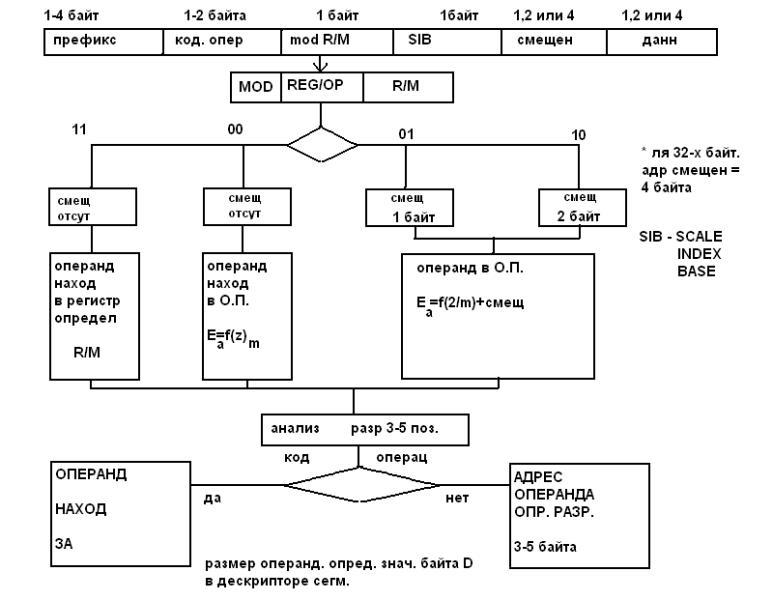
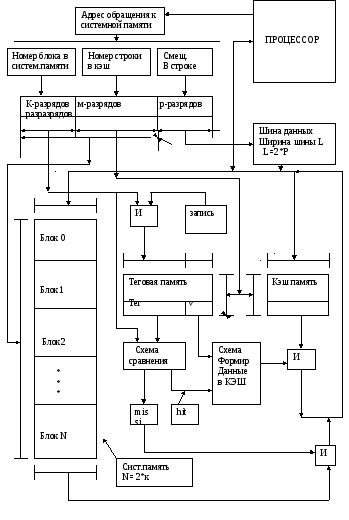
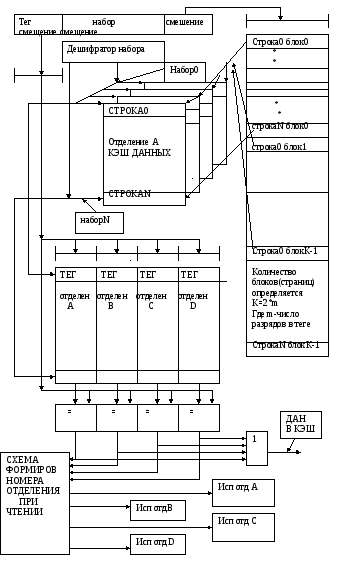
Полностью ассоциативная кэш.
Этот тип КЭШ в своей тэговой части содержит полный физический адрес требуемых данных, однозначно определяющий их место в системной памяти. Поэтому в КЭШ такой архитектуры содержимое любой ячейки системной памяти может быть помещено в любую ячейку КЭШ.
Но с другой стороны схема поиска о наличии данных в таком КЭШ является сложной, так как требует одновременного анализа всех ячеек тэговой части.
Если для малого количества ячеек удается такую схему реализовать, то для большого объема это требует больших аппаратных издержек, то в конечном счёте применение такой архитектуры является нецелесообразным.
БЛОК-СХЕМА
Как видно из блок схемы в режиме чтения текущий адрес данных подается на схемы сравнения, количество которых определяется количеством ячеек в КЭШ. На другой вход схем сравнения поступают значения адресов (тэги записанные в каждую из ячеек теговой части в процессе записи в КЭШ).
Та схема сравнения, которая обнаружит совпадения
![]()
формирует сигнал, разрешающий выдачу данных из соответствующей ячейки накопительного блока.
Говоря о структуре содержимого ячеек теговой памяти, необходимо отметить, что данные в КЭШ используются не только для чтения но и для их изменения в процессе обработки в процессоре.
Возникает вопрос: «Что делать с такими данными?»
Записывать ли их в КЭШ обратно после обработки или отправлять в системную память, тогда что делать с исходной копией которая подверглась изменению и находтся в КЭШ.
Если эти изменённые данные являются промежуточным результатом и используются для дальнейших вычислений, то их можно записать в КЭШ и только получив конечный результат можно отправить в системную память.
Как долго измененные данные могут находится в КЭШ? Это время тоже является очень важным по той же причине, что в системе кроме процессора обычно присутствуют другие агенты, имеющие прямой доступ к памяти (контроллер жёсткого диска).
Даже эти вопросы обнажают проблемы, которые необходимо решать при вводе КЭШ в систему.
Отсюда вывод:
Для решения всех этих задач, которые связанны с так называемой когерентностью КЭШ и системной памяти, наличие только адреса данных в тэговой части НЕДОСТАТОЧНО. Необходима дополнительная информация отображающая состояние данных в системе (КЭШ) (биты достоверности).
.
. .
Адрес, который формируется в формате
команды
процессор
(регистровая память)


КЭШ память
Блок преобразования
логического адреса в реальный
блок формирования
адреса операции
блок формирования
адреса команды
Внешняя память
канал ввода\вывода
ПДП- прямой доступ
памяти





















системная память

ЛЕКЦИЯ N7
КЭШ-память прямого отображения.
