

КЛ_АВС
.pdfАсинхронный |
ввод-вывод. Параллельно |
обычному |
выполнению |
команд независимые |
процессоры управляют |
операциями |
ввода-вывода. |
Первой ЭВМ с независимым процессором ввода-вывода являлась ЭВМ709
фирмы IBM (1958г.).
Виртуальная память. Определение адресного пространства программы осуществляется без "привязки" к физическим областям памяти обычно с целью создания впечатления, что вычислительная система имеет больший объем основной памяти, чем тот, которым она фактически располагает. В 1959г. в вычислительной системе Atlas Манчестерского университета были реализованы принципы разделения памяти на страницы и динамическая трансляция адресов аппаратными средствами.
Мультипроцессорная обработка. Два или более независимых процессора обрабатывают потоки команд из общей памяти. Не ясно, кто был первооткрывателем такого способа обработки, однако, в конце 50-х начале 60-х годов, он был реализован в вычислительных машинах Sage фирмы
IBM, Sperri-Univac LARC и D825 фирмы Burroughs.
Существенное противоречие между высокой скоростью обработки данных в процессоре и низкой скоростью работы устройств ввода/вывода потребовало высвобождения ЦПУ от функций передачи информации и предоставления этих функций специальным устройствам – контроллерам и интерфейсам.
31

4. Модели памяти
Размещение байтов слова в памяти
Во всех компьютерах память разделена на ячейки, которые имеют последовательные адреса. В настоящее время наиболее распространенный размер ячейки — 8 бит, но раньше использовались ячейки от 1 до 60 бит. Ячейка из 8 бит называется байтом. Причиной применения именно 8- разрядных ячеек памяти является ASCII-символ, который занимает 7 бит, а вместе с битом четности — 8. Если в будущем будет доминировать кодировка UNICODE, то ячейки памяти, возможно, станут 16-разрядными. Вообще говоря, число 24 лучше, чем 23, поскольку 4 — степень двойки, а 3 — нет. Байты обычно группируются в 4-байтные (32-разрядные) или 8-байтные (64-разрядные) слова с командами манипулирования целыми словами.
Порядок байтов в информатике — метод записи байтов многобайтовых чисел.
В общем случае, когда нужно компактно записать число, большее 255 необходимо использовать несколько байтов. Число M факторизуется по основанию 256:
|
n |
|
|
|
|
K ai 256i a0 2560 a1 2561 a2 2562 |
an 256n |
|
|
|
i 0 |
|
|
|
Набор чисел |
a0 , a1 , , an и |
является последовательностью |
байтов для |
|
записи. |
|
|
|
|
На практике используется три основных варианты записи |
|
|||
Порядок от |
младшего |
к старшему (little-endian): a0 , a1 , |
, an , запись |
|
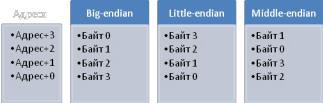
начинается с младшего и заканчивается старшим. Этот порядок записи принят в памяти персональных компьютеров с x86-процессорами, в связи с чем, иногда, его называют интеловский порядок байтов (по названию фирмы-создателя архитектуры x86).
Порядок от старшего к младшему (big-endian): an , an 1 , , a0 , запись начинается со старшего и заканчивается младшим. Этот порядок является стандартным для протоколов TCP/IP, он используется в заголовках пакетов данных и во многих протоколах более высокого уровня, разработанных для использования поверх TCP/IP. Поэтому, порядок байтов от старшего к младшему часто называют сетевым порядком байтов (network byte order). Этот порядок байтов используется процессорами IBM 360/370/390, Motorola 68000, SPARC (отсюда третье название — порядок байтов Motorola,
Motorola byte order).
Порядок байтов от старшего к младшему применяется в многих форматах файлов — например, PNG.
Многие процессоры могут работать и в порядке от младшего к старшему, и в обратном, например, ARM, PowerPC (но не PowerPC 970), DEC Alpha, MIPS, PA-RISC и IA-64. Обычно порядок байтов выбирается программно во время инициализации операционной системы, но может быть
32
выбран и аппаратно перемычками на материнской плате. В этом случае правильнее говорить о порядке байтов операционной системы. Переключаемый порядок байтов иногда называют bi-endian.
Смешанный порядок байтов (middle-endian) иногда используется при работе с числами, длина которых превышает машинное слово. Производится факторизация числа на машинные слова, которые записываются в формате, естественном для данной архитектуры, но сами слова записываются в обратном порядке.
Классический пример middle-endian — представление 4-байтных целых чисел на 16-битных процессорах семейства PDP-11 (известен как PDPendian). Для представления двухбайтных значений (слов) использовался порядок little-endian, но 4-хбайтное двойное слово записывалось от старшего слова к младшему.
В процессорах VAX и ARM используется смешанное представление для длинных вещественных чисел.
Рис. 1. Размещение байтов слова в памяти Big-endian и Little-endian ЭВМ
Пример
Далее приведён пример, в котором описывается размещение 4- байтового числа в ОЗУ ЭВМ, доступ к которому может производиться как к 32-разрядному слову, так и побайтно.
Все числа записаны в 16-тиричной системе счисления.
Число: 0xA1B2C3D4
Факторизация: D4*0x01 + C3*0x100 + B2*0x10000 + A1*0x1000000 Порядок от младшего к старшему (little-endian): 0xD4, 0xC3, 0xB2,
0xA1
Порядок от старшего к младшему (big-endian): 0xA1, 0xB2, 0xC3, 0xD4 Порядок, принятый в PDP-11 (PDP-endian): 0xB2, 0xA1, 0xD4, 0xC3
Достоинства и недостатки
Существенным достоинством little-endian по сравнению с big-endian порядком записи считается возможность «неявной типизации» целых чисел при чтении меньшего объёма байт (при условии, что читаемое число помещается в диапазон). Так, если в ячейке памяти содержится число 0x00000022, то прочитав его как int16 (два байта) мы получим число 0x0022, прочитав один байт — число 0x22.
Обратно, считается что у little-endian, по сравнению с big-endian есть «неочевидность» значения байтов памяти при отладке (последовательность байтов (33, 44, 55, 12) на самом деле значит 0x12554433, для big-endian эта последовательность (33, 44, 55, 12) читалась бы «естественным» для
33
арабской записи чисел образом: 0x33445512). Наименее удобным в работе считается middle-endian формат записи; он сохранился только на старых платформах.
Для записи длинных чисел (чисел, длина которых существенно превышает разрядность машины) обычно предпочтительнее порядок слов в числе little-endian (поскольку арифметические операции над длинными числами производятся с конца). Порядок байтов в слове — обычный для данной архитектуры.
Запись многобайтового числа из памяти компьютера в файл или передача по сети требует соблюдения соглашений о том, какой из байтов является старшим, а какой младшим. Прямая запись ячеек памяти приводит к возможным проблемам при переносе приложения с платформы на платформу.
Пример кода, работающего правильно на процессорах Intel , и дающего не правильный результат на Macintosh.
int i = 0x0901;
char *ptr = (char *)&i;
printf("\nLow byte is %d; next byte is %d.", *ptr, *(ptr+1));
Порядок байтов в конкретной машине можно определить с помощью программы на языке Си (testendian.c):
#include <stdio.h>
unsigned short x = 1; /* 0x0001 */ int main(void)
{
printf("%s\n", *((unsigned char *) &x) == 0 ? "big-endian" : "little-endian"); return 0;
}
Вывод данной программы осмыслен только на платформах, где размер типа unsigned short больше, чем размер типа unsigned char. Это заведомо верно на подавляющем большинстве компьютеров, так как они имеют 8- разрядный байт. Однако существуют и аппаратные платформы с 32разрядным байтом.
Для преобразования между сетевым порядком байтов (network byte order), который всегда big-endian, и порядком байтов, использующимся на машине (host byte order), стандарт POSIX предусматривает функции htonl(),
htons(), ntohl(), ntohs():
uint32_t htonl(uint32_t hostlong); — конвертирует из текущего порядка байтов в сетевой 32-битную беззнаковую величину;
uint16_t htons(uint16_t hostshort); — конвертирует из текущего порядка байтов в сетевой 16-битную беззнаковую величину;
uint32_t ntohl(uint32_t netlong); — конвертирует из сетевого порядка байтов в текущий 32-битную беззнаковую величину;
uint16_t ntohs(uint16_t netshort); — конвертирует из сетевого порядка байтов в текущий 16-битную беззнаковую величину.
34
В случае совпадения текущего порядка байтов и сетевого, функции могут быть «пустыми» (то есть, не менять порядка байтов). Стандарт также допускает, чтобы эти функции были реализованы макросами.
Выравнивание
Многие архитектуры требуют, чтобы слова были выровнены в своих
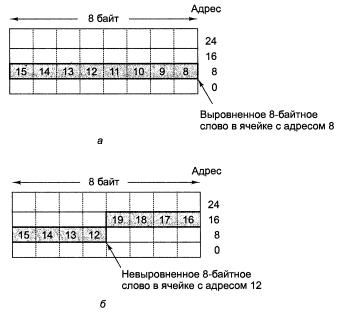
естественных границах. Объект длиной s байт, находящийся по адресу байта A выровнен, если A
mods =0. Так, 4-байтное слово может начинаться с адреса 0, 4, 8 и т. д., но не с адреса 1 или 2. Точно так же слово из 8 байт может начинаться с адреса 0, 8 или 16, но не с адреса 4 или 6. Механизм размещения 8-байтных слов в памяти иллюстрирует рис. 5.2. Выравнивание адресов требуется довольно часто, поскольку при этом память работает наиболее эффективно. Например, процессор Pentium 4, который вызывает из памяти по 8 байт за обращение, использует 36-разрядные физические адреса, но содержит только 33 адресных бита. Следовательно, Pentium 4 даже не сможет обратиться к невыровненной памяти, поскольку младшие 3 бита явным образом не определены. Эти биты всегда равны 0, и все адреса памяти кратны значению 8 байт. Однако требование относительно выравнивания адресов иногда вызывает некоторые проблемы. В процессоре Pentium 4 программы могут обращаться к словам, начиная с любого адреса, — это качество восходит к модели 8088 с шиной данных шириной 1 байт, в которой не требовалось, чтобы ячейки располагались в 8-байтных границах. Если программа в процессоре Pentium 4 считывает 4-байтное слово с адреса 7, аппаратное обеспечение должно сделать одно обращение к памяти, чтобы вызвать байты с 0 по 7, а второе — чтобы вызвать байты с 8 по 15. Затем центральный процессор извлекает требуемые 4 байта из 16, считанных из памяти, и компонует их в нужном порядке, чтобы сформировать 4-байтное слово.
Рис. 2. Расположение слова из 8 байт в памяти: (а) - выровненное слово; (б) - невыровненное слово.
35
Большинство машин имеют единое линейное адресное пространство, которое простирается от адреса 0 до какого-то максимума, обычно 232 или 264 байт. В некоторых машинах содержатся раздельные адресные пространства для команд и данных, так что при вызове команды с адресом 8 и вызове данных с адресом 8 происходит обращение к разным адресным пространствам. Такая система гораздо сложнее, чем единое адресное пространство, но зато она имеет два преимущества. Во-первых, все с теми же 32-разрядными адресами появляется возможность иметь 232 байт для программ и дополнительные 232 байт для данных. Во-вторых, поскольку запись всегда автоматически происходит только в пространство данных, случайная перезапись программы становится невозможной, и, следовательно, устраняется один из источников программных ошибок. Отметим, что раздельные адресные пространства для команд и для данных — это не то же самое, что разделенная кэш-память первого уровня. В первом случае все адресное пространство целиком дублируется, и считывание из любого адреса вызывает разные результаты в зависимости от того, что именно считывается: слово данных или команда. При разделенной кэш-памяти существует только одно адресное пространство, просто в разных блоках кэш-памяти хранятся разные части этого пространства.
Семантика памяти
Еще один аспект модели памяти — семантика памяти. Естественно ожидать, что команда LOAD, если она выполняется после команды STORE, обратится к тому же адресу и возвратит только что сохраненное значение. Однако во многих машинах микрокоманды переупорядочиваются. Таким образом, существует реальная опасность, что память будет работать не так, как ожидается. Ситуация усложняется при наличии мультипроцессора, когда каждый процессор посылает в общую память поток запросов на чтение и запись, и эти запросы тоже могут быть переупорядочены.
Системные разработчики могут применять один из нескольких подходов решения этой проблемы. С одной стороны, все запросы к памяти могут быть упорядочены таким образом, чтобы каждый из них завершался до того, как начнется следующий. Такая стратегия отрицательно сказывается на производительности, но зато дает простейшую семантику памяти (все операции выполняются строго в том порядке, в котором они расположены в программе). С другой стороны, можно вообще не давать никаких гарантий относительно упорядоченности запросов к памяти, а чтобы добиться такой упорядоченности, программа выполняет команду SYNC, которая блокирует запуск всех новых операций с памятью до тех пор, пока не завершатся предыдущие. Эта идея весьма затрудняет работу создателей компиляторов, поскольку им приходится тщательно разбираться в том, как работает соответствующая микроархитектура, но зато разработчикам аппаратного обеспечения предоставлена полная свобода в плане оптимизации
36
использования памяти. Возможны также промежуточные модели памяти, в которых аппаратное обеспечение автоматически блокирует запуск определенных операций с памятью (например, тех, которые связаны с RAW- и WAR-взаимозависимостями), при этом запуск всех других операций не блокируется. Хотя реализация этих возможностей на уровне архитектуры набора команд довольно утомительна (по крайней мере, для создателей компиляторов и программистов на языке ассемблера), сейчас заметна тенденция к преобладанию подобного подхода. Данная тенденция вызвана к жизни такими разработками, как механизмы переупорядочения микрокоманд, конвейеры, многоуровневая кэш-память и т. д.
37
5. Архитектура системы команд.
Системой команд ЭВМ называют полный перечень команд который данная ЭВМ способна выполнить.
Архитектура системы команд – те свойства ВМ которые видны и доступны программисту.
Для реализации вычислений наиболее эффективным образом важнейшую роль играет правильный выбор архитектуры системы команд. Общая характеристика архитектуры системы команд ВМ складывается из ответов на следующие вопросы:
1.Какого вида данные будут представлены в ВМ и в какой форме;
2.Где эти данные смогут храниться помимо основной памяти;
3.Каким образом будет осуществляться доступ к данным;
4.Какие операции могут быть выполнены над данными;
5.Сколько операндов могут присутствовать в команде;
6.Как будет определяться адрес очередной команды;
7.Каким образом будут закодированы команды;
Классификация архитектуры системы команд
Архитектуры системы команд
Первая аккумуляторная архитектура |
Стековая архитектура (B5500,B5600,1963- |
(EDSAC 1950) |
1966) |
Регистровая архитектура (IBM 360 1964) |
Архитектура с безонерандным набором |
|
команд ROSC (IGNITE, 2001) |
CISC (VAX, Intel 432, 1077-1986)
Load/Store с выделенным доступом памяти (GrayI; CDC6600 1963-1976)
RISC (Mips, Spare; IBM R56000 1987)
VLIW (Itanium) конец 1990 архитектура с ком. словом сверхбольшой длины
38
Классификация по составу и сложности команд.
Современные технологии программирования ориентируются на языки высокого уровня, главная цель которых облегчить процесс программирования. Переход к ЯВУ породил серьёзную проблему. Сложные операторы характерные для ЯВУ существенно отличаются от простых машинных операций, реализуемых в большинстве ВМ. Проблему эту называют семантическим разрывом, а её следствием является недостаточно эффективное выполнение программы на ВМ. Пытаясь преодолеть семантический разрыв разработчики в настоящее время выбирают один из трёх подходов и соответственно один из трёх типов архитектуры системы команд.
1Архитектура с полным набором команд CISC (Complex instruction set computing)
2Архитектура с сокращённым набором команд RISC (reduced instruction set computing)
3Архитектура с командными словами сверх большой длины VLIM (Very Long Instruction Word)
ВВМ типа CISC проблема семантического разрыва решается за счёт расширения системы команд; дополнения её сложными командами семантич. аналогичными операторов ЯВУ. Основоположником CISC архитектуры считается IBM которая начала применять данный подход на машинах IBM360. Аналогичный подход характерен и для компании Intel AMD.
Для CISC архитектуры типично:
1.Наличие в процессоре сравнительно небольшого числа регистров общего назначения;
2.Большое количество машинных команд некоторые из которых аппаратно реализуют операторы ЯВУ;
3.Разнообразие способов адресации операндов;
4.Множество форматов команд различной разрядности;
5.Наличие команд, в которых обработка совмещена с доступом в памяти.
Рассмотренный способ решения проблемы семантического разрыва приводит к усложнению аппаратуры, главным образом УУ, что в свою очередь отрицательно сказывается на производительности ВМ в целом.
Процессор с сокращённым набором команд: термин RISC впервые был использован в 1980 году. Патерсеном и Гитцелем. Идея заключалась в ограничении списка команд ВМ наиболее часто используемых простейшими командами оперирующими данными размещёнными только в регистре процессора. Обращение к памяти допускается, лишь при помощи специальных команд чтения и записи. В результате резко падает количество форматов команд и способов указания адресов операндов, сокращено число
39
форматов команд, что позволило существенно упростить аппаратные свойства и увеличить быстродействие.
Концепция VLIW базируется на RISC архитектуре, где несколько простых RISC-команд объединяются в одну сверхдлинную и выполняются параллельно. В плане архитектуры системных команд, архитектура VLIW сравнительно мало отличается от RISC. Появился лишь дополнительный уровень параллемума вычислений. В результате этого архитектуру VLIW можно отнести к ВС, а не к ВМ
Характеристика |
CISC |
RISC |
VLIW |
|
|
|
|
Длина команд |
Варьируется |
Единая |
Единая |
|
|
|
|
Расположение |
Варьируется |
Неизменное |
Неизменное |
полей в |
|
|
|
команде |
|
|
|
Количество |
Сравнительно |
Много |
Много |
регистров |
небольшое |
|
|
Доступ к памяти |
Выполняется как |
Специализированные |
Специализированные |
|
часть команды |
команды |
команды |
(8 регистров;12 режимов адресации; Операнды 42, 64, 80 Команды 1-12
байт)
Классификация по способу хранения операндов.
Количество команд и их сложность безусловно являются важнейшими факторами. Однако не меньшую роль при выборе архитектуры системных команд играет ответ на вопрос о том, где могут храниться операнды и результат операций и каким образом к ним осуществляется доступ. С этих позиций различают следующие виды архитектур системных команд (АСК)
1.Стековую
2.Аккумуляторную
3.Регистровую
4.Архитектуру с выделенным доступом к памяти Выбор типа архитектуры влияет на следующие принципиальные
моменты:
Сколько адресов будет содержать адресная часть команды
Какова будет длина этих адресов
Насколько просто будет осуществить доступ к операндам
Какой в конечном итоге будет длина команд
Стековая архитектура
Стек образует множество логических взаимосвязанных ячеек, действующих по принципу “последним вошёл – первым вышел” (LIFO). Верхнюю ячейку называют вершиной стека. Для работы со стеками
40