

Последовательная обработка команд в процессоре.
1)Начало выполнения любой команды в процессоре начинается с выборки её из памяти, размещении в регистре команд и модификация адреса счетчика команд в зависимости от длинны команды , поступающий на обработку в процессор.
2) На следующем этапе осуществляется декодирование команды её полей, содержащих информацию о месте нахождения операндов; кода операции для логических и арифметических команд, а для команд управления, в частном случае переходов, расшифровка условий перехода и формирование адреса перехода.
3) По окончании декодирования и подготовительных операций начинается выполнение команд. Блок управления координирует работу всех узлов процессора «разбивая» выполнение команды на временные интервалы ( такты, микрокоманды, микрооперации) в зависимости от архитектуры его реализации «жесткая логика» или «микропрограммное управление».
Блок операций в различных архитектурах реализуется по-разному.
В простейшем варианте представляет арифметическое устройство. Может в своем составе содержать специальные блоки для выполнения логических операций, операций с фиксированной и плавающей точкой.
В архитектуре с конвейерной организацией в скалярных процедурах, с без упорядоченным выполнением, блок операций содержит пулы инструкций (микроопераций) ожидающих выполнение и выполненных, различные устройства для выполнения арифметических и логических операций,
обеспечивающих параллельную обработку на аппаратном уровне.
Блок операций результат своих вычислений размещает в регистровый файл или в оперативную память. Для RISC архитектур связь оперативной памяти осуществляется специальными микрооперациями или командами STORE и LOAD.
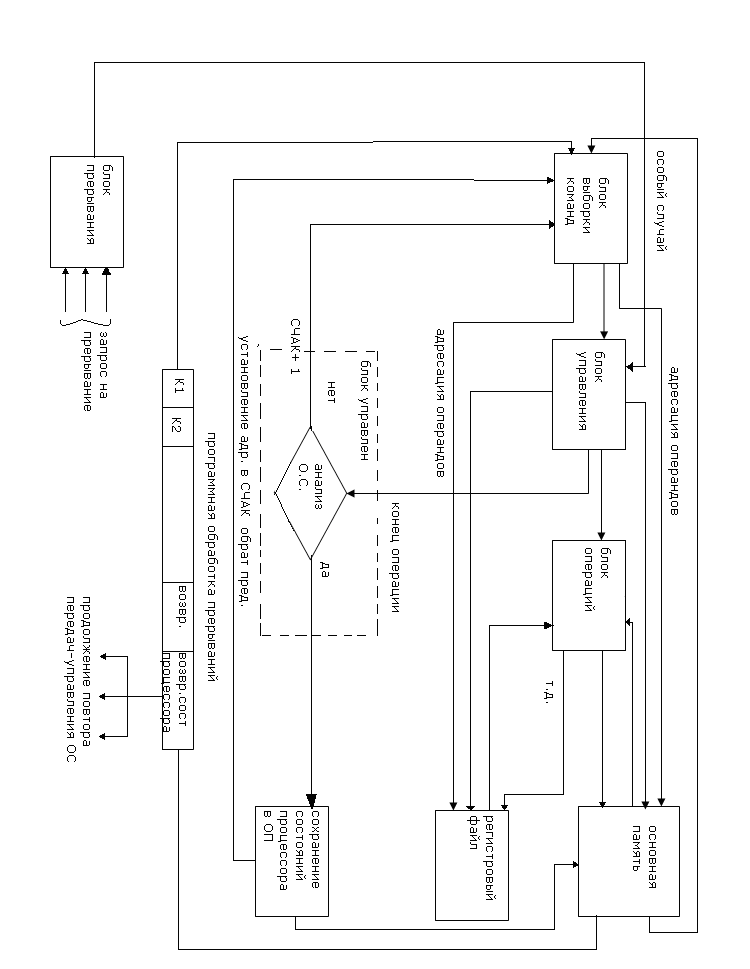
Для контроля выполнения команд в процессоре существует специальный узел, отвечающий за сбор информации о всех отклонениях и возмущениях ( прерываний ), нарушающих последовательное выполнение программы. Все эти ситуации классифицируются как особые случаи, и в случае их возникновения в процессоре происходят прерывания с сохранением его текущего состояния и порядком управления обработки прерывания, со сменой текущего адреса команд адресом первой команды в обработчике прерываний. По окончании обработки прерывания возможны различные продолжения с передачей управления прерванной программе, операционной системе, повтором выполнения команды, аварийной остановкой.
ЛЕКЦИЯ N 9
Тема лекции:
Состав и назначение основных блоков процессора.
Архитектура блока Тема выборки команд.
ВВЕДЕНИЕ
Как было отмечено ранее, хранение и продвижение данных потоков определяется двумя принципами ( Фон-Неймана и Гарвардской архитектурой), которые в современных архитектурах существуют совместно. В соответствии с наличием потоков команд и данных в состав процессора входят блоки , в функции которых заложены обработка и контроль за продвижением данной информации, независимо от выбранного принципа. Конечно же, в каждой архитектуре блоки эти имеют свои особенности, свои аппаратные решения, но основные функции их одни и те же. Такими блоками являются:
Блок выборки команд – продвижение, прием команды из процессора, обработка адресной информации, формирование адресов операндов и следующего адреса команды.
Блок операций – обработка данных, согласно алгоритму, определенному коду операции в команде.
Блок управления – координатор всех операций в процессоре при выполнении команды.
Рассматривая форматы команд и данных, обрабатываемых в процессоре, мы отметили, что их выбор и определяет архитектуру процессора как:
CISC – архитектура – набор сложных и простых команды реализующихся обычно за несколько тактов более 3-х или микропрограммой или группой микропрограмм
RISC – архитектура – набор простых команд реализующихся за один-два такта и имеющих формат регистр-регистр.
Процесс выполнения команды в процессоре может быть нарушен ситуацией возникающей при сбоях и отклонениях связанных особым случаем Данные нарушения контролируются специальным блоком прерывания. Архитектурно блок прерывания может располагаться как в кристалле так и отдельные его компоненты на системной плате ( контроллер прерывания 8252, и контроллер APIC).
Знакомство с архитектурой блоков, их функционированием мы начнем в той последовательности , в какой происходит обработка команды в процессоре.
БЛОК ВЫБОРКИ КОМАНД
При разработке архитектуры Б.В.К. необходимо учитывать следующие обстоятельства:
1) Процессор производит обмен информацией с памятью за один цикл группой байт, в которой количество байт определяется числом младших разрядов, не участвующих в адресации.
Команды в ОП могут располагаться внутри адресного пространства, начиная с любого байта, поэтому прежде чем активизировать декодеры, расшифровывающие поля команд, необходимо произвести поиск начального байта команды, и затем, в соответствии с форматом команды подключить соответствующий байт команды к соответствующему декодеру или направить их(поля) в соответствующие регистры(базы, смещения и т.д.). Различные архитектуры решают эту проблему в соответствии с форматом команд используемых ими.
В любом случае регистр адреса команды должен содержать все младшие разряды адреса, которые игнорируются при обращении ОП процессора за данными.
2) Для формирования адреса следующей команды необходимо знать кодировку длины команды, заложенную в формате команды. Для этого вышестоящий уровень архитектур машинных команд должен представлять эту информацию.
В системах с конвейерной организацией, осуществляющих запуск нескольких команд за один цикл Б.В.К. проделывает предварительную разметку пакета команд, поступающих на декодирование.
3)Б.В.К. должен содержать схему, контролирующую выполнение этапа декодирования ,а после его завершения осуществляет подачу другой команды на дешифратор, то есть осуществлять продвижение команд по буферу ,а в случае обнаружения свободного места достаточного для размещения новой порции командной информации организовать запрос с целью поиска необходимых данных на всех уровнях памяти согласно иерархии.
4)Современные системы работают с виртуальной памяти. Для этого аппаратные средства содержат блок трансляции логических адресов в физические. Адрес команды также подвергается этим преобразованиям при обращении к системной памяти, а вот содержимое регистров адресов команд -это эффективные адреса, то есть блок выборки команд в своих адресах отслеживает адреса команд в рамках страницы, поэтому в случае обнаружения выхода за рамки страницы в процессе модификации адресов Б.В.К. должен сформировать сигнал прерывания в процессоре.
При наличии буферной памяти команд для, того чтобы уменьшить вероятность промаха блок выборки команд(Б.В.К.) должен организовать своевременную загрузку следующих данных.Для этого каждый раз после подкачки команд из буферной памяти команд(Б.П.К.) в оконечный буфер не дожидаясь следующего обращения за командой в Б.П.К.,Б.В.К. осуществляет контроль за наличием следующих данных в Б.П.К. и при их отсутствии в памяти команд и при условии свободного места в оконечном буфере загружает данные в Б.П.К. и оконечный буфер, а при отсутствии места в оконечном буфере загружается только Б.П.К.
