

555_Innovatsii_inauchno-tekhnicheskoe_tvorchestvo_molodezhi2014_
.pdf
Рисунок
Функционал называется диаметральным функционалом и применяется к столбцам trace–матрицы. Здесь рассматривается три его варианта:
Первым вариантом является стандартная норма. Вторым вариантом является максимум функции. Третий вариант является стандартным центром массы.
Функционал называется круговым. Он применяется к 2 – периодической функции, полученной после применения функционала. Здесь применяется два его варианта:
Первым вариантом является вычисление логарифма по формуле
2
h ln h 1d .
0
Вторым вариантом является просто интеграл 2 –периодической функции
2
h h d .
0
Комбинируя данные функционалы можно получить триплетные признаки устойчивые к различным аффинным преобразованиям, таким как сдвиг, поворот и масштабирование [2].
На этапе обучения приложения в базу данных заносятся некоторые объекты, полученные в результате сегментации, а затем для них с использованием выбранных , и функционалов вычисляются значения различных триплетных признаков. Далее в этом модуле предусмотрена оптимизация полученного набора признаков с целью отбора наиболее информативных.
На этапе распознавания в приложение загружается образ, для которого вычисляются наиболее информативные признаки, и на их основе осуществляется распознавание. На данный момент в качестве алгоритма распознавания используется простой алгоритм процентного сравнения с эталоном.
В целом для ускорения работы системы планируется разработать драйвер, позволяющий программным модулям взаимодействовать с графическим процессором персонального компьютера. Графический процессор может использоваться для выполнения наиболее длительных и часто встречающихся операций, таких как процедуры сканирования изображений, вычисление для них значений триплетных признаков.
373
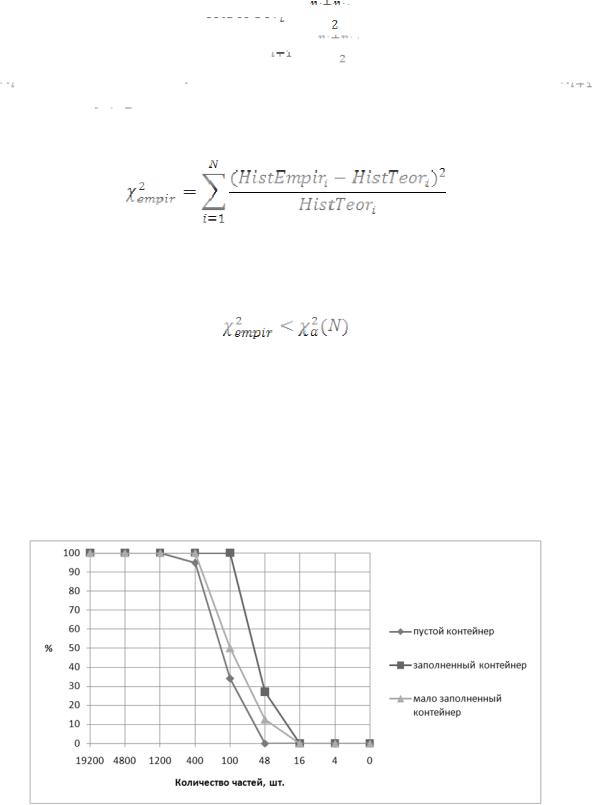
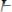























 ,
,























 ,
,
 – число пикселей
– число пикселей 
 той яркости эмпирической гистограммы,
той яркости эмпирической гистограммы, 


 – число пикселей
– число пикселей 


 ой яркости эмпирической гистограммы.
ой яркости эмпирической гистограммы.
 и количестве степеней свободы N.
и количестве степеней свободы N.

ИННОВАЦИИ И НАУЧНО-ТЕХНИЧЕСКОЕ ТВОРЧЕСТВО МОЛОДЕЖИ
РОССИЙСКАЯ НАУЧНО-ТЕХНИЧЕСКАЯ КОНФЕРЕНЦИЯ
МАТЕРИАЛЫ КОНФЕРЕНЦИИ
Редактор: Белезекова А.С. Верстка: Белезекова А.С.
Подписано в печать 15.04.2014,
формат бумаги 62x84/16, отпечатано на ризографе, шрифт №10, изд. л. 23,8, заказ № 44 , тираж 30. СибГУТИ
630102, Новосибирск, ул. Кирова, 86.