

А.4 Лабораторная работа 4 – 2ч. Разработка функциональных требований к проектируемой системе с помощью dfd диаграмм и Case-средств
А.4.1 Цель работы - изучение методологии структурного системного анализа и проектирования информационных систем с использованием диаграмм потоков данных (DFD) и ее применение для построения модели функционирования информационной системы с использованием средств Case-систем MS Visio / BPWin.
А.4.2 Предмет работы
Предметом лабораторной работы является логическое моделирование АЭИС.
А.4.3 Содержание лабораторной работы
1) Изучить методологию структурного анализа предметной области с использованием диаграмм потоков данных (DFD), а также возможности моделирования DFD в Case-системах MS Visio / BPWin.
2) Определить функции, подлежащие автоматизации. Использовать вариант задания и результаты моделирования функционирования предметной области предыдущей работы.
3) Построить функциональную модель ИС автоматизирующую выбранные процессы предметной области варианта задания с использованием методологии DFD.
4) Построить модели бизнес процессов «как есть» и «как должно быть».
5) Составить отчет по проделанной работе.
6) Защитить работу.
А.4.4 Оборудование и технические средства
Для выполнения работы необходимы технические и программные средства лаборатории ”Электронный офис”, доступ к сетевому серверу кафедры и Case-система MS Visio / BPWin.
А.4.5 Порядок выполнение работы
- Изучить методологию DFD структурного анализа.
В процессе изучения методологии структурного анализа необходимо использовать материал лекций, а также литературу и методические материалы.
- Изучить возможности Case-системы MS Visio / BPwin.
- Построить модели процессов предметной области по теме индивидуального задания с использованием MS Visio / BPwin.
- Оформить отчет
- Защитить работу.
В процессе защиты лабораторной работы необходимо представить отчет, продемонстрировать построенные модели на экране, иметь конспекты лекций, а также знать работу Case-системы и ответить на контрольные вопросы.
А.4.6 Требования к оформлению работы
Отчет должен дополнять отчет о предыдущей работе и содержать разделы:
1) описание функционирования ИС предметных областей варианта задания.
2) моделей функционирования ИС предметных областей варианта задания в виде DFD-диаграмм (распечатки) и их описание. Описание должно включать описание внешних сущностей, функций каждого процесса с указанием входных и выходных потоков данных, а также хранилищ данных.
А.4.7 Методические указания к выполнению работы
В структурном подходе используются в основном две группы средств, описывающих функциональную структуру системы и отношения между данными. Каждой группе средств соответствуют определенные виды моделей (диаграмм), наиболее распространенными среди которых являются:
- DFD (Data Flow Diagrams) - диаграммы потоков данных;
- SADT (Structured Analysis and Design Technique - метод структурного анализа и проектирования) — модели и соответствующие функциональные диаграммы.
- ERD (Entity-Relationship Diagrams) - диаграммы "сущность-связь".
Общие сведения
Диаграммы потоков данных (DFD) являются основным средством моделирования функциональных требований к проектируемой системе. С их помощью эти требования представляются в виде иерархии функциональных компонентов (процессов), связанных потоками данных. Главная цель такого представления — продемонстрировать, как каждый процесс преобразует свои входные данные в выходные, а также выявить отношения между этими процессами.
Диаграммы потоков данных известны очень давно. В фольклоре упоминается следующий пример использования DFD для реорганизации переполненного клерками офиса, относящийся к 20-м гг. Осуществлявший реорганизацию консультант обозначил кружком каждого клерка, а стрелкой — каждый документ, передаваемый между ними. Используя такую диаграмму, он предложил схему реорганизации, в соответствии с которой два клерка, обменивающихся множеством документов, были посажены рядом, а клерки с малым взаимодействием были посажены на большом расстоянии друг от друга. Так появилась первая модель, представляющая собой потоковую диаграмму - предвестника DFD.
Для построения DFD традиционно используются две различные нотации, соответствующие методам Йордана и Гейна - Сэрсона. Эти нотации незначительно отличаются друг от друга графическим изображением символов. Далее при построении примеров будет использоваться нотация Гейна - Сэрсона.
В соответствии с данными методами модель системы определяется как иерархия диаграмм потоков данных, описывающих асинхронный процесс преобразования информации от ее ввода в систему до выдачи пользователю. Диаграммы верхних уровней иерархии (контекстные диаграммы) определяют основные процессы или подсистемы с внешними входами и выходами. Они детализируются при помощи диаграмм нижнего уровня. Такая декомпозиция продолжается, создавая многоуровневую иерархию диаграмм, до тех пор, пока не будет достигнут уровень декомпозиции, на котором процессы становятся элементарными и детализировать их далее невозможно.
Источники информации (внешние сущности) порождают информационные потоки (потоки данных), переносящие информацию к подсистемам или процессам. Те, в свою очередь, преобразуют информацию и порождают новые потоки, которые переносят информацию к другим процессам или подсистемам, накопителям данных или внешним сущностям — потребителям информации.
Состав диаграмм потоков данных
Основными компонентами диаграмм потоков данных являются:
- внешние сущности;
- системы и подсистемы;
- процессы;
- накопители данных;
- потоки данных.
Внешняя сущность представляет собой материальный объект или физическое лицо, представляющие собой источник или приемник информации, например заказчики, персонал, поставщики, клиенты, склад. Определение некоторого объекта или системы в качестве внешней сущности указывает на то, что они находятся за пределами границ анализируемой системы. В процессе анализа некоторые внешние сущности могут быть перенесены внутрь диаграммы анализируемой системы, если это необходимо, или, наоборот, часть процессов может быть вынесена за пределы диаграммы и представлена как внешняя сущность.
Внешняя сущность обозначается квадратом, расположенным как бы над диаграммой и бросающим на нее тень для того, чтобы можно было выделить этот символ среди других обозначений (рисунок А.4.1).

Рисунок А.4.1 - Графическое изображение внешней сущности
При построении модели сложной ЭИС она может быть представлена в самом общем виде на так называемой контекстной диаграмме в виде одной системы как единого целого либо может быть декомпозирована на ряд подсистем (рисунок А.4.2).
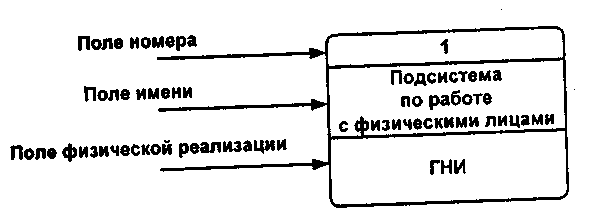
Рисунок А.4.2 - Подсистема по работе с физическими лицами
(ГНИ — Государственная налоговая инспекция)
Номер подсистемы служит для ее идентификации. В поле имени вводится наименование подсистемы в виде предложения с подлежащим и соответствующими определениями и дополнениями.
Процесс представляет собой преобразование входных потоков данных в выходные в соответствии с определенным алгоритмом. Физически процесс может быть реализован различными способами: это может быть подразделение организации (отдел), выполняющее обработку входных документов и выпуск отчетов, программа, аппаратное реализованное логическое устройство и т. д. Процесс на диаграмме потоков данных изображен на рисунке А.4.3.
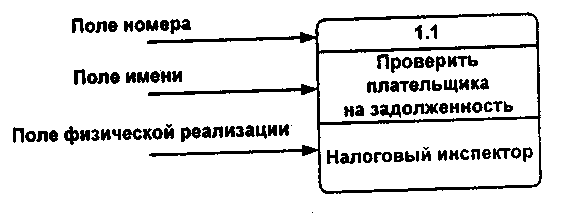
Рисунок А.4.3 - Графическое изображение процесса
Номер процесса служит для его идентификации. В поле имени вводится наименование процесса в виде предложения с активным недвусмысленным глаголом в неопределенной форме (вычислить, рассчитать, проверить, определить, создать, получить), за которым следуют существительные в винительном падеже, например: "Ввести сведения о налогоплательщиках", "Выдать информацию о текущих расходах", "Проверить поступление денег".
Использование таких глаголов, как "обработать", "модернизировать" или "отредактировать", означает недостаточно глубокое понимание данного процесса и требует дальнейшего анализа.
Информация в поле физической реализации показывает, какое подразделение организации, программа или аппаратное устройство выполняет данный процесс.
Накопитель данных - это абстрактное устройство для хранения информации, которую можно в любой момент поместить в накопитель и через некоторое время извлечь, причем способы помещения и извлечения могут быть любыми.
Накопитель данных может быть реализован физически в виде микрофиши, ящика в картотеке, таблицы в оперативной памяти, файла на магнитном носителе и т. д. Накопитель данных на диаграмме потоков данных (рисунок А.4.4) идентифицируется буквой "D" и произвольным числом. Имя накопителя выбирается из соображения наибольшей информативности для проектировщика.
Накопитель данных в общем случае является прообразом будущей базы данных, и описание хранящихся в нем данных должно быть увязано с информационной моделью (ERD).

Рисунок А.4.4 - Графическое изображение накопителя данных
Поток данных определяет информацию, передаваемую через некоторое соединение от источника к приемнику. Реальный поток данных может быть информацией, передаваемой по кабелю между двумя устройствами, пересылаемыми по почте письмами, магнитными лентами или дискетами, переносимыми с одного компьютера на другой, и т. д.
Поток данных на диаграмме изображается линией, оканчивающейся стрелкой, которая показывает направление потока (рисунок А.4.5). Каждый поток данных имеет имя, отражающее его содержание.
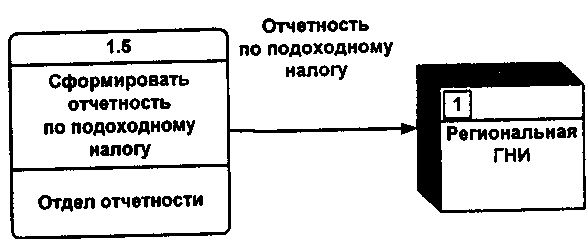
Рисунок А.4.5 - Поток данных
Построение иерархии диаграмм потоков данных
Главная цель построения иерархии DFD заключается в том, чтобы сделать требования к системе ясными и понятными на каждом уровне детализации, а также разбить эти требования на части с точно определенными отношениями между ними. Для достижения этого целесообразно пользоваться следующими рекомендациями:
- размещать на каждой диаграмме от 3 до 6—7 процессов. Верхняя граница соответствует человеческим возможностям одновременного восприятия и понимания структуры сложной системы с множеством внутренних связей, нижняя граница выбрана по соображениям здравого смысла: нет необходимости детализировать процесс диаграммой, содержащей всего один процесс или два;
- не загромождать диаграммы не существенными на данном уровне деталями;
- декомпозицию потоков данных осуществлять параллельно с декомпозицией процессов. Эти две работы должны выполняться одновременно, а не одна после завершения другой;
- выбирать ясные, отражающие суть дела имена процессов и потоков, при этом стараться не использовать аббревиатуры.
Первым шагом при построении иерархии DFD является построение контекстных диаграмм. Обычно при проектировании относительно простых систем строится единственная контекстная диаграмма со звездообразной топологией, в центре которой находится так называемый главный Процесс, соединенный с приемниками и источниками информации, посредством которых с системой взаимодействуют пользователи и другие внешние системы. Перед построением контекстной DFD необходимо проанализировать внешние события (внешние сущности), оказывающие влияние на функционирование системы. Количество потоков на Контекстной диаграмме должно быть по возможности небольшим, поскольку каждый из них может быть в дальнейшем разбит на несколько потоков на следующих уровнях диаграммы.
Для проверки контекстной диаграммы можно составить список событий. Список событий должен состоять из описаний действий внешних сущностей (событий) и соответствующих реакций системы на события. Каждое событие должно соответствовать одному (или более) потоку данных: входные потоки интерпретируются как воздействия, а выходные потоки — как реакции системы на входные потоки.
Если для сложной системы ограничиться единственной контекстной диаграммой, то она будет содержать слишком большое количество источников и приемников информации, которые трудно расположить на листе бумаги нормального формата, и, кроме того, единственный главный процесс не раскрывает структуры такой системы. Признаками сложности (в смысле контекста) могут быть: наличие большого количества внешних сущностей (десять и более), распределенная природа системы, многофункциональность системы с уже сложившейся или выявленной группировкой функций в отдельные подсистемы.
Для сложных систем строится иерархия контекстных диаграмм. При этом контекстная диаграмма верхнего уровня содержит не единственный главный процесс, а набор подсистем, соединенных потоками данных. Контекстные диаграммы следующего уровня детализируют контекст и структуру подсистем.
Иерархия контекстных диаграмм определяет взаимодействие основных функциональных подсистем, как между собой, так и с внешними входными и выходными потоками данных и внешними объектами (источниками и приемниками информации), с которыми взаимодействует система.
Разработка контекстных диаграмм решает проблему строгого определения функциональной структуры ЭИС на самой ранней стадии ее проектирования, что особенно важно для сложных многофункциональных систем, в создании которых участвуют разные организации и коллективы разработчиков.
После построения контекстных диаграмм полученную модель следует проверить на полноту исходных данных об объектах системы и изолированность объектов (отсутствие информационных связей с другими объектами).
Для каждой подсистемы, присутствующей на контекстных диаграммах, выполняется ее детализация при помощи DFD. Это можно сделать путем построения диаграммы для каждого события. Каждое событие представляется в виде процесса с соответствующими входными и выходными потоками, накопителями данных, внешними сущностями и ссылки на другие процессы для описания связей между этим процессом и его окружением. Затем все построенные диаграммы сводятся в одну диаграмму нулевого уровня.
Каждый процесс на DFD, в свою очередь, может быть детализирован при помощи DFD или (если процесс элементарный) спецификации. При детализации должны выполняться следующие правила:
- правило балансировки - при детализации подсистемы или процесса детализирующая диаграмма в качестве внешних источников или приемников данных может иметь только те компоненты (подсистемы, процессы, внешние сущности, накопители данных), с которыми имеют информационную связь детализируемые подсистема или процесс на родительской диаграмме;
- правило нумерации — при детализации процессов должна поддерживаться их иерархическая нумерация. Например, процессы, детализирующие процесс с номером 12, получают номера 12.1, 12.2, 12.3 и т. д.
Спецификация процесса должна формулировать его основные функции таким образом, чтобы в дальнейшем специалист, выполняющий реализацию проекта, смог выполнить их или разработать соответствующую программу. Спецификация является конечной вершиной иерархии DFD. Решение о завершении детализации процесса и использовании спецификации принимается аналитиком исходя из следующих критериев:
- наличия у процесса относительно небольшого количества входных и выходных потоков данных (2 — 3 потока);
- возможности описания преобразования данных процессом в виде последовательного алгоритма;
- выполнения процессом единственной логической функции преобразования входной информации в выходную;
- возможности описания логики процесса при помощи спецификации небольшого объема (не более 20 - 30 строк).
Сравнительный анализ sadt-моделей и диаграмм потоков данных
Как уже отмечалось, практически во всех методах структурного подхода (структурного анализа) на стадии формирования требований к ПО используются две группы средств моделирования:
- диаграммы, иллюстрирующие функции, которые система должна выполнять, и связи между этими функциями - DFD или SADT (IDEF0);
- диаграммы, моделирующие данные и их отношения (ERD).
Таким образом, наиболее существенное различие между разновидностями структурного анализа заключается в средствах функционального моделирования. С этой точки зрения все разновидности структурного анализа могут быть разбиты на две группы - использующие DFD (в различных нотациях) и использующие SADT-модели. Соотношение применения этих двух разновидностей структурного анализа в существующих CASE-средствах составляет 90% для DFD и 10% для SADT. Вероятно, соотношение такого же порядка справедливо и для распространенности рассматриваемых моделей на практике.
Сравнительный анализ этих двух разновидностей методов структурного анализа проводится по следующим параметрам:
- адекватность средств решаемым задачам;
- согласованность с другими средствами структурного анализа;
- интеграция с последующими стадиями ЖЦ ПО (прежде всего со стадией проектирования).
Адекватность средств решаемым задачам. Модели SADT (IDEFO) традиционно используются для моделирования организационных систем. С другой стороны, не существует никаких принципиальных ограничений на использование DFD в качестве средства построения статических моделей деятельности организаций.
Следует отметить, что метод SADT успешно работает только при описании хорошо специфицированных и стандартизованных бизнес-процессов в зарубежных корпорациях, поэтому он и принят в США в качестве типового. Например, в Министерстве обороны США десятки лет существуют четкие должностные инструкции и методики, которые жестко регламентируют деятельность подразделений, делают её высокотехнологичной и ориентированной на бизнес-процесс. В российской действительности с ее слабой типизацией бизнес-процессов, их стихийным появлением и развитием разумнее ориентироваться на модели, основанные на потоковых диаграммах.
Если же речь идет не о системах вообще, а о ЭИС, то здесь DFD вне конкуренции. Практически любой класс систем успешно моделируется при помощи DFD-ориентированных методов. SADT-диаграммы оказываются значительно менее выразительными и удобными при моделировании ЭИС.
Так, дуги в SADT жестко типизированы (вход, выход, управление, механизм). В то же время применительно к ЭИС стирается смысловое различие между входами и выходами, с одной стороны, и управлениями и механизмами, с другой — входы, выходы и управления являются потоками данных и правилами их преобразования. Анализ системы с помощью потоков данных и процессов, их преобразующих, является более прозрачным и недвусмысленным.
Более того, в SADT вообще отсутствуют выразительные средства для моделирования особенностей ЭИС. DFD же с самого начала создавались как средство проектирования информационных систем (SADT — как средство моделирования систем вообще) и имеют более богатый набор элементов, адекватно отражающих специфику таких систем (например, хранилища данных являются прообразами файлов или баз данных, внешние сущности отражают взаимодействие моделируемой системы с внешним миром).
Наличие в DFD спецификаций процессов нижнего уровня позволяет преодолеть логическую незавершенность SADT (а именно обрыв модели на некотором достаточно низком уровне, когда дальнейшая ее детализация становится бессмысленной) и построить полную функциональную спецификацию разрабатываемой системы.
Согласованность с другими средствами структурного анализа. Главным достоинством любых моделей является возможность их интеграции с моделями других типов. В данном случае речь идет о согласованности функциональных моделей со средствами моделирования данных. Согласование SADT-модели с ERD практически невозможно или носит искусственный характер. В свою очередь, DFD и ERD взаимно дополняют друг друга и являются согласованными, поскольку в DFD присутствует описание структур данных, непосредственно используемое для построения ERD.
Интеграция с последующими стадиями ЖЦ ПО. Важная характеристика модели — ее совместимость с моделями последующих стадий ЖЦ (прежде всего стадии проектирования, непосредственно следующей за стадией формирования требований и опирающейся на ее результаты).
DFD могут быть легко преобразованы в модели проектируемой системы. Более того, известен ряд алгоритмов автоматического преобразования иерархии DFD в структурные карты различных видов, что обеспечивает логичный и безболезненный переход от формирования требований к проектированию системы. С другой стороны, формальные методы преобразования SADT-диаграмм в проектные решения ЭИС отсутствуют.
В заключение необходимо отметить, что одним из основных критериев выбора того или иного метода является степень владения им со стороны консультанта или аналитика, грамотность выражения своих мыслей на языке моделирования. В противном случае в моделях, построенных с использованием любого метода, будет невозможно разобраться.
Средства структурного анализа и их взаимосвязи
Прежде чем подробно рассмотреть каждое из основных инструментальных средств структурного анализа, необходимо обсудить их в общем виде и продемонстрировать их взаимосвязи.
Для целей моделирования систем вообще, и структурного анализа в частности, используются три группы средств, иллюстрирующих:
- функции, которые система должна выполнять;
- отношения между данными;
- зависящее от времени поведение системы (аспекты реального времени).
Среди всего многообразия средств решения данных задач в методологиях структурного анализа наиболее часто и эффективно применяемыми являются следующие:
DFD (Data Flow Diagrams) — диаграммы потоков данных совместно со словарями данных и спецификациями процессов;
ERD (Entity-Relationship Diagrams) — диаграммы "сущность-связь";
STD (State Transition Diagrams) — диаграммы переходов состояний.
Все они содержат графические и текстовые средства моделирования: первые — для удобства демонстрирования основных компонентов модели, вторые — для обеспечения точного определения ее компонентов и связей.
Логическая DFD показывает внешние по отношению к системе источники и стоки (адресаты) данных, идентифицирует логические функции (процессы) и группы элементов данных, связывающие одну функцию с другой (потоки), а также идентифицирует хранилища (накопители) данных, к которым осуществляется доступ. Структуры потоков данных и определения их компонентов хранятся и анализируются в словаре данных. Каждая логическая функция (процесс) может быть детализирована с помощью DFD нижнего уровня; когда дальнейшая детализация перестает быть полезной, переходят к выражению логики функции при помощи спецификации процесса (мини-спецификации). Содержимое каждого хранилища также сохраняют в словаре данных, модель данных хранилища раскрывается с помощью ERD. В случае наличия реального времени DFD дополняется средствами описания зависящего от времени поведения системы, раскрывающимися с помощью STD. Эти связи показаны на рисунке А.4.6.
Перечисленные средства дают полное описание системы независимо от того, является ли она существующей или разрабатываемой с нуля. Таким образом строится логическая функциональная спецификация — подробное описание того, что должна делать система, освобожденное насколько это возможно от рассмотрения путей реализации. Это дает проектировщику четкое представление о конечных результатах, которые следует достигать.
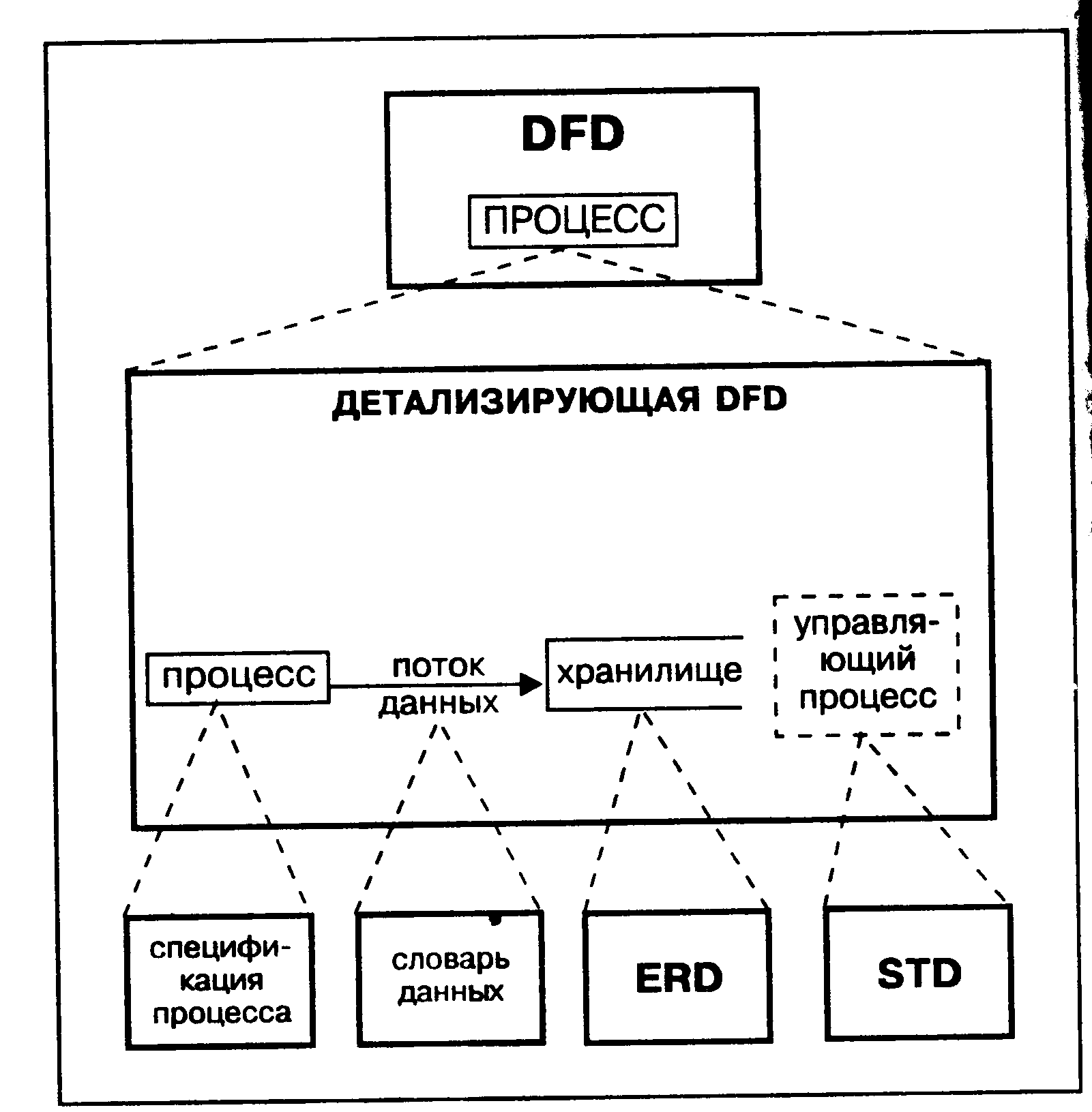
Рисунок А.4.6 - Компоненты логической модели
Диаграммы потоков данных (DFD) являются основным средством моделирования функциональных требований проектируемой системы. С их помощью эти требования разбиваются на функциональные компоненты (процессы) и представляются в виде сети, связанной потоками данных. Главная цель таких средств — продемонстрировать, как каждый процесс преобразует свои входные данные в выходные, а также выявить отношения между этими процессами.