В основу построения КЭШ прямого отображения положен следующий принцип:
Общее пространство оперативной памяти разбивается на равные блоки, размер которых равен размеру КЭШ памяти.
КЭШ память кроме накопительного блока имеет блок хранения тэгов, являющихся признаком наличия запрашиваемых данных в КЭШ.
Размер тэговой памяти равен размеру накопительного блока как в КЭШ полностью ассоциативный. В качестве тэга используется старшие разряды адреса памяти, которые по сути являются номером одного из блоков, на которые разбита основная память. Средняя часть адреса используется для адресации КЭШ и тэговой памяти и определяет адрес строки (страницы, слова) в КЭШ. Младшая часть адреса, не участвующая в выборке строки из кэш количеством своих разрядов определяет ширину выборки из памяти а своим значением смещение то есть место положение первого считываемого или записываемого байта в строке
При такой
архитектуре в КЭШ прямого отображения
на каждую строку в КЭШ будет претендовать
количество строк из основной памяти
равное количеству блоков, на которое
разбита основная память, т.е ![]() -
где k- количество разрядов тэга.
-
где k- количество разрядов тэга.
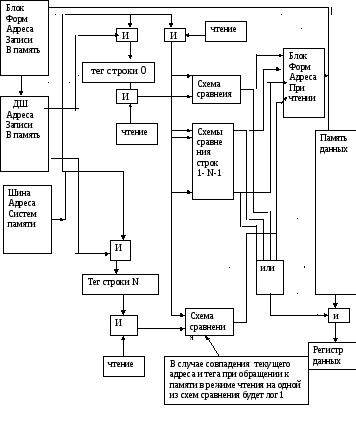
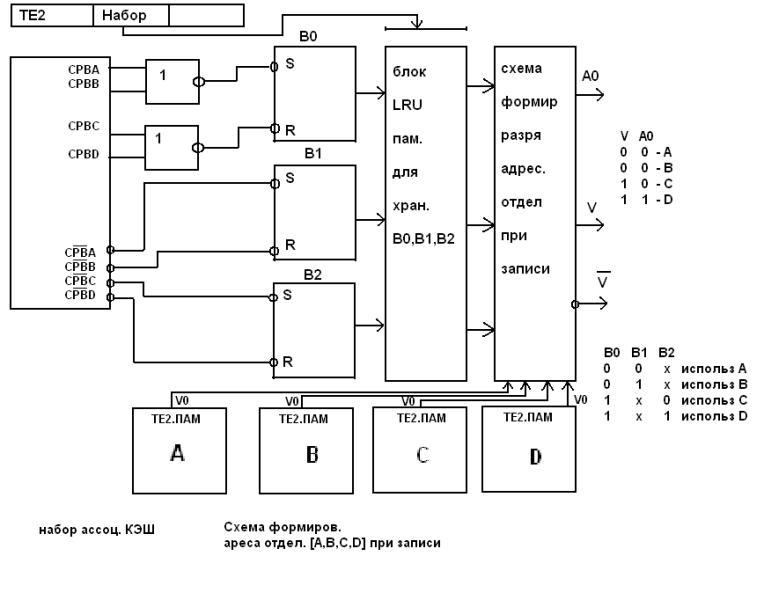
КРАТКОЕ ОПИСАНИЕ РАБОТЫ КЭШ ПРЯМОГО ОТОБРОЖЕНИЯ ПО БЛОК_СХЕМЕ
При обращении к памяти за данными процессор выставляет адрес на шину адреса .Как было сказано выше и видно из схемы разряды адреса разделены на три группы, о назначении которых мы уже говорили, и используются в соответствующих функциональных блоках кэш, а именно, старшая часть как данные или тег для теговой памяти, записываемые в нее при загрузке данных в кэш и считываемые из нее каждый раз в начале любого цикла обращения к системной памяти независимо от того будет это цикл записи или чтения.
Средняя часть , адресом теговой памяти и кэш подается напрямую на адресные входы памятей без каких либо сигналов управления . Младшая часть адреса ,как видно на блок – схеме определяет ширину выборки данных и для данной архитектуры ширина шины данных основной памяти и кэш совпадают. В случае, если размер строки в кэш не совпадает и больше ширины выборки из основной памяти то он должен быть ей кратным целому числу чтобы обеспечить полноценный обмен между кэш и основной памятью.
Как только значение адреса фиксируетя на шине адреса с задержкой, определяемой логикой работы схемы сравнения и временем счиывания из теговой памяти формируется сигнал “miss”(промах) или “hit”(совпадение) и с учетом бита достоверности (V=1) определяется нахождение данных в кэш. Если данные в кэш, то соответствующий сигнал разрешает выдачу данных из кэш на шину данных. Если данные в кэш отсуствуют, то формируется запрос к системной памяти и данные считываются из нее в режиме чтения.
Если “ данные в кэш” формируется при записи ,то это значит что процессор брал данные из кэш изменил их и обязан записать их в кэш установив при этом бит V:=0 (грязный) в том случае ,если цикл записи в основную память будет произведен с задержкой(политика обратной записи). Если запись в основную память следует без задержки, то контроллер кэш оставляет бит V в единице,(политика прямой записи) таким образом отслеживая когерентность данных в основной памяти и кэш.

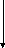



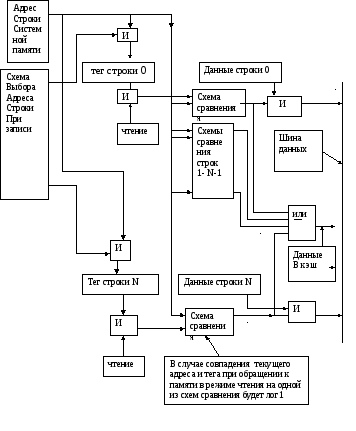
Наборно-ассоциативная КЭШ состоит, как и КЭШ прямого отображения, из накопительного блока и тэгового.
Накопительный блок состоит из четырёх отделений А, В, С, D. (четырёх канальная КЭШ).
Обращение к каждому отделению (адрес) формируется из двух частей:
a) адрес строки внутри отделения (набор).
б) адрес номера отделения.
В представленной архитектуре адрес номера отделения (2 разряда) представляются двумя старшими разрядами КЭШ, которые формируются контроллером кэш и не входят в разрядную сетку адресной шины
отделения А 0 0 XXXXX
B 0 1 X X X X X
C 1 0 X X X X X
D1 1 X X X X X
т.е. набор представлен как подмножество из 4-ех одноимённых (имеющих одни и те же значения адреса строк в отделениях) строк в отделениях.
Формирование адреса отделения формируется по разному в зависимости от операции (чтение или запись)
Как видно из блок схемы, выбор отделения при чтении, осуществляется по сигналам CPBA, CPBB, CPBC, CPBD, однозначно его определяющие.
В режиме записи алгоритм сложнее, как видно из схемы, в блок формирования адресов номера отделения поступают 3 группы сигналов.
a) CPBA, CPBB, CPBC, CPBD
б)
![]() ,
,
![]() ,
,
![]() ,
,
![]()
в) биты отслеживающие
обращение в отделение КЭШ
![]() ,
,
![]() ,
,
![]()
в соответствии с порядком перечисленным выше эти группы сигналов в таком приоритете участвуют в формировании адресов отделения .
1.При формировании одного из сигналов сравнения то есть hit=1 выбор отделения осуществляется по соответствующему сигналу сравнения.
2. В случае отсутствия
сигнала «hit»
запись осуществляется после проверки
бит ) ![]() ,
,
![]() ,
,
![]() ,
,
![]() ;
в случае обнаружения
;
в случае обнаружения ![]() =0
в одном из отделений, запись осуществляется
в этот отделение.
=0
в одном из отделений, запись осуществляется
в этот отделение.
Если ![]() =
=
![]() =
=
![]() =
=
![]() =1,
то в действие вступает алгоритм LPU,
на основании которого формируется номер
отделения, к которому не было в обращения
в предыдущих 2-ух циклах выборки из КЭШ.
=1,
то в действие вступает алгоритм LPU,
на основании которого формируется номер
отделения, к которому не было в обращения
в предыдущих 2-ух циклах выборки из КЭШ.
Схема обновления
битов ![]() ,
,
![]() ,
,
![]() контролирует все обращения при чтении
устанавливая их и сбрасывая в 0 в
соответствии с алгоритмом, и каждый раз
по окончании цикла чтения записывает
их обновлённые значения в блок памяти
LPU.
контролирует все обращения при чтении
устанавливая их и сбрасывая в 0 в
соответствии с алгоритмом, и каждый раз
по окончании цикла чтения записывает
их обновлённые значения в блок памяти
LPU.
Что касается
содержимого тэговой памяти ясно, что
кроме значения тэгов (старшей части
адреса) в строках тэгов памяти хранятся
биты достоверности и значения ![]() ,
,
![]() ,
,
![]() .
.
И так в основе архитектуры наборно-ассоциативной кэш используется тот же принцип построения как в КЭШ прямого отображения с той лишь разницей, что в архитектуре наборно-ассоциативной КЭШ вводятся элементы ассоциативного характере при доступе к данным.
Структуру такой КЭШ можно представить как КЭШ с размером строк в несколько раз больше чем ширина выборки из основной памяти и определяемое числом отделений в КЭШ, но размер строки скрыт от системы и адресуется как в кэш прямого отображения, таким образом являясь собственностью контроллера кэш и поэтому строку в ней называют набором. Контроллер имея в своем распоряжении набор размещает в нем данные согласно выше указанному алгоритму, а при чтении из кэш осуществляет поиск данных подобно как это реализуется в ассоциативной кэш ,обращаясь в одном такте одновременно к теговым памятям отделений.
Возможность произвольного размещения строки в границах набора позволяет частично устранить недостатки, связанные с четким расположением строк в КЭШ прямого отображения и содержать в строках набора группу строк из разных страниц.
Запись ,как мы уже говорили, строки набора происходит по выбранному алгоритму, реализованному в контроллере КЭШ, и, как наиболее часто используемых в таких системах, известен как механизм LPU. Суть которого заключается в том, что при записи используется строка к которой дольше всего не было обращения.
Least Recently Used
Например, для того, чтобы производить анализ количества обращений в КЭШ с 4 отделениями и выделить строку к которой подряд 2 раза не было обращения достаточно 3 разрядов (триггеров).
![]() -
триггер (бит) фиксирующий обращение к
паре отделений из 2-ух возможных.
-
триггер (бит) фиксирующий обращение к
паре отделений из 2-ух возможных.
![]() -
Фиксированное
обращение к отделениям в 1-ой паре.
-
Фиксированное
обращение к отделениям в 1-ой паре.
![]() -
фиксированное
обращение к отделениям во 2-ой паре.
-
фиксированное
обращение к отделениям во 2-ой паре.
Схема формирования
![]() ,
,![]() ,
,![]()
Установка
триггеров ![]() ,
,![]() ,
,![]() ясна из самой
схемы. Значение разрядов номера отделения
формируются на значениях
ясна из самой
схемы. Значение разрядов номера отделения
формируются на значениях ![]() ,
,![]() ,
,![]() из памяти
LPU
на основе таблиц указанных на схеме.
Значения эти используются в случае,
если значения битов достоверности во
всех отделениях тэговой памяти имеют
из памяти
LPU
на основе таблиц указанных на схеме.
Значения эти используются в случае,
если значения битов достоверности во
всех отделениях тэговой памяти имеют
![]() =
=
![]() =
=
![]() =
=
![]() =1
=1
Если в каком либо отделении бит достоверности будет равен 0, то данные безусловно будут записаны в это отделение.
Схема установки (сброса) ![]() ,
,![]() ,
,![]()
C
S
R
 PBA
PBA![]() CPBB
CPBB
C
S
R S
R
 PBC
PBC![]() CPBD
CPBD
CPBA
C PBB
PBB
C PBC
PBC
CPBD
Для того чтобы понять как работает механизм LRU рассмотрим все возможные комбинации триггеров B0,B1,B2 и соответствующие им обращения к отделениям.
Анализируя полученные варианты, можно заметить ,что при отсутствии обращения к отделению A состояние триггера B2 может принимать как 0 так и 1,а состояния триггеров B0 и B1 “10”соответственно.
При отсутствии обращения к отделению B триггера B0 B 1 находятся в 1, а состояние B2 безразлично.
Если не было обращений к отделению C, то B0 иB2 имеют нулевые состояния, а состояние B1 безразлично.
При отсуствии двух обращений к отделению D B0 в нулевом состоянии, B2 в единичном, а B1 в безразличном.
Обращение B0 обращение B1 обращение B2 не было к
AvB 0 B 0 D 0 C
AvB 0 B 0 C 1 D
AVB 0 A 1 D 0 C
AVB 0 A 1 C 1 D
CVD 1 B 0 D 0 A
CVD 1 B 0 C 1 A
CVD 1 A 1 D 0 B
CVD 1 A 1 C 1 B
Результирующая таблица
1 1 х запись в B
1 0 x запись в A
0 x 0 запись в C
0 x 1 запись в D
корректировка
B0,
B1,
B2.
И запись в блок хранения




ЛЕКЦИЯ N8
Тема лекции:
Процессор. Назначение, классификация архитектур процессоров по управлению потоками команд и данных, их хранению и по набору выполняемых команд.
Структура и форматы обрабатываемых команд и данных в процессоре. Последовательность выполнения команды в процессоре.
Процессоры – центральная часть, ядро ЭВМ, предназначенная для реализации алгоритма, заложенного в программе, аппаратными средствами.
Процессор состоит из совокупности блоков, каждый из которых отвечает за определенный этап процесса обработки информации.
Совокупность этапов связанных с обработкой одной команды называется шагом работы процессора или командным циклом.
3) Командный цикл, делящийся на более мелкие этапы работы процессора, называется машинным циклом, который в свою очередь делится на машинные такты.
|
Командный цикл | ||||||||
|
Машинный цикл |
Машинный цикл |
Машинный цикл | ||||||
|
T1 |
T2 |
T3 |
T1 |
T2 |
T3 |
T1 |
T2 |
T3 |
Такое деление характерно для микроконтроллеров и микропроцессоров то есть для процессоров имеющих архитектуру блока управления с «жесткой логикой».
Для архитектур процессоров с микропрограммным управлением используют понятие как микропрограмма, микрокоманда, микрооперация. По сути эти понятия не эквивалентны выше указанным.
Микропрограмма или группа микропрограмм формируют командный цикл
Микрокоманда это группа микроопераций или одна микрооперация – по времени соответствует действию в процессоре в течении машинного такта.
4) Первоначально в процессоре существовало два потока информации: команды и данные, обрабатываемые процессором в этой команде , в дальнейшем с внедрением систем диагностирования и восстановления работоспособности процессора за счет средств резервирования стали внедрятся в архитектуру процессора блоки контроля, диагностики, восстановления и соответствующие им информационные и управляющие тракты.
Хранение продвижение потоков команд и данных определяется двумя принципами ( Фон-Неймана и Гарвардской архитектурой), которые в современных архитектурах существуют совместно. В соответствии с наличием потоков команд и данных в процессоре существуют блоки занимающиеся обработкой и контролем продвижения данной информации.
Но прежде чем начать говорить о назначении и составе этих блоков в процессоре остановимся подробнее на реализации вышеупомянутых принципах подробнее.
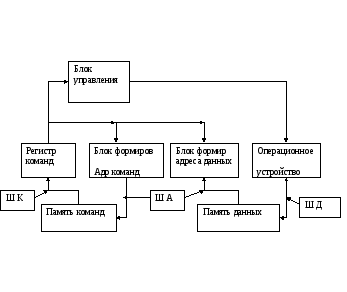
Блок-схема архитектуры Фон-Неймана.
