

Определение нфбк и приведение к нфбк.
Таблица находится в НФ Бойса-Кодда (НФБК) тогда и только тогда, когда любая функциональная зависимость между полями сводится к полной функциональной зависимости от возможного ключа.
В соответствии с этим таблицы Блюда и Продукты, имеющие по паре возможных ключей (№ блюда, блюдо, № продукта, продукт) находятся в НФБК или в 3НФ.

-
№ зач.
ФИО
№ темы реферата
Тема
X → Y, Y → Z X→ Z
Решение этой проблемы заключается в разбиении этой таблицы на две - № зач., Фамилия; № темы, тема.
НФБК
R с зависимостью F находится в НФБК, если всякий раз, когда в R имеет место X → A, XX, X включает ключ R.
То есть допускаются зависимости, в которых ключевые функции определяют один или более других атрибутов.
№33) Определение 4НФ и приведение к 4НФ.
В следующих НФ (4 и 5) учитываются не только функциональные многозначные связи между полями таблицы. Полная декомпозиция таблицы – это совокупность любого числа ее проекций, соединение которых полностью совпадает с содержимым таблицы.
Таблицы находится в 5НФ тогда и только тогда, когда в каждой ее полной декомпозиции все проекции содержат возможный ключ.
Таблица не имеющая ни одной полной декомпозиции также находится в 5НФ.
4 НФ
является частным случаем 5НФ. Когда
полная декомпозиция должна быть
соединением двух проекций. Очень важно
подобрать реальную таблицу, которая
находится в 4НФ, но не была бы в 5НФ.
НФ
является частным случаем 5НФ. Когда
полная декомпозиция должна быть
соединением двух проекций. Очень важно
подобрать реальную таблицу, которая
находится в 4НФ, но не была бы в 5НФ.
№34) Языки манипулирования данными (ЯМД). Реляционная алгебра (РА).
Конкретный язык манипулирования РБД называется реляционно-полным.
Если любой запрос, выражаемый с помощью одного выражения РА или одной формулы РИ может быть представлен с помощью одного оператора этого языка.
Механизмы РА и РИ эквивалентны, то есть для любого допустимого выражения РА можно построить производящую такое же результат формулу РИ и наоборот.
Различаются оба этих механизма уровнем процедурности. Выражение РА строится на базе алгебраических операций (высокого уровня) и имеют процедурную интерпретацию, то есть запрос на языке реляционной алгебры может быть вычислен на основе алгебраич. операций с учетом старшинства и скобок.
Формула РИ не может быть однозначно трактована, она устанавливает условие, в котором должны удовлетворять кортежи обр. языки РИ декларированы и менее процедурны.
Редко алгебра или исчисление принимаются в качестве полной основы языка БД (SQL).
Расширенный начальный вариант алгебры представлен Коддом.
Набор алгебраических операций состоит из 8, которые делятся на 2 класса:
теоретико-множественные (1)
специальные (2)
В состав (1) входит:
объединение отношений
пересечение отношений
взятие разности отношений
прямое произведение отношений
В состав (2) входит:
ограничение отношений
проекция отношений
соединение отношений
деление отношений
В состав алгебры включается операция присваивания (позволяется сохранить в БД результаты вычисления).
Операция переименования атрибутов (дает возможность корректно сформировать заголовок или схема результата).
Общая интерпретация реляционных операций
При выполнении операции объединения двух отношений производится отношение, включающее в себя все кортежи, входящие хотя бы в одно из отношений операндов.
Операция пересечения двух отношений производит отношение, включающее все кортежи, входящие в оба отношения операнда.
Отношение, являющееся разностью двух отношений включает все кортежи, входящие в отношение 1 операнд такие, что ни один из них не входит в отношение 2 операнда.
При выполнении прямого произведения двух отношений производится отношение, кортежи которого являются конкатенацией (сцеплением) кортежей 1 и 2 операндов.
Результатом ограничения отношения по некоторому условию является отношение, включающее кортежи отношения операнда удовлетворяющие этому условию.
При выполнении проекции отношения на заданный набор атрибутов производится отношение, кортежи которого производятся путем взятия соответствующих значений из кортежей отношения операнда.
При соединении двух отношений по некоторому условию образуется отношение, кортежи которого являются конкатенацией кортежей 1 и 2 отношения и удовлетворяющих условию.
У операции реляционного деления два операнда: бинарное и унарное отношение. Результат состоит из одноатрибутных кортежей, включающих значение 1 атрибута кортежей 1-го операнда таких, что множество значений 2-го атрибута совпадает с множеством значений 2-го операнда.
Операция переименования производит отношение, тело которого совпадает с телом операнда, но имена атрибутов изменены.
Операция присваивания позволяет сохранить результат вычисления реляционного выражения существующим отношением БД.
№35) Определение реляционного исчисления (РИ).
Реляционное исчисление
Пример: БД с отношениями:
СОТРУДНИКИ (№, имя, зарплата, отдел)
ОТДЕЛЫ (№_отдела, количество, начальник)
Запрос: выбрать имена сотрудников, являющиеся начальниками отделов с количеством сотрудников более 50.
Средства РА:
Соединение отношения СОТРУДНИКИ и ОТДЕЛЫ по условию N, начальник.
Ограничить полученное отношение по условию количество больше 50.
Проекция результатов предыдущей операции на атрибут имя, N.
В реляционном исчислении (РИ): выдать имена и номера такие, что существует отдел с таким же значением поля начальник и значением количество больше 50.
В РИ указываются характеристики результатов без указания способа его формирования. Система сама решает какие операции и в каком порядке будут выполняться.
Кортежные переменные
Базисными понятиями РИ являются:
Понятие переменной с определенной для нее ОДЗ.
Понятие правильно построенной формулы, опирающейся на переменные, предикаты и кванторы. В зависимости от определения переменной различаются
Исчисление кортежей (областями определения переменных является кортеж некоторого отношения)
Исчисление доменов (областью определения являются домены, но которых определены атрибуты отношений БД, то есть допустимым значением переменной является значение домена)
Реляционное исчисление с переменными кортежами
Формулы в РИ имеют вид {t/ (t)}, где t - , (t) – формула построенная из атомов и операторов.
Атомы в РИ бывают:
R(t), где R – имя отношения, t – переменная (кортеж)
S[i] u[j], где
S, u – переменные кортежей
i, j – номер атрибутов кортежей
- арифметический оператор сравнения. = {=, <, >, ≤, ≥, ≠}
i-я компонента отношения S находится в соотношении с j-ой компонентой отношения u.
S[i] a, a S[i], a – const
Введем понятия свободных и связанных переменных.
Вхождение переменной в формулу является связанным, если этой переменной предшествует квантор, в противном случае переменная является свободной.
Кванторы играют роль деклараций. Квантор – утверждение, относящееся к объекту.(, )
Определение свободных и связанных переменных аналогично глобальным и локальным переменным. Формулы, свободные и связанные переменные определения кортежей можно определить:
Каждый атом есть формула. Все вхождения переменной кортежа, упомянутые в атоме являются свободными в этой формуле.
Если
 - формулы, то формулы и
- формулы, то формулы и
а)

