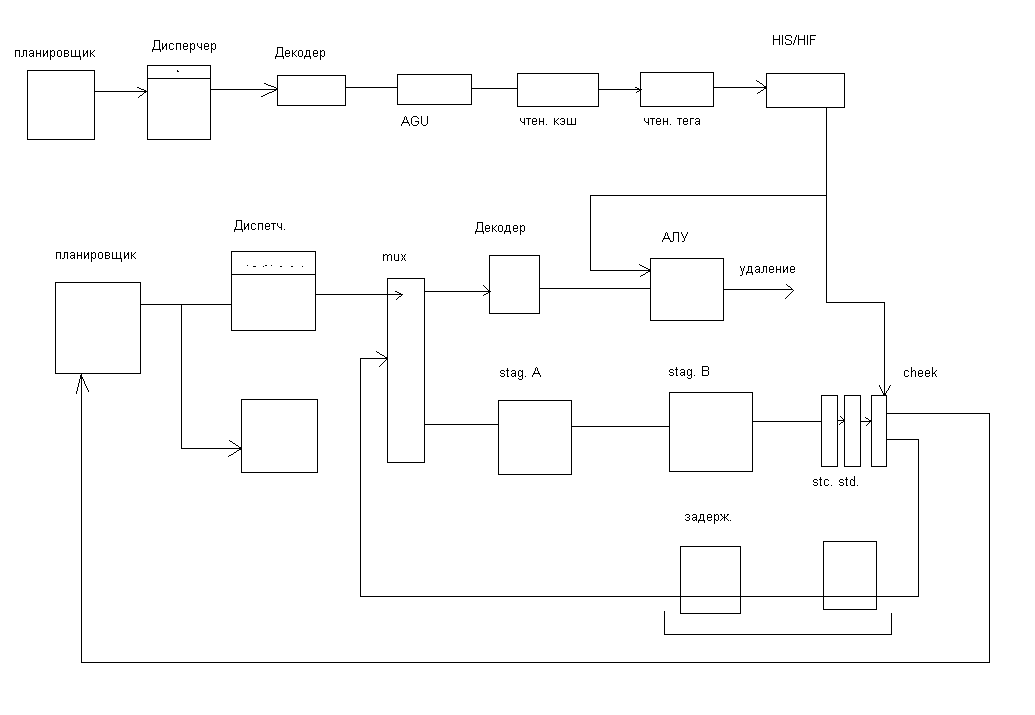
Идеология организации без упорядоченного выполнения
В свое время узел формирования адреса был вынесен из операционного блока, с той целью чтобы освободить основной сумматор от вычисления адресов операнда и перенести в блок выборки команд, в котором в совокупности с КЭШ памятью команд организован законченный цикл подготовки операндов к выполнению операций над ними в операционном блоке, таким образом сформировать 2хступенчатый конвейер в процессоре.
Идеология без упорядоченного выполнения основана на предварительном анализе команд по возникновению конфликтов при их выполнении, задержки их выпуска по конвейер и пропуска внеочередных команд, которые могут быть беспрепятственно выполнены. Конфликты эти относятся в первую очередь к группе конфликтов по данным. Конфликты эти классифицируются по типу RAWиWAR,WAW.
Первоначально анализ возможного возникновения этих конфликтов проводился на стадии декодирования и вычисления операндов, в дальнейшем для реализации без упорядоченного выполнения формирование адресов операндов выделили в отдельную стадию конвейера с той целью чтобы дать возможность формировать адреса операндов внеочередным командам поступающим на конвейер. Таким образом стадия декодирования была разбита на два такта:
Такт выдачи
Такт чтения операндов
Такт выдачи стал контролировать ситуацию использования регистра результата в команде, предыдущими командами в качестве регистра результата (WAW– запись после записи) с целью избежать искажения при предыдущих команд. Если такая ситуация могла иметь место, то команда не выпускала на конвейер.
На этапе чтения операндов анализировать стали возможность возникновения RAWпри выпуске команды на конвейер, т.е. операнды источники проходят проверку не являются ли они регистрами результата предыдущих команд, находящихся в стадии выполнения или в данный момент не происходит ли запись из функционального устройства по адресу источника в команде.
В связи с без упорядоченным выполнением, завершающую стадию конвейера, связанную с записью результата в регистровый файл, пришлось разделить на 2 части.
Это первая предварительная - стадия завершение.
Вторая – запись результата.
На этапе запись результата блок управления конвейером отслеживает возможность возникновения конфликтов типа WARдля того, чтобы исключить искажение значений в регистрах, используемых в качестве источников предыдущими командами находящимися на стадии выполнения.
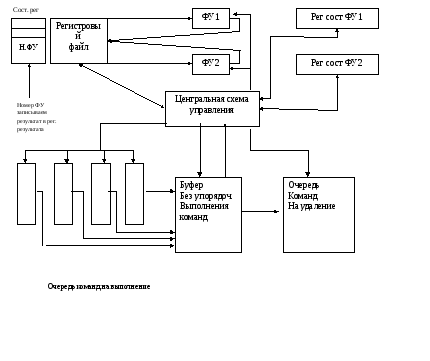
Как следует из представленной блок–схемы, централизованная схема управления осуществляет контроль за приемом команд во входную очередь, загружая их в буфер без упорядоченного выполнения. При готовности операндов и наличии свободных функциональных устройств централизованная схема управления передает команды им на выполнение и по завершении передает их в очередь команд на удаление ,соблюдая последовательность программного кода.
Алгоритм Томасуло
С одной стороны выделение чтения операндов в отдельную стадию конвейера наводит на мысль о возможности размещения узла формирования адресов операндов в глубину конвейера с целью его параллельной работы с другими функциональными блоками операционного устройства. В этом случае отпадает необходимость в начале конвейера держать буфер для команд ,ожидающих выполнения только при одном условии, если будут отсутствовать в системе конфликты RAW, которые контролирует эта стадия.
Одним из способов устранения конфликтов типа RAW-это наличие обходных цепей, когда результат сумматора передается на один из его входов в случае использования его в качестве источника в следующей команде. В этом случае в регистровом файле просто будут отсутствовать источники, которые могут быть прочитаны раньше чем попадет в них конечный результат, потому что все результаты ,которые будут использованы в следующей команде в качестве источника просто не будут записываться в регистровый файл. Следовательно, при использовании технологии без упорядоченного выполнения можно воспользоваться методом обходных цепей.
И так целесообразность перемещения узла чтения операндов в глубь конвейера будет только в том случае, если операционное устройство, имея блочную структуру, будет иметь для каждого функционального узла буфер команд, ожидающих выполнения; уже с готовыми операндами,, а блок чтения операндов имея свой буфер с адресами для операндов будет поставщиком операндов в эти функционального устройства.
Это во-первых, а во-вторых и основное промежуточные результат вычислений не будет передаваться в регистровый файл, а будет перемещаться из одного функционального устройства в другое или же в свое во входную очередь подобно архитектуре обходных цепей в сумматоре, а запись результата выполнения операции будет производиться только при завершении всех предыдущих команд при отсутствии конфликтов WAR, подобно как это делается при централизованном управлении при заключительной стадии конвейера «Запись результата».
Конфликты WAW, отслеживаемые при централизованном управлении просто будут отсутствовать, так как будет исключена ситуация циклов ранней преждевременной записи в регистровый файл в силу логики работы распределенных схем контроля за конфликтами.
Конфликты RAWпри распределенной схеме управления конвейером не будут возникать же из-за того, что все циклы чтения промежуточных результатов из регистрового файла просто отсутствует, так как эти результаты будут подаваться непосредственно на исполнительное устройство из других функциональных блоков.
Без обходных цепей в сумматоре … … С обходными цепями в сумматоре
ADDR1R2R3IDEXWBIDEX
S
 UB
R4R1R3
ID EX WB ID EX WB
UB
R4R1R3
ID EX WB ID EX WB
Невозможна одновременная запись и чтение в R1
конфликт просто не возникает т.к. результат ADD поступает на вход сумматоре для вычитания.
… ….
Вышеописанная технология реализует алгоритм Томасуло, основные принципы которого мы и отметим.
Но прежде чем сформулировать эти принципы рассмотрим еще способ устранения конфликтов типа WAR на конвейере. Таким является способ переименования регистров.
1









 .R5=R1+R2
IDEXWструктурный конфликт: регистр. файл
занят;
.R5=R1+R2
IDEXWструктурный конфликт: регистр. файл
занят;
2




 .R6=R0*R5
IDEXWзапись
2-ой команды
.R6=R0*R5
IDEXWзапись
2-ой команды
3



 .R5=R3+R4
.R5=R3+R4
регистр R5 ЗАНЯТ2ойкомандой запись не возможна
4
 .R7=R0*R5
.R7=R0*R5








IDEXEXWRAWконфликт поR5 между 1и 2
командами








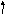 IDEXEXWRAWR5
занят 3ей командой
IDEXEXWRAWR5
занят 3ей командой


 5.R5=R1+R2
5.R5=R1+R2
6

 .R6=R0*R5
IDEXWкак видно из примера
переименование регистров
.R6=R0*R5
IDEXWкак видно из примера
переименование регистров
7 .S1=R3+R4IDEXWувеличивает
производительность работы конвейера
.S1=R3+R4IDEXWувеличивает
производительность работы конвейера
8

 .R7=R0*S1
.R7=R0*S1


 ID
EX EX W
ID
EX EX W


 ID
EX EX W
ID
EX EX W
Метод переименования регистров (пример)
Предположим, что необходимо вычисление (¬x + ¬y)c
¬x = ix1 + jy2; ¬x + ¬y=i(x1+x2) + j(y1+y2)
¬y=ix2 + jy2; c(¬x + ¬y)=ic(x1+x2) + c(y1+y2)j
Т.е. значение координаты нового вектора: c(x1+x2),c(y1+y2) которые будут помещены в регистровый файл.
Данные вычисления будут производиться на суперскалярном процессоре имеющегот 2 конвейера: конвейер с фиксированной точкой (операции сложения) и конвейер умножения (множительное устройство)
Программа для выполнения:
ADDR5=R1+R2
MUL R6=R0*R5
ADD R5=R3+R4
MUL R7=R0*R5
Общая схема:

R7
R6
R5
R11X1
R2X2
R3 Y1
R4Y2
R0C
Анализ работы суперскалярного процессора с использованием переименования регистров показывает, что возможно окончание выполнения команд не в том порядке, как они расположены в программном коде т.е. на лицо внеочередное выполнение команд.
Для организации выдачи результатов в порядке определяющем программным кодом необходимо сохранять содержимое временных регистров до того времени, когда вся редыдущая команда закончит выполнение и будут удалены из конвейера. В течении времени пока временной регистр содержит данные он используется последующими командами как источник. Т.е. отсюда вывод: при суперскалярной архитектуре использование временных регистров необходим блок выходной … команд, который будет контролировать окончание выполнения команд в двух фазах:
Завершение
Запись результата
Удаляя с конвейера те команды которые будут иметь статус второй фазы.
КОНВЕЙЕР
очередь
завершенных команд Очередь
команд на удаление с конвейра Р.Ф.
Входной
поток команд …
памяти






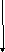








КОНВЕЙЕР
Одной из проблем без упорядоченного выполнения является ситуация возникающая при обработке прерываний, когда необходимо восстановить состояние процессора до начала выполнения команды, вызвавшей прерывание.
При последовательном выполнении команды этой ситуации не возникает, а так при без упорядоченном выполнении возможно окончание последующих, ранее предыдущих, а при выполнении предыдущих могли возникнуть прерывания, а исходные данные последующих может быть уже нельзя восстановить, вот тогда и возникает ситуация выход из которой можно найти
А) сохранение исходных данных команд, находящихся в буферах исполнительных устройств и всех команд в буфере очередности, контролирующего последовательность выполнения программного кода, имеющих статус “‘ завершение”.
Если возникнет прерывание, то состояние машины можно будет восстановить до точки предшествующей всем командам выполненным вне очереди
Б) сохранение всех х результатов в буфере, который хранит новые значения всех команд, находящихся в состоянии “завершение”
В) выдавать команды на этап запись результата” ,если известно что все предыдущие команды выполнены без прерываний, это является гарантией, что ни одна из предыдущих команд не будет завершена пока не будет обработано прерывание.
Г) Хранить все адреса команд и сами команды, находящиеся на не выполнении в конвейере.
Блок предсказания переходов
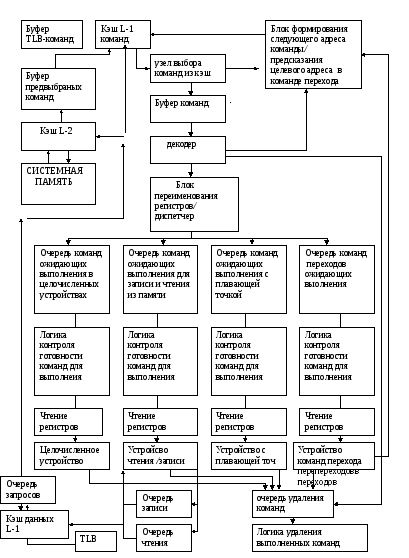
Без упорядоченное выполнение и механизм обработки прерываний в процессоре в этом случае, который восстанавливает состояние процессора после не одной, а возможно нескольких выполненных команд, наводит на мысль об использовании технологии предсказания переходов. Направлять поток выполненных команд на основе предсказаний, а в случае ошибки восстанавливать состояние процессора и начинать выполнение программы по адресу, сохраненному в процессоре, в случае ложного предсказания. Точно также как это осуществлялось при обработке прерывания, только вместо адреса перехода по прерыванию, используется адрес, по которому должно переходить выполнение программы в случае ложного предсказания. Но реализация идеи выполнения команд по предположению, так же как и без упорядоченное выполнение, требует внедрения дополнительных аппаратных средств в архитектуру, процессора и это в первую очередь будет буфер переупорядочивания,, который представляет дополнительные виртуальные ресурсы как и станция резервирования в алгоритме Томасуло. Буфер хранит промежуточные результаты от момента завершения операции до ее стадии “запись результата”.
Буфер является источником операндов для команд, точно так же как станция резервирования, обеспечивающая промежуточное хранение и передачу операндов в алгоритме Томасуло. После того как команда в алгоритме Томасуло записала результат в регистровый файл, он становится доступным для других команд. В случае выполнения команд с использованием механизма предсказания адреса перехода, запись в регистровый файл, производится только после получения результата условия, по которому должен быть произведен переход в программе. Только после этого все команды, следующие за командой перехода получают статус”запись результата” . Вот поэтому каждая команда имеет позицию в буфере переупорядочивания до тех пор пока она не получит статус “запись результата”., Результат помечается номером строки в буфере, а не номером станции резервирования. Вот почему станции резервирования ,получая данные из буфера, обязаны отслеживать номер строки, чтобы отправить результат операции в строку буфера из которого были получены исходные данные.
Алгоритм Томасуло
Основной идеей алгоритма Томасуло являлся отказ от централизованного управления функциональными устройствами с точки зрения связи с регистровым файлом на промежуточном этапе выполнения. Отказ от записи промежуточных результатов в регистровый файл т.е. тех, которые будут использованы в следующих командах следовательно исключить конфликты типа RAW, иWAR, используя для этого во-первых, переименование регистров, во-вторых, станции резервирования.
Станции резервирования представляют ячейки буферной памяти типа FIFO. Для каждого функционального устройства структура каждой станции состоит из информационной части и теговой.
Информационная часть содержит операнды поступающие на обработку из:
А) регистрового файла
Б)из функционального устройства как и промежуточный результат
В) Из оперативной памяти
Теговая часть каждой строки в буфере памяти содержит 6 полей:
Поле операции
Поля, указывающие станции резервирования, которые будут вырабатывать соответствующие операнды источники, нулевые значения этих полей указывают, что операнды уже находятся в полях значения операндов.
2 поля операндов источника
Поле занято, указывает, что данная станция резервирования и соответствующее ей устройство заняты.
-
Поле операнда
Номер станции резервирования
Номер станции резервирования
Значение 1го операнда
Значение второго операнда
Занято
Откуда должны подавать первый операнд
Откуда должен поступать второй операнд
Регистровый файл и буфер записи имеют поле в котором указано функциональное устройство, которое будет вырабатывать значения для записи в регистр или память. Буфер записи имеют поле для записи значения операнда в память.
Аппаратура, реализующая алгоритм Томасуло, может быть расширена для обеспечения поддержки выполнения по предположению. С этой целью необходимо, как было отмечено выше, ввести фазу фиксации результата и фазу записи результата. Добавление к последовательности выполнения команды фазы фиксации требует сохранение всех команд закончивших выполнение и их результатов до момента пока не сформируется признак, по которому должен быть произведен переход. Вот почему без упорядоченное выполнение команд и механизм предсказания требуют одних и тех же аппаратных средств- дополнительного набора аппаратных буферов, которые хранят результаты команд, закончивших выполнение но еще не записавших результат в память или в регистровый файл.
Каждая теговая строка в буфере содержит 4 поля
Поле типа команды
Поле места назначения, по которому будет отправлен результат выполнения команды
Поле значения
Поле состояния команды(микрооперации)
Поле типа команды определяет является ли команда перехода, командой записи в память, или регистровый файл.
Поскольку каждая команда имеет позицию в буфере, до тех пор, пока она не будет зафиксирована и результат не будет отправлен в регистровый файл, результат выполнения команды хранится в строке с той же позицией. Все это время позиция строки, то есть ее адрес ,будет являться ссылкой для всех команд , использующих ее результат в свих операциях.
При выполнении по предположению запись в регистровый файл не производится до тех пор пока команда не не получит статус “запись результата”
Большое преимущество схемы Томасуло заключается в распределении логики обнаружения конфликтов и устранение приостановок ,связанных с конфликтами WAWиWAR. Это преимущество возникает из-за наличия станций резервирования, которые хранят промежуточные результаты вычислений и общей магистральной шины результата ,которая дает возможность одновременной загрузки результата в несколько станций в случае необходимости , таким образом давая возможность поступления нескольких команд, ожидающих этот результат, на выполнение из входной очереди в функциональные устройства в одном такте конвейера при условии ,что каждая станция резервирования имеет свою магистраль , связанную с входной очередью. Одновременное начало выполнения команд, ожидающих данные с магистрали результата, в функциональных устройствах возможно и при наличии одной магистрали загрузки команд из входной очереди ,если эти команды уже находятся в станциях резервирования функциональных устройств.
В первые данная схема была предложена Томасуло при проектировании устройства с плавающей точкой. В дальнейшем его идея бала использована во многих архитектурах процессоров и стала базовой при проектировании в них блоков операций. Достаточно для этого привести пример архитектуры процессоров линейки Pentiumна основе базовой моделиP6. Именно в этой модели были использованы функциональные устройства с использованием станций резервирования, технологии безупорядочного выполнения микроинструкций, переименования регистров и предсказания переходов.
Проверка
наличия команды




 нет
нет



Проверить
Rрезi=i
- 1, i - 2, … , i - x
 ДаID1-выдача
ДаID1-выдача




 конфликтWAW
конфликтWAW
да нет
Блокировка
выдачи
Разрешение
выдачи
Проверка
Rчт=Rрез
i-1,i-2,…,i-x
ID2- чтен




 Да
нет нет
Да
нет нет
Разрешение
выдачи ком в ФУ
Блокировка
выдачи команды в ФУ
Установить
Ф.У.занято
EX-выполнение

Сбросить Ф.У.занято




Проверка
Rрез=Rчт
i-1,i-2,…,i-k





Разрешена
запись в Rрезi,
Регистр состояния ФУ
|
Свободно/занято |
Поле операции |
… |
Поле операции |
номер регистрарезультат |
содержмрегистра операнд1 |
содерж регистраоперанд2 |
Поле поставки операнд1 |
Поле поставки операнд2 |
готовность операнд 1 |
Готов. Операнд 2 | ||||||||
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 | ||||||||||

Для многофункциональных устройств
Структурная схема без упорядоченного выполнения с блоком предсказывания переходов





 Станции
резервирования
Станции
резервирования
В
ФУ

 ходная
очередь шина
ходная
очередь шина





Строка станции резервирования
|
Q |
номер |
номер |
Vi |
Vj |
| |
|
|
Код операции |
Строки в буфере |
Строки в буфере |
|
|
занято |

 СDВ
СDВ
ФУ



Регистровый файл
Регистровый
файл
|
Занято |
Номер строки в буфере переупорядочивания откуда должен поступить результат |



Буфер
переупорядочивания
















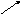














Буфер переупорядочения
|
Номер |
Занят |
Команда |
Состояние |
Место назначения |
Значение |
|
1 |
|
Код команды или микрооперации команды |
Завершение/записать результат выполнения |
Номер регистра результата регистровом файле |
Значение опрерандов |
|
2 | |||||
|
3 | |||||
|
4 |



![]()

ЛЕКЦИЯ N13
Тема лекции:
Микроархитектура процессоров INTEL класса
«Pentium»
Классическим примером процессоров этого класса является модель процессора Р6
(PentiumPro) ставший в свое время базовой для процессоровPentium2 и 3. Микроархитектура этого процессора содержит аппаратные средства, обеспечивающие конвейерную обработку команд и всех ситуаций, возникающих при этом, ранее нами рассмотренных аппаратными средствами.
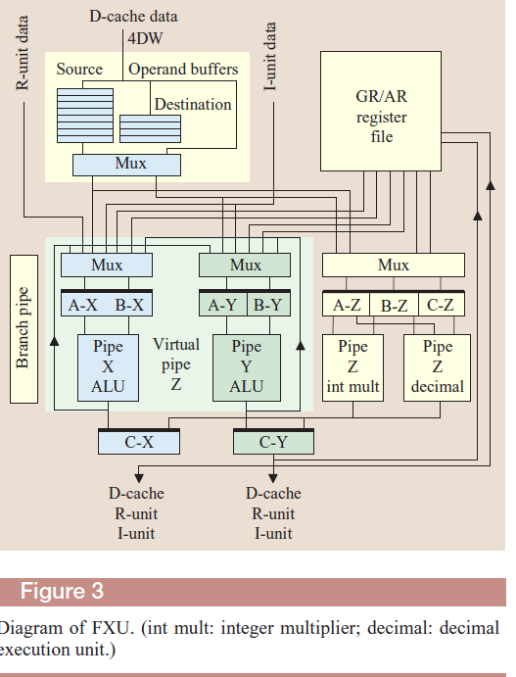
Как видно из блок схемы процессор содержит 3 отдельных независимых функциональных блока, обеспечивающих 3х фазную обработку команд.
А) выборка
Б) выполнение
В) завершение
Эта классическая структура применялась и ранее в предыдущих поколениях различных микроархитектур, с той лишь разницей, что для CISCмоделей эти функциональные блоки были связаны воедино во время выполнения отдельной команды. Наличие кэш команд и данных 1 ого уровня является признаком модифицированной Гарвардской архитектуры, обеспечивающей совмещение выполнения выборки очередной командыcвыполнением предыдущей. Эта технология была использована и ранее, к примеру, в наших отечественных моделях (ЕС 1045 и др.).
Микроархитектура блока декодирования имеет классические элементы, присущие любой системе, будь то жесткая логика или микропрограммное управление и предназначены для дешифрации команд и задания алгоритма обработки команд в процессоре. Но с другой стороны каждый блок имеет свои особенности, связанные со структурой и форматами команд, поступающих на обработку. Так в рассматриваемой архитектуре . команды имеют сложную структуру, которые разрабатывались без учета конвейерной обработки еще в предыдущих моделях (CISC).
Поэтому для сохранения преемственности программного обеспечения пришлось разрабатывать сложные декодеры, преобразующие СISCкоманды в набор микроопераций, представляющих по сутиRISCкоманды. Для решения этой задачи пришлось разрабатывать достаточно сложные декодеры и организовывать многостадийный конвейер в рамках блока. Как мы уже говорили ранее, что формат команд, используемых в микропроцессорах класса х86 и в последующих разработках на базовой моделиP6,
кроме поля кода операции имеет поле байта-модификатора в которых содержится вся информация о структуре команды, ее длине и способах адресации операндов, которая и
служит исходной информацией для разработки аппаратных средств декодеров..
По сути, о чем мы сейчас говорили это классическая функция блока декодирования по преобразованию команды в набор микроопераций. Тогда же в чем же особенность?
А особенность заключается в том, что в CISCархитектурах микрооперации, выполняющиеся последовательно одна за другой функционально связаны, как и команды в программном коде, адрес текущей определяет адрес последующей. В данном же решении микрооперации выходящие из декодера сохраняются в промежуточном буфере, становясь доступными группе исполняющих устройств, для которых они предназначены независимо от принадлежности команд в программном коде.
Возникает вопрос? А как же строгая последовательность программного кода. А для этого декодер на этапе декодирования связывает в цепочку микрооперации, принадлежащие одной команде, для того чтобы в процессе выполнение команды считать выполненной, когда все микрооперации в цепочке устанавливают флаг статуса «выполненных». А так как в случае беспорядочного выполнения возможно и внеочередное выполнение команды, команда удаляется из процессора только в том случае, если предыдущие команды выполнены.
Именно чтобы обеспечить эту функцию аппаратными средствами используется буфер микроопераций, в котором микрооперации записываются и удаляются в строгой последовательности согласно программному коду.
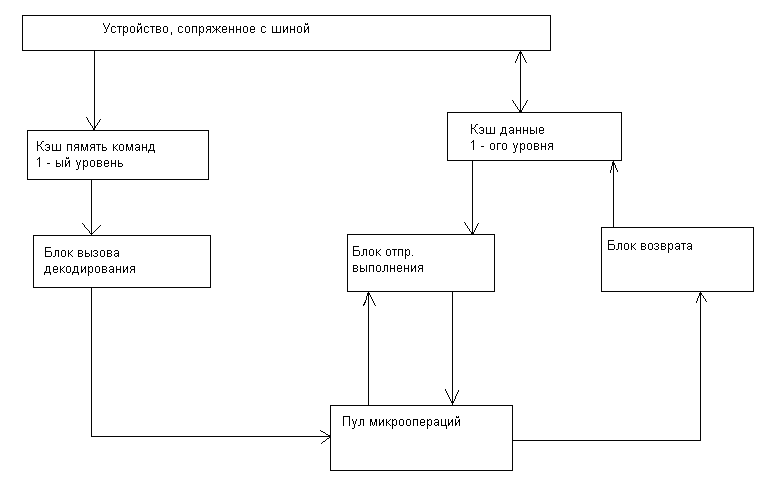
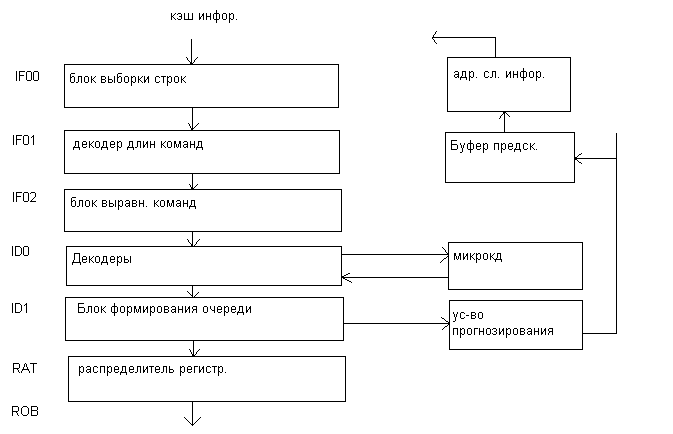
Как видно из блок схемы буфер микроопераций (пул микроопераций) является связывающим звеном между тремя основными блоками в процессоре. Он представляет адресуемую память, состоящую из 40 регистров. Он содержит микрооперации ожидающие выполнения, а также те, Которые уже выполнены, но не получили статус удаления из буфера «фиксация». Устройство диспетчера может выбирать для выполнения, как уже упомянуто выше, любую микрооперацию при готовности операндов и наличии свободного функционального устройства для их обработки Максимально 2 физических регистра со статусом завершения (удаления) могут быть прочитаны в каждом цикле. А теперь кратко о стадиях конвейера блока выборки декодирования. Наличие 3х стадий IF0,IF1,IF2 на этапе выборки объясняется следующими причинами.
выборка из кэш (32 байта кода программ.)
определение начала команд, их длина в области 32 байта (дешифрация кода команды и байта модификатора)
этап выравнивания. Т.к. декодеры работают с жестко распределенными полями в формате команды.
Команда, поступающая из декодирования должна быть выровнена на начало границы ввиду того, что в границах 32х байта считанных их кэш может начинаться не обязательно с 0 – ого байта.
Этап декодирования включает 2 стадии: ID0,ID1.
Первая собственно предназначена для формирования форматов микроопераций.
Вторая для выстраивания очереди микроопераций.
Блок формирования очереди работает следующим образом:
Получив микрооперацию от декодера, он контролирует прием бита «завершения» из декодера в каждой следующей микрооперации и при получении его устанавливать признак конца цепочки, таким образом, связывая все микрооперации относящиеся к одной команде.
На этой же стадии конвейера получая от декодера признак команды, в случае обнаружения команды перехода формируется адрес следующей команды
с учетом, что переход назад более вероятен, чем вперед, на случай если блок предсказания не имеет другой информации о направлении перехода.
Блок декодирования имеет в своем составе 3 декодера, 2 предназначены для декодирования «простых» команд и один «сложный», декодирующий как простые, так и сложные команды. При работе декодеров имеется своя специфика. Если «сложный» декодер захватывает сложную команду, за которой следует «простые» две команды, то работают все декодера. Если же идет простых 3 команды, то 3 декодера работают одновременно и выдают в одном такте 3 микрооперации.
4 – 1 – 1 (6 микроопераций)
1 – 4 – 1 (2 микрооперации)
1 – 1 – 1 (3 микрооперации)
Этап RAT.
На этой стадии конвейера поддерживается переименование регистров (логических) программных в физические для исключения конфликтов WARиWAW. Реальные программные регистры могут быть заменены в микрооперации любым из 40 внутренних, находящиеся в буфере.
Кроме того, на этой стадии к коду микрооперации добавляется поле статуса и поле «флагов», после чего микрооперации поступают в пул микрооперации, поле микрооперации дополняется разрядами для хранения значений самих операндов.
С
сост
сост

Устройство выборки (декодирования)

Пул инструкций.
Пул инструкций принимает поток микроопераций, определяемый программным кодом. Он представляет адресуемую память, состоящую из 40 регистров. Он содержит микрооперацию ожидающую выполнения, а также те, которые уже выполнены, но не получили статус «фиксации». Устройство диспетчеризации может выбирать для выполнения любую микрооперацию при готовности операндов. Максимально 2 физических регистра со статусом завершения могут быть прочитаны в каждом цикле.
Устройстводиспетчеризации / выполнения.
Устройство диспетчеризации / выполнения является устройством безпорядоченного выполнения, которое диспетчеризирует и выполняет согласно зависимости данных и доступности ресурсов. Выбор и диспетчеризация микроопераций из пула инструкций управляется станцией резервирования. Она постоянно сканирует пул инструкций с целью поиска микроопераций готовых для выполнения. Т.е. все источники – операнды доступны и диспетчеризация их к доступным устройствам.
Результат выполнения микрооперации возвращается в пул и хранится совместно и микрооперациями до тех пор, пока не обработаются устройством восстановления.
Процесс выполнения и диспетчеризации является классическим процессом безупорядоченного выполнения, где микрооперации обрабатываются в соответствии с готовностью данных и наличия ресурсов без учета порядка следования в программе.
Когда 2 или более микрооперации одного типа претендуют в одно и тоже время на один ресурс, они выполняются в порядке FIFOпоступления в пул.
Исполнение микрооперации осуществляется двумя целочисленными устройствами, двумя устройствами с плавающей точкой и одним устройством обращения к памяти, позволяя диспетчеризовать до 5 микроопераций за такт. Устройство формирования адресов для команд перехода промахи перехода и сигнализирует BTBпроизвести перезагрузку конвейера. Устройство связи с памятью управляет микрооперациями «Загрузка» и «Запись». Для чтения из памяти достаточно одного адреса, поэтому эта операция декодирует в одну микроперацию. Запись декодируется в 2 микрооперации (адрес/данные).

Блок обработки изменением последовательности.
Основная задача этого блока осуществлять контроль за состоянием микрооперацией находящейся в пуле инструкций и по мере их готовности к выполнению в других устройствах помещать их для выполнения. Попав в пул, микрооперация становится доступной
Для выполнения в функциональных устройствах, о чем свидетельствует бит «готовности» в поле типов микрооперации. Длина очереди 20 элементов.
Диспетчер распределяет микрооперации по портам, которые связаны с функциональным устройством. При этом каждый порт имеет свои собственные очереди, в виде FIFO.
Некоторые функциональные устройства разделяют один порт, который является мультиплексным. Может случиться так, что в такте будет несколько микроопераций, претендующих на обработку. В этом случае вступает механизм приоритета, учитывающий «важность микрооперации» и ее момент поступления в ROB(пул инструкций). Так, например микрооперация перехода считается важнее, нежели микрооперация обработки целых чисел.
Микрооперация, попав в порт после обработки в функциональном блоке «возвращается» в пул инструкций, получая статус «выполнена». Функциональный блок должен «знать» адрес регистра в ПУЛе, значение которого должно сопровождаться инструкцией.
Т.е. являться тегом ее в процессе всей обработки. Исходя из стадий конвейера, который реализует работу блока, а их 3. Можно предположить, что:
1) ROBявляется полностью ассоциативной памятью.
2) для выдачи микроопераций в станцию резервирования в ROBучаствуют только регистры с меткой «очередь» (стадия резервации).
3) Поиск осуществляется по коду операции или нескольких их возможных значений.
4) Каждый порт для организации связи с ячейкой ROBимеет магистраль, на которую выходит регистрыROBа. Только в этом случае поиск может быть осуществлен за один такт и эти же регистры могут выдать информацию в порт в следующем такте. Для возвращения результата вROBфункциональные блоки ы также должны иметь собственные магистрали для записи результатов вROB.
Основное назначение блока восстановления.
Основное назначение блока восстановления - отправлять результаты спекулятивного выполненных микроопераций в машинные регистры, адресуемые в программном коде или в ячейки оперативной памяти. Т.е. следить за выполнением микрооперации в пулtинструкций и записывать результаты их выполнения строго согласно программному коду.
Для этого подобно станции резервирования блок восстановления постоянно контролирует состояние микрооперации в пуле инструкций, просматривая, чтобы они были выполнены и не имели бы зависимости от других микроопераций в пуле, прежде чем фиксировать их окончательные результаты в процессоре, учитывая при этом наличие прерывания исключений и условие перехода.
Устройство восстановления способно восстанавливать до 3х микроопераций в такт, после того , как результаты микрооперации зафиксировали в машинных регистрах , они удаляются из пула. Подобно блоку отправки / выполнения конвейер блока восстановления имеет 3 стадии.
Анализ выполнения операции
Запись результатов в машинные регистры
Удаление выполненных микроопераций.
Устройство сопряжения с шиной предназначено для связи процессора с кэш памятью 1 ого и 2 ого уровня и системной памятью. Связь с кэш 1-ого уровня осуществляется для кэш данных и кэш команд, осуществляя реализацию модифицированной гарвардской архитектуры. Связь с памятью 2 ого уровня осуществляется по отдельной шине 64 бит. Системная шина представляет собой группы сигналов независимых. функционально друг от друга, тем самым, обеспечивая конвейерную организацию. Для обеспечения конвейерной организации устройство шинного интерфейса содержит буфер запросов к памяти, состоящей из очередей по записи и чтению. Данный буфер обеспечивает, например выполнение запросов чтения, давая возможность «обгонять» операциям чтения, операции записи, тем самым осуществлять спекулятивное чтение данных, то есть доставляя их заранее в процессор.Следует отметить запись осуществляются только строго в программной последовательности.
С учетом безупорядоченного выполнения и чтения как следствие данного режима устройство сопряжения с шиной или «записи/чтения» должно обеспечивать следующие условия:
1) Запись никогда не выполняется спекулятивно
2) Запись выполняется только в программном порядке
3) Операции записи диспетчеризуются только когда адрес и данные доступны и нет более старшей записи, ожидающей диспетчеризации
4) Запись может быть блокирована, чтобы дать возможность ее обходить операциям чтения.
5) Возможность «спекулятивного» выполнения чтения когда более младшая операция чтения обгоняет старшиеперации чтения .
Для реализации чтения необходимо:

Для записи

В связи с этим каждому входу очереди запросов на запись соответствует
Очередь SRQ– содержит адрес записи
Очередь SDQ– содержит данные записи
Для очереди на чтение соответствующей очереди LRQ
Вход SDQсодержит результат, который должен быть записан после того, как все предыдущие микрооперации в пуле будут в фазе завершения, как только будет разрешение их удаления данные должны быть записаны в память.
ЛЕКЦИЯ N 14
оТема лекции:
Микроархитектура Pentium 4.
Если кратко характеризовать архитектуру Pentium4 можно отметить следующее.
Процессор Pentium4 также как и Р6 состоит из 3х основных функциональных блоков:
устройство предварительной обработки инструкций в порядке их следования в программном коде. Результатом работы этого блока является последовательность микроопераций, поставляемые в исполнительном блоке.
блок выполнения микроопераций реализующий алгоритм безупорядоченного выполнения.
блок завершения.
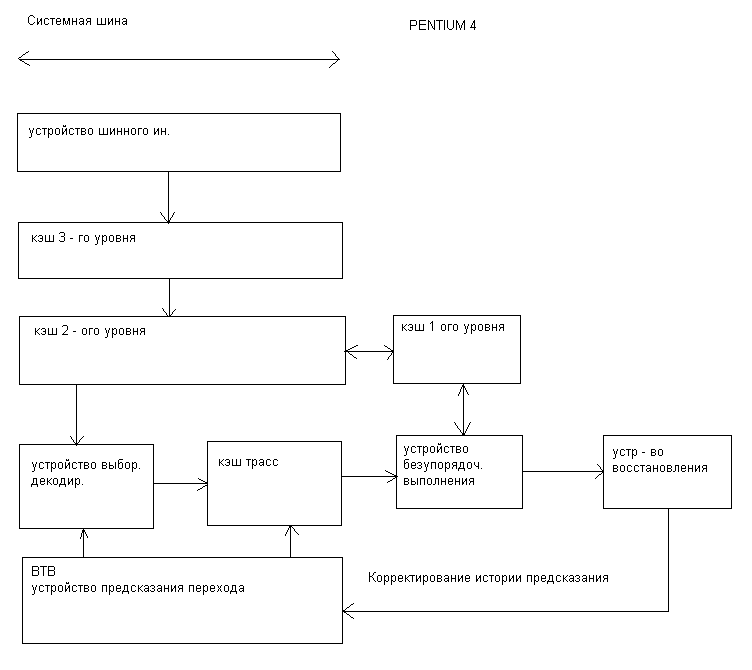
Основное отличие от Р6, это наличие кэш трасс, представляющие память декодированных инструкций т.е. микрооперации, которые читаются из кэш трасс в буферах исполнительного устройства.
Как и в Р6 микрооперации формируются по коду выполнения программы, с той или иной лишь разницей, что эту работу блок предварительной выборки производит заранее и накапливает их в памяти. При этом работает блок предсказания перехода, который выбирает направление выполнения программы и как бы «сшивая» единую последовательность микроопераций, устраивая не только безусловные переходы, но и условные на основании данных в блоке предсказания.
Если при декодировании встречается «сложная» инструкция то как и в Р6 используется постоянная память ROM, в которой уже находиться последовательность микроопераций данной инструкции. При этом эти микрооперации не вставляются в кэш трасс и ставятся на место инструкции «заплатка» - указатель /адрес на место нахождения последовательности микроопераций вROM.
В случае «промаха» в кэш трасс инструкции выбираются из более высокого уровня памяти. Декодируются таким образом поколения кэш трасс. Такая операция формирования сегмента кэш трасс занимает от 10,15 ти тактов до 30 ти т.е., «скрытый участок» конвейера достаточно сложная операция т.к. она проводится заранее и имеет большую «емкость» кэш трасс. Эти издержки вполне допустимы.
Сравнивая количество стадий конвейераустройства выборки/декодирования (без учета формирования очередной линейки кэш трасс) 8 по отношению к 7 стадиям в Р6. Кэш трасс представляет как бы память микропрограмм, формируемая динамически в процессе работы в процессоре и дает возможность многократно выполнять не только повторяющие инструкции но и целый сегмент программного кода.
Так на что же расходуются эти 8 стадий?
Первые 4 такта – извлечение последовательности из кэш трасс и предсказание перехода. Первый раз уже блок формирования адреса перехода выполняет свою функцию при формировании трассы но т.к. от этого момента до выполнения в процессоре проходит достаточно времени и блок предсказания переходов может иметь обновленные данные о ходе выполнения программы , то для «корреляции» в текущем моменте блок активизируется вторично. 1 такт уходит на буферизацию микроинструкции после чтения из кэш трасс и еще 1 такт чтобы выбрать «тройку» микроинструкций из очереди подготовить для нее ресурсы процессора. 2 такта уходит на замену логических регистров в микроинструкциях временными физическими из таблицы замены регистров.
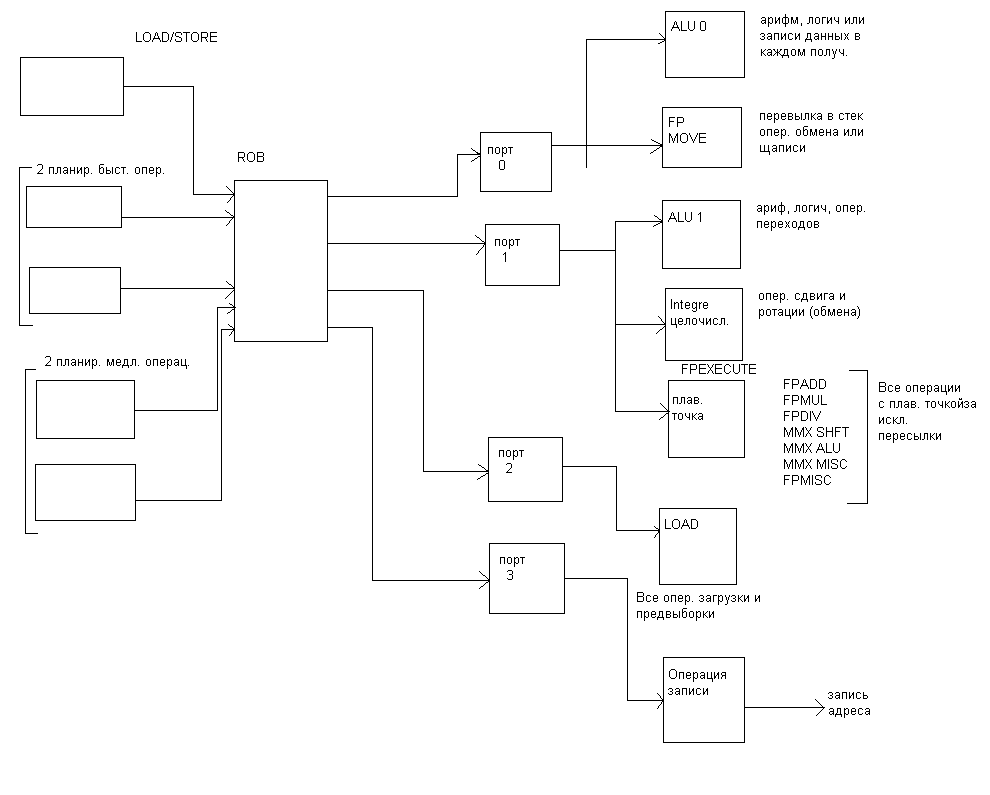
Функциональные исполнительные устройства в Pentium 4
После того как инструкция поступила в пул инструкций, процессор начинает распределять их по соответствующим исполнительным устройствам.
Принцип такой же как и в Р6, но имеет свои особенности.
Во первых, если в Р6 выполнение всех микроинструкций на стадии резервирования управляется одним планировщиком, то в Pent4 таких планировщиков 5, которые «разбирают» микроинструкцию в пуле. Все микрооперации к тому обращения к памяти формируются в отдельную очередь, которую контролирует отдельный планировщик (16 микроопераций).
Все другие формируются в другую очередь, которая управляется 2 мя «быстрыми» и 2 мя «медленными» планировщиками. Всеми простыми арифметически-логическими операциями управляют быстрые планировщики, которые распределяют по 2 микроинструкци за такт.
Второй особенность - микроинструкции отправляются выполняться на исполнительное устройство к тому моменту времени, когда должны поступить операнды из кэш. Если в Р6 схема обработки выглядит так:
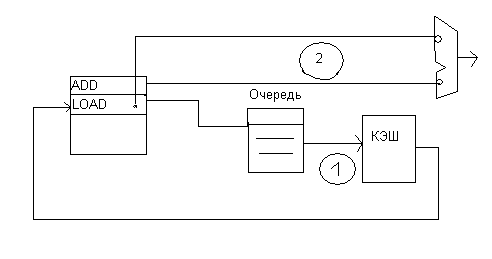
В Pentium4 работают 2 независимых планировщика со своими микрооперациями, согласовывая (синхронизируя) между собой свои действия.
Например. планировщик распределяя микроинструкцию LOADобращаясь за операндом в память, обязан сообщить всем остальным о постановке ее в очередь.. Планировщик, управляющий операцией сложения, в которой участвует этот операнд из памяти обязан поставить в очередь и отправить микрооперацию в исполнительное устройство с задержкой с таким расчетом, чтобы к появлению данных из кэш на шине микроинструкция была в исполнительном устройстве. Это теоретически. На самом деле чтобы избежать критической ситуации, когда данных не будет в кэш, конвейер исполнительного устройства имеет аппаратные средства повторить микроинструкцию, используя дублирующую копию микроинструкции, которая продвигалась параллельно по дублирующему псевдоконвейеру, не подвергаясь обработке в функциональном устройстве. Это делается‘ с той целью чтобы в случае промаха возвратить микроинструкцию на основной конвейер для повтора.
Механизм «Реплей»
Суть этого механизма заключается в том, что в исполнительном устройстве содержится 2 конвейера. Как следует из выше сказанного второй конвейер представляет циклическую память по которой продвигается копия микроинструкции в которой количество циклов равно количеству тактов необходимых для получения информации о наличии данных в кэш. Другая причина ввода петли повтора -это дать возможность планировщику посылать на конвейер и другие микроинструкции, которые имеют зависимости типа RAWот вышестоящей, посылая их на петлю повтора вслед за ней ,таким образом использовать максимально функциональное устройство и увеличить пропускную способность системы.
Следует заметить что данная технология не является совершенной так как могут возникнуть ситуации когда на петлю попадает группа микроинструкций, которые имея зависимость между собой , зацикливание конвейера. А если учесть, что каждый планировщик имеет свою петлю повтора, то ситуации могут возникнуть еще критичней..
Как видно из схемы в случае «промаха» кэш микроинструкции «заворачивают» на запасной путь из 2 ого конвейера, чтобы через некоторую задержку попасть на основной конвейер. При этом блок контроля «сообщает» планировщику о ситуации, чтобы он оставил «дырку» для повтора выполнения операции.
.
Лекция 15
Краткая характеристика Power 4.
Начало направления RISCархитектурыIBMбыло положено сRISCSystem6000 в 1990
Являющейся приемственником серии eServerpSeries.
Начальная модель процессора функционировала в области частот от 20Мгц до 30Мгц. В 1993 году pow2 был разработан, работающ. В области частот от 55Мгц до 71,5Мгц и выполняет до 6 инструкций за цикл (такт).
Параллельно был анонсирован в этом же году pow601, явившийся как результат совместной разработкиIBM,APLbMotorola,Texas.
Все вышеуказанные микропрограммы были 32х разр. Архитектуры. Начиная с RS64 анонсированного в 1997 году иpow3. В 1998 начинается эпоха 64х разрядных архитектур.
Микропроцессоры класса RS64,RS64=2,3,4 през. Запись для коммерческих приложений.
RS64 вначале работали на частоте 125Мгц. Более поздние разработкиRS64 - 4 функционирующий на частоте 750Мгц.
Power- 3 был презентован (оптимизирован) для технологических приложений, работающих изначально на частоте 200Мгц. В дальнейшем модифицирован до 450Мгц.
Power- 4 был разработан для использования как в коммерческих так и в технологических приложениях.Power– 4 был сконструирован в манереPowerPCархитектуры .Изначально заложили для работы на частоте 1,1Ггц и 1,3Ггц.
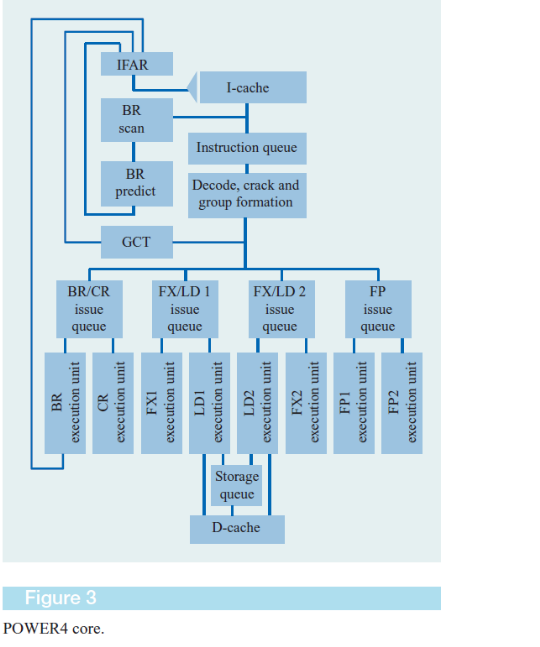
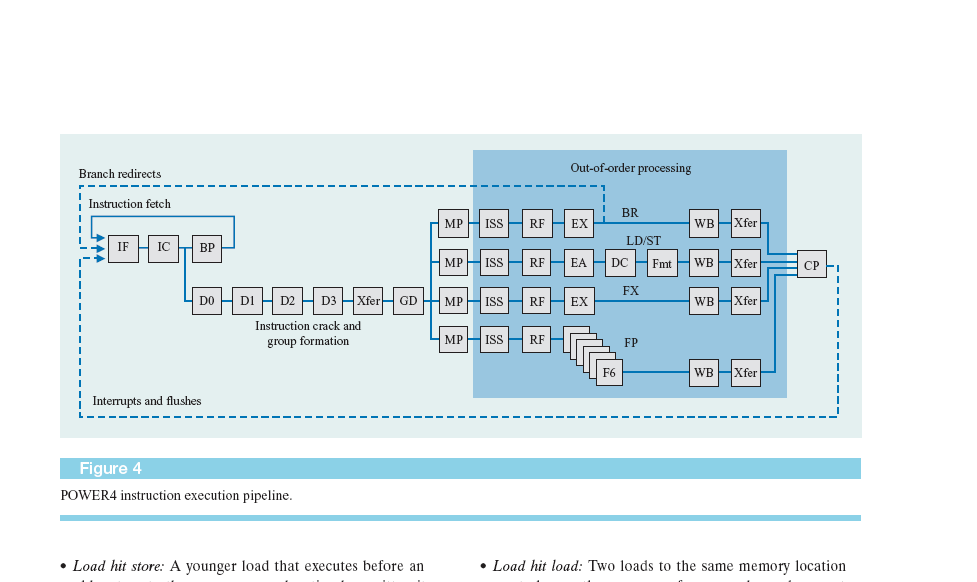
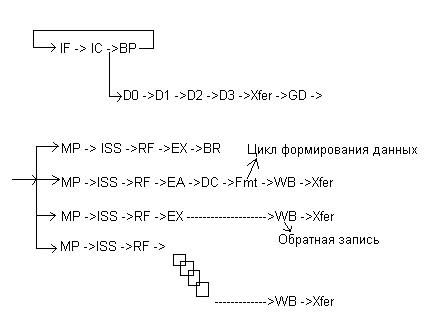
Стадии конвейера Power 4.
IF, IC, BP – циклы предназначенные для выборки инструкций и анализа предсказания перехода.
D0, D1, D2, D3 Xfer, GD – циклы, в течении которых инструкция декодируется и формируется в группы.
MP – цикл, в течении которого выявляются все зависимости, ресурсы, и группа диспетчеризуется в соответствующую очередь.
ISS – данный цикл предназначен для постановки в очередь для выполнения в функциональном устройстве, чтения соответствующего адреса регистра для выбора данных из регистрового файла и формирования адреса для записи результата .
EX – цикл выполнения.
WB – цикл записи в регистр результатов. В этом цикле инструкция заканчивает выполнение, но не завершенной она не моет завершиться по крайней мере еще 2 цикла.
Xfer, CP – циклы предназначенные для завершения всех старших Групп или инструкций в той же группе.
Следует отметить, что инструкции, выбранные из кэш инструкций ждут D1 цикл, если они выбираются раньше, чем попадут в группу. Подобные инструкции могут ждатьMPцикла, если ресурсы недоступны илиISSцикла или СР цикла для завершения.
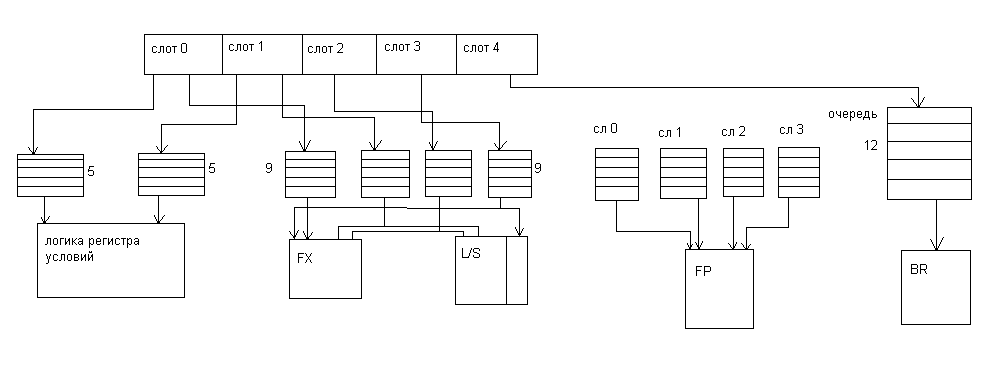
Особенностью архитектуры Power4 является объединение инструкций в группы по 5 инструкций в каждой, которые поступают после формирования на этап диспетчеризации для дальнейшего исполнения в соответствующих исполнительных устройствах. Это делается с целью упрощения механизма отслеживания за выполнением инструкций при безупорядочном выполнении в исполнительных устройствах. Если вINTELотслеживается каждая инструкция и удаляется с конвейера при завершении всех предыдущих, то вPower4 удаляется группа целиком, т.е. 5 инструкций при условии, что все инструкции в группе завершены, и все предыдущие группы удаляются с конвейера.
Power4 имеет так называемую Глобальную таблицу завершения групп. Для увеличения числа инструкций находящихся на исполнении в устройствахPower4 имеет Глобальную таблицу завершения инструкций на 20 входов. Т.е. одновременно отслеживаются 20 групп. Т.е. 20*5=100 инструкций, а при 2х ядерном до 200. Для каждой группы находящейся на этапе выполнения в таблице отводится строка, в которую заложен адрес
1 ой инструкции в группе. Таким образом, частью механизма завершения инструкций в программном порядке.
Индивидуальные группы следуют через систему то есть состояние процессора отслеживается на границе группы ,а не на границе инструкции внутри группы .Любая исключительная ситуация вызывает сохранение старшей группы, предшествующей возникновению причины прерывания.
Группа содержит до пяти внутренних инструкций. На стадии формирования группы инструкции в группе размещаются последовательно. Старшая инструкция в слот 0,следующая за ней в слот 1 и т.д. Слот 4 зарезервирован для инструкций перехода. Только одна группа инструкций распределяется за цикл и все инструкции в группе распределяются одновременно.
Индивидуальные инструкции из очередей в функциональных устройствах поступают на выполнение беcпорядочно. Результат фиксируется ,когда группа завершает выполнение условием которого является ситуация ,когда все старшие группы завершены и завершены все инструкции в группе.
Для осуществления корректного выполнения некоторым инструкциям запрещены спекулятивные операции то есть обгонять впереди идущие в программном коде. Примером таких инструкций являются инструкции чтения и записи в защищенные области памяти или такие как запись в регистры ,фиксирующие состояние процессора.
Для организации безупоряочного выполнения большинство логических (архитектурных) регистров подвергаются преобразованию, но не все . Инструкции, в которых запрещено переименование, размещаются в конце группы
Внутренние инструкции в группе в большинстве своем являются системными командами ,однако, иногда системные команды разбиваются на несколько внутренних при формировании группы. Если системная команда разбивается на две внутренние, то обе они должны быть в одной группе. Если обе инструкции не могут быть размещены в одной группе, то группа заканчивается и новая группа формируется .Инструкция следуемая за разбиваемой может быть размещена в группе при наличии в ней места.
Следует отметить, что при формировании групп учитываются возможности инструкций из слотов в исполнительном устройстве. Так например, в слоте 4 могут располагаться инструкции перехода, если к моменту формирования группы таковой не окажется, то их место 4 ый слота формир. Инструкц. Н.О.П.
Так устройство, обрабатывающее содержимое регистра условий может принимать инструкции только из слота 0 или 1.
В Power4 до 8 инструкций выбираются в каждом цикле из кэш инструкций в прямо. Логика предсказания переходов сканирует выбранные инструкции, просматривая до 2х переходов в каждом цикле. В зависимости от типа найденного перехода, различные механизмы предсказания помогают предсказывать направление и адрес перехода. Безусловные переходы не предсказываются.Pow4 использует 3 таблицы историй переходов. Первая таблица, называемая локальным предсказанием подобна традиционной таблице В.Н.Т. Это 16.384 входов табл (2 в 14 ой степени) индексируем. Адреса инструкций перехода с 1 бит. Предсказания.
Вторая таблица, называемая глобальным предсказанием. Предсказывает направление перехода на действительную траекторию выполнения при каждом переходе. Траекторией прохождения в 11 бит регистре по одному биту на каждую группу инструкций выбранную из кэш для каждой из предыдущих 11 выбранных групп. Этот вектор называется вектором глобальной истории. Каждый бит в глобальной истории была им выбрана следующая группа из последовательного сектора кэш. Вектор глобальной истории собирает информацию о выполнении этих секторов. Т.е. если выбор направления выбранной инструкции и какая либо группа иносказ. Обрабатывается глобальный вектор немедленно модифицируется.
В.Т.В. содержит 3 таблицы:
1) таблица локальных переходов.
2) глобальная таблица
3) Селекторная таблица, осуществляющая фиксацию по каждому предсказанию.
Локальная таблица Глобальная таблица Селекторная таблица
Power 5
1)Организация многопоточного режима.
Для этого на стадии до – после выборки инструкций из кэш они распределяются по 2м потокам отдельные буфера по 24 инструкции каждая. Таким образом, комплектуются группы инструкций из одного потока.
2)Регистровый фаил разделяется между двумя потоками. Т.е. все регистры файла доступны каждому из потоков.
3) Для реализации многопоточности размер и структура очередей были модифицированы.
Таблица GCTдля каждого входа (группы) сигнала содержит дополнительный бит, фиксирующий принадлежность группы к потоку.
Помимо этого каждый логический регистр при замене на физический стал содержать бит
(индекс) принадлежности к потоку. А количество физических регистров было увеличено.
4) Модернизация подверглась очер. Для инструкцииL/S. Дело в том, что области памяти для потоков разнесены в адресном пространстве. Поэтому очереди эти разделились поровну между потоками. А для того, чтобы исключить «пузыри» для этих инструкций организовали виртуальные очереди, в которых фиксируется инструкция при диспетчеризации, но без указания адресов памяти. Как только в реальной очереди освобождается место, инструкция переходит из виртуальной очереди в реальную, и для нее формируется адрес обращения к памяти.
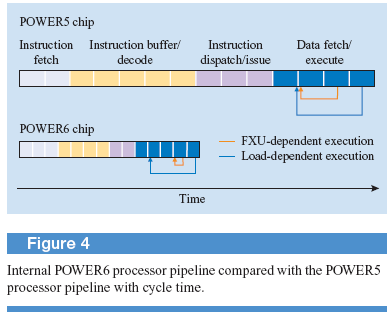
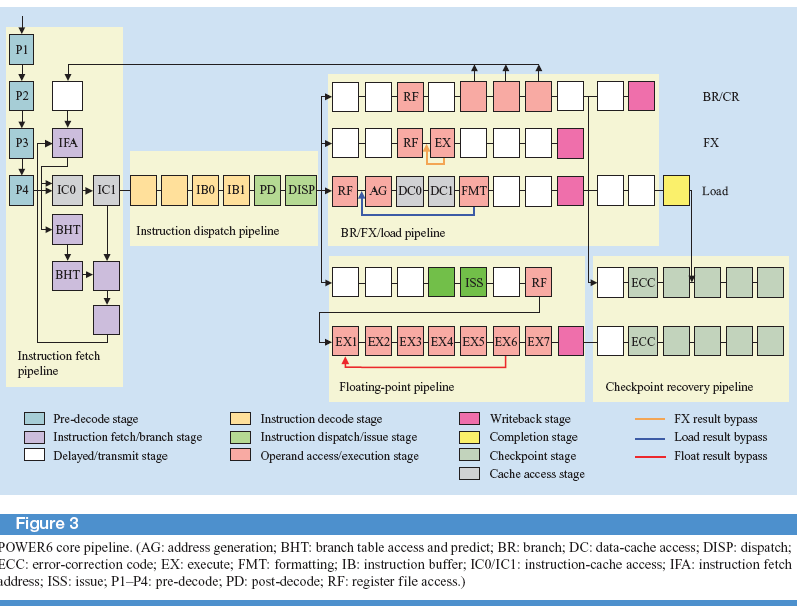
Архитектурные особенности POWER 6
Главной особенностью архитектуры Power6 от предыдущих Р4 и Р5 является вынос за пределы конвейера стадий формирования групп, поступающих на диспетчеризацию. Формирование групп вPower6 осуществляется при переходе инструкций из кэшL2 в
кэш инструкции. Таким образом, в кэш L1 поступают формированные группы. Кроме этого, если в Р4 и Р5 сохраняются зависимости внутри группы, то в Р6 инструкции в группе друг от друга независимы кроме инструкции с плавающей точкой.
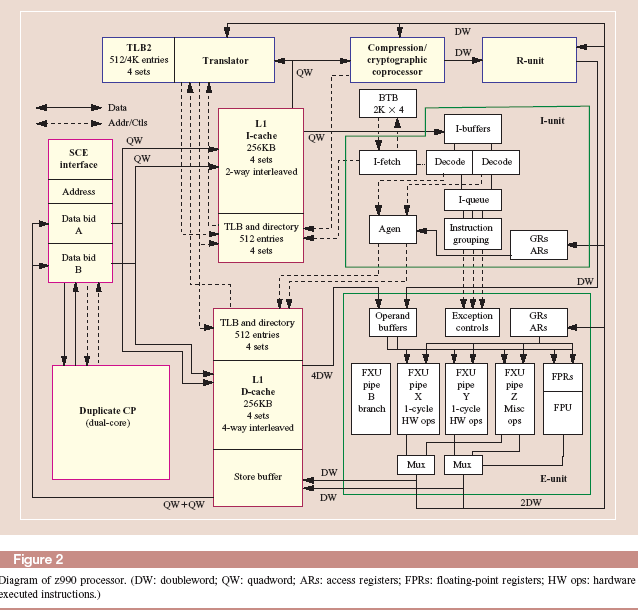
Архитектура микропроцессора Z990
Прежде чем рассматривать архитектуру микропроцессора Z990, необходимо отметить, что данная архитектура явилась результатом эволюции развития серверов предшествующих поколений, родоначальником которых была серия манфреймов IBM360. Особенностью этой серии была CISC архитектура ,которая определяла структуру и форматы команд, реализуемых в процессорах этой серии . Кроме того эти процессора достаточно развитую аппаратную систему диагностики и восстановления работоспособности процессоров ,поддерживаемую на программном уровне специальными системными командами. Хотя эти процессора не были суперскалярными и выполняли только одну инструкцию за цикл, но имели достаточно высокие показатели и характеристики при выполнении сложных CISC команд за счет наличия дополнительных аппаратных средств(акселераторы, блоки логических операций) и мощную систему памяти ,включающую буферные памяти команд и аппаратные средства поддержки преобразования логических адресов в физические.
Внедрение принципов RISC архитектуры при проектировании процессора сопровождалось разработкой и появлением новых языков программирования C, C++, Java, которые использовались для написания программных приложений для пользователей. Для того чтобы сохранить возможность выполнения уже ранее разработанных приложений и новых разработчики архитектуры процессора решили совместить как технологию суперскалярности, так и возможность выполнения сложных команд CISC архитектуры.
При разработке архитектуры микропроцессора были учтены и использованы достижения и наработки в предшествующих моделях процессоров. Это в первую очередь использование милликодов и аппаратные средства восстановления работоспособности системы при возникновении сбоев.
Кроме того в микропроцессореZ990 подобно его предшественникам используется дублирование функционирования основных узлов процессора и содержится несколько механизмов для трансляции его состояния в резервный процессор в случае фатальной ошибки.
В микропроцессоре рассматриваемой архитектуры не используется технология безупорядочного выполнения команд, что является отличительной особенностью от других RISC процессоров. За счет этого была сокращена аппаратная часть микропроцессора поддержки этого режима и ее место заняли схемы дублирования основных узлов и восстановления при возникновении ошибок.
Одним из оригинальных решений при проектировании было решение сохранить использование милликода, который использовался еще в предшествующих моделях.
Для того, чтобы понять, что из себя представляет милликод и как он используется в процессоре, напомним, что существуют два основных метода реализации команд в процессоре. Это микропограммное управление ижесткая логика.
Большинство команд в микропроцессореZ990 реализуется аппаратными средствами, т. е. использует жесткую логику и только сложные команды используют милликод.
Если рассматривать архитектуру микропроцессоров ,например, линейку микропроцессоров PENTIUM фирмы INTEL ,то можно отметить, что при реализации сложных команд ,когда дешифратор не справляется с декодированием инструкции в микроинструкции там используется, так называемый, микрокод ,хранящийся в постоянной памяти микропроцессора , который можно интерпретировать как элемент микропрограммного управления.
С точки зрения методологии подхода к реализации сложных команд нет разницы ,,но отличие заключается в том, что INTEL использовала микроинструкции ,имеющие свою специфичную структуру и формат, а IBM стандартные команды с вертикальным кодированием, таким образом милликод также как основной набор команд выполняется на тех же аппаратных средствах, это во первых. А во-вторых, функциональные возможности милликода намного шире ,чем системные команды, то есть при входе в режим выполнения милликода его рутинам доступны аппаратные средства, которые не доступны даже системным командам.
Размещается милликод ,точнее его рутины в системной памяти в определенной области ,в которую запрещен доступ системным командам и загружается в эту область во время инициализации системы по включению питания то есть эта область по сути выполняет функцию памяти микропрограмм.
И так, отказавшись от технологии микропрограммного управления, IBM сохранила ее метод управления вычислительным процессом за счет
1 Использования особого режима во время выполнения милликода.
2 Расширения функциональных возможностей, что позволило реализовать не только интерпретацию сложных команд, но и выполнять сервисные функции в процессоре, связанные с диагностическими операциями и реализацией механизмов прерывания.
Применение милликода в процессоре позволило разработчикам серверов перенести часть функций при реализации виртуального режима в них с системного уровня на аппаратный и именно этот факт стал при реализации технологии логических партиций LPAR в серверах фирмы IBM, то есть многооперационных систем на одной аппаратной платформе.
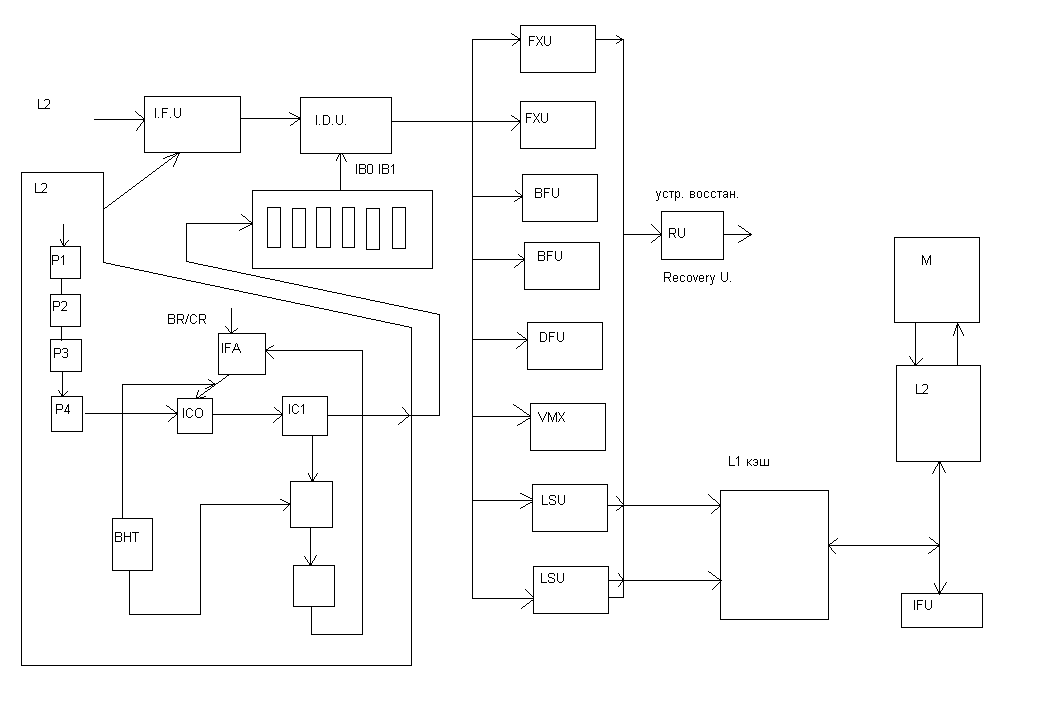
Выборка инструкций и блок предсказания переходов.
Доступ к кэш памяти инструкций по времени занимает 3 цикла конвейера в течении которых формируется запрос в кэш инструкций со стороны устройства выборки инструкций и передача выбранных инструкций в буферные регистры. Обычно эти циклы скрыты и не влияют на производительность процессора так как выборка инструкций из кэш производится с опережением, и была еще использована в свое время в отечественных ЭВМ серии ЕС начиная с ряда2.
В тех случаях когда текст инструкции необходимо декодировать немедленно, то она ,минуя буфер, передается на декодер(случай перевыборки, связанный с командой перехода,.когда целевая инструкция отсутствует в буфере команд)
Устройство выборки имеет 16 буферных регистров, каждый с разрядностью в 4 слова.
Логика предсказания переходов содержит буфер целевых адресов, строки которых содержат, бит предсказания, целевой адрес и адрес самой команды перехода. В случае отсутствия информации в буфере для данной команды перехода принимается решение- нет перехода на целевой адрес.
Помимо этого буфер переходов целевого адреса содержит “историю” переходов, указывая, что на данный момент наиболее вероятен “сильный”,”слабый”или отсутствие перехода в зависимости от величины счетчика переходов.
Декодирование и формирование групп.
Декодеры инструкций могут декодировать любой тип инструкций. Большинство инструкций декодируется в одном цикле. Однако, наиболее сложные требуют более одного цикла для декодирования, к таким, например, относятся двухадресные инструкции, указывающие на расположение операндов в памяти.
Большинство других инструкций декодируются вместе, объединяясь в группу с одним исключением: инструкция перехода должна быть старшей в группе.До трех инструкций может входить в группу.
Совместно с командой перехода, которая является старшей в группе, могут находиться простые, выполняемые за один такт, к которым относятся логические и арифметические операции.
Идея размещения команды перехода старшей в группе связана с тем, что на первый взгляд является парадоксальной, так как эти команды предназначены для анализа признаков результатов от предыдущих команд. Однако выбранная схема при отсутствии безупорядочного выполнения, то есть в порядке следования программному коду дает возможность получать результат перехода в одном цикле с проверяемой командой так как она выполняется в предыдущей группе программного кода.
Во время формирования групп могут иметь место факторы ,которые ограничивают их эффективное выполнение в процессоре и препятствуют включению инструкций в группу. Так ,например ,одним из условий является , что генерация адреса обращения к памяти должна быть завершена до того или в том цикле ,в котором соответствующая инструкция ,использующая этот адрес, включается в группу для исполнения. Кроме того ,если инструкция имеет зависимость при формировании адреса от инструкции уже распределенной в группу,(старшая инструкция производит операцию над базовым или индексным регистрами, являющихся составной частью адреса операнда) то она не включается в группу.
Такие зависимости как RAWв группе между инструкциями запрещены ,с одним исключением .Если такая зависимость существует между инструкциями типа LOUD,выполняющей загрузку данных в регистр из памяти или из другого регистра регистрового файла, а другая использует загружаемый регистр как источник операнда в арифметической или логической операции, то такая комбинация разрешена в группе. Путем простого изменения маршрута на вход исполнительного конвейера продвижение операнда может быть реализовано с минимальными потерями.
Конвейеры операционных устройств
После формирования групп инструкции поступают в исполнительные устройства.
B-конвейер предназначен для определения в действительности будет переход в программе или нет.
Х конвейер выполняет простые инструкции и инструкции милликода .
Y конвейер выполняет простые инструкции.
Z конвейер содержит специальные аппаратные средства для выполнения сложных инструкций, включая операции умножения с фиксированной точкой и десятичную арифметику.
В других случаях при необходимости формируется виртуальный конвейер для обработки 16 байтного потока данных(пересылка символов и операции память-память).
FPU конвейер выполняет операции с плавающей точкой.
Лекция 16
Тема лекции: Мультипрограммный режим работы ЭВМ.
1. Общие принципы организации мультипрограммного режима.
2.Программно аппаратные средства поддержки мультипрограммного режима.
В основу мультипрограммного режима работы ЭВМ положен принцип одновременного выполнения программ в машине.
Определение “одновременный” является чисто условное, так как данный режим был внедрен в архитектуру процессора фон неймановской модели, классифицируемой как SISD- одна инструкция, одни данные. То есть процессор в каждый момент времени в данной архитектуре выполняет одну команду и говорить об одновременном выполнении не только программ ,но команд не имеет смысла. Да, впоследствии, с внедрением конвейерной обработки команд в процессоре стало возможным их одновременное выполнение, причем количество одновременно выполняемых команд стало определяться глубиной конвейера и их количества в процессоре. Но это была технология параллельной обработки команд, принадлежащих одной программе, поэтому понятие “одновременный” в мультипрограммном режиме подразумевает только одновременное нахождение программ в системной памяти процессора, готовых в любое время продолжить выполнение при представлении им процессорного времени.
Идеи мультипрограммного режима работы ЭВМ были выдвинуты в результате анализа занятности ресурсов системы в процессе выполнения программ. Выяснилось, что процессор вынужден простаивать, то есть останавливать выполнение программы из за неготовности ее к работе, в частности отсутствия данных в памяти и ожидания окончания операций ввода вывода, когда эти данные поступят в память.
Для того, чтобы увеличить пропускную способность выполнения задач и была разработана концепция организации мультипрограммной обработки в системе, суть которой сводилась к тому, что при возникновении простоя при выполнении программы представлять ресурсы системы другой.
А для того ,чтобы реализовать это необходимо было ввести в архитектуру комплекс аппаратно программных средств и это в первую очередь управляющей программы, выполняющей функции диспетчера и контроллера за выполнением программ в процессоре.
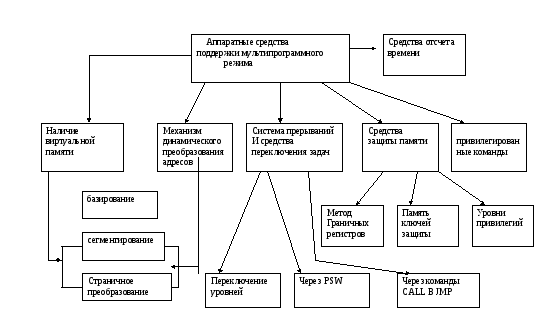
Аппаратные средства поддержки многопрограммного режима в ЭВМ
1. Наличие виртуальной памяти для хранения программного кода и данных, представляемой каждому пользователю потребовало специальных аппаратных средств по преобразованию логических адресов виртуальной памяти в физические и разбиение физической памяти на страницы- области непрерывного адресного пространства . Смысл такого разбиения физической памяти заключается в том ,что и виртуальная память разбивается на такие же по размеру страницы в результате чего операционная система, размещая программы и данные пользователей во внешней памяти системы(диски, ленты), во время выполнения их в процессоре, используя механизм преобразования логических адресов в физические, осуществляет перемещение содержимого виртуальных страниц из внешней памяти в системную. Таким образом, используя концепцию организации виртуальной памяти в системе,
пользователям была предоставлена возможность размещения своих программ и данных вне зависимости от размеров реальной физической памяти в системе.
2. Система прерываний и средства переключения задач.
Механизм прерываний существовал и в однопрограммном режиме.
Особенностью системы прерывания в мультипрограммном режиме является то , что реакцию на большую часть причин прерываний и их обработку осуществляет не программа пользователя , а управляющая программа- супервизор, при этом если прерывание возникло при возникновении ошибки в программе или другой причине не связанной с нарушением работы системы , блокируется только выполнение этой программы с формированием сообщения пользователю о причине останова. Если пользователь в своей программе желает сформировать запрос на прерывание, то в зависимости от среды вычислительной системы ему представляется возможность использования в программе специальных команд- команд программных прерываний( архитектура intel) или команды обращения к супервизору “вызов супервизора” (в архитектуре ibm). Так, например, при обработке программных прерываний пользователю может быть предоставлена возможность блокировки тех или иных причин прерываний путем их маскирования как это делалось в архитектуре отечественных ЭВМ серии ЕС и в настоящее время в z архитектуре.
Что касается механизма переключения задач, то в основу заложен принцип прерывания выполнения программы с той лишь разницей ,что при переключении задач процессор сохраняет при переключении больший объем информации состоянии программы и процессора.
3 Механизм защиты памяти.
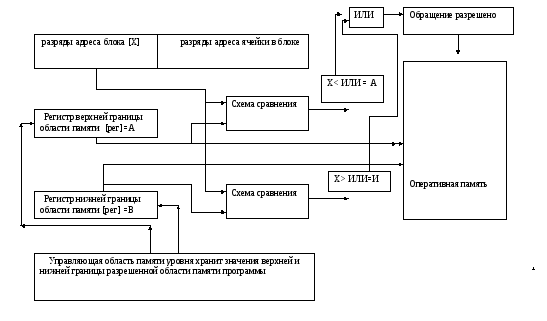
Механизм защиты памяти в мультипрограммном режиме необходим, для того чтобы исключить вмешательство как случайное, так и преднамеренное одной программы в другую.
Существуют различные аппаратные решения реализации механизмов защиты, наиболее применяемые из них – это
Защита с использованием метода верхней и нижней границы области разрешенной памяти, наличие памяти ключей защиты, применение уровней привилегий.
4.Привилегированные команды, которые могут выполняться только на определенных уровнях или при двух уровневой организации в состоянии системы “супервизор”.
5. Средства отсчета времени, которые предназначены для управления выполнением задач в процессоре. Эти средства позволяют контролировать и выделять кванты времени на выполнение задач на аппаратных ресурсах, Супервизор обрабатывает прерывания от таймера, контролирует затраченное время работы процессора по выполнению той или иной программы и по истечении временного кванта размещает на аппаратных ресурсах другую задачу.
Уровни привилегий.
Идея использования уровней привилегий для защиты областей памяти в мультипрограммном режиме была еще реализована в архитектурах ЭВМ второго поколения. Концепция эта используется в современных микропроцессорах, примером тому может быть архитектура микропроцессоров фирмы INTEL, и была реализована в аппаратных средствах механизма сегментации, который помимо использования уровней привилегий для защиты памяти имеет дополнительные возможности и средства ,которые мы и рассмотрим .
Механизм сегментации является основным программно- аппаратным средством защиты информации в системной памяти микропроцессоров фирмы INTEL.
При использовании сегментации памяти каждая программа имеет свой собственный набор сегментов, размещаемых в линейном адресном пространстве .Процессор устанавливает границы между этими сегментами, таким образом исключая возможность вмешательства одной программы в другую. Механизм сегментации позволяет классифицировать сегменты по типу и набору разрешенных операций производимых в границах сегмента, то есть расширяет набор средств защиты памяти.
Все сегменты внутри системы содержатся в линейном адресном пространстве. Для локализации байта в конкретном сегменте должен быть сформирован логический адрес, состоящий из селектора сегмента и смещения. Селектор сегмента является уникальным идентификатором, определяющим смещение в дескрипторной таблице, указывающим на местонахождения в ней дескриптора сегмента. Каждый дескриптор определяет размер сегмента ,тип сегмента, права доступа, уровень привилегий, местонахождение первого байта в сегменте (называемым базовым адресом сегмента)
Смещение сегмента складывается со значением базового адреса для определения положения байта внутри сегмента, эта сумма называется линейным адресом.
Процессор транслирует каждый логический адрес в линейный.
Трансляция логического адреса в линейный адрес производится в три этапа.
Использует смещение в селекторе сегмента для локализации дескриптора сегмента в глобальной или локальной (задачи) дескрипторной таблице и читает содержимое дескриптора в свои регистры.
Осуществляет контроль дескриптора сегмента с целью проверки прав доступа к сегменту и проверяет значение смещения с пределом, указывающим размер сегмента.
Производит сложение адреса из дескриптора со смещением ,если не обнаружено нарушение защиты, то есть формирует логический адрес.
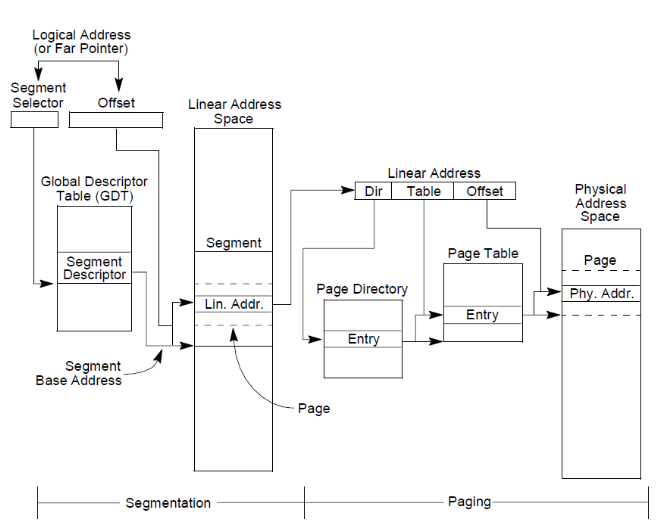
На данной схеме изображены два независимых этапа преобразования логического адреса в физический адрес: сегментация и страничное преобразование. Как видно из схемы сегментация адресов в процессоре не связана с режимом виртуализации системной памяти и полностью возложена на этап страничного преобразования ,то есть механизм сегментации задействован всегда и в том случае, когда страничное преобразование не используется линейный адрес становится физическим автоматически.
Следует отметить, что в некоторых архитектурах сегментация памяти используется как начальный или промежуточный этап преобразования логического адреса в физический. Примером тому архитектура процессоров фирмы IBM.
 .
.
Лекция N17
Тема лекции: Организация мультипрограммного режима работы ЭВМ.
1.Понятие задачи, структура задачи, структурные данные для управления задачи.
2.Механизм, обеспечивающий переключение выполнения задач в мультипрограммной среде вычислительной системы.
Для организации мультипрограммного режима работы вычислительной системы ее архитектура содержит аппаратно программные средства ,как уже упоминалось выше.
Для того чтобы рассмотреть подробно организацию выполнения задачи, переход от одной задачи к другой в качестве примера рассмотрим, как это реализуется в механизме переключения задач в процессорах INTEL.
Архитектура процессоров INTEL в составе имеет блок сегментации, который в свою очередь не только организует механизм защиты доступа ко всем структурным данным, расположенным в виртуальной памяти, но и реализует доступ к ним в соответствующих сегментах. Поэтому,
переключение задач , cвязанное с доступом к памяти также использует блок сегментации , используя при этом соответствующие структуры системных данных и дескрипторы, определяющие их специфику и расположение в виртуальной памяти.
И так прежде чем рассматривать работу этого механизма, сформулируем определение задачи , ее структуру и структуры системных данных для ее управления.
Задача – это единица работы которую процессор может активизировать ,выполнять и задержать выполнение.
Эта структура может быть использована для выполнения программы, задания или процесса, сервисной утилиты операционной системы ,обработки прерывания или исключения.
При работе процессора в защищенном режиме все действия процессора трактуются как действия внутри задачи то есть в самом простом варианте функционирование системы представляется как выполнение, по крайней мере одной задачи. В случае выполнения нескольких задач включается программно аппаратный комплекс для их переключения.
Структура задачи.
Задача состоит из двух частей:
область выполнения
сегмент состояния задачи
Область выполнения включает сегмент кода, сегмент стека один или более сегменты данных.
Сегмент состояния задачи используется для ее выполнения и является местом записи ее текущего состояния при переключении в мульти программном режиме.
Состояние задачи определяется:
областью текущего выполнения, которая представлена сегментными селекторами в сегментных регистрах
состоянием регистров общего назначения
состоянием регистра флагов
состоянием управляющего регистра, в котором хранится физический адрес каталога страниц
содержимым регистра задачи
содержимым регистра локальной дескрипторной таблицы, в котором находится селектор, указывающий на строку в глобальной дескрипторной таблице . В этой строке размещается базовый адрес локальной дескрипторной таблицы , оформленной как системный сегмент.
Базовым адресом карты ввода вывода
Звеном к предыдущей задаче
Стеком указателей к уровням привилегий 0,1, 2
Структуры данных для управления задачи представлены
Сегментом состояния задачи
Дескриптором шлюза задачи
Дескриптором сегмента состояния задачи
Регистром задачи
Флагом вложенной задачи в регистре флагов
Сегмент состояния задачи
Информация состояния процессора необходимая для восстановления задачи при переключении хранится в сегменте состояния задачи, в который эта информация была записана ранее в момент прерывания.
Помимо выше указанной информации о состоянии задачи в сегмент состояния задачи записывается адрес текущей инструкции и содержимое регистра флагов.
Рассматривая в свое время многоуровневую организацию памяти в вычислительной системе , мы отметили об использовании виртуальной памяти как об одном из средств поддержки организации мультипрограммного режима в системе. Мы уже говорили ранее, что при использовании технологии виртуализации системной памяти используется механизм преобразования логических адресов в физические. Следует помнить, что в архитектуре процессоров фирмы INTEL блок сегментации не является частью механизма преобразования логических адресов памяти в физические. Он является частью аппаратных средств системы для организации сегментированной виртуальной памяти, в которой она представлена системе набором сегментов - непрерывных областей памяти различного размера, доступ к которым осуществляется через дескрипторы, организованные в таблицы.
Доступ же к ним осуществляется через селекторы, которые находятся в соответствующих регистрах сегментов кода, данных и стека.
Мы еще будем разбирать , когда и каким образом селекторы загружаются в соответствующие регистры сегментов, а сейчас разберем форматы и типы дескрипторов.
Код тип дескрипторов
11.10.98
0 0 0 0 – резерв.
0 0 0 1 – 16 бит. TSS(доступен)
0 0 1 0 – LDT
0 0 1 1 – 16 бит. TSS(занят)
0 1 0 0 – 16 бит. Шлюз вызова
0 1 0 1 – шлюз задачи
0 1 1 0 – 16 бит. Шлюз прерыв.
0 1 1 1 – 16 бит. Шлюз пов.
1 0 0 0 – резерв.
1 0 0 1 – 32 бит. TSS(доступен)
1 0 1 0 – резерв.
1 0 1 1 - 32 бит. TSS(занят)
1 1 0 1 – резерв.
1 1 1 0 - 32 бит. Шлюз. прерыв.
1 1 1 1 - 32 бит. Шлюз пов.
Типы системных дескрипторов.
Когда S( тип дескриптора ) установлен в дескриптор является системным.
Процессор распознает следующие типы дескрипторов.
дескриптор LDT
дескриптор TSS
дескриптор шлюза вызова
дескриптор шлюза ловушка
дескриптор шлюза задачи
дескриптор шлюза прерывания
Эти дескрипторы разделяются на 2 категории:
Системные дескрипторы, указывающие на вход к системным сегментам ( LDTиTSS)
Дескрипторы шлюзов, которые содержат сами указатели к точкам входа в процедурах в сегментах кода и селектора их дескриптора.
Дескрипторные сегментные таблицы – область сегментных дескрипторов. Дескрипторная таблица может быть различных размеров и может содержать до 8192 (2^13) 8 байтные дескрипторов.
Различают 2 вида таблицы LDTиGDT. Каждая система должна иметь однуGDT, которая может быть использована для всех программ и задач в системе, в то время как одна или большеLDTможет быть определено. НапримерLDTможет быть назначена для каждой отдельной задачи или несколько задач могут иметь ту же самуюLDT.GDTне является сама сегментом, т.е. она является структурой данных в линейном адресном пространстве. Базовый линейный адрес и пределGDTдолжен быть выровнен по 8 байтной границе. Величина предела дляGDTвыражается в байтах также как и для сегментов.Limit+ база адрес определяет послед байт достоверный в таблице.
Величина лимита=0 соответствует 1 байт, поэтому т.к. дескриптор сегмента 8 байт, предел GDTдолжен быть на 1 меньше т.е. 8N-1.
Все программы, выполняющиеся в системе могут использовать эту таблицу для обращения к сегментам памяти. Для локализации таблицы предназначен специальный регистр GDTR, в котором находится 32-х битное поле линейного базового адреса таблицы
1ый дескриптор в GDTне используется в процессоре. Селектор сегмента для этих «нулевых» дескрипторов не генерирует исключения, когда загружен в регистр сегмента данных (DS,ES,FS,GS), но всегда генерирует исключение в защищенном режиме, когда делается попытка доступа к памяти, используя дескриптор.
LDTразмещается в системном сегменте поэтомуGDTдолжна содержать сегментный дескриптор дляLDTсегмента. Если система поддерживает несколькоLDT, каждая таблица должна иметь отдельный селектор сегмента и сегментный дескриптор вGDT. Сегментный дескриптор дляLDTможет быть размещен в любом местеGDT.
LDTдоступна через ее селектор, базовый линейный адрес, предел, права доступа.
Дескриптор LDT
|
База сегм. 15:-0 |
Lim 15:-0 |
G P тип
-
База 31:-24
0
0
0
Lim 16:-19
DPL
База 16:-23
Поле DPLв дескрипторе дляLDTне используется.
И так при переключении задач для доступа к сегментам состояния задач имеется два вида дескрипторов.
Дескриптор сегмента состояния задачи является прямым указателем на расположение сегмента состояния задачи в линейном адресном пространстве виртуальной памяти и соответственно содержит адрес начала сегмента в памяти.
Дескриптор шлюза задачи является элементом косвенной адресации при обращении к сегменту состояния задачи.
Введение дополнительного этапа адресации объясняется следующими причинами.
Во первых, дескрипторы сегментов состояния задач могут находиться только в глобальной дескрипторной таблице и обычно имеют наивысший уровень привилегий (DPL=0).
Для того, чтобы структура задачи могла использоваться на других уровнях привилегий и при обработки прерываний и исключений и программах пользователей и был введен этот дополнительный этап, то есть дескриптор шлюза задачи содержит селектор, который указывает на строку с дескриптором сегмента состояния задачи в глобальной таблице.
Во вторых дескриптор шлюза задачи имеет свой уровень привилегий и при обращении к нему действует механизм защиты
[CPL,RPL]<,=DPL шлюза задачи
Таким образом, операционная система, располагая дескрипторы шлюзов задач с одним и тем же значением селектора может организовать доступ к одной задаче с разных уровней привилегий и расположить эти дескрипторы не только в глобальной таблице , но и локальных и таблице прерываний потому что при обращении к дескриптору состояния задачи через шлюз проверка уровня DPL дескриптора сегмента состояния задачи блокируется.
Регистр задачи.
Регистр задачи предназначен для хранения 16 битного селектора сегмента состояния задачи во время ее выполнения в процессоре причем значение селектора сегмента состояния задачи является видимой частью регистра то есть доступной для чтения и изменения программным обеспечением , а невидимая его часть, которая доступна только аппаратным средствам, предназначена для кэширования самого дескриптора сегмента состояния задачи .
Дав определение задачи, как единице работы, следует помнить что понятие задачи классифицирует процесс в вычислительной системе не с точки зрения объема и сложности выполняемых вычислений ,а c точки зрения цели, поставленной при постановке задачи. Поэтому, в зависимости от сложности задачи она может быть представлена одной или несколькими программами и даже состоять из нескольких функциональных модулей, сформированных в виде самих задач.
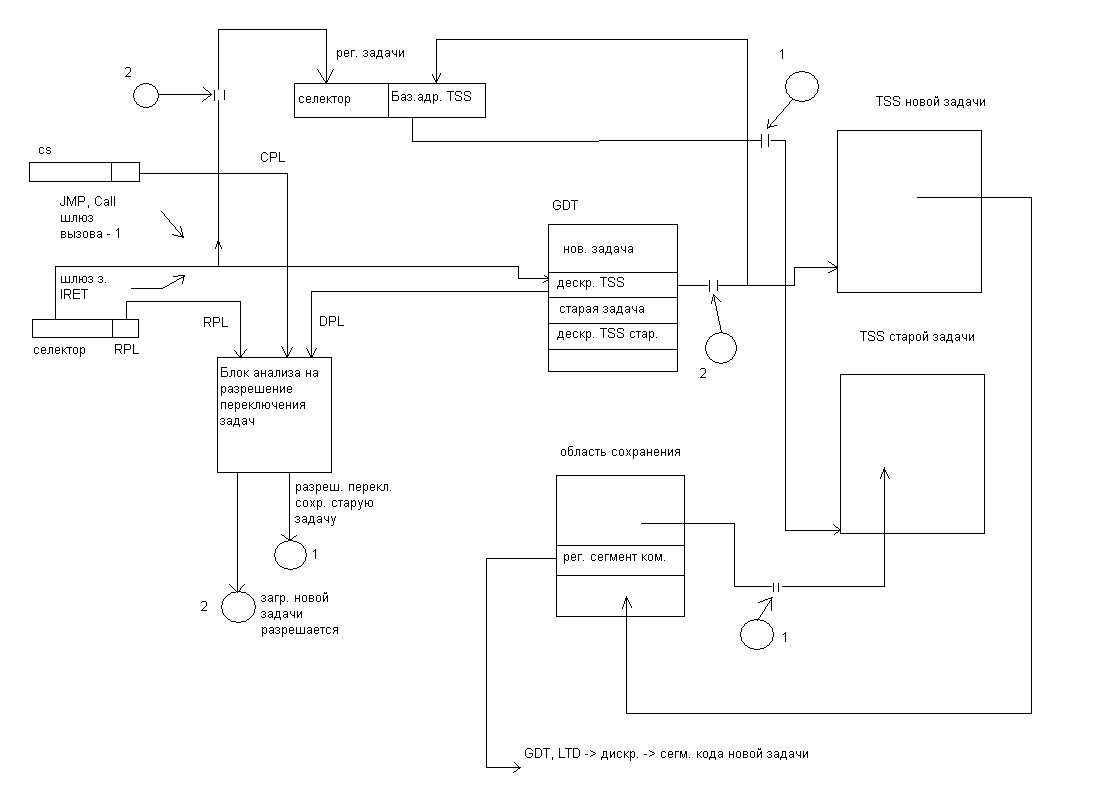
Связь между этими блоками во время выполнения задачи осуществляется через аппаратно-программный интерфейс , активизируемый системными командами CALLи JMP
Передача управления от одного сегмента к другому осуществляется и внутри задачи через дескрипторы сегментов, поэтому для передачи управления от одной задачи к другой используются специальные дескрипторы, классифицируемые как системные данные для управления задачами.
Для того, чтобы осуществлять связь между модулями внутри задачи оформленными в свою очередь как самостоятельные задачи, вводятся аппаратные средства в виде флагов, указывающих на вложенность одной задачи в другую.