

3. Проект архитектуры:
Проект архитектуры – это разработка внутреннего представления данных и преобразование их в соответствующую форму. Процесс компиляции можно проводить последовательно, а можно параллельно.
При последовательной обработке необходимо:
из текста программы на ПАСКАЛЕ выделить лексемы, из которых она состоит;
построить из полученных лексем дерево синтаксического разбора, соответствующее входным данным;
строят выходной код, основываясь на дереве синтаксического разбора, соответствующий входному файлу.
При параллельной обработке выбирается очередной символ из входного потока, если эта законченная лексема, то проводиться её анализ и генерируется выходной код, соответствующий этой лексеме.
В курсовой работе процесс компиляции будем проводить последовательно.
Таким образом, для процесса компиляции необходимо написать три модуля:
Модуль для лексического анализа (lex.pas);
Модуль для синтаксического анализа (sa_unit);
Модуль для генератора кода (gen_unit.pas).
Таким образом, процесс компиляции будет проходить следующим образом:
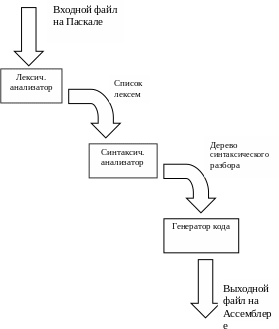
Распишем подробно выполняемые функции и данные, которые используются в каждом из модулей.
Лексический анализ
Типы данных:
Для представления лексем используем тип Symbol:
Symbol: array[1..8] of char;
Тип TLexema используется для распознавания очередной лексемы (принадлежит ли она к ключевым словам или это переменная или терминальный символ)
TLexema = record
Type:TypOfLex; // Тип лексемы
Value: Symbol; //значение лексемы
end;
При обработке входного файла полученные лексемы будем записывать в массив лексем:
SLexem: array [1..maxEntry] of TLexema;
maxEntry - константа максимального количества лексем
Тип лексемы – перечисляемый тип
typeoflexema=(bgop,endop,ifop,elsop,forop,toop,readop,
writop,readlnop,writlnop,boolop,falsop,truop,intop,tzop,ttop,sko,skz,skko,skkz,addinst,subinst,letop,twop,konst,prg,varop,doop,tk,teq,thenop,mulinst,divinst,Varable,orinst,andinst,bool);
Распишем типы лексем:
Bgop - лексема begin;
Endop - лексема end;
Ifop - лексема if;
Elsop - лексема else;
Forop - лексема for;
Toop - лексема To;
Readop - лексема Read;
Writop - лексема Write;
readlnop - лексема Readln;
writlnop - лексема Writeln;
boolop – лексема Boolean;
falsop - лексема False;
truop - лексема True;
intop - лексема integer;
tzop - лексема ‘;’;
ttop - лексема ‘:’;
sko - лексема ‘(’;
skz - лексема ‘)’;
skko - лексема ‘[’;
skkz - лексема ‘]’;
addinst - лексема ‘+’;
subinst - лексема ‘-’;
letop - лексема ‘:=’;
twop - лексема ‘..’;
konst - константы;
prg - лексема program;
varop - лексема var;
doop - лексема Do;
tk - лексема ‘.’;
teq - лексема ‘=’;
thenop - лексема then;
mulinst - лексема ‘*’;
divinst - лексема ‘/’;
Varable - переменная;
Orinst - лексема or;
Andinst - лексема and;
Bool - лексема boolean;
Tgt - лексема ‘>’;
Tlt - лексема ‘<’;
Tge - лексема ‘>=’;
Tle - лексема ‘<=’;
Tne - лексема ‘<>’;
Синтаксический анализ
При синтаксическом анализе проводиться разбор лексем, выделенных при лексическом анализе, и построение дерева синтаксического разбора. Построим синтаксические деревья для всех грамматических конструкций.
Для программы строится дерево следующего вида:
Входные лексемы:
Program main;
Var <имя переменной>: <тип переменой>;
….
Begin
{составной оператор};
End.
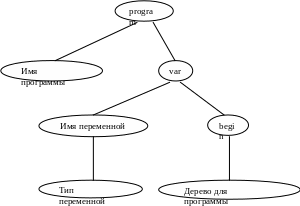
Деревья для описания переменных, используемых в программе, строятся следующим образом:



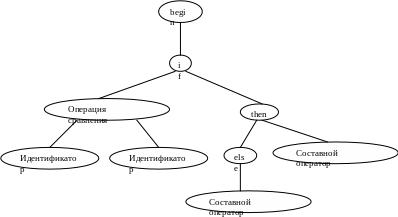
Дерево для оператора IF, строится следующим образом:
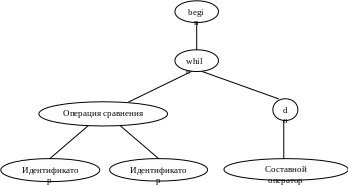
Дерево для оператора WHILE строится следующим образом:
Дерево для операторов Read, Write, Readln, Writeln строятся следующим образом:

Синтаксический анализ арифметических выражений будем проводить следующим образом:
Анализ арифметического выражения;
Перевод арифметического выражения в обратную польскую запись;
Построение дерева по обратной польской записи.
Перевод арифметического выражения в обратную польскую запись произведем по следующему алгоритму:
Операнды переписываются в выходную строку.
Открывающая скобка помещается в стек.
Знаки операций помещаются в стек, из которого предварительно выталкиваются, и помещаются в выходную строку все знаки с большими или равными приоритетами.
Закрывающая скобка выталкивает из стека в выходную строку все знаки до открывающей скобки, и уничтожается вместе с ней.
Генератор кода
По дереву, составленному на этапе синтаксического анализа, вырабатываем выходной код, соответствующий входному файлу input.pas.
Выходной файл формируется следующим образом:
Формируется заголовок для выходного файла;
. Model Small ; используемая модель памяти - малая
. Stack 256 ; определим стек размером 256
Формируется сегмент данных, состоящий из описаний переменных, используемых в программе.
.DATA
<имя переменной> <тип переменной> <начальное значение>
Формируется заголовок для сегмента кода:
.Code
Start:
mov Ax, @Data ;сохраняем в регистре Ax смещение сегмента данных
mov Ds, Ax ;сохраняем в сегментном регистре Ds его смещение
Формируется код соответствующий программе.
Для каждого оператора программы строится соответствующий выходной код по правилам, описанным во внешнем проекте.
Формируется окончание программы.
mov Ax,4C00h
int 21h
END Start
Выходной код для операторов, используемых в программе, приведен в разделе внешнего проекта.
Тестирование
Входной файл input.pas
program main;
var a:integer;
i:integer;
j:integer;
k:integer;
mass:array[1..20] of integer;
begin
j:=(i+j-k)/(i-j)/(k+i)+10;
for i:= 1 to 20 do begin
read(a);
if a<i then Mass[i]:=a/2
else Mass[i]:=a*2;
end;
end.
Выходной файл output.asm
.MODEL SMALL
.STACK 128
.DATA
MASS dw 20 dup (?)
K dw 0
J dw 0
I dw 0
A dw 0
Start:
move Ax,@DATA
move Ds,Ax
move Ax,10
push Ax
move Ax,I
push Ax
move Ax,K
push Ax
pop Ax
pop Bx
add Ax,Bx
push Ax
move Ax,J
push Ax
move Ax,I
push Ax
pop Ax
pop Bx
sub Ax,Bx
push Ax
pop Ax
pop Bx
div Ax,Bx
push Ax
pop Ax
pop Bx
add Ax,Bx
push Ax
move Ax,K
push Ax
move Ax,J
push Ax
move Ax,I
push Ax
pop Ax
pop Bx
add Ax,Bx
push Ax
pop Ax
pop Bx
sub Ax,Bx
push Ax
pop Ax
pop Bx
div Ax,Bx
push Ax
pop Ax
move J,Ax
move Cx,20
sub Cx,1
inc Cx
move I,1
lp0:
ink I
push Cx
call read
move A,Ax
move Ax,A
cmp AX,I
jg lp3
move Ax,2
push Ax
move Ax,A
push Ax
pop Ax
pop Bx
mul Ax,Bx
push Ax
move Ax,I
push Ax
pop Ax
pop Bx
div Ax,Bx
push Ax
pop Ax
move Bx,I
move MASS [Bx],Ax
j lp4
lp3:
lp4:
pop Cx
loop lp0
mov Ax,04CH
int 21h
end Start
Входной файл input.pas
program main;
var a:integer;
i:integer;
j:integer;
k:integer;
mass:array[1..20] of integer;
begin
j:=((((i+j)*k+i)/a+10)*i+8)/3;
if a<i then
begin
for i:= 1 to 20 do
begin
read(a);
Mass[i]:=a/2;
end;
end;
end.
Выходной файл output.asm
.MODEL SMALL
.STACK 128
.DATA
MASS dw 20 dup (?)
K dw 0
J dw 0
I dw 0
A dw 0
Start:
move Ax,@DATA
move Ds,Ax
move Ax,3
push Ax
move Ax,8
push Ax
move Ax,I
push Ax
move Ax,10
push Ax
move Ax,A
push Ax
move Ax,I
push Ax
move Ax,K
push Ax
move Ax,J
push Ax
move Ax,I
push Ax
pop Ax
pop Bx
add Ax,Bx
push Ax
pop Ax
pop Bx
mul Ax,Bx
push Ax
pop Ax
pop Bx
add Ax,Bx
push Ax
pop Ax
pop Bx
div Ax,Bx
push Ax
pop Ax
pop Bx
add Ax,Bx
push Ax
pop Ax
pop Bx
mul Ax,Bx
push Ax
pop Ax
pop Bx
add Ax,Bx
push Ax
pop Ax
pop Bx
div Ax,Bx
push Ax
pop Ax
move J ,Ax
move Ax,A
cmp AX,I
jg lp2
move Cx,20
sub Cx,1
inc Cx
move I,1
lp2:
ink I
push Cx
call read
move A,Ax
move Ax,2
push Ax
move Ax,A
push Ax
pop Ax
pop Bx
div Ax,Bx
push Ax
pop Ax
move Bx,I
move MASS[Bx],Ax
pop Cx
loop lp2
j lp3
lp2:
lp3:
mov Ax,04CH
int 21h
end Start
Тестирование процедуры
Для тестирования выберем процедуру, реализующую алгоритм преобразования выражения в обратную польскую запись. Этот алгоритм описан в предыдущих разделах. Тестирование будем проводить, предполагая, что все нижележащие модули (процедуры) протестированы. Приведем текст процедуры:
procedure tested;
var tec:TLexema;
begin
case sLexem[tlex].Type of
varable,konst:outs(sLexem[tlex]);
sko:push(sLexem[tlex]);
skz: begin pop(tec);
while tec.Type<>sko do
begin
outs(tec);pop(tec);
end;
end;
addinst,subinst:begin
if pStek<>1 then
begin pop(tec);
while (pStek<>1)and (tec.Type<>sko) or
(tec.Type=addinst) or
(tec.Type=subinst) do
begin
outs(tec);
if pStek<>1 then pop(tec);
end;
push(tec);
end;
push(sLexem[tlex]);
end;
mulinst,divinst: begin
if pStek<>1 then
begin pop(tec);
while ((pStek>1)and ((tec.Type=mulinst) or
(tec.Type=divinst))) do
begin
outs(tec);
if pStek<>1 then pop(tec);
end;
push(tec);
end;
push(sLexem[tlex]);
end;
else err(1,' ');
end; end.
Алгоритм выполнения процедуры


Тестирование будем проводить по следующей схеме:
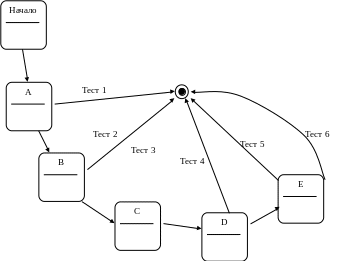
Ветвления:
A |
Slexem[tLex].Type=Varable or SLexem[tLex].Type=konst |
B |
Slexem[tLex].Type=sko |
C |
Slexem[tLex].Type=skz |
D |
Slexem[tLex].Type=addinst or SLexem[tLex].Type=subinst |
E |
Slexem[tLex].Type=mulinst or SLexem[tLex].Type=divinst |
Текст программы-драйвера для тестирования этой процедуры приведен ниже:
program test;
uses crt,sa_unit,gen;
procedure outst;
var i:integer;
begin
for i:=1 to pOut-1 do writeln(OutStr[i].Value);
end;
procedure outstack;
var i:integer;
begin
for i:=1 to pStek-1 do write(Stek[i].Value);
end;
procedure test1;
var i:integer;
begin
clrscr;
tlex:=1;
sLexem[tlex].Type:=Varable;
sLexem[tlex].Value:='pol ';
pStek:=1;
pOut:=1;
tested;
writeln('Выходная строка');
write('Расчетная:');writeln(sLexem[tlex].Value
);
write('Фактически:');
outst;
if sLexem[tlex].Value<>OutStr[1].Value then writeln('Ошибка') else
writeln('Данные соответствуют');
writeln('Содержимое стека');
writeln('Расчетное: стек пуст');
write('Фактически:');
outstack;
end;
{****************************************}
procedure test2;
var i:integer;
begin
clrscr;
tlex:=1;
sLexem[tlex].Type:=sko;
sLexem[tlex].Value:='( ';
pStek:=1;
pOut:=1;
tested;
writeln('Выходная строка');
writeln('Расчетная: строка пуста');
write('Фактически:');outst;
writeln('Содержимое стека');
writeln('Расчетное: "( "');
writeln('Фактически:');outstack;
end;
{****************************************}
procedure test3;
var i:integer;
St:TLexema;
begin
clrscr;
tlex:=1;
sLexem[tlex].Type:=skz;
sLexem[tlex].Value:=') ';
pStek:=1;
St.Value:='( ';
St.Type:=sko;
push(St);
St.Value:='+ ';
St.Type:=addinst;
push(St);
St.Value:='* ';
St.Type:=mulinst;
push(St);
St.Value:='/ ';
St.Type:=divinst;
push(St);
pOut:=1;
tested;
writeln('Выходная строка');
writeln('Расчетная: / * +');
write('Фактически:');outst;
writeln('Содержимое стека');
writeln('Расчетное: стек пуст');
writeln('Фактически:');outstack;
end;
{****************************************}
procedure test4;
var i:integer;
St:TLexema;
begin
clrscr;
tlex:=1;
sLexem[tlex].Type:=addinst;
sLexem[tlex].Value:='+ ';
pStek:=1;
St.Value:='- ';
St.Type:=subinst;
push(St);
St.Value:='( ';
St.Type:=sko;
push(St);
St.Value:='* ';
St.Type:=mulinst;
push(St);
St.Value:='+ ';
St.Type:=addinst;
push(St);
St.Value:='* ';
St.Type:=mulinst;
push(St);
St.Value:='/ ';
St.Type:=divinst;
push(St);
pOut:=1;
tested;
writeln('Выходная строка');
writeln('Расчетная: / * + * +');
write('Фактически:');outst;
writeln('Содержимое стека');
writeln('Расчетное: - ( + ');
writeln('Фактически:');outstack;
end;
{****************************************}
procedure test5;
var i:integer;
St:TLexema;
begin
clrscr;
tlex:=1;
sLexem[tlex].Type:=mulinst;
sLexem[tlex].Value:='* ';
pStek:=1;
St.Value:='- ';
St.Type:=subinst;
push(St);
St.Value:='( ';
St.Type:=sko;
push(St);
St.Value:='* ';
St.Type:=mulinst;
push(St);
St.Value:='+ ';
St.Type:=addinst;
push(St);
St.Value:='* ';
St.Type:=mulinst;
push(St);
St.Value:='/ ';
St.Type:=divinst;
push(St);
pOut:=1;
tested;
writeln('Выходная строка');
writeln('Расчетная: / * ');
write('Фактически:');outst;
writeln('Содержимое стека');
writeln('Расчетное: - ( * + * ');
writeln('Фактически:');outstack;
end;
{****************************************}
procedure test6;
var i:integer;
St:TLexema;
begin
clrscr;
tlex:=1;
sLexem[tlex].Type:=forop;
sLexem[tlex].Value:='for ';
pStek:=1;
pOut:=1;
tested;
writeln('Выходная строка нет');
writeln('Содержимое стека нет');
end;
{****************************************}
{****************************************}
begin
test1;
readkey;
test2;
readkey;
test3;
readkey;
test4;
readkey;
test5;
readkey;
test6;
end.
Ошибки при тестировании процедуры не обнаружены.