn-1 =gn |
|
Sn |
Pn= |
|
|
g1 |
|
|
g2 |
|
|
g n-1 |
|
|
g n |
|
Рис. 13.1. Представление последовательности в виде связанного списка. Каждый элемент списка состоит из поля INFO (содержащего элемент последовательности) и поля LINK (содержащего адрес следующего элемента)
Здесь каждый узел состоит из двух полей. Под узлом понимается одно или несколько последовательных слов в памяти машины, выступающих как единое целое. — пустой или нулевой указатель. Рассмотрим более употребляемый способ задания списка.
|
|
S1 |
|
|
S2 |
|
… |
Sn-1 |
|
|
Sn |
|
|
|
|
|
|
|
|
|
|
|
|
|
|




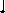
 P0
P0
Рис. 13.2. Способ задания списка
Связанное представление данных облегчает операции включения и исключения элемента, если ячейка Si известна. Для этого лишь необходимо, изменить значение некоторых указателей. Например, чтобы исключить элемент S2 из последовательности, изображенной на рис. 13.2, необходимо положить LINK(g1)=LINK(g2). После этой операции элемента S2 в последовательности больше не будет.

|
|
S1 |
|
|
S2 |
|
|
S3 |
|
… |
|
|
|
|
|
|
|
|
|
|
|


 P0
P0
Рис. 13.3. Исключение элемента из связанного списка
Чтобы в последовательность (рис. 13.2) включить новый элемент S5 после S1, необходимо воспроизвести новый элемент в некоторой ячейке g5 с INFO(g5) = S5 и LINK(g5) = LINK(g1) и присвоить LINK(g1) g5.
|
|
S1 |
|
|
S2 |
|
|
S3 |
|
… |
|
|
|
|
|
|
|
|
|
|
|



 P0
P0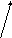
-
S5
g5
Рис. 13.4. Включение элемента в связанный список
Также легко осуществляется сцепление последовательностей и разбиение последовательности на части.
Использование связанного распределения предполагает существование некоторого механизма, который по мере надобности собирает ячейки (мусор), когда они освобождаются.
С помощью связанного распределения достигается большая гибкость, но идет потеря скорости обращения к данным. При последовательном представлении фиксированное соотношение между i и ячейкой Si позволяет, в частности, иметь быстрый и прямой доступ к любому элементу последовательности. В связанном распределении такого соотношения не существует, и доступ ко всем элементам последовательности, кроме первого, не является прямым и эффективным. Кроме того, при связанном представлении приходится тратить память на указатели Pi.
В приложениях при выборе последовательного или связанного способа представления данных разумно сначала проанализировать типы операций, которые чаще других будут выполняться над данными и в соответствии с этим выбрать способ организации данных. Если операции производятся преимущественно над случайными элементами, если осуществляется поиск отдельных элементов или производится упорядочение элементов, то лучше применять последовательное распределение.
Связанное распределение предпочтительнее, если в значительной степени используются операции включения и/или исключения элементов, а также сцепления и/или разбиения последовательностей.