Для изображения DFD традиционно используются две различные нотации: Иодана (Yourdon) и Гейна-Сарсона (Gane-Sarson). Далее при построении примеров будет использоваться нотация Иодана, все исключения будут предварительно оговариваться.
Основные символы DFD
Основные символы DFD изображены на рисунке А.4.7. Опишем их назначение. На диаграммах функциональные требования представляются с помощью процессов и хранилищ, связанных потоками данных.
1) Потоки данных (Flow) являются механизмами, использующимися для моделирования передачи информации (или даже физических компонентов) из одной части системы в другую. Потоки на диаграммах обычно изображаются именованными стрелками, ориентация которых указывает направление движения информации. Иногда информация может двигаться в одном направлении, обрабатываться и возвращаться назад в ее источник. Такая ситуация может моделироваться либо двумя различными потоками, либо одним - двунаправленным.
2) Назначение процесса (Process) состоит в преобразовании входных потоков в выходные в соответствии с действием, задаваемым именем процесса. Это имя должно содержать глагол в неопределенной форме с последующим дополнением (например, вычислить максимальную высоту). Кроме того, каждый процесс должен иметь уникальный номер для ссылок на него внутри диаграммы. Этот номер может использоваться совместно с номером диаграммы для получения уникального индекса процесса во всей модели.
3) Хранилище (накопитель, Store) данных позволяет на определенных участках определять данные, которые будут сохраняться в памяти между процессами. Фактически хранилище представляет “срезы” потоков данных во времени. Информация, которую оно содержит, может использоваться в любое время после ее определения. Имя хранилища должно идентифицировать его содержимое и быть существительным. В случае, когда поток данных входит или выходит в/из хранилища, и его структура соответствует структуре хранилища, он должен иметь то же самое имя, которое нет необходимости отражать на диаграмме.
4) Внешняя сущность (External entity) представляет сущность вне контекста системы, являющуюся источником или приемником системных данных. Ее имя должно содержать существительное, например, СКЛАД ТОВАРОВ. Предполагается, что объекты, представленные такими узлами, не должны участвовать ни в какой обработке.
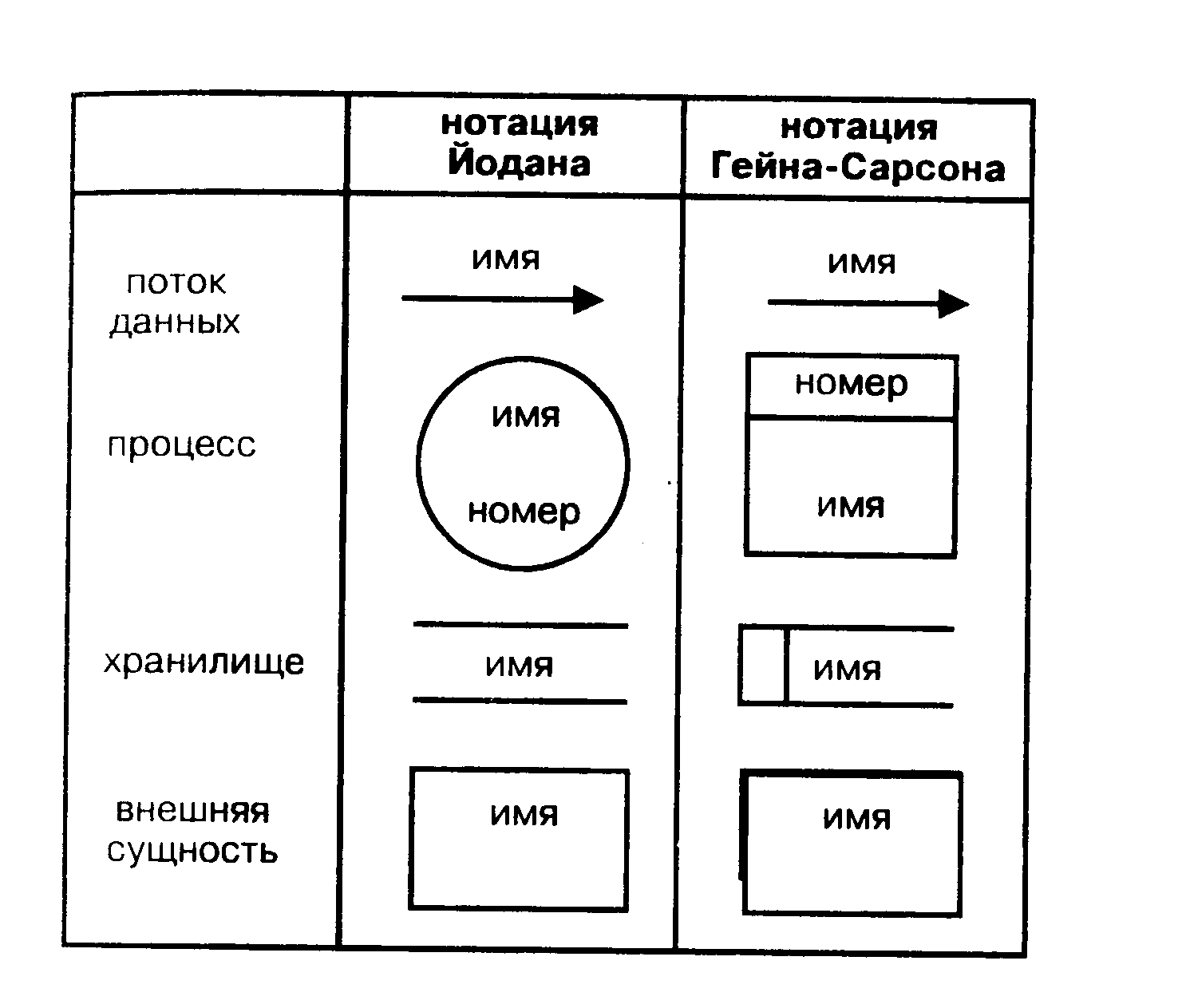
Рисунок А.4.7 - Основные символы диаграмм потоков данных
Контекстная диаграмма и детализация процессов
Декомпозиция DFD осуществляется на основе процессов: каждый процесс может раскрываться с помощью DFD нижнего уровня.
Важную специфическую роль в модели играет специальный вид DFD — контекстная диаграмма, моделирующая систему наиболее общим образом. Контекстная диаграмма отражает интерфейс системы с внешним миром, а именно, информационные потоки между системой и внешними сущностями, с которыми она должна быть связана. Она идентифицирует эти внешние сущности, а также, как правило, единственный процесс, отражающий главную цель или природу системы насколько это возможно. Каждый проект должен иметь только одну контекстную диаграмму, при этом нет необходимости в нумерации ее единственного процесса.
DFD первого уровня строится как декомпозиция процесса, который присутствует на контекстной диаграмме.
Построенная диаграмма первого уровня также имеет множество процессов, которые в свою очередь могут быть декомпозированы в DFD нижнего уровня. Таким образом строится иерархия DFD с контекстной диаграммой в корне дерева. Этот процесс декомпозиции продолжается до тех пор, пока процессы могут быть эффективно описаны с помощью коротких (до одно страницы) миниспецификаций обработки (спецификаций процессов).
При таком построении иерархии DFD каждый процесс более низкого уровня необходимо соотнести с процессом верхнего уровня. Обычно для этой цели используются структурированные номера процессов. Так, например, если мы детализируем процесс номер 2 на диаграмме первого уровня, раскрывая его с помощь DFD, содержащей три процесса, то их номера будут иметь следующий вид: 2.1, 2.2 и 2.3. При необходимости можно перейти на следующий уровень, т.е. для процесса 2.2 получим 2.2.1, 2.2.2 и т.д.
Примеры DFD диаграммы представлены на рисунках А.4.8-4.10.
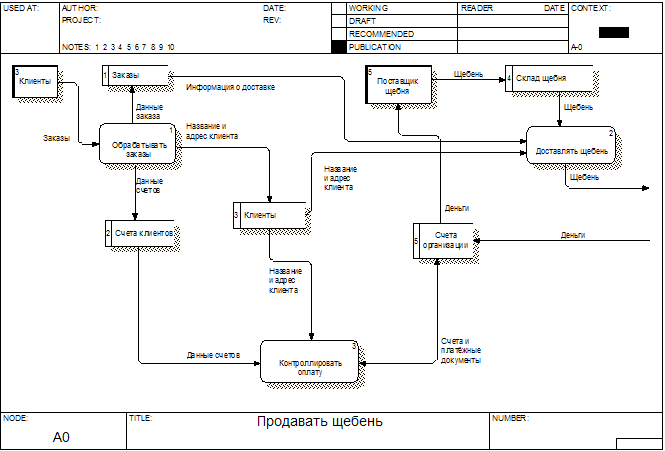
Рисунок А.4.8 – Пример 1 DFD диаграммы
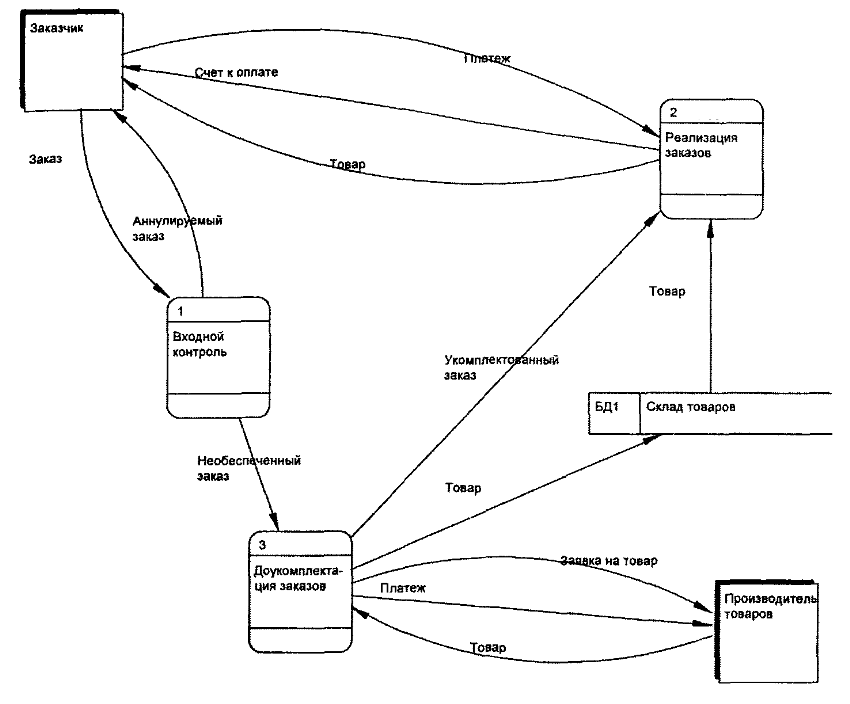
Рисунок А.4.9 – Пример 2 DFD диаграммы
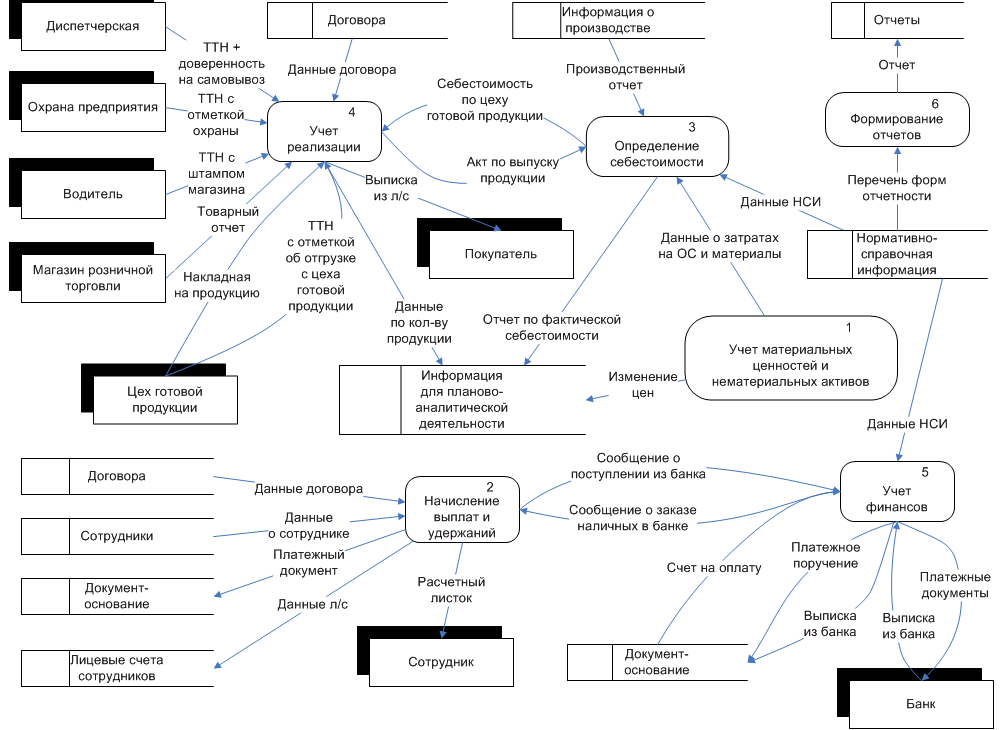
Рисунок А.4.10 – Пример DFD диаграммы для описания потоков данных при бухгалтерском учете на небольшом производственном предприятии