

Вопросы для самоконтроля
Состав технико-экономических показателей.
Натуральные показатели. Примеры.
Стоимостные показатели. Примеры.
Как оценивается объем производства?
Показатели использования средств производства.
Определения основных технико-экономических показателей.
Лабораторная работа № 5: Элементы dm-технологий в среде ms Excel Справочный материал
DM-технология
Развитие методов записи и хранения данных привело к бурному росту объемов собираемой и анализируемой информации. Объемы данных настолько внушительны, что человеку просто не по силам проанализировать их самостоятельно, хотя необходимость проведения такого анализа вполне очевидна, ведь в этих "сырых" данных заключены знания, которые могут быть использованы при принятии решений. Для того чтобы провести автоматический анализ данных, используется Data Mining.
Data Mining – это процесс обнаружения в "сырых" данных ранее неизвестных нетривиальных практически полезных и доступных интерпретации знаний, необходимых для принятия решений в различных сферах человеческой деятельности. Data Mining является одним из шагов Knowledge Discovery in Databases.
Алгоритмы, используемые в Data Mining, требуют большого количества вычислений. Раньше это являлось сдерживающим фактором широкого практического применения Data Mining, однако сегодняшний рост производительности современных процессоров снял остроту этой проблемы. Теперь за приемлемое время можно провести качественный анализ сотен тысяч и миллионов записей.
Задачи, решаемые методами Data Mining:
Классификация – это отнесение объектов (наблюдений, событий) к одному из заранее известных классов.
Регрессия, в том числе задачи прогнозирования. Установление зависимости непрерывных выходных от входных переменных.
Кластеризация – это группировка объектов (наблюдений, событий) на основе данных (свойств), описывающих сущность этих объектов. Объекты внутри кластера должны быть "похожими" друг на друга и отличаться от объектов, вошедших в другие кластеры. Чем больше похожи объекты внутри кластера и чем больше отличий между кластерами, тем точнее кластеризация.
Ассоциация – выявление закономерностей между связанными событиями. Примером такой закономерности служит правило, указывающее, что из события X следует событие Y. Такие правила называются ассоциативными. Впервые эта задача была предложена для нахождения типичных шаблонов покупок, совершаемых в супермаркетах, поэтому иногда ее еще называют анализом рыночной корзины (market basket analysis).
Последовательные шаблоны – установление закономерностей между связанными во времени событиями, т.е. обнаружение зависимости, что если произойдет событие X, то спустя заданное время произойдет событие Y.
Анализ отклонений – выявление наиболее нехарактерных шаблонов.
Проблемы бизнес анализа формулируются по-иному, но решение большинства из них сводится к той или иной задаче Data Mining или к их комбинации. Например, оценка рисков – это решение задачи регрессии или классификации, сегментация рынка – кластеризация, стимулирование спроса – ассоциативные правила. Фактически, задачи Data Mining являются элементами, из которых можно собрать решение подавляющего большинства реальных бизнес задач.
Регрессия и задача прогнозирования
Для построения уравнения регрессии необходимо определить факторы, от которых планируется построить уравнение.
Информативность факторов можно оценить с использованием коэффициента парной корреляции.
Показателем
тесноты линейной взаимосвязи между
переменными Х и Y является выборочный
коэффициент парной корреляции
![]() .
.
Величину коэффициента корреляции можно найти в MS Excel с помощью: Данные/ анализ данных / КОРРЕЛЯЦИЯ
если r > 0, то говорят о прямой корреляционной зависимости между Х и Y: при увеличении Х величина Y имеет тенденцию в среднем возрастать;
если r < 0, то говорят об обратной корреляционной зависимости между Х и Y: при увеличении Х величина Y имеет тенденцию в среднем уменьшаться;
в зависимости от того, насколько
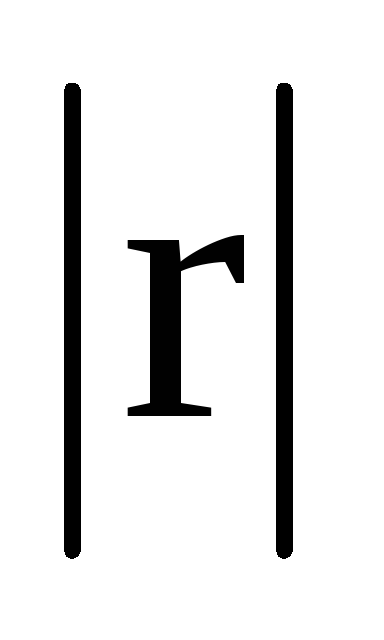 приближается к 1, различают три уровня
корреляционной зависимости:
приближается к 1, различают три уровня
корреляционной зависимости:
слабую (при
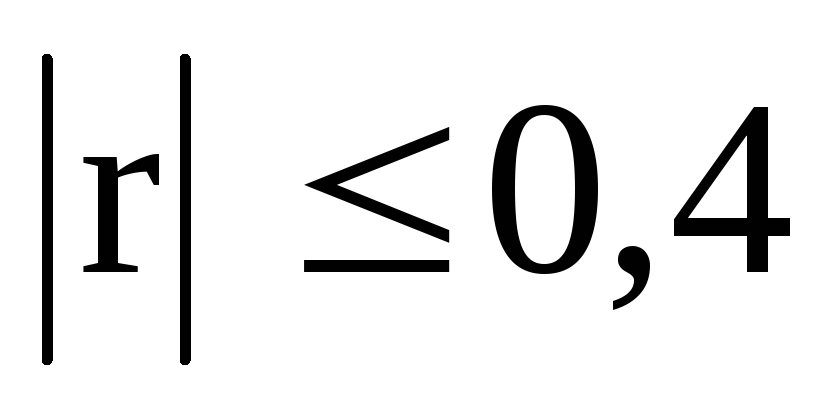 ),
),умеренную (при
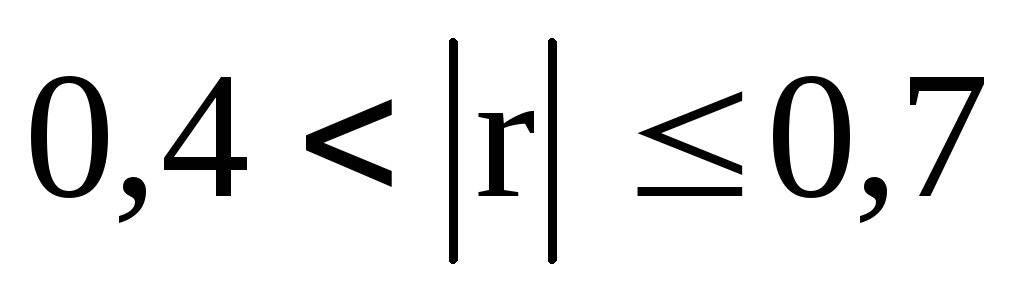 ),
),тесную (при
 ).
).
Практически в каждом отдельном случае результирующая величина Y складывается из двух слагаемых:
![]() ,
,
где Y – фактическое значение результирующего показателя;
![]() –теоретическое
(расчетное) значение этого показателя;
–теоретическое
(расчетное) значение этого показателя;
– случайная
величина, характеризующая отклонение
фактического значения Y от расчетного
![]() из-за неучтенных в модели факторов и
случайных ошибок.
из-за неучтенных в модели факторов и
случайных ошибок.
Уравнение
![]() называется уравнением регрессии.
называется уравнением регрессии.
Построить модель – значит определить ее коэффициенты и записать ее уравнение не в общем, а в пригодном для расчетов виде.
Универсальным способом построения линейных моделей (как парных, так и множественных) является в MS Excel программа РЕГРЕССИЯ (Данные / анализ данных / РЕГРЕССИЯ).
Прогнозирование – это оценка значений результирующего показателя Yв некоторой, представляющей практический интерес прогнозной ситуации, которая описывается факторными переменными Х*.
Прогнозные значения Х*факторных переменных либо задаются, либо рассчитываются отдельно. Предполагают, что в период прогнозирования сохраняются существующие взаимосвязи между переменными.
Точечный прогноз величины Y выполняется
по уравнению модели путем подстановки
в него соответствующих значений факторных
переменных
![]() .
.
В случае парной модели
![]() - ожидаемое значение признака Y.
- ожидаемое значение признака Y.
Реальные значения Y скорее всего будут
отличаться от рассчитанных прогнозных
![]() .
Это отличие объясняется двумя причинами:
.
Это отличие объясняется двумя причинами:
1) расчет
![]() проведен по уравнению регрессии,
коэффициенты aj которого найдены по
выборочным данным, являются случайными
величинами со стандартными отклонениями
S(aj). Значит
проведен по уравнению регрессии,
коэффициенты aj которого найдены по
выборочным данным, являются случайными
величинами со стандартными отклонениями
S(aj). Значит![]() – тоже случайная величина и имеет
стандартное отклонение
– тоже случайная величина и имеет
стандартное отклонение![]() ;
;
2) согласно уравнению эконометрической
модели
![]() ,
т.е. реальное (индивидуальное) значение
результирующего признака может
отклоняться от расчетного (теоретического)
на случайную величину,
что увеличивает стандартную ошибку
,
т.е. реальное (индивидуальное) значение
результирующего признака может
отклоняться от расчетного (теоретического)
на случайную величину,
что увеличивает стандартную ошибку![]() по сравнению с
по сравнению с![]() .
.