

Запис даних
Сукупність значень зв'язаних елементів даних утворює запис даних. На мал. 1.2 такими елементами даних є прізвище і ідентифікаційний номер клієнта, тип рахунку і т.д. Записи зберігаються на деякому носії, як яке може виступати людський мозок, лист паперу, пам'ять ЕОМ, зовнішній пристрій ЕОМ, що запам'ятовує, і т.д.
Файл даних
Записи даних утворюють файл даних: файл є впорядкованою сукупністю записів. На мал. 1.2 показаний приклад файлу у віддрукованому вигляді - звіт керівника відділенням (витримка) із записами одного типу. Файл такого типу - з схожими записами (тобто що містять однакове число елементів) -називається «плоским». Файл також може містити записи різного типу. Іноді файл називають набором даних.
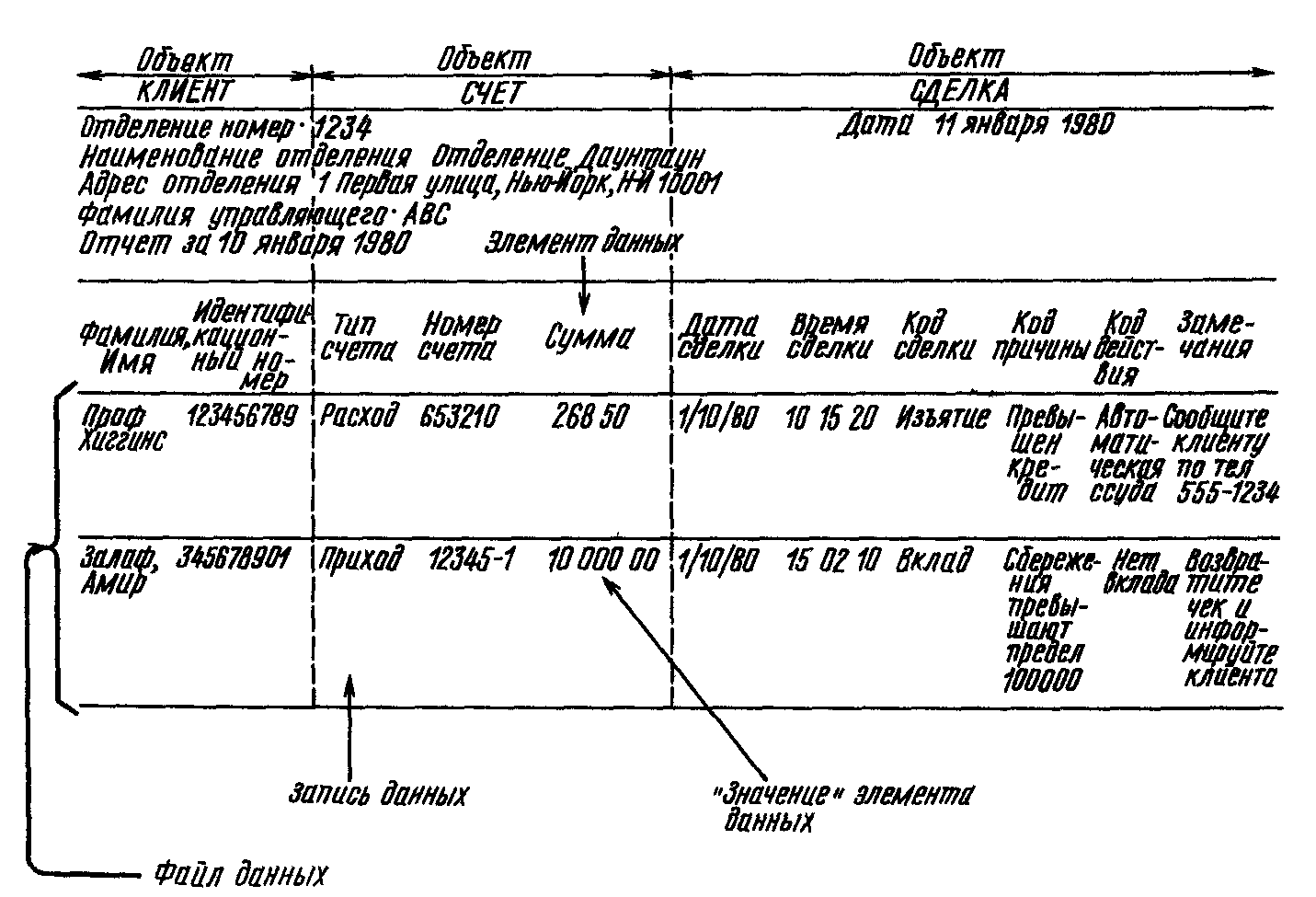
Мал.. 1.2
Методи доступу, або універсальні підпрограми доступу, гарантують різний ступінь незалежності від фізичного зберігання ліпних, при якій деякі зміни фізичного зберігання можуть відбиватися в методах доступу і не вимагати внесення змін в прикладні програми. Надалі ми розглянемо способи створення прикладних програм, не залежних від фізичних характеристик пристроїв зберігання даних. Проте раніше обговоримо деякі недоліки традиційного середовища файлів даних.
Недоліки традиційної організації файлів даних
Розглянемо задачі, пов'язані з банківськими операціями (мал. 1.1). Нижче перераховуються проблеми, з якими доводиться стикатися в процесі обробки даних при використовуванні декількох файлів.
Надмірність даних. Деякі елементи даних, такі, як ім'я, адреса і ідентифікаційний номер клієнта, неминуче використовуються в багатьох прикладних програмах. Оскільки дані потрібні декільком прикладним програмам, вони часто записуються в декілька файлів, тобто одні і ті ж дані зберігаються в різних місцях. Таке положення називають «надмірністю даних». Воно робить проблематичним забезпечення несуперечності даних. Надмірність даних вимагає наявності декількох процедур введення, оновлення і формувань звітів.
Обмеження по доступності даних. У сучасних умовах, коли обстановка швидко змінюється, особа з відповідними правами доступу необхідна мати нагоду одержати дані за прийнятний відрізок часу. Якщо ж дані розкидані по декількох файлах, доступність даних, комбінованих з цих файлів, обмежена.
Складнощі в управлінні. Через надмірність даних у файлах важко реалізувати нові директиви по всій наочній області. Наприклад, якщо номер соціального страхування не можна буде використовувати як ідентифікаційний номер, то там, де номер соціального страхування вже використовується, потрібно певні тимчасові витрати для внесення змін у всі файли.
Для вирішення вищезгаданих проблем були розроблені системи баз даних.
Класифікація баз даних. Проектування реляційної бази даних. Нормалізація даних.
За технологією обробки даних бази даних підрозділяються на централізовані і розподілені.
Централізована база даних зберігається в пам'яті однієї обчислювальної системи. Якщо ця обчислювальна система є компонентом мережі ЕОМ, можливий розподілений доступ до такої бази. Такий спосіб використовування БД часто застосовується в локальних мережах ПК.
Розподілена база даних складається з декілько х, можливо пересічних або навіть дублюючих один одного частин, що зберігаються в різних ЕОМ обчислювальної мережі. Робота з такою базою здійснюється за допомогою системи управління розподіленою базою даних (СУРБД).За способом доступу до даних БД розділяються на БД з локальним доступом і БД з видаленим (мережевим) доступом.
Системи централізованих баз даних з мережевим доступом припускають різну архітектуру подібних систем:
файл-сервер;клієнт-сервер.Файл-сервер. Архітектура системи БД з мережевим доступом припускає виділення однієї з машин мережі як центральна (сервер файлів). На такій машині зберігається спільно використовувана централізована БД. Всі інші машини мережі виконують функції робочих станцій, за допомогою яких підтримується доступ призначеної для користувача системи до централізованої бази даних. Файли бази даних відповідно до призначених для користувача запитів передаються на робочі станції, де в основному і виробляється обробка. При великій інтенсивності доступу до одних і тих же даних продуктивність інформаційної системи падає. Користувачі можуть також створювати на робочих станціях локальні БД, які використовуються ними монопольно. Клієнт-сервер. У цій концепції мається на увазі, що крім зберігання централізованої бази даних центральна машина (сервер бази даних) повинна забезпечувати виконання основного об'єму обробки даних. Запит на дані, видаваний клієнтом (робочою станцією), породжує пошук і витягання даних на сервері. Витягнуті дані (але не файли) транспортуються по мережі від серверу до клієнта. Специфікою архітектури клієнт-сервер є використовування мови запитів SQL (Structured Query Language).
Нормалізація - це розбиття таблиці на дві або більш, володіючих кращими властивостями при додаванні, зміні і видаленні даних.Остаточна мета нормалізації зводиться до отримання такого проекту бази даних, в якому кожен факт з'являється лише в одному місці, тобто виключена надмірність інформації. Це робиться не стільки з метою економії пам'яті, скільки для виключення можливої суперечності даних, що зберігаються.
Індексація даних
Як вже наголошувалося, стандартним прийомом підвищення ефективності доступу до записів в базах даних є створення індексних масивів по окремих, звичайно ключових полях. Ідея індексів заснована на тому факті, що якщо для підвищення ефективності доступу до конкретного кортежу-запису використовувати лінійне впорядкування кортежів в таблиці (скажімо, за абеткою для текстових ключових полів або за збільшенням для числових ключових полів), то накладні витрати по «перетрушуванню» всієї таблиці після додавання/видалення рядків-кортежів перевищать виграш в часі доступу. Структура індексів (індексних масивів) будується так, щоб на основі деякого критерію можна було б швидко знаходити по значенню поля, що індексується, покажчик на потрібний запис (рядок) таблиці і діставати до неї доступ. При цьому сукупність записів-кортежів базової таблиці не обов'язково упорядковувати, а при їх зміні необхідно змінити тільки індексний масив.
Як і для інформаційних масивів самих даних (таблиць), так і для індексних масивів застосовуються лінійні і нелінійні структури. Як лінійні структури індексів в більшості випадків виступають інвертовані списки. Інвертований список будується за схемою таблиці з двома колонками - «Значення поля», що індексується, і «Номера строк»* (див. мал. 2.16). Інвертовані списки найчастіше застосовуються для індексації полів, значення яких в різних рядках-записах можуть повторюватися, наприклад, поле «Рік народження» таблиці «Співробітники» (у реляційних базах даних такі поля не можуть бути ключовими).
Значение индексируемого поля ("Год рождения") |
Номера, строк |
1958 |
3 |
1959 |
5, 17, 123, 256 |
1960 |
31, 32, 77 |
1961 |
11, 45, 58, 167, 231 |
1962 |
7, 8, 9, 10, 234, 235, 236 |
Рис. 2.16. Пример инвертированного списка
Рядки інвертованого списку упорядковуються по значенню поля, що індексується. Для доступу до потрібного рядка початкової таблиці спочатку у впорядкованому інвертованому списку відшукується рядок з необхідним значенням поля,* потім прочитується номер відповідного рядка (рядків) в початковій таблиці і далі по йому вже здійснюється безпосередній доступ до шуканого рядка базової таблиці.
При додаванні нового рядка в базову таблицю її значення по полю, що індексується, шукається в раніше складеному індексі. Якщо відповідний рядок інвертованого списку відшукується (тобто подібне значення поля, що індексується, серед рядків таблиці вже зустрічалося і було поставлене на облік), то в осередок другого стовпця відповідного рядка індексу дописується номер сторінки, куди був поміщений відповідний рядок базової таблиці. Якщо такого значення в індексі немає, то створюється новий рядок індексу і здійснюється переупорядковування нового стану індексного масиву.
При видаленні рядка з базової таблиці також здійснюється пошук відповідного рядка в індексному масиві і здійснюється викреслювання в індексі відповідного номера посилаємого рядка базової таблиці. Якщо при цьому інших рядків в базовій таблиці з таким же значенням поля, що індексується, не залишилося (відповідний осередок індексу став порожнім), то віддаляється і весь даний рядок індексу з подальшим перевпорядковуванням всього індексного масиву. При цьому за рахунок того, що індекс у вигляді інвертованого списку містить лише один стовпець значень, витрати на «перетрушування» при додаванні або видаленні записів істотно менше в порівнянні з тим, якби перевпорядковування відбувалося безпосередньо в самій базовій таблиці
Самостійна робота №2
Тема: Проектування концептуальної моделі даних.
Мета: ознайомитися з питаннями, пов’язаними зі проектуванням концептуальної моделі даних.
Форма роботи: вивчення теоретичного матеріалу.
План:
Важливість розробки концептуальної моделі даних.
Аналіз даних, збір даних.
Вимоги до збору даних.
Положення теорії нормалізації відносин.
Графічне представлення концептуальної моделі.
Основна література: