

КЛ_АВС
.pdfВ целом уровни памяти характеризуются пятью параметрами.
1.Время доступа, включая задержки на всех промежуточных уровнях;
2.Объем памяти данного типа в системе;
3.Стоимость хранения единицы информации;
4.Полоса пропускания, т. е. количество единиц информации за единицу времени, переданные на следующий уровень;
5.Размер блока – приблизительное количество единиц информации, перемещаемых между соседними уровнями за 1 раз.
Иерархия памяти РС должна обладать следующими тремя свойствами:
1.включение - если некоторые значения могут быть найдены на другом уровне, оно должно присутствовать на всех уровнях, расположенных ниже;
2.конкретность – все копии одного и того же значения должны быть идентичны;
3.локальность – программа осуществляет доступ к ограниченному адресному пр-ву памяти в каждый временной интервал.
Для реальных иерархий эти требования не выполняются.
Организация КЭШ – памяти.
Кэш-память представляет собой быстродействующее ЗУ, размещенное на одном кристалле с ЦП или внешнее по отношению к ЦП. Кэш служит высокоскоростным буфером между ЦП и относительно медленной основной памятью. Идея кэш-памяти основана на прогнозировании наиболее вероятных обращений ЦП к оперативной памяти. В основу такого подхода положен принцип временной и пространственной локальности программы.
Если ЦП обратился к какому-либо объекту оперативной памяти, с высокой долей вероятности ЦП вскоре снова обратится к этому объекту. Примером этой ситуации может быть код или данные в циклах. Эта концепция описывается принципом временной локальности, в соответствии с которым часто используемые объекты оперативной памяти должны быть "ближе" к ЦП (в кэше).
При обращениях к кэш-памяти на реальных программах преобладают обращения по чтению. Все обращения за командами являются обращениями по чтению и большинство команд не пишут в память. Обычно операции записи составляют менее 10% общего трафика памяти. Желание сделать общий случай более быстрым означает оптимизацию кэш-памяти для выполнения операций чтения, однако при реализации высокопроизводительной обработки данных нельзя пренебрегать и скоростью операций записи.
К счастью, общий случай является и более простым. Блок из кэшпамяти может быть прочитан в то же самое время, когда читается и сравнивается его тег. Таким образом, чтение блока начинается сразу как только становится доступным адрес блока. Если чтение происходит с попаданием, то блок немедленно направляется в процессор. Если же
81
происходит промах, то от заранее считанного блока нет никакой пользы, правда нет и никакого вреда.
Однако при выполнении операции записи ситуация коренным образом меняется. Именно процессор определяет размер записи (обычно от 1 до 8 байтов) и только эта часть блока может быть изменена. В общем случае это подразумевает выполнение над блоком последовательности операций чтение-модификация-запись: чтение оригинала блока, модификацию его части и запись нового значения блока. Более того, модификация блока не может начинаться до тех пор, пока проверяется тег, чтобы убедиться в том, что обращение является попаданием. Поскольку проверка тегов не может выполняться параллельно с другой работой, то операции записи отнимают больше времени, чем операции чтения.
Очень часто организация кэш-памяти в разных машинах отличается именно стратегией выполнения записи. Когда выполняется запись в кэшпамять имеются две базовые возможности:
сквозная запись (write through, store through) - информация записывается в два места: в блок кэш-памяти и в блок более низкого уровня памяти.
запись с обратным копированием (write back, copy back, store in) -
информация записывается только в блок кэш-памяти. Модифицированный блок кэш-памяти записывается в основную память только когда он замещается. Для сокращения частоты копирования блоков при замещении обычно с каждым блоком кэш-памяти связывается так называемый бит модификации (dirty bit). Этот бит состояния показывает был ли модифицирован блок, находящийся в кэш-памяти. Если он не модифицировался, то обратное копирование отменяется, поскольку более низкий уровень содержит ту же самую информацию, что и кэш-память.
Оба подхода к организации записи имеют свои преимущества и недостатки. При записи с обратным копированием операции записи выполняются со скоростью кэш-памяти, и несколько записей в один и тот же блок требуют только одной записи в память более низкого уровня. Поскольку в этом случае обращения к основной памяти происходят реже, вообще говоря требуется меньшая полоса пропускания памяти, что очень привлекательно для мультипроцессорных систем. При сквозной записи промахи по чтению не влияют на записи в более высокий уровень, и, кроме того, сквозная запись проще для реализации, чем запись с обратным копированием. Сквозная запись имеет также преимущество в том, что основная память имеет наиболее свежую копию данных. Это важно в мультипроцессорных системах, а также для организации ввода/вывода.
Когда процессор ожидает завершения записи при выполнении сквозной записи, то говорят, что он приостанавливается для записи (write stall). Общий
82
прием минимизации остановов по записи связан с использованием буфера записи (write buffer), который позволяет процессору продолжить выполнение команд во время обновления содержимого памяти. Следует отметить, что остановы по записи могут возникать и при наличии буфера записи.
Вструктуре кэш-памяти выделяют два типа блоков данных:
память отображения данных (собственно сами данные, дублированные из
оперативной памяти);
память тегов (признаки, указывающие на расположение кэшированных данных в
оперативной памяти).
Пространство памяти отображения данных в кэше разбивается на строки - блоки фиксированной длины (например, 32, 64 или 128 байт). Каждая строка кэша может содержать непрерывный выровненный блок байт из оперативной памяти. Какой именно блок оперативной памяти отображен на данную строку кэша, определяется тегом строки и алгоритмом отображения. По алгоритмам отображения оперативной памяти в кэш выделяют три типа кэш-памяти:
полностью ассоциативный кэш;
кэш прямого отображения;
множественный ассоциативный кэш.
Для полностью ассоциативного кэша характерно, что кэш-контроллер может поместить любой блок оперативной памяти в любую строку кэшпамяти. В этом случае физический адрес разбивается на две части: смещение в блоке (строке кэша) и номер блока. При помещении блока в кэш номер блока сохраняется в теге соответствующей строки. Когда ЦП обращается к кэшу за необходимым блоком, кэш-промах будет обнаружен только после сравнения тегов всех строк с номером блока.
Одно из основных достоинств данного способа отображения - хорошая утилизация оперативной памяти, т.к. нет ограничений на то, какой блок может быть отображен на ту или иную строку кэш-памяти. К недостаткам следует отнести сложную аппаратную реализацию этого способа, требующую большого количества схемотехники (в основном компараторов), что приводит к увеличению времени доступа к такому кэшу и увеличению его стоимости.
83
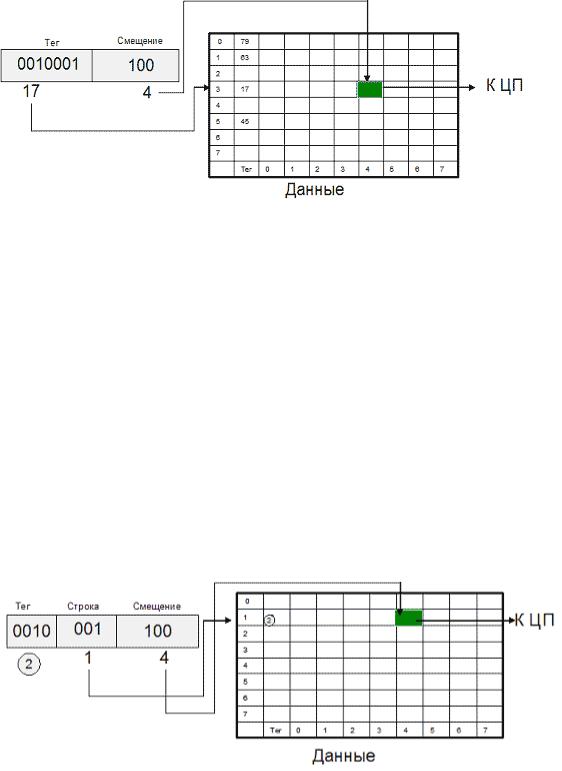
Полностью ассоциативный кэш 8х8 для 10-битного адреса
Альтернативный способ отображения оперативной памяти в кэш - это кэш прямого отображения (или одновходовый ассоциативный кэш). В этом случае адрес памяти (номер блока) однозначно определяет строку кэша, в которую будет помещен данный блок. Физический адрес разбивается на три части: смещение в блоке (строке кэша), номер строки кэша и тег. Тот или иной блок будет всегда помещаться в строго определенную строку кэша, при необходимости заменяя собой хранящийся там другой блок. Когда ЦП обращается к кэшу за необходимым блоком, для определения удачного обращения или кэш-промаха достаточно проверить тег лишь одной строки.
Очевидными преимуществами данного алгоритма являются простота и дешевизна реализации. К недостаткам следует отнести низкую эффективность такого кэша из-за вероятных частых перезагрузок строк. Например, при обращении к каждой 64-й ячейке памяти в системе кэшконтроллер будет вынужден постоянно перегружать одну и ту же строку кэш-памяти, совершенно не задействовав остальные.
Кэш прямого отображения 8х8 для 10-битного адреса
Несмотря на очевидные недостатки, данная технология нашла успешное применение, например, в МП Motorola MC68020, для организации кэша инструкций первого.
Компромиссным вариантом между первыми двумя алгоритмами является множественный ассоциативный кэш или частично-ассоциативный кэш. При этом способе организации кэш-памяти строки объединяются в
84
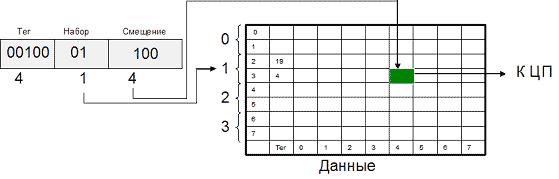
группы, в которые могут входить 2, 4, : строк. В соответствии с количеством строк в таких группах различают 2-входовый, 4-входовый и т.п. ассоциативный кэш. При обращении к памяти физический адрес разбивается на три части: смещение в блоке (строке кэша), номер группы (набора) и тег. Блок памяти, адрес которого соответствует определенной группе, может быть размещен в любой строке этой группы, и в теге строки размещается соответствующее значение. Очевидно, что в рамках выбранной группы соблюдается принцип ассоциативности. С другой стороны, тот или иной блок может попасть только в строго определенную группу, что перекликается с принципом организации кэша прямого отображения. Для того чтобы процессор смог идентифицировать кэш-промах, ему надо будет проверить теги лишь одной группы (2/4/8/: строк).
Двухвходовый ассоциативный кэш 8х8 для 10-битного адреса
Данный алгоритм отображения сочетает достоинства как полностью ассоциативного кэша (хорошая утилизация памяти, высокая скорость), так и кэша прямого доступа (простота и дешевизна), лишь незначительно уступая по этим характеристикам исходным алгоритмам. Именно поэтому множественный ассоциативный кэш наиболее широко распространен.
Для организации кэш-памяти можно использовать принстонскую архитектуру (смешанный кэш для команд и данных, например, в Intel-486). Это очевидное (и неизбежное для фон-неймановских систем с внешней по отношению к ЦП кэш-памятью) решение не всегда бывает самым эффективным. Разделение кэш-памяти на кэш команд и кэш данных (кэш гарвардской архитектуры) позволяет повысить эффективность работы кэша по следующим соображениям:
Многие современные процессоры имеют конвейерную архитектуру, при которой блоки конвейера работают параллельно. Таким образом, выборка команды и доступ к данным команды осуществляется на разных этапах конвейера, а использование раздельной кэш-памяти позволяет выполнять эти операции параллельно.
Кэш команд может быть реализован только для чтения, следовательно, не требует реализации никаких алгоритмов обратной записи, что делает этот кэш проще, дешевле и быстрее.
85
Именно поэтому все последние модели IA-32, начиная с Pentium, для организации кэш-памяти первого уровня используют гарвардскую архитектуру.
Критерием эффективной работы кэша можно считать уменьшение среднего времени доступа к памяти по сравнению с системой без кэшпамяти. В таком случае среднее время доступа можно оценить следующим образом:
Tср = (Thit x Rhit) + (Tmiss x (1 Rhit))
где Thit - время доступа к кэш-памяти в случае попадания (включает время на идентификацию промаха или попадания), Tmiss - время, необходимое на загрузку блока из основной памяти в строку кэша в случае кэш-промаха и последующую доставку запрошенных данных в процессор, - частота попаданий.
Очевидно, что чем ближе значение Rhit к 1, тем ближе значение Tср к Thit. Частота попаданий определяется в основном архитектурой кэш-памяти и ее
объемом. Влияние наличия и отсутствия кэш-памяти и ее объема на рост производительности ЦП показано в
Основная память
Это следующий уровень иерархии памяти и служит в качестве ------------
---- ввода /вывода между процессором и внешними устройствами.
Для оценки производит осн.память исп.2 осн-----
1.задержка доступа
2.полоса пропускания
Задержка памяти традиционно оценивается двумя параметрами : 1.временем доступа (access time)
2.длительностью цикла памяти (cycle time)
Время доступа – это промежуток времени между выдачей запроса на чтение и поступление требуемого слова из памяти.
Длительность цикла памяти – определяется min временем между 2 последовательными обращениями к памяти.
Основная память современных компьютеров реализуется на статических и динамических ЗУ (запоминающее устройство) с произвольной выборкой.
Микросхемы статических ЗУ имеют меньшее время доступа и требует циклов регенерации. Микросхемы динамических ЗУ характеризуется большей емкостью и меньшей стоимостью, но требует схем регенерации и имеют значительно большее время доступа. В процессе развития динамических ЗУ с ростом их емкости основным вопросом их стоимости таких микросхем был вопрос о количестве адресных линий и стоимости соответствующего корпуса. В те годы было принято решение о необходимости мультиплексирования адресных линий, позволивших
86
наполовину сократить количество контактов корпуса необходимых для передачи адреса . Поэтому обращение к динамическим ЗУ обычно происходит в 2 этапа:
1.начинается с выдачи сигнала RAS (ROW ACCESS STOKE), которые фиксируют в микросхеме поступивший адрес строки;
2.включает переключение адреса для указания адреса столбца и подачу сигнала CAS(COLUMN ACCESS STOKE), которые фиксируют этот адрес и разрешает работу выходных буферов микросхем.
Назначение этих сигналов связано с внутренней организацией микросхем, которые обычно представляют собой прямоугольную матрицу которую можно адресовать с помощью указания № строки и № столбца.
Дополнительным требованием организации динамических ЗУ является необходимость периодической регенерации ст. состояния. Поэтому ко всем строкам всех микросхем динамической памяти должны производится периодические обращения в пределах определенного временного интервала =8мс. Обычно контролер памяти включает в свой состав соответствующую аппаратуру регенерации, а время затраченное на регенерацию, стараются поддержать на уровне меньшем 5% от общего времени.
В отличии от динамических, статические ЗУ не требуют регенерации и время доступа к ним совпадают с длительностью цикла. Согласование производительности современных компьютеров с νоснов.памяти ВС остается одной из важнейших проблем. Поэтому важным направлением современных разработок является методы ↑ полосы пропускания памяти за счет ее организации. Основными методами увеличения полосы пропускания является:
-увеличение разрядности памяти;
-использование расслоение памяти;
-использование независимых банков памяти;
-обеспечение режима бесконфликтного обращения к банкам памяти;
-использование специальных режимов работы динамических микросхем памяти;
Увеличение разрядности основной памяти.
Связано с разрядностью кэш-п 1-го и 2-го уровня. Кэш-п 1-го уровня во многих случаях имеет физическую ширину шин данных, соответствующие разрядности машинного слова, так как большинство компьютеров выполняют обращение именно к этой единице информации. В ситемах буз кэш-п 2-го уровня ширина шин данных основной памяти часто соответствуеь ширине шин данных кэш-п. Удвоение или учетверение ширине шин кэш-п и основной памяти удваивает или учетверяет соответствующую полосу пропускания системной памяти.
Реализация более широких шин вызывает необходимость мультиплексирования данных между кэш-п и процессором. Эти мультиплексоры оказывают на критические пути поступления информации в
87
процессор. Кэш-п 2-го уровня несколько смягчает эту проблему, т.о. мультиплексоры могут располагаться между 1 и 2 уровнями кэш-п. Другая проблема, связанная с увеличением разрядности памяти, определятся необходимостью вычисления min объема для поэтапного расширения памяти. Удвоение или учетверение шины памяти приводит и к удвоению\ учетверению этого min объема. Кроме того существуют проблема и с контролем и исправлением ошибок в системе с памятью большой разрядности.
Расслоение памяти.
Наличие в системе множества микросхем памяти позволяет использовать потенциальный параллелизм, заложенный в такой организации.
Для этого микросхемы памяти объединяются в банки \ модули, содержащие фиксированное число слов. Причем только к одному из ятих слов банка возможно обращение. В реальных системах имеющаясяVдост. к таким банкам, редко оказывается достаточной =>,чтобы увеличить эту скорость нужно обращаться сразу к нескольким банкам одновременно. Одна из общих методик для этого называется расслоением памяти. При расслоении банки памяти обычно упорядочивают так, чтобы N последовательных адресов памяти (i,…,i+N) приходилось на N различных банков, т.е. в i-том банке памяти находятся только те слова, адреса которых имеют вид: K*N+i, где K (0;m-1), m-число слов в одном банке, т.е. можно достичь в N раз большей Vдост. и памяти в целом, чем у отдельного его бака, если обеспечить при каждом доступе обращения к данным в каждом из банков. Большинство способов реализации таких расслоенных структур напоминают конвейера, обеспечивающие рассылку адресов в различные банки и мультиплексирующие поступающие из банков данные. Таким образом, степень/коэффициент расслоения определяют распределение адресов по банкам памяти. Такие системы оптимизируют обращение по последовательным адресам памяти, что является характерным при подкачке информации в кэш-п. при чтении, а также при записывании в кэш-п. обратного отображения. Однако если требуется доступ к случайным адресам памяти, то производительность расслоенной памяти может значительно снижаться. Обобщением идеи расслоения памяти является возможность реализации нескольких независимых обращений, когда несколько контролеров памяти позволяют банкам памяти работать независимо.
Если система памяти разработана для поддержки множество независимых запросов, как, например при реализации многопроцессорной и векторной обработки, эффективность систем будет в значительной степени зависеть от частоты поступления независимых запросов к разным банкам. Обращение по адресам отличающиеся на нечетное число, хорошо обрабатывается традиционными схемами расслоения памяти. Одно из решений, используемое для обработки последовательных обращений к памяти, если разница в адресах четная, заключается в том, чтобы
88
статистически снизить вероятность подобных обращений, путем значительного увеличения количества банков памяти.
Использование специфических свойств динамических ЗУ с произвольной выборкой
Обращение к динамическим ЗУ происходит в 2 этапа: 1.обращение к строке; 2.обращение к столбцу;
При этом внутри микросхемы осуществляется буферизация битов строки прежде чем происходит обращение к столбцу. С целью увеличения производительности все современные микросхемы памяти обеспечивают возможности подачи сигналов синхронизации, которые позволяют выполнить последовательные обращения к буферу без дополнительного времени обращения к строке. Имеются 3 способа такой оптимизации:
1.блочный режим (nibble mode)→динамических ЗУ может обеспечить выдачу 4-ех последовательных ячеек для каждого сигнала строба адреса строки;
2.страничный режим (page mode) →буфер работает как статические ЗУ. При изменении адреса столбца возможен доступ к произвольным битам в буфере до тех пор, пока не будет обращение к другой строке или не наступит время регенерации;
3.режим статического столбца (static mode)→аналогично 2 за исключением того, что нет необходимости переключать строб адреса столбца каждый раз для изменения адреса столбца.
Большинство современных ЗУ допускают использование из этих режимов. При чем выбор режима осуществляется на стадии установки кристалла в корпус, путем выбора соответствующего соединения. Плюсом такой оптимизации является то, что она незначительно повышает стоимость системы, позволяя практически учетверить пропускную способность памяти. Например, блочный режим был разработан для поддержки режимов, аналогичных расслоению памяти. Кристалл за один раз читает значение 4-ех бит и выдает их наружу в течении 4-ех оптимизированных циклов. Если время пересылки по шине не превосходит времени оптимизации цикла единственное усложнение для организации памяти с 4-ех кратным расслоением заключается в несколько усложненной схеме синхронизации.
Страничный режим |
и режим |
статического столбца также |
могут |
использоваться, обеспечивая также |
большую степень расслоения |
при |
|
усложнении схемы упр.
Новое поколение динамических ЗУ разработано с учетом дальнейшей оптимизации интерфейса между памятью и процессором. К таким системам относятся памяти типа RAMBUS, DDR, DDR2 и т.д.
Вторичная память
Память на магнитных носителях
89
Жесткие диски включают в себя эл-мех. и электронную части. Эл-мех часть расположена в жестком корпусе, внутри которой закреплен двигатель с вращающим шпинделем и смонтированным на нем дисками накопителя + в том же корпусе подвижный блок чтение \ запись с приводом, обеспечивающий позиционирование головок. Поверхность дисков имеет магнитное покрытие, а процесс записи состоит в локальных изменениях магнитного состояния этого покрытия. Информация на диске расположена по окружностям – дорожкам. Дорожки для хранения информации разбиты на секторы. Каждый сектор обладает определенной структурой, включающей в себя заголовок, поле данных и контрольный код этого поля.
В электронную часть диска входит контроллер, усилители сигналов интерфейсных шин и буферная память(кэш диска). Контроллер обеспечивает разгона \ установки шпинделя, позиционирование головок, чтение \ запись информации. Для чтения и записи данных головки удерживаются над диском при помощи спец. следящей системы, считываются с дисков специальные сервометки. Эти метки записываются либо в спец. местах дорожек, либо не в служебных серводорожках расположенных осн., или (редко) на специальной выделенной поверхности диска. Требования обеспечения работы сист. Позиционирования приводит к тому, что поперечная плотность записанных данных меньше продольной. Сервометки также используются для поддержания постоянной скорости вращения диска. Время позиционирования требуемой дорожки зависит от расстояния до него текущего положения головки чтения \ запись. Минимальное время затрачиваемого на переход к соседнему цилиндру. На переход с дорожки на дорожку в переделах 1-го цилиндра затрачивается приблизительно столько же времени, сколько на переход на дорожку другого цилиндра, т.о. система позиционирования даже при переключении дорожек в пределах цилиндра должна вымереть точность установки головок.
Для предотвращения потери данных в случае выхода из строя диска его контроллер обычно осуществляет специальный мониторинг состояния диска, фиксируя изменение таких его параметров, как
частота чтения данных; время разгона шпинделя до номинальной скорости вращения;
кол-во перемещенных секторов кол-во ошибок системы позиционирования общее число отработанных часов и т.д.
Средства: SMART (Self-Monitoring-Analyzing and Reporting-Technology)
На основании изменений этих параметров с течением времени контроллер системы SMART способен предвидеть предположительное время выхода диска из строя.
Интерфейсы работы с диском.
I. Интерфейс Serial ATA является дальнейшем развитием семейства ATA.Последней версией \ специализацией является ATAP I-6(ATA/133).
90