В компьютерах с конвейерной организацией причиной задержки конвейера является команда перехода, то есть конфликты связанные с этими командами относят к конфликтам по управлению. Методом решения этих конфликтов является аппаратные средства так называемые блоки предсказания переходов, которые формируют адрес следующей команды на основании статических и динамических данных ,о переходах в процессе выполнения команды.
Блок выборки в таких компьютерах сохраняет в своем составе основные блоки ,которые содержат Б,В.К. в процессоре с последовательным выполнением с одним существенным отличием. Это узел формирования адреса, обращения к КЭШ инструкции. Адрес этот формируется блоком предсказания переходов(Вranch taget buffer B.Т.В.), исходя из практики что % предсказания ≥90% , данная технология дает положительный результат.
Описание работы блока-выборки команд по структурной схеме.
На примере развития архитектуры блока выборки команд можно отчетливо проследить как две альтернативные идеи: фон-неймоновская и гарвардской архитектуры нашли свое применение в рамках одной и той же вычислительной системы, получив название «модифицированная гарвардская архитектура». На первоначальном этапе блок выборки команд представлялся счетчиком адреса очередной команды, отслеживающей выполнение команд (программа в процессоре). Источником для загрузки переданной команды для выполнения являлась оперативная память адреса, которая определялась регистром адреса команды ( IP ). Выполнение следующей команды, а точнее её выборка из памяти начиналась только после выполнения предыдущей. Повышение производительности вычислений за счет аппаратных средств привело к организации иерархической структуры памяти, а точнее к появлению КЭШ, и нескольким буферным регистрам для команд, дававшим возможность предварительной выборки из памяти очередной порции команд, ждущих выполнение в процессоре. Выборка команд по-прежнему осуществлялась по общей шине команд/данных, связывающих процессор-память, сохраняя классический принцип организации Фон-Неймана, но только с уменьшением количества запросов за командами в память, благодаря наличию буферных регистров для команд.
С другой стороны усложнение системы адресации данных для выполнения на первоначальном этапе, а именно базирования и индексирования привело к необходимости для вычисления адресов использовать основной сумматор блока арифметики. И только внедрение дополнительного оборудования «адресной арифметики» в структуру блока выборки команд позволило освободить основной сумматор и совместить в процессоре этап выполнения очередной команды с этапом подготовки следующей для выполнения, включающий в себя выборку из буферных регистров, декодирование, формирование адреса операндов для обращения в память. Но в такой архитектуре не был по-настоящему применен принцип гарвардской архитектуры, и только с появлением КЭШ команд, являющихся результатом идеи увеличения емкости буферных регистров, привело к появлению отдельной шины команд в структуре блока выборки команд и с адресной шины обращение к этой памяти. Но эта КЭШ команда была и остается не изолированной от системной шины данных/команд, связывающей процессор и память. Шина это по-прежнему остается основной магистралью заполнения командной информации КЭШ команд. кроме того она является поставщиком команд в блок выборки. Команда из основной памяти и КЭШ непосредственно поступают в буферные регистры блока в случае отсутствия (промаха) команд в КЭШ команд. Таким образом формируя модифицированную гарвардскую архитектуру характеризующуюся наличием связи шины команд и данных в случае необходимости. Таким элементом связи в структуре блока является КВД – коммутатор выдачи данных.
В связи с вышесказанным можно отметить, что БВК имеет основные источники для обработки команд:
А) системная память
Б) буферная память ( КЭШ данных и команд )
В) буферная память команд
Следует отметить, что в дальнейшем в архитектуре компьютера появилась и отдельная КЭШ данных. Таким образом увеличилась глубина проникновения принципов гарвардской архитектуры.
Б
А) Буферные регистры
Б) Схему контроля за продвижение команд в ней
В) Регистры для хранения адресов команд
Адресный узел блока выборки команд
Основное назначение адресного блока выборки команд - отслеживать текущее значение адреса выполняемой команды, его модификации в соответствии с длиной выполняемой команды.
При наличии буферных регистров и кэш памяти команд, адресный узел имеет достаточно сложную структуру в функциональные обязанности входят:
а) формирование адреса обращения за командой в кэш команд
б) формирование значения адреса при обращении за командой в буферную или системную память с учетом свободного места в буфере FIFO на момент запроса
в) сохранение логического адреса обращения за командой в память вышестоящего уровня (кэш или системную память) и возвращение его в адресный тракт при загрузке команд из нее.
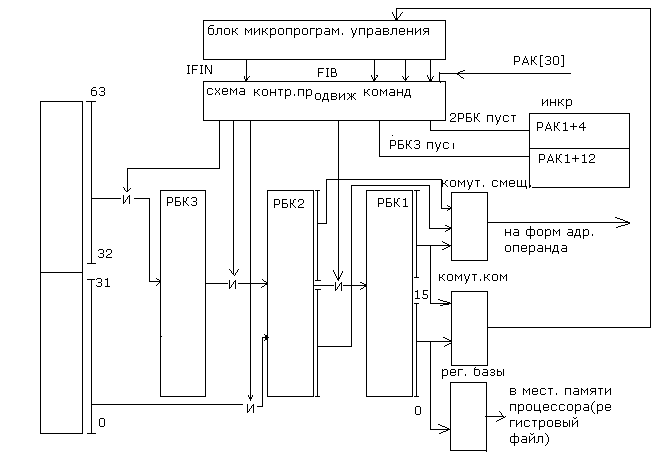
Как видно из схемы адресный тракт содержит два регистра команд, один из которых исполнительный, то есть выходы разрядов которого подаются на схемы модификации для формирования адресов обращения за командами в кэш команд, системную или буферную память. Это регистр РАК1.
РАК1 – отслеживает текущий адрес команды. Текущий адрес команды формируется схемой модификации управляемой кодом шины предыдущей команды.
Код длины кодируется в разных системах по-разному, в частности для IBM этот код длины укладывается в коде операций и для этой архитектуры схема выглядит следующим образом:
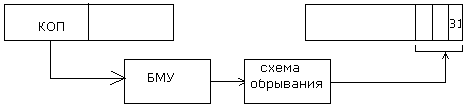
Схема обновления
Как видим из блока схемы выход РАК1 поступает на две схемы формирования адреса запроса для загрузки очередной порции команд в буферные регистры:
А) запрос к ОП (системная память, участвуют все разряды адреса команды) формируется с использованием схем коррекции ИКР+4 и ИКР+8 которые
управляются блоком микропрограммного управления и схемой контроля за продвижением команд в буфере FIFO, фиксирующей наличие свободных мест в буфере.
Схема модификации ИКР+8 активизируется при наличии признака свободного регистра РБК3, используется только при обращении за командами в оперативную или буферную память. Значение модифицированного адреса команды подается на вход блока преобразования логического адреса в физический и возвращается в адресный тракт при получении команды из памяти.
Схема модификации ИКР+4 используется при выполнении цикла запроса в оперативную или буферную память в случае отсутствия команд в кэш команд и при наличии двух свободных регистров в FIFO указывая при этом что команды будут загружены в FIFO и кэш команд.
Эта схема также используется при загрузке модифицированного адреса в регистр РАК2 с той целью чтобы в случае двух свободных регистров РБК3 и РБК2 и обнаружении данных в кэш памяти команд указать на адрес команды, которая будет загружена из кэш команд в РБК2 и в следующем такте продвижения команд в буфере будет передана в РБК1 для выполнения в процессоре.
Значение РАК2 в этом же такте будет передано в РАК1.
Б) к буферу памяти команд (КЭШ команд, участвуют младшие разряды адреса команды, определяющие размер буферной памяти: старшая часть адреса используется как тег в теговой памяти на схеме не показанной)
Для этой цели используется схема ИКР+12, модификация производится каждый раз при запросе за командами в кэш команд, независимо от того есть ли свободные места в буфере. Запрос этот формируется для анализа наличия команд в памяти команд: если команды есть в памяти ,то они считываются и заносятся в буфер
при условии свободного места (два регистра должны быть свободны) в противном случае загрузка команд из кэш команд не производится.
.
Адресный регистр РАК2 предназначен для:
А) хранения адреса переданной команды в случае признака 2РБК – пустые и признака дан доступ в КЭШ. используется, как сказано выше для фиксации адреса команды загружаемой из кэш команд.
РАК2=РАК1+4 указывает на то, что в РБК1 еще находятся команды или команда в зависимости от формата на выполнении.
Б) для хранения адреса первой команды загружаемой из ОП или БП при первоначальной загрузке.
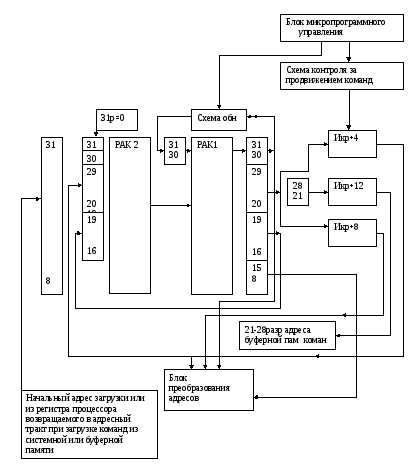
Организация индексной памяти кэш команд
Первой попыткой сокращения числа циклов обращения за командами в процессоре, как упоминалось ранее, было внедрение буферных регистров для хранения команд ,ожидающих выполнения.
Дальнейшее усовершенствование этого механизма привело к внедрению буферной памяти команд при этом необходимо было, чтобы кэш память команд могла бы способствовать максимальной автономности функционирования блока выборки команд, а это можно сделать только при условии организации отдельного адресного тракта обращения за командами в процессор то есть вернуться к забытым принципам гарвардской архитектуры.
Но с другой стороны к этому времени фон-неймановская архитектура имела мощную базу программно-аппаратного комплекса.
И решение было найдено в реализации так называемой модифицированной гарвардской архитектуры, о которой также неоднократно говорилось.
В этой архитектуре интерфейс процессор- системная память остается фон-неймановский то есть общая шина команд/данных.
В процессоре два независимых друг от друга информационных тракта команд и данных.
Препятствием для реализации этой идеи стал блок преобразования логических адресов в физические, являющегося аппаратной частью механизма виртуальной памяти , а следовательно, чтобы организовать максимальную автономность каждого тракта нужно было “разрезать” блок на две части, каждая из которых занимается преобразованиями своих адресов. Именно такой механизм функционирует ,например, в POWER4 ,который мы рассмотрим позже.
Такое решение преемственно при наличии кэш команд и данных. Эта архитектура появилась позже, а на первом этапе вопрос стоял об организации только кэш команд и дублировать работу механизмам преобразования адресов, результаты которого уже использовались в общей кэш для команд и данных, не имело смысла.
А значит, нужно было максимально использовать результаты функционирования блока преобразований логических адресов при обращении в общую память команд и данных. В качестве теговой информации в индексной памяти кэш команд использовать физический адрес станицы,, который является результатом преобразований в блоке преобразования логических адресов в физические, и данные этой страницы уже находятся в обшей кэш и они достоверны.
И вот почему. Алгоритм преобразования логических адресов в физические предполагает, что в результате преобразования физический логический адреса будут иметь в группе младших разрядов одно и то же значение, которое определяет смещение начального байта искомой информации в границах страницы.
Следовательно, если выбрать размер адресного поля для кэш команд равный размеру страницы, то тогда индексная часть адреса будет определять физический адрес страницы в памяти и необходимость ввода дополнительного буфера TLB отпадет, потому что содержимое ячеек TLB, которые хранят физические адреса страниц, будет хранится в индексной памяти кэш команд.
Что же касается размера кэш, то он может быть и меньше размера страницы в этом случае старшие разряды адресного поля кэш команд переходят в теговую часть.
Возможно и увеличение размера кэш , тогда не меняя размера полей можно использовать наборно-ассоциативную кэш, в которой адресная часть будет определять набор.
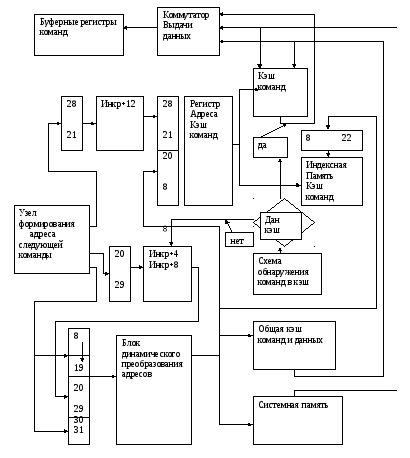

Схема управления продвижения команд в буферных регистрах осуществляет продвижение команд на основе информации полученной из блока микропрограммы управления ( микрооперация IFTN).
Схема и в целом блок БВК работают следующим образом. Для управления БВК в микропрограмме реализующей выполнение команды вводятся следующие микроприказы.
А) микроприказ IFTN, по которому происходит продвижение команды по конвейеру, анализ наличия свободных буферов, модификация адреса команды. Анализ наличия команд в БПК и их загрузка из БПК в РБК при двух пустых буферных регистрах.
Б) микрооперация FIB, организующая запрос за командой в КЭШ данных или системную память в случае отсутствия в КЭШ памяти команд.
Эти две микрооперации размещены в следующем порядке
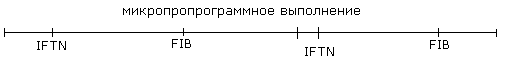
Формирование значения адреса следующей команды определяется не только зависимостью от длины предыдущей, этот алгоритм работает на линейном участке программы. Как известно, существуют команды переходов и особые случаи возникающие в процессе выполнения команд и механизм прерываний в процессоре. Поэтому блок выборки команд имеет дополнительный тракт формирования адреса команды перехода.
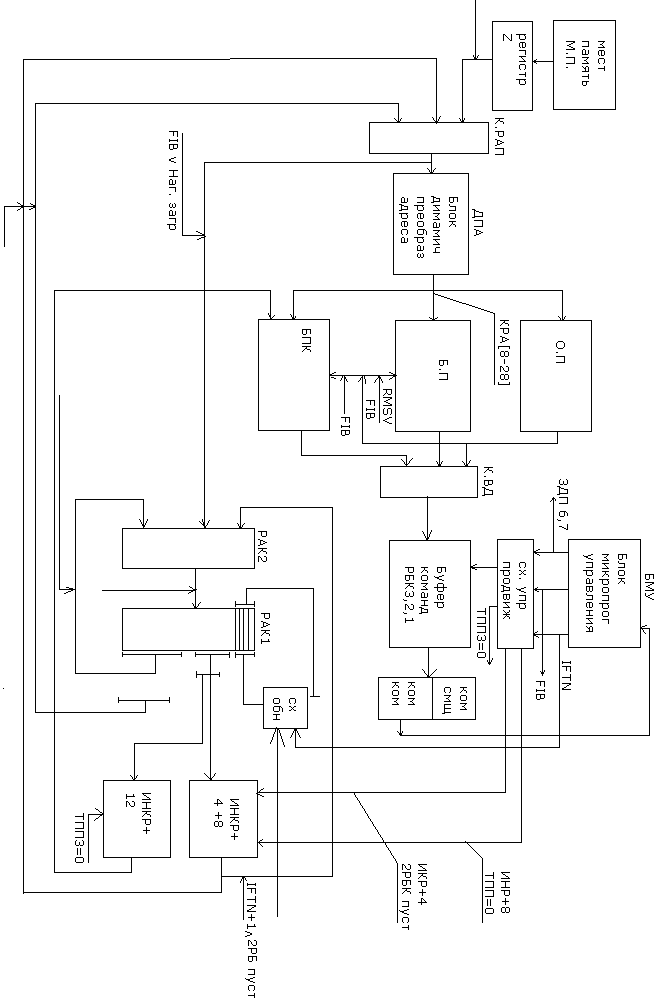
В представленной блок схеме таким трактом является тракт загрузки регистра РАК2 из процессора через его регистр RZ и местной памяти.
На схеме представлена архитектура буферных регистров блока выборки команд.
Загрузка команд производится через коммутатор, на входы которого заведены разряды шины команд/данных процессора. Прием в буферные регистры ,как видно из схемы, происходит под управлением блока микропрограммного управления в специальных микрооперациях. Сдвиг команд в сторону дешифраторов осуществляет схема , управляемая также блоком микропрограммного управления: она же и определяет наличие свободного места в буфере, корректируя адрес для запроса в память за очередной порцией команд.
Код операции в зависимости от расположения команды в буферных регистрах из за различной длины команд поступает на коммутатор из первой или второй половины буферного регистра РБК1. По той же причине на вход коммутатора смещения подаются разные группы разрядов регистров РБК1и РБК2.
Значения адреса базовых и индексных регистров подаются в местную память процессора, откуда соответствующие значения базы и индекса поступают на адресный сумматор.
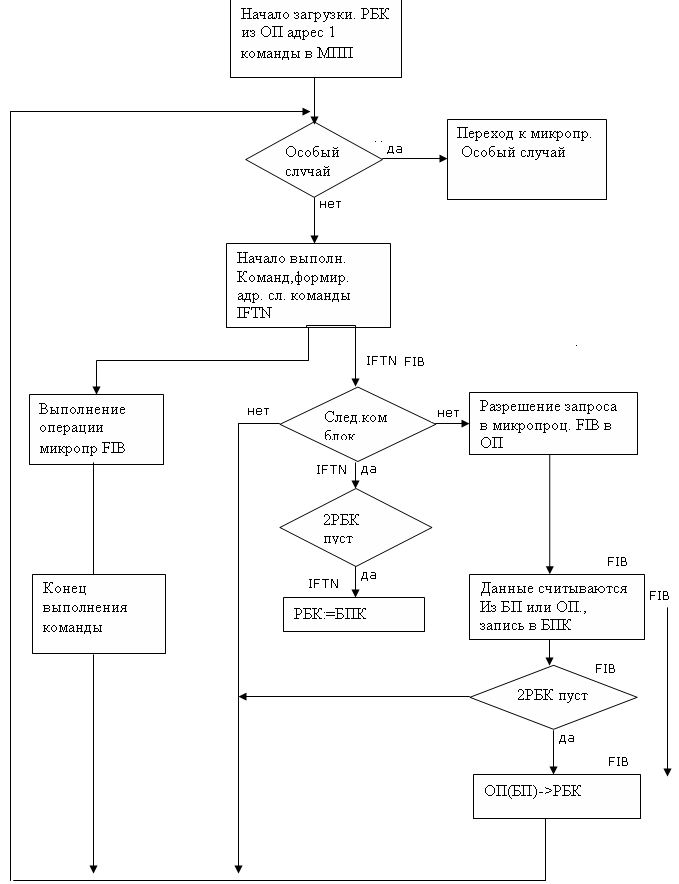
След.ком. БПК
БЛОК ВЫБОРКИ КОМАНД POWER4.
Прежде чем рассматривать архитектуру блока выборки команд POWER 4 необходимо отметь следующее:
POWER4 является суперскалярным процессором с конвейерной организацией обработки команд. Как мы увидим далее, при рассмотрении технологии конвейерной обработки команд в процессоре возникают конфликты по управлению, связанные с выполнением команд переходов.
Для уменьшения времени простоя конвейера используется технология предсказания переходов то есть вероятностный метод продвижения команд по конвейеру .Не вдаваясь в подробности функционирования механизма логики предсказания переходов, который мы рассмотрим позже, отметим только то , что загрузка очередной порции команд в кэш инструкций из вышестоящего уровня иерархии памяти происходит по адресу, сформированному этой логикой (блоком предсказания переходов)
Так как адреса обращения за командами являются логическими при использовании виртуальной памяти и требуется их преобразование в физические, то для сокращения числа обращений к блоку преобразования адресов, используются буфера быстрой переадресации (TLB) , в которых хранятся значения адресов логических страниц и соответствующих им физические адреса , вычисленные ранее при первом обращении в память по выше упомянутым логическим адресам этих страниц.
Но в отличии от кэш данных механизм обнаружения команд в кэш инструкций и использование буферов быстрой переадресации намного сложнее и это в первую очередь связано с использованием вероятностного метода выбора инструкций из кэш.
Если при загрузке строки данных в кэш промах в дальнейшем при обращении к данным этой строки может возникнуть при изменении их самим процессором или другим агентом системы (многопроцессорные системы) , то при загрузке строки команд в кэш инструкций нет ни какой гарантии, что все команды в этой строке будут выполнены полностью, прежде чем будет загружена другая порция команд в кэш инструкций (из за команд переходов).
Уменьшить вероятность промаха можно уменьшением размера строки ,загружаемой в кэш инструкций, но при этом возрастает размер буфера переадресации.
Большой же размер строки приводит к увеличению числа команд переходов и усложняет логику предсказаний и снижает вероятность правильности предсказания ,поэтому был выбран компромиссный вариант –выбирать строку большого размера ,а анализ предсказания переходов осуществлять по секторам строки ,на которые она делиться. При чем РАЗМЕР СЕКТОРА выбрать равным буферу , в который читаются команды из кэш инструкций для выполнения в процессоре. Но для этого пришлось вводить не один буфер TLB а два, потому что первый хранит физические адреса строк находящихся в кэш в соответствии с логическими адресами обращения за командами .а второй буфер осуществляет контроль за продвижением команд внутри строки каждый раз при загрузке очередного сектора из кэш инструкций в буферные регистры путем сравнения физических адресов из обоих буферов
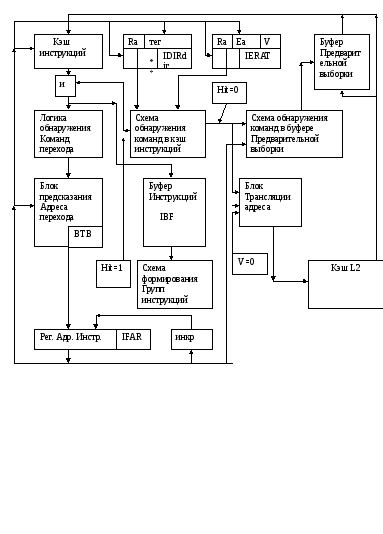
Инструкция выбирается из КЭШ инструкций по значению адреса IFAR- Instr.fetch address reg.
Обычно IFAR загружается согласно логике предсказания перехода.
В случае ошибочного предсказания ,необходимо будет произвести корректировку значения IFAR, чтобы продолжить выполнение потока инструкций в нужном направлении. Кроме этого изменение потока инструкций может быть вызвано прерыванием от внешних событий, в любом случае, как только в IFAR будет загружен адрес команды, то до восьми инструкций поступает на конвейер в каждом цикле.
Каждая строка в КЭШ инструкция составляет 128 байт, которая разделена на 4 эквивалентных сектора по 32 байта, которые определяют ширину данных записи/ считывания в цикле работы кэш памяти команд.
В архитектуре Power взят буфер Т LB( translate looksid buffer) и SLB – (Segment looksid buffer) для преобразования эффективного адреса в реальный. Power4 содержит 4 буфера трансляции (по два на каждый процессор в двух ядерной архитектуре то есть на каждый процессор приходится кэш команд и кэш данных).
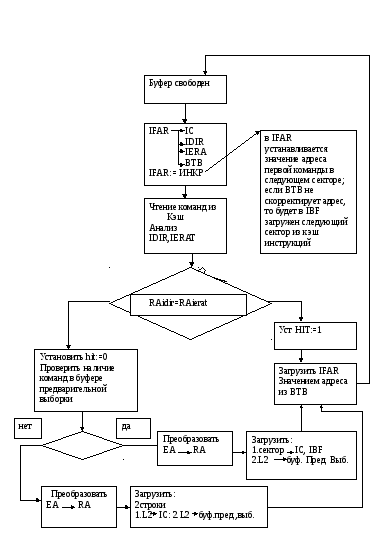
Когда конвейер инструкций готов получать инструкцию, содержимое IFAR посылается в полностью ассоциативный буфер IDIR(Instr. Directory), который адресуется частью эффективного адреса, другая часть которого используется как тег . Кроме этого теговая строка содержит 42 бита реального адреса, содержащие два полных физических адреса строк, переписанных из кэш L2 в кэш инструкций и находящихся в ней на данный момент. Так как размер кэш L2 составляет 1,5 МГБ, то для фиксации адресов двух строк из кэшL2 в кэш инструкций нужны эти 42 разряда. В блоке выборки команд имеется еще таблица переадресации IERAT , которая имеет такую же архитектуру как и выше упомянутый буфер с той лишь разницей , что в теговой строке содержится физический адрес-результат преобразования логического адреса. Содержимое этих двух буферных таблиц и является исходной информацией для определения наличия команд в кэш инструкций.
И так содержимое регистра адреса выборки инструкций ,обновляется принимая значение адреса первой инструкции в следующем секторе, после того как он будет передан в кэш инструкций , выше упомянутые таблицы и в блок предсказания где сформируется адрес команды, по которому возможно пой дет выполнение программы, если по данному адресу логика обнаружения команд перехода зафиксирует таковую или по другим адресам в считанном секторе в случае его нахождения в кэш инструкций . Если в считанном секторе не будет обнаружен факт перехода и все команды в секторе будут выполняться последовательно, то в буфер инструкций будет загружен следующий сектор. А сейчас вернемся к началу цикла выборки инструкций из кэш и рассмотрим подробнее механизм обнаружения их в памяти .
И так по значению в IFAR считывается значение реального адреса из “IDIR” эффективный и реальный адреса из таблицы IERAT.
IERAT (содержит эффективный и соответствующий ему реальные адреса) проверяется с тем чтобы проверить достоверность входа и чтобы реальный адрес сравнить со значением IDIR. Если в таблице IERAT установлен флаг INVALID, то
EA должен быть транслирован из TLB и SLB. Выбранная инструкция «пузырится». Если IERAT VALID, RAIPIR=RAIER устанавливая Icahehit i=1, разрешает продвижение конвейера и работу блока предсказаний и IFAR вновь устанавливается в соответствии с индикатором ВТВ. Активизируются декодеры, начинается формирование групп, логика разрешает выбранным инструкциям продвигаться по конвейеру.
ЕСЛИ обнаружен промах, возможны несколько сценариев:
1) буфер предвыборки проверяется есть ли в нем затребованная инструкция, и если да, логика продвигает эти инструкции к конвейеру: как если бы они были выбраны из КЭШа и записывает также критический сектор в КЭШ.
2) Если инструкции нет в буфере, формируются два последовательных запроса к КЭШ уровня L2. L2 обрабатываются, в результате чего будет произведена запись в кэш инструкций и в буфер предвыборки .
В случае присутствия затребованной инструкции в буфере предвыборки, организуется запрос в кэш L2 за очередной строкой.
В дополнение к механизму выборки инструкции по затребованным запросам БВК осуществляет выборку инструкций, которые в скором времени будет затребована для выполнения.
ЛЕКЦИЯ N10
Тема лекции: Процессор.
Блок управления.