б)

в)

Экземпляры переменных кортежей являются свободными или связанными в формулах (а) – (с). В зависимости от того. Связанные они или свободны в одной из этих формул.
Если
 - формула, то квантор (S)
- формула. S связана во
всей формуле. Значение этой формулы:
существует значение S,
при подстановке которого вместо всех
вхождений S в формулу
она
становится истиной.
- формула, то квантор (S)
- формула. S связана во
всей формуле. Значение этой формулы:
существует значение S,
при подстановке которого вместо всех
вхождений S в формулу
она
становится истиной.Если - формула, то формула-квантор (S) тоже формула со значением для всех S истинна .
Формулы могут при необходимости заключаться в скобки. Имеется ранжирование операторов. Преимуществом пользуются арифметические, сравнения, кванторы, отрицание, дизъюнкция, конъюнкция.
Ничто иное не является формулой.
Формулы РИ:
Объединение RS {t/R(t) S(t)}
Разность R – S { t/R(t)
 S(t)}
S(t)}Произведение (tk) {t(r+s)/( u(r))( v(S)) (R(u)S(v) t[1] = u[1] …t[r] = u[r] t[r+1] = v[1] …t[r+S] = v[S])}
Т.о. выражения РИ с переменными кортежами
есть выражения вида {t/ },
где t – единственная
свободная переменная кортеж в
.
},
где t – единственная
свободная переменная кортеж в
.
Реляционное исчисление с переменными на доменах
Строится на тех же операторах.
Различия состоят:
Вместо переменных кортежей в качество переменной выступает домен.
Атомы имеют вид R(х1, х2,…, хк), где хi – const или переменная на домене. Значения тех хi, которые являются переменными должны быть выбраны таким образом, чтобы эта совокупность х была кортежем отношения.
Формулы в РИ с переменными на доменах используют связки
 ,
кванторы, сущ. понятия свободных и
связанных переменных.
,
кванторы, сущ. понятия свободных и
связанных переменных.
Общие выражения с переменной на доменах имеет вид:
 ,
где
,
где
 - множество из доменов, удовлетворяющих
формуле
.
- множество из доменов, удовлетворяющих
формуле
.
Теорема 1: если G есть формула РА, то существует эквивалентное ей выражение с переменными корежами.
Теорема 2: для каждого выражения реляционного счисления с переменными кортежами существует эквивалентное ему выражение РИ с переменными на доменах.
Теорема 3: для всякого выражