

Блок микропрограммного управления
1) структура микрокоманды.
Подобно структуре машинной команд имеющих операционную и адресные части, характерные для машин модели Фон-Неймана, блоки микропрограммного управления данного направления оперируют с микрокомандами, имеющих подобную им структуру, то есть микрокоманда состоит из адресной и операционной части. В зависимости от способа кодирования микроопераций, то есть функциональных управляющих сигналов, различают структуры блоков микропрограммного управления:
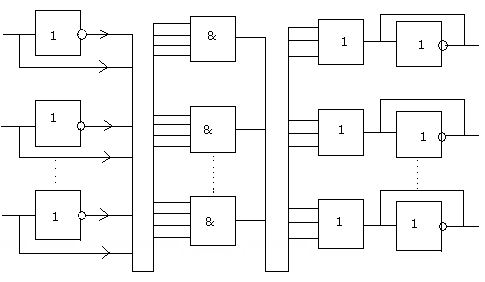
а) с горизонтальным кодированием;
б) с вертикальным кодированием;
в) вертикально-горизонтальным кодированием;
г) горизонтально-вертикальным кодированием.
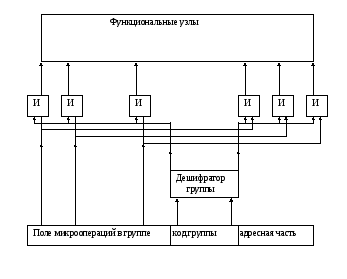
1)Структуры с горизонтальным кодированием
|
|
|
|
|
|
|
|
|
|
Где каждый разряд операционного поля указывает на наличие 1 или отсутствие 0 микрооперации. Достоинства: возможность одновременного выполнения микроопераций в одном такте. Недостаток: большая разрядность микрокоманд.
2)Вертикальное кодирование
Операционное поле представляет двоичный код микрокоманды.
При количестве m разрядов общее число микроопераций =2m.
Недостаток- возможно выполнение только одной микрооперации в такте

Горизонтально-вертикальное кодирование(гибрид двух способов).

При данном способе кодирования операционная часть микрокоманды разбивается на несколько полей, каждое из которых
обычно управляет однородными узлами в процессоре. Например, в поле микроопераций АЛУ кодируются арифметические действия над операндами а их местонахождения кодируются адресами операционных регистров в соответствующих полях микрокоманды.
Для анализа состояния узлов в процессоре отводят поля переходов, по кодам которых происходит аппаратная проверка того или иного флага или триггера в процессоре и в зависимости от его нулевого или единичного состояния формируется сигнал установки разряда
адреса следующей микрокоманды.
Вертикально-горизонтальный способ кодирования.
Принцип данного способа заключается в том, операционное поле микрокоманды разбивается на две части;
В первой каждый разряд фиксирует наличие или отсуствие микрооперации, подобно как это делается при горизонтальном методе, в группе микроопераций, номер или код которой указывается во второй части операционного поля микрокоманды.
Такой способ хоть и позволяет сократить длину микрокоманды, но требует тщательного анализа и большой подготовительной работы при проектировании блока микропрограммного управления так как необходимо выбрать не только оптимальное число групп, но и сформировать их по возможности равномощными. Сложность реализации блока управления при таком кодировании еще и в том, что каждая микрокоманда имеет ограниченные возможности воздействия на количество функциональных узлов в процессоре, в противном случае пришлось бы увеличить длину первой части операционного поля микрокоманды, чтобы охватить управлением как можно большее число узлов в процессоре. А это проще реализовать при горизонтально-вертикальном кодировании, когда в составе одной микрокоманды не одно поле, а группа полей и управлению подвергаются все узлы в процессоре таким образом увеличивая степень параллелизма на уровне выполнения команды.
Способ же вертикально-горизонтального кодирования ,как напрашивается вывод, в системах с малым количеством объектов управления или в которых происходит последовательная активизация узлов, функционирующих по принципу временного разделения с передачей промежуточных результатов из одного в другой,
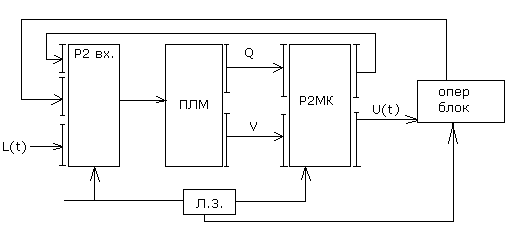
Блок-схема блока с микропрограммным управлением
1)Каждое управляющее слово расположено в ЦП по определенному адресу.
2)Часть разрядов микрокоманд отведена для размещения адреса следующей микрокоманды.
3)Одновременно с выполнением текущей микропрограммы формируется адрес следующей микрокоманды.
4)Для организации ветвления в микропрограмме( ближний переход) в микрокоманде отводят поле для анализа условий переходов(обычно для формирования младших разрядов регистрового адреса микрокоманд).
5)Для перехода в другие микрокоманды используются технологии перехода как и в программах с использованием регистрового адреса возврата.
6)В управления памяти микропрограмм находятся следующие вызовы микропрограмм:
а)микропрограммы операций;
б) микропрограммы выборки команд;
в) микропрограммы обработки прерываний;
г) микропрограммы пульт. операций;
д)микропрограммы продвижение таймеров;
е) микропрограммное восстановление после машинных ошибок;
ж) диагностические микропрограммы
дш
дш
дш
Коммутатор адреса микроком.
Дш
Поля
Перех.
Дш
Поля
перех
Из каналов в.выв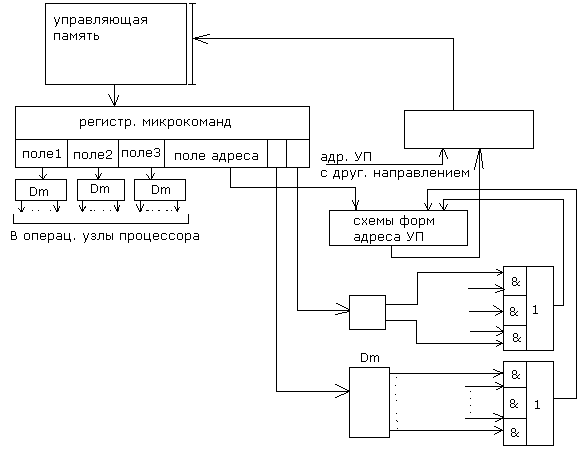
Блок перехода к микропрограммам с использованием
р
Установ.
ТХР
Адреса
возврата
Установки
ТХР
Адреса
возврата
Микропрограммные управления в Z архитектурах.
Идея использования микрокода в Z архитектурах базируется на следующих положениях:
1) микрокод размещается в системной памяти ( HSA – hardware system address ) области предназначен для описания аппаратных средств, а не как во всех предыдущих архитектурах в отдельной памяти со своей структурой микрокоманд.
2) Структура микрокода (формат) такой же как и для всех команд в системе. Имеет вертикальное кодирование, то есть это не микрокоманда, а обычная системная команда.
3) Рутины ( микропрограмм ) могут использовать только те команды, которые непосредственно выполняются в процессоре, то есть использование экстракодов, представляющих комплекс команд, запрещено.
4) Кроме того в набор команд микрокода входит около 70-ти инструкций, которые могут быть использованы в рутинах микрокодах. Эти инструкции обрабатывают уникальные данные, доступ к которым для системных команд запрещен.
5) Для обработки данных в рутинах микрокода выделяются специальные регистры, а так же для хранения адресов с целью доступа к областям памяти пользователя и к областям HSA.
6) Микрокод использует аппаратные средства предсказания переходов в блок ВТВ, так же как и инструкции системных команд.
7) Использование в составе блока восстановления в процессоре регистров доступных микрокоду обеспечить интерфейс для управления аппаратными средствами процессора.
Блок управления с жесткой логикой.
Формирователи управляющих
сигналов
Функциональные блоки процессора
Комбинационные схемы
Блока управления процессора
Дешиф.
Кода операций
В основу блока управления с жесткой логикой положен принцип построения комбинационных схем с обратными связями, схем в которых каждое последующее состояние элементов схем определяется предыдущим и с учетом всех возмущающих воздействий, представляющих результаты действия микроопераций или по- другому управляющих сигналов, поступающих в функциональные блоки процессора , так и сигналов внешних несвязанных непосредственно с работой процессора.
Активизация блока управления с жесткой логикой происходит при выполнении команды по коду операции, который подается на дешифратор, на одном из выходов которого формируется управляющий сигнал, действующий во время выполнения команды в процессоре.
В блоке управления находится распределитель импульсов, который по каждому тактовому импульсу в конъюнкции с управляющим сигналом с дешифратора кода операции формирует конкретные для каждой команды управляющие сигналы, направляемые в блоки процессора.
Количество тактов вырабатываемых распределителем берется из условия выполнения самой сложной команды в процессоре требующей для выполнения наибольшее количество тактов.
Обычно выполнение команды делится на этапы или машинные циклы, как мы уже говорили, поэтому каждый этап выполнения команды фиксируется на триггерах. Переключение этих триггеров осуществляется через комбинационные схемы, в качестве входных сигналов в которых используют не только управляющие сигналы с дешифратора кода операций , но и другие параметры формата команд. Так, например, триггер такта базирования в команде не будет установлен, если при переходе из такта чтения команды комбинационная схема обнаружит нулевое значение поля базы в формате команды. При таком построении блока управления каждый триггер, фиксирующий этап выполнения команды, своим единичным состоянием разрешает формирование управляющих сигналов, распределенных во времени в течении такта. То есть помимо основного распределителя импульсов требуется дополнительный с большей частотой, вырабатывающий тактовые сигналы для каждого машинного цикла или этапа выполнения команды в процессоре
На ниже приведенной схеме представлен фрагмент комбинационной схемы ,на которой показано взаимодействие распределителя тактовых импульсов и выходов дешифратора кода операций при формировании управляющих сигналов во время выполнения команды в процессоре и влияние сигналов обратной связи поступающих из других блоков в блок управления.
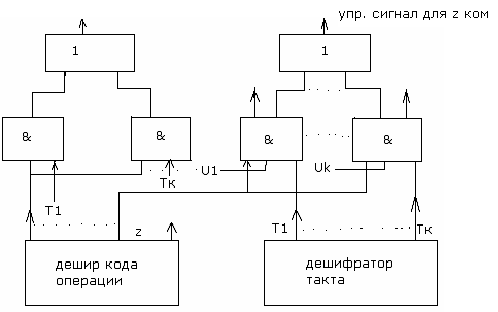
В качестве другого примера приведена схема с жесткой логикой на базе использования программируемой логической матрицы, при изготовлении которой ,образуется схема допускающая множество вариантов комбинации входных сигналов. На каждый входное элемент представляющий конъюнкцию подаются все входные сигналы как в прямой так и в инверсной форме. Ко входам каждого элемента выполняющего функцию ИЛИ подведены все выходы элементов И . Таким образом можно реализовать любую комбинационную схему в приделах наличия количества логических элементов путем устранения ненужных связей методом прожига.
Использование П.Л.М. в блоке управления «жесткой логикой»
ЛЕКЦИЯ N11
Тема лекции:
Блок операций.
Конвейерная обработка команд в процессоре.
Блок операций.
Блок операций предназначен для аппаратной реализации тех функций, которые заложены в команды осуществляющие преобразование данных, указанных в адресной части команды.
Преобразования эти в первую очередь связаны с арифметическими и логическими действиями над операндами, поэтому блок операций
идентифицируют как АЛУ.
Именно блок операций во многом определяет архитектуру процессора. В зависимости от функций, заложенных в архитектуру блока операций, процессор может быть классифицирован как спецпроцессор, предназначенный для решения узкого круга задач, связанных с определенными видами математических вычислений.
Примером тому могут быть матричный или векторный процессор, которые выполняют однотипные операции над большими массивами данных.
При проектировании процессора общего назначения в котором основная масса операций связана с выполнением разнотипных действий над элементами массива, целесообразно иметь классическое операционное устройство в виде многофункционального АЛУ, в котором в зависимости от выполняемой операции активизируется соответствующий узел или схема.
Например, при обработке последовательных кодов в реальном масштабе применяются АЛУ побитной обработки.
При последовательной обработке команд в процессоре целесообразно иметь многофункциональное многоразрядное АЛУ,
А при выполнении операций с плавающей точкой с особенностью алгоритма выполнения операции блочное, в котором два блока независимо друг от друга ведут параллельную обработку мантисс и порядков операндов.
В виду специфики представления чисел в двоичной системе исчисления умножение двух чисел реализуется с использованием операций сложения и сдвигов промежуточных сумм относительно множимого. Процесс занимает не один такт работы операционного устройства. Для сокращения времени на выполнение операции умножения применяют два метода: логический и аппаратный.
Логический использует одновременное умножение на два или более разрядов множителя. Комбинационная схема анализирует группу разрядов, активизирует работу сумматора и сдвигателя.
Аппаратный метод включает в себя комбинационные схемы ускоренного переноса, совмещения во времени операций сдвига и сложения, табличные методы умножения, в которых используются программируемые запоминающие устройства. В зависимости от комбинаций входных сигналов ( групп разрядов множимого и множителя) на выходе ППЗУ формируется произведение.
Операция умножения в этом случае выполняется за один такт.
Кроме арифметических операций операционный блок выполняет ряд логических действий над операндами. Это И, ИЛИ, сложение по модулю два.
Операции над операндами проводят поразрядно .В многофункциональных АЛУ в целях экономии затрат на аппаратные средства при операциях над многоразрядными числами используют побайтную обработку в однобайтном тракте операционного устройства. Например, при обработке четырехбайтных операндов потребуется соответственно четыре такта работы логического сумматора, а в случае нахождения одного из операндов в оперативной памяти , потребуются кроме тактов выборки его из памяти еще такты для выравнивания на целочисленную границу считанного операнда в тракте операционного устройства так как операнд в памяти может находиться начиная с любого байта ,поэтому чтобы производить операцию над одноименными разрядами операндов и требуется эта корректировка.
Для ускорения выполнения логических операций за счет аппаратных издержек стали использовать отдельный блок логических операций, по другому стали применять блочную структуру операционного устройства. Мы уже говорили о блочном построении АЛУ для операций с плавающей точкой, так вот тенденция этого направления стала определяющей при внедрении конвейерной обработке команд в процессоре.
Основной принцип работы ускорителя выполнения логических операций-это обработка операндов словами, а не побайтно, что приводит к сокращению числа сдвигов работе сдвигателя за счет сдвига группы байт в одном такте.
Так, например, при побайтной обработке при расположении операнда в границах двойного слова (а именно такова ширина шины выборки из памяти команд/данных во многих архитектурах) требуется четыре такта как максимум для подачи байтов слова в УЛК и плюс такт на подачу второй части двойного слова на сдвигатель, то для выравнивания при обработке словами в четыре байта потребуется всего два такта.
Конвейерная обработка.
Конвейерная обработка команд в процессоре.
Конвейерная обработка команд в процессоре и её проектирование относится к так называемому методу «совмещения операций», который кроме вышеуказанной конвейеризации включает еще и параллелизм.
Параллелизм является более высокой ступенью обработки команд в процессоре и совмещения операций в нем достигается путем использования нескольких копий аппаратных средств, из-за чего и достигается высокая производительность. Примером использования параллелизма может служить аппаратная поддержка организаций технологии ……………. в «INTEL», которая за счет дублирования части аппаратных средств позволяла организовывать двух поточную обработку команд и соответственно организации двух логических процессоров на базе одного физического кристалла.
Другим примером может служить принцип работы POWER 5 SMT. Другими словами технология параллелизма это промежуточная архитектура или организация аппаратного комплекса между конвейерной организацией скалярных и суперскалярных процессоров и многопроцессорной системой..
Конвейерная организация в общем случае основана на разделении подлежащих к исполнению функций на более мелкие части, называющиеся ступенями, и выделений для каждой из них отдельного блока аппаратуры. При этом конвейерную обработку можно использовать для совмещения этапов разных команд. Производительность при этом возрастает не за счет сокращения времени выполнения одной команды, а за счет одновременной обработки команд на конвейере. Подобная технология «расчленения» выполнения команды на более мелкие этапы была еще использована в процессорах СISC архитектуры с микропрограммным управлениям; но эта технология предполагала монополизацию аппаратных средств микропрограммой на все время выполнения команды в процессоре. В принципе организация конвейерной обработки с микропрограммным управлением возможна, но для этого каждая ступень конвейера должна иметь свои микрокоманды и память для их хранения. А это связанно с аппаратными изменениями. Хотя попытки такой организации были. Примером тому был блок акселератора со своей памятью микропрограмм для выполнения операций сдвига, умножения, деления. Акселератор получал управления от основной микропрограммы, реализующей выполнение команды. Микропрограмма акселератора запускалась и шла параллельно выполнению микропрограмм. Для временного согласования работы акселератора и микропрограммы процессора микрокоманды содержат специальные микрооперации, осуществляющие остановку микропрограмм в случае необходимости.
Но в этом случае параллельная обработка осуществлялась только в рамках одной команды, это сокращало время её выполнения. Максимум чего добивалась CISC архитектура это организация двухступенчатого конвейера благодаря применению модифицированной гарвардской архитектуры в структуре блока выборки команд. За счет совершения этапов выборки команды и выполнения. И так в начале 80-х стало ясно, это CISC архитектура процессора на базе принципа Фон-Неймана – совместной командной шины и данных стала тормозом для дальнейшего повышения производительности работы процессора.
Для осуществления вышеуказанных задач необходимы другие принципы, которые были реализованы в RISC архитектуре. Но с другой стороны те наработки в программном обеспечении CISC процессоров нельзя было откинуть. Пример тому INTEL, которая для сохранения программного продукта оставила «старый» уровень архитектуры команд и для реализации конвейера в своих процессорах стала «резать» свои команды на микрооперации аппаратными средствами после выборки команд из памяти и размещения в буферных регистрах. При этом используемые для этих целей сложные декодеры( 3 штуки ) таким образом осуществляют поставку микроопераций в RISC ядро своих процессоров. В случае сложного декодирования команд, которые интерпретировались больше чем три микрооперации, используется микрокод, записанный в специальную память и представляющий набор микроопераций для выполнения этой сложной команды. Для указания принадлежности микроопераций в одной команде используется специальный бит в формате микрооперации, который устанавливается в «1» во всех микрооперациях принадлежащих команде, кроме последней ,в которой он устанавливается в 0 – указывая конец цепочки. Но конвейерная обработка команд в процессоре поставила перед разработчиками процессоров новые задачи, решение которых было связано с устранением конфликтов возникающих при работе конвейеров.
Суть этих конфликтов заключается в логических взаимосвязях элементов программного кода, который не вызывают конфликтов при их последовательном выполнении, и начинают конфликтовать при совмещении операций. К такой категории конфликтов относятся:
1) конфликт по данным
2) структурный конфликт – возникает при распределении аппаратных ресурсов при выполнении команд, когда не возможно их одновременное использование.
3) конфликты по управлению, возникающие при конвейеризации команд переходов, которые изменяют значение текущего адреса счетчика команд, и осуществляют ветвление в программе вынуждая приостанавливать конвейер до получения результата, по значению которого осуществляется переход или нет.
Структурные конфликты
Прежде чем рассматривать подробно эти конфликты и способы их устранения, определим основные этапы выполнения команды в процессоре
IF-чтение команды из памяти
ID-декодирование и формирование адреса операндов ,подготовка операции для выполнения
EX-выполнение операций
MEM-если операнд находится в оперативной памяти(КЭШ) необходим такт для запроса за операндом.
WB-запись результата операции в регистровый файл.
Предполагаем RISC архитектуру ,с использованием команд STORE и LOAD (чтение и запись результата в память) стадия МЕМ.
Пример: структура конфликта
IF ID EX ….EX WB
IF ID…….. .EX WB
Этап выполнения EX предыдущей команды занимает больше чем один такт, вторая команда вынуждена ждать освобождение операционного блока.
Пример2:
IF ID EX MEM WB LOAD R1(R6)
IF ID EX [задержка из-за того ,]WB ADD R2 R3 R4
[что регистровый файл имеет только один порт записи]
,где []-задержка
Пример3: 1- IF ID EX MEM WB
2- IF ID EX [ ] WB
3- IF ID EX [ ] WB 4- [ ] IF ID EX WB
Конфликт четвертой команды с первой одновременный запрос в память за данными и командой. Конфликт будет устранен при раздельном хранении команд и данных(гарвардская архитектура)
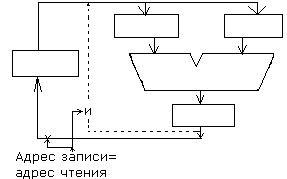
Конфликт по данным
ADD R1 R2 R3 IF ID EX WB
SUB R4 R1 R5 IF [ ] ID EX WB
Невозможна одновременная запись и чтение в R1.
Вариант обхода конфликта
Конфликты по управлению
Конфликты по управлению, как было сказано раннее, связаны с командой перехода, которые в любой системе команд являются условными или безусловными.
На первый взгляд, безусловные команды не должны вносить конфликт в работу конвейера, но дело в том ,что блок выборки команд узнает о типе команды на этапе дешифрации, а во вторых целевой адрес в лучшем случае будет вычислен в блоке выборки команд. Если в нем присутствует выделенная подсистема, предназначенная для быстрого выявления команд переходов и вычисления целевого адреса. Благодаря этой подсистеме обе эти задачи (переход и адрес перехода) решаются на этапе декодирования, это уменьшает издержки работы конвейера.
Рассмотрим пример четырех случаев конвейера с предположением , что целевой адрес вычисляется на этапе работы блока выполнения(Е)
Команды перехода:
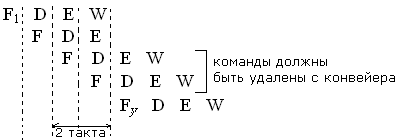
Еще больше задержки возникают при выполнении условного перехода ,когда результат зависит от выполнения предыдущей команды в большинстве случаев и переход может быть определен только после анализа результата, тогда количество удаляемых команд будет зависеть от времени получения результата.
В связи с изложенной проблемой возникает задача: разработка способов, позволяющих уменьшить данные издержки.
Динамические предсказания переходов
Один из способов – хранить специальную таблицу, в которую записывать условные переходы , и там их искать, когда они появятся снова простейшая версия: для каждой команды перехода –таблица содержит одну ячейку , в которой храниться адрес команды перехода и бит ,указывающий был ли переход или нет предыдущего результата и в соответствии с этим осуществляется переход.
Такая схема эффективна в циклах.
Существует несколько способов организации таких таблиц .В сущности ее можно организовать в форме КЭШ памяти, где в качестве тега храниться адрес команды перехода. Данная схема эффективно в том случае если задержка в вычислении целевого адреса минимальна.
Для улучшения работы схем в КЭШ можно записывать целевой адрес,вычисленный при 1 процессе.

СЧАК- счетчик адреса команд
БВК- блок выборки команд
Однобитовая схема
Однобитовая схема предсказание перехода обладает тем недостатком, что прогноз будет предсказан при в ходе в цикл и выходе из него каждый раз.
Для увеличения вероятности предсказания применяется двухбитная схема предсказания.
00-очень малая вероятность перехода, предсказание отсутствует .
01-малая вероятность перехода
10-большая вероятность перехода, предсказание делают переход
11- очень большая вероятность , предсказание делают переход.
нет перехода

ЛЕКЦИЯ N12
Б
Еще одним способом повышения производительности работы конвейера является использование метода без упорядоченного выполнения команд в процессоре, суть которого заключается в обработке команд на конвейере с изменением последовательности программного кода. Для наглядности приведем промер:
Для наглядности приведем пример:
1 2 3 4 5 6 7 8 9 10 11
1

 .LoadR1mRAWIDmmmmmw
.LoadR1mRAWIDmmmmmw
2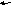 .
ADD R3R1R2
ID EX W
.
ADD R3R1R2
ID EX W
3.SUB R4R5R6 ID EX W
В данной последовательности команд команды 1, 2 имеют зависимости RAWкоторая не может быть устранена т.к. 2аякоманда ждет операнда из памяти, обращение к которому может занимать несколько циклов, а в случае «промаха» в кэш, количество их будет увеличено.
С другой стороны команда 3 не связана по
данным с 1й и 2йкомандой, и
перестановка ее в позицию 2 не скажется
на результате программы. Таким образом
будет устранен простой конвейер.
другой стороны команда 3 не связана по
данным с 1й и 2йкомандой, и
перестановка ее в позицию 2 не скажется
на результате программы. Таким образом
будет устранен простой конвейер.
1 2 3 4 5 6 7 8 9
Load R1 m ID m m m m m W
SUB R4R5R6 ID EX W
ADD R3R1R2 ID EX W
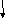
Предположение что возможно одновременно чтение и запись в регистровый файл.