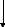

Комментарий к блок-схеме архитектуры Фон-Неймана
Наличие жестко заданного набора исполняющих команд и программ было характерно для первых компьютеров, которые конструировались, как теперь принято называть, по Гарвардской архитектуре.
Отличие архитектуры Фон-Неймана заключается в принципиальной возможности работы над управляющей программой точно так же, как и над данными. И для этого необходимо, чтобы программа и данные находились в одной физической памяти или , по-другому, был реализован принцип совместного хранения программ и данных в памяти ЭВМ. Эта особенность архитектуры позволяет наиболее гибко управлять работой вычислительной системы, но имеет недостаток – возможность искажения управляющей программы, что понижает надежность работы системы. Для уменьшения этого используются в данной архитектуре различные механизмы защиты областей памяти.
Как видно из блок-схемы, процессор связан шинами адреса, команд/данных. Для разделения потока команд и данных внутри процессора используются (в зависимости от архитектуры) как аппаратные, так и микропрограммные средства, реализующие специальные циклы (такты) работы процессора, фиксирующие запросы в оперативную память за командой или данными.
Модернизация архитектуры Фон-Неймана и Гарвардская архитектура
Эти два направления определяют архитектуру вычислительных машин, до сих пор во многих случаях дополняя друг друга при их совместном использовании в рамках одной вычислительной системы или порознь в зависимости от решаемых задач.
Сама идеология модели Фон-Неймана, как было сказано выше, состоит в последовательном выполнении команд программы в процессоре, когда следующая команда поступает на исполнение после завершения предыдущей. Эта концепция удовлетворяла требованиям до тех пор, пока не потребовались вычислительные системы с производительностью, которую данная архитектура уже не смогла обеспечить. Поэтому модель Фон-Неймана стала подвергаться ревизии на всех этапах выполнения команд.
Первоначальной модернизации стал подвергаться этап чтения из выборки команды из процессора путем внедрения дополнительных буферных регистров для последующих команд, а затем и ввода дополнительной памяти для их хранения (БПК, КЭШ команд).
Таким образом, это позволило ускорить выполнение команд в процессоре за счет сокращения числа циклов обращения к оперативной памяти за командами, так как процессор мог уже выбирать не очередную команду,а порцию очередных команд а блок управления передав очередную команду на выполнение в АЛУ смог продвигать следующую команду к декодерам из буферных регистров уже не обращаясь в оперативную память . Частота обращения за командами в память сократилась с вводом буферной памяти команд и выборка (передача команд из основной памяти) стала производиться только при отсуствии очередной команды в КЭШ или в свободное время когда процессор не обращается к памяти.
С внедрением БПК (КЭШ команд) шина данных и шина команд были разделены внутри процессора. А это уже было частичным внедрением Гарвардской архитектуры, несмотря на то что команды и данные хранились в общей памяти,такая архитектура была в ЕС ЭВМ ряд II.

В дальнейшем уже в архитектуре ПК (Intel) была введена КЭШ данных, и это уже была модель Гарвардской архитектуры в процессоре. А общая память в вычислительной системе работала по принципу Фон-Неймана, поставляя и принимая команды и данные в процессор по общей шине.
С развитием технологии преобразования аналоговых сигналов в цифровой вид для их обработки в процессоре, гарвардская архитектура завоевала прочные позиции.
Согласно теории аналоговый сигнал можно идентифицировать с достаточной точностью, если стробировать, его с Т=1/2F, где F - .. частота спектра, передаваемого сигнала.












![]() ,
,

т.е. время на обработку квантованных значений входящего сигнала ограничено. И в этом случае принцип Гарвардской архитектуры, как мы убедимся далее, позволяет ускорить обработку таких сигналов.
Как видно из блок-схемы, процессор связан шинами адреса, команд/данных. Для разделения потока команд и данных внутри процессора используются (в зависимости от архитектуры) как аппаратные, так и микропрограммные средства, реализующие специальные циклы (такты) работы процессора, фиксирующие запросы в оперативную память за командой или данными.
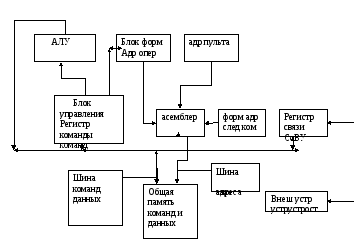
БЛОК-СХЕМА ГАРВАДСКОЙ АРХИТЕКТУРЫ ЭВМ
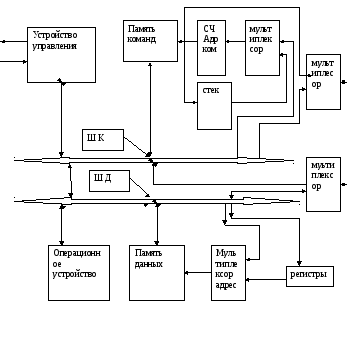
Комментарий к блок-схеме гарвардская архитектура ЭВМ.
В гарвардской архитектуре существует две физически раздельные памяти:
1) память команд
2) память данных
В первом компьютере Эйкена данные считывались с перфоленты а для хранения программы использовались регистры в которые предварительно команды записывались с пульта оператора. Это позволяло одновременно подавать на обработку данные и коды операций над ними в исполнительное устройство.
Как видно из блок-схемы команды считываются из памяти команд в регистр команды процессора ,в котором кодовая часть операции активизирует блок управления , задающий алгоритм работы операционного устройства .
Адресная часть команды в зависимости от вида команды используется для формирования адреса следующей команды или для адресации операндов в памяти данных или того и другого. То есть подобно, как и в фон-неймановской архитектуре. Отличие в том ,что в данной схеме отсутствует ассемблер адреса ,а две отдельные шины адреса для команд и данных направляются к своим памятям.
Операционное устройство получив “приказ” из устройства управления в автономном цикле может производить операции над данными, а командный блок может в это время организовать подготовку к выполнению следующей .
Другими словами говоря данную архитектуру можно рассматривать как двух ступенчатый конвейер.
Недостаток данной схемы –две адресные шины. На практике для сокращения числа шин адреса команд и данных передают по соответствующим шинам используя мультиплексирование.(см. рис.2)
Как видно из блок-схемы для того чтобы осуществлять управление операционным устройством и передавать адресную часть команд в память данных используют для связь между шиной команд и данных. Связь эту также используют для передачи констант из памяти в операционное устройство, используемые как операнды.
Данная архитектура используется в микропроцессорах предназначенных для цифровой обработки аналоговых сигналов.
Рассмотрим кратко назначение узлов на блок-схеме.
Счетчик команд представляет автоинкрементный счетчик с параллельной загрузкой либо из стека либо с шины команд. Автоинкремент используется на линейном участке программы. Загрузка счетчика команд с младших разрядов шины команд осуществляется при условных и безусловных переходах.
Стек используется для возврата из подпрограмм.
В данной архитектуре имеется две возможности адресовать ячейки памяти данных . При первом способе адрес указывается в команде а при втором ( косвенная адресация ) адрес берется из регистра предварительно загруженного значением адреса обращения к памяти. Имеется возможность производить инкрементацию или декрементацию (увеличение или уменьшение на единицу) значения этих регистров, что позволяет их использовать для организации циклических участков программы. Кроме того эти регистры могут использоваться для хранения данных считанных из памяти.
RISC и CISC
По виду используемых команд процессоры делятся на :
А) с CISC архитектурой, (с полным набором команд, выполняемых по сложным алгоритмам);
Б) с RISC архитектурой (с командами, выполняемыми за 1-2 такта процессора)
Появление процессоров с набором CISC команд явилось следствием модернизации формата команд в процессорах с архитектурой Фон-Неймана. Как известно, первоначальный формат команды состоял из кода операции и адресной части, указывающей расположение операнда в оперативной памяти. Целью модификации было упрощение алгоритма программы, то есть расширение функциональных возможностей команды, код которой мог бы на уровне аппаратных средств реализовать не только функции обработки операндов, но и их чтение из оперативной памяти, и обратно запись результата.
Такая структура удовлетворяла требованиям до внедрения конвейерной обработки команд в процессоре.
С внедрением конвейерной обработки операндов стало ясно, что для производительной работы конвейера необходимо исходные данные держать в регистрах самого процессора, а не извлекать из оперативной памяти, так как последнее явилось причиной простоя конвейера из-за необходимости ожидания доставки данных из оперативной памяти по запросу процессора.
Если в нескольких словах идея RISC архитектуры состояла в том, что в процессоре имеется достаточно большой регистровый файл, ячейки которого проходят непосредственное обращение из команд и результат записывается обратно в регистровый файл. Записи из регистрового файла в оперативную память и обратно cтали осуществляется командам, которые не связаны с обработкой данных в процессоре. Т.е. команды осуществляющиеся в CISC архитектуре обращение к памяти за операндами выполняющие операции над ними разделили на 2группы команд( команды класса RR и команды класса LOAD и STORE выполняющих запись данных из оперативной памяти в регистровый файл и запись из регистрового файла а в память ).
Так все арифметические операции в RISC архитектуре используют только регистровый формат RR, а команды MOV (пересылки) осуществляют перемещение только из регистра в регистр или обмен между группами регистров.
Если в CISC архитектуре существуют команды, которые кроме операций на сумматоре активизируют работу сдвигателя, осуществляя сдвиг операции, то в RISC архитектуре таких команд нет, а есть отдельные команды арифметики и сдвига. Как сказано выше связь процессора с оперативной памятью в RISC архитектуре осуществляется посредством команд LOAD или STORE, выполняющих загрузку и выгрузку регистровых файлов из/в процессор.
С вводом механизмов базирования и индексирования, а далее механизма динамического преобразования адресов обращения к памяти, время выборки данных увеличилось, но в целом архитектура ЭВМ выиграла в производительности, во-первых, за счет того, что выше указанные механизмы явились основными элементами организации многопрограммного режима ЭВМ, а во-вторых, из-за того, что программный код (последовательность команд) на линейном участке выполняется в пределах страницы и сегмента. Необходимости производить полный цикл преобразования адреса из логического в физический, каждый раз нет а делать это только при изменении значения страницы или сегмента, если параметры преобразования текущей страницы и сегмента сохранять в регистрах процессора или в специальных буферных памятях, т.е. «опускать» этапы преобразования адресов, используя их.
Другим средством для ускорения вычислительного процесса было введение регистровой памяти. Это направление, в конечном счете привело к созданию RISC архитектуры процессора.
CISC архитектура
Большой набор команд.
Команды достаточно сложны, со сложной структурной адресацией операндов, зачастую имеют нефиксированный формат от 1 до 16 байт.
Имеют действия с операндами, находящимися как в общих (программных) регистрах процессора, так и в формате команды или оперативной памяти, адреса которых формируются на основании кодировки, указанной в самой команде (байт-модификатор)
Выполняются в зависимости от формата от нескольких единиц до десятков и сотен тактов процессора.
Ф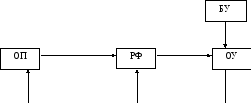 орматRR,
RX,
орматRR,
RX,
команда содержит адрес ОП
и адрес регистра
БУ – блок управления
РФ – регистровый файл
ОУ – оперативное устройство
ОП – оперативная память
RISC архитектура
Команды простые, выполняются за 1, 2 тактов компьютера.
Формат фиксирован, что упрощает управление потоком команд в процессоре.
Процессорное ядро содержит регистровый файл, формат команд RR.
Для доставки данных из памяти и записи результата в память используются команды LOADи STORE.
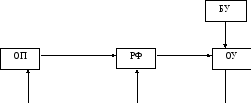
(1) формат RR
(3) (2) формат STORE
(3) формат LOAD
(2) (1)
СТРУКТУРЫ И ФОРМАТЫ КОМАНД И ДАННЫХ В ПРОЦЕССОРЕ.
Одним из важных факторов, учитываемых при проектировании и выборе архитектуры процессора, является определение набора команд, видов обрабатываемых данных их форматы и структура.
Именно вышеперечисленные исходные параметры определяют микроархитектуру процессора.
Команда-это своего рода информационный блок или двоичный код в котором кодируется выполняемая операция над данными , их местонахождение в вычислительной системе и где будет сохранен результат операции.
Следовательно команды, их двоичный код являются конечным результатом преобразований всех уровней в иерархической вычислительной системе, стоящими выше уровня микроархитектуры процессора.
По характеру выполняемых операций различают следующие основные группы команд
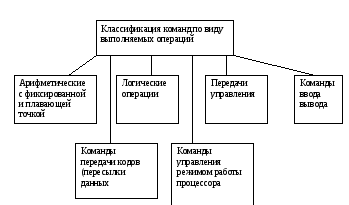
Исходя из определения команды, код ее должен в общем случае состоять из двух частей : операционной и адресной для которых в формате команды отводят группы разрядов(поля). Если операционная часть во многих случаях определяется одним полем, то адресная часть состоит из нескольких полей. Наличие нескольких полей в адресной части дает возможность кодировать одно, двух и трех адресные команды и различные способы адресации с использованием механизмов базирования и индексирования.
Когда говорят о формате команды, то имеют в виду ее структуру то есть разметку с указанием номеров разрядов, определяющих границы отдельных полей,с указанием числа разрядов(бит) в каждом поле. Форматы команд могут быть постоянной или переменной длины в рамках одной системы команд.
При использовании команд переменной длины в структуру команд закладывают код длины команды для которого используют или отдельные биты или косвенное кодирование указывая длину ,например, значением разрядов кода операции.
И так код поля операции и количество разрядов в поле определяет множество выполняемых команд в системе.
Адресная часть, указывающая адрес операнда содержит в общем случае не абсолютный физический адрес памяти, как это было в первой фон-неймановской модели, а так называемое смещение относительно некоторого физического (логического при использовании динамического преобразования адреса) адреса в оперативной памяти так как в противном случае при большом объеме памяти для указания абсолютного адреса пришлось бы использовать слишком длинные адресные поля.
С другой стороны выбирая длину команд необходимо учитывать чтобы длины команд были в согласовании с элементами данных выбираемых из памяти для обработки и равны байту, полуслову, слову, и так далее с целью упрощения аппаратной логики выборки информации из памяти.
Что же касается наличия числа адресных полей в формате команд, то наиболее простым вариантом было бы использование четырех полей:
Два поля для источников операндов
Поле для хранения результата операции
Поле для указания адреса следующей команды в программе
То есть использовать принудительный порядок выборки команд.
Такая технология на уровне программного кода не используется а используется в микропрограммах, для которых характерны алгоритмы с детерминированными связями между операторами.
Использование трех адресных команд было характерно для первых ЭВМ команды которых имели вид:
ОП[A3] : =ОП[A2] *ОП[A1]
Операция производится над содержимым ячеек с адресами A1 и A 2
Результат записывается в память по адресу A3.
Формирование адреса следующей команды в системах с трех адресной организацией на линейном участке программы происходит автоматически увеличиваясь на длину выполненной команды, а командах управления кодируется обычно в одном из адресных полей.
Для сокращения длины команды используют двух адресный формат
ОП[A1] : = ОП[A1]* ОП[A2]
Применение одноадресного формата команды, в которой указывается адрес одного операнда целесообразно использовать для обработки данных с размещением по последовательным адресам в памяти для которой оператор имеет следующий вид:
АККУМ : = АККУМ*ОП[A1]
То есть в процессе обработки данные считываются из памяти, обрабатываются в процессоре и результат обработки используется в последующем цикле, как второй операнд при этом формат команды указывает на адрес начала массива и содержит код длины массива.
Определив формат команды далее необходимо разработать технологию формирования адреса обращения к данным или по другому способы адресации в командах. Поэтому выбор способов адресации, формирование исполнительного адреса и преобразование адресов является одним из важных вопросов при разработке и выборе архитектуры процессора.
Разнообразие способов адресации усложняет аппаратную логику блока формирования адреса с одной стороны, а с другой расширяет функциональные возможности команд и соответственно дает возможность более гибкого управления вычислительным процессом.
Так что при разработке архитектуры процессора необходимо учитывать этот фактор, фактор который в свое время стал одним из определяющих в направлениях развития CISC и RISC архитектур процессоров.
Способы адресации.
1. Непосредственная.

Операнд размещается в формате команды
R1: = [R1]* const.
2. Прямая.
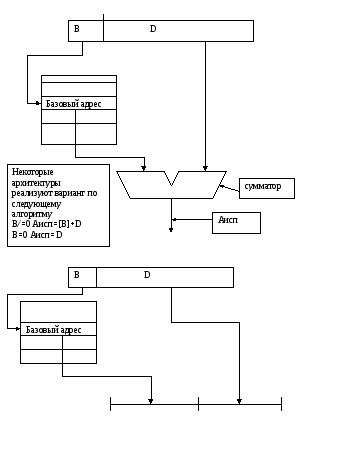
Аисп = [A] где [A]-содержимое поля адресной части команды. Использовалась в первых ЭВМ. Может быть реализована как частный случай относительной адресации, если базирование не используется.
3. Относительная адресация
Aисп = Aбазы + Aсмещ
Абазы – адрес значение которого может находится в одном из общих или специально выделенных регистрах для хранения значения базового адреса , при нулевом значении содержимого базового регистра относительная адресация трансформируется в прямую.
В арианты
относительной адресации
арианты
относительной адресации
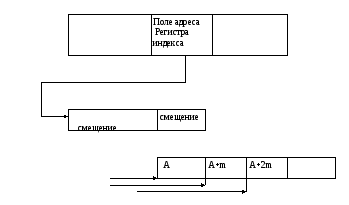
Индексная адресация.
Реализуется также как относительная, с той лишь разницей, что в индексной ячейке хранится не базовый адрес а индекс(смещение) величина которого используется для модификации адреса данных(увеличения или уменьшения в зависимости от режима индексирования) при выполнении команды.
Данный режим используется при обработке массива данных при организации циклических вычислений.
Косвенная адресация.
Адрес операнда указывается косвенно через указатель, который находится в формате команды. В случае использования регистра в качестве указателя адреса содержимое этого регистра и будет адресом операнда в памяти. Такая форма косвенной адресации носит название косвенной регистровой, может быть использован и другой режим когда указателем адреса операнда может служить ячейка оперативной памяти.
Форматы данных.
В ЭВМ применятся две формы представления чисел с фиксированной и плавающей точкой .При представлении чисел с фиксированной точкой диапазон представления чисел зависит от расположения точки в разрядной сетке числа. Если точка располагается слева от старшего разряда, диапазон чисел определится 2*-(n-1) <v=[х] <v=1-2*-(n-1)
В случае расположения фиксированной точки справа от младшего разряда диапазон -2*n-1 <v=х<v=2*n-1 -1
Где n –количество разрядов числа.
Представление чисел с плавающей точкой в общем случае имеет вид
Х=S*p х q
S*p- характеристика числа
q-мантисса ,дробное число.
p-порядок числа, может быть как положительным так и отрицательным числом.
Для упрощения операций над порядками вводят так называемый смещенный порядок pсмещ=p+A A=2*k где к -число разрядов порядка
То есть pсмещ является положительным числом
Для отображения числа с плавающей точкой разрядная сетка делится на два поля:
Поле порядка
Поле мантиссы
Знак числа указывается в крайнем левом разряде разрядной сетки числа
Для повышения точности вычислений используют нормализацию основанную на том, что при фиксированном числе разрядов мантиссы любая величина в машине представляется с наибольшей точностью нормализованным числом, оно считается нормализованным, если мантисса будет выражаться значением
1/s <v=q<1
В случае двоичного представления чисел это означает: ½<v=q<1.
Технология нормализации результата вычисления будет сводиться к сдвигу мантиссы результата влево до первой значащей единицы в старшем разряде.
Символьное и двоично-десятичное представление информации.
Так как процессор обрабатывает не только числовую информацию но и алфавитно –цифровую, то для отображения такой информации используют специальные коды, количество разрядов для кодирования каждого элемента алфавита определяет его размер.
Для выполнения операций десятичной арифметики применяют двоично –десятичное кодирование, где каждая цифра от нуля до девяти представляется в двоичном коде и использованием четырех разрядов, так как 2*4=16, то коды 1010-1111 не используют и при обнаружении их в операциях десятичной арифметики формируется признак особого случая в процессоре.
Однако использование этого кода связано с трудностями при обнаружении переносов в операциях так как перенос из тетра-ды в тетра-ду осуществляется по модулю 16 а не 10.
Для того чтобы обнаружить перенос к одному из операндов в каждой тетра-де прибавляют 6. Если при сложении сумма в тетра-де будет больше
Или равна 10 ,то будет перенос в следующую, если переноса не будет ,
То необходима корректировка результата в тетра-де, из которой не было переноса (из нее необходимо вычесть, а это эквивалентно корректировке результата на плюс десять -6=-(16-10) .Вычитание16 с нулевыми разрядами в тетра-де 10000 не влияют на результат в тетра-де, а прибавление кода 10 (1010) даст правильный результат)