

2. Проектирование бд на основе нормализации, характеристика 1nf, 2nf, 3nf.
Нормализация базы данных - это удаление избыточных данных из каждой таблицы в базе данных. У нормализации двойная цель - удалить лишние копии данных и обеспечить максимальную гибкость, как в структурах таблиц, так и в интерфейсных приложениях на случай возможных будущих изменений в базах данных. Выделяют три нормальных формы:
Первая нормальная форма (1NF). Для того чтобы таблица считалась нормализованной к первой нормальной форме, каждое из ее отношений не должно содержать сложных (неатомарных) атрибутов. Если по условию задачи подразумеватеся неатомарный атрибут, то он заменяется на набор характеристик, т.е. на несколько атрибутов (вплоть до создания нового отношения), которые связаны с исходным атрибутом.
Вторая нормальная форма (2NF). Для того чтобы привести таблицу ко второй нормальной форме, нужно, чтобы все не ключевые поля полностью зависели от первичного ключа таблицы и от каждого поля в первичном ключе, если последний состоит из нескольких полей. Это значит, что каждое не ключевое поле должно уникально определяться первичным ключом и полями, его составляющими.
Третья нормальная форма (3NF). Для того чтобы таблица была приведена к третьей нормальной форме, нужно, чтобы все не ключевые поля полностью зависели от первичного ключа таблицы и не зависели друг от друга. Таким образом, к квалификации второй нормальной формы добавляется требование независимости каждого не ключевого поля таблицы от других не ключевых полей.
3. Служба dns. Конфигурирование: зоны, ресурсные записи, виды серверов.
Система доменных имен (Domain Name System) — служба имен Интернета, стандартная служба TCP/IP. Служба DNS дает возможность клиентским компьютерам в сети регистрировать и разрешать доменные имена. Доменные имена используются, чтобы находить ресурсы в сети и обращаться к ним.
Домен DNS основан на концепции дерева именованных доменов. Каждый уровень дерева может представлять или ветвь, или лист дерева. Ветвь — это уровень, содержащий более одного имени и идентифицирующий набор именованных ресурсов. Лист — имя, указывающее заданный ресурс
Корневой
домен:
Корень дерева именованных доменов,
задает неименованный уровень; часто
указывается в виде двойных пустых
кавычек (" "). При использовании в
доменном имени указывается точкой в
конце имени. Определяет, что имя
расположено в корневом, самом высоком,
уровне доменной иерархии. (Точка (.) или
точка, стоящая в конце имени, например,
"sample.mydomain.org.")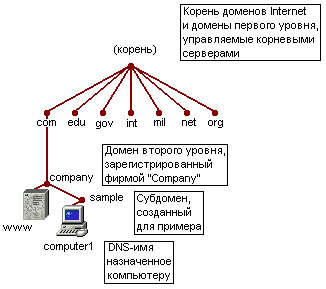
Домен верхнего уровня: Имя, состоящее из двух или трех символов, обычно указывающее страну (Россия — ш, Нидерланды — nl, Украина — иа и т. п.) или тип организации, использующей имя (com — коммерческая, mil — военная, США и т. д.) (".com" означает, что имя зарегистрировано фирмой или другой организацией для коммерческого использования в Интернете).
Домен второго уровня: Имя переменной длины, зарегистрированное частным лицом или организацией для использования в Интернете. Такие имена всегда основаны на домене верхнего уровня, в зависимости от типа организации или географического местоположения ("mydomain.org" — имя домена второго уровня)
Субдомен: Дополнительные имена, которые организация может создавать в пределах домена второго уровня. Применяются для указания различных организационных единиц или территориальных подразделений больших организаций ("sample.mydomain.org." — субдомен домена второго уровня "mydomain.org.")
Имя хоста или ресурса Листья дерева имен DNS, задают определенный ресурс или хост ("host.sampte.mydbmain.org.", где host— имя хоста или какого-либо ресурса в сети)
Формат
ресурсных записей в DNS.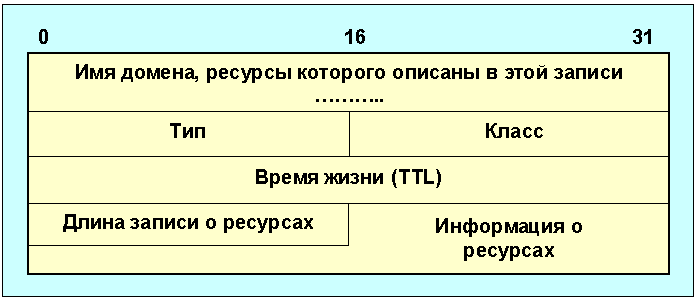
Имя домена в этой записи может иметь произвольную длину. Поля тип и класс характеризуют тип и класс данных, включенных в запись (аналогичны используемым в запросах). Поле время жизни (TTL) содержит время (в секундах), в течение которого запись о ресурсах может храниться в буферной памяти (в кэше). Обычно это время соответствует двум дням. Формат информации о ресурсах зависит от кода в поле тип, так для тип=1 - это 4 байта IP-адреса. Сервер имен может обслуживать и другие запросы, например, по IP-адресу определять символьное имя домена или преобразовать имя домена в адрес почтового сервера. Когда организация присоединяется к Интернет, она получает в свое распоряжение не только определенную DNS-область, но и часть пространства в in-addr.arpa, соответствующую ее IP-адресам. Домен in-addr.arpa предназначен для определения имен по их IP-адресам. Такая схема исключает процесс перебора серверов при подобном преобразовании.
Билет №8
1. Средства для работы с памятью в языке С++: указатели; базовые понятия; адресная арифметика.
Под управлением памятью имеются в виду возможности программы по размещению и манипулированию данными. Поскольку единственным "представителем" памяти в программе выступают переменные, то управление памятью определяется тем, каким образом работает с ними и с образованными ими структурами данных язык программирования.
Указателем называется переменная, которая содержит значение адреса элемента памяти, где хранится значение другой переменной. Главная операция над указателями - это косвенное обращение (разыменование), т.е. обращение к объекту, на который настроен указатель. Эту операцию обычно называют просто косвенностью. Операция косвенности * является префиксной унарной операцией. Например: char c1 = 'a'; char* p = &c1; // p содержит адрес c1 char c2 = *p;// c2 = 'a'
Присваивание указателей различного типа. Операцию присваивания указателей различных типов следует понимать как назначение указателя в левой части на ту же самую область памяти, на которую назначен указатель в правой. Но поскольку тип указываемых переменных у них разный, то эта область памяти по правилам интерпретации указателя будет рассматриваться как заполненная переменными либо одного, либо другого типа.
char A[20] ={0x11,0x15,0x32,0x16,0x44,0x1,0x6,0x8A}; char * p; int *q; long *l; p = A; q = (int*) p; l = (long*) p; p[2] = 5; /* записать 5 во второй байт области A */ q[1] = 7; /*записать 7 в первое слово области A*/
Здесь p - указатель на область байтов, q - на область целых, l - на область длинных целых. Соответственно операции адресной арифметики *(p+i), *(q+i), *(l+i) или p[i], q[i], l[i] адресуют i-ый байт, i-ое целое и i-ое длинное целое от начала области Область памяти имеет различную структуру (байтовую, словную и т.д.) в зависимости от того, через какой указатель мы с ней работаем. При этом неважно, что сама область определена как массив типа char - это имеет отношение только к операциям с использованием идентификатора массива.
Присваивание значения указателя одного типа указателю другого типа сопровождается действием, которое называется в Си преобразованием типа указателя , и которое в Си++ обозначается всегда явно. Операция (int*)p меняет в текущем контексте тип указателя char* на int*. На самом деле это действие является чистой фикцией (команды транслятором не генерируются). Транслятор просто запоминает, что тип указуемой переменной изменился и операции адресной арифметики и косвенного обращения нужно выполнять с учетом нового типа указателя.
Явное преобразование типа указателя в выражении. Преобразование типа указателя можно выполнить не только при присваивании, но и внутри выражения, "на лету". В этом случае текущий указатель меняет тип указываемого элемента только в цепочке выполняемых операций. char A[20]; ((int *)A )[2] = 5;
Имя массива A - указатель на его начало - имеет тип char*, который явно преобразуется в int* . Тем самым в текущем контексте мы ссылаемся на массив как на область целых переменных. Применительно к указателю на массив целых выполняется операция индексации и последующее присваивание. Результат : целое 5 записывается во второй элемент целого массива, размещенного в А .
Операция *p++ применительно к любому указателю интерпретируется как " взять указываемую переменную и перейти к следующей" , следовательно, значением указателя после выполнения операции будет адрес переменной, следующей за выбранной. Использование такой операции в сочетании с явным преобразованием типа позволяет извлекать или записывать переменные различных типов, последовательно расположенных в памяти.
char A[20], *p=A; *p++ = 5; /*Записать в массив байт с кодом 5*/ *((int* )p)++ = 5; /*Записать в массив целое 5*/ *((double*)p)++ = 5.5; /*Записать в массив вещественное 5.5*/
Работа с памятью на низком уровне. Операции преобразования типа указателя и адресной арифметики дают Си невиданную для языков высокого уровня свободу действий по управлению памятью. В Си имеется возможность работать с памятью на " низком" уровне. На этом уровне программист имеет дело не с переменными, а с помеченными областями памяти, внутри которых он может размещать данные любых типов и в любой последовательности, в какой только пожелает. Естественно, что при этом ответственность за корректность размещения данных ложится целиком на программиста.
Операция sizeof вызывает подстановку транслятором соответствующего значения размерности указанного в ней типа данных в байтах. С этой точки зрения она является универсальным измерителем, который должен использоваться для корректного размещения данных различных типов в памяти.
Работа с последовательностью данных, определяемой форматом. Массив можно определить как последовательность переменных одного типа, структуру - как фиксированную последовательность переменных различных типов. Но существуют данные иного рода, в которых заранее неизвестны ни типы переменных, ни их количество, а заданы только общие правила их следования (формат). В таком формате значение предыдущей переменной может определять тип и количество расположенных за ней переменных.
Последовательности данных, определяемых форматом широко используются при упаковке больших массивов, представлении объектов с переменной размерностью и произвольными свойствами и т.д.. При работе с ними требуется последовательно просматривать область памяти, извлекая из нее переменные разных типов и на основе анализа их значений делать вывод о типах последующих за ними. Такая задача может быть решена с использованием операции явного преобразования типа указателя.
Другой вариант заключается в использовании объединения (union), которое, как известно, позволяет использовать общую память для размещения своих элементов. Если элементами union являются указатели, то операции присваивания можно исключить.
union ptr { int *p; double *d; long *l; } PTR; int A[100]; PTR.p=A; *(PTR.p)++ =5; *(PTR.l)++ =5; *(PTR.d)++=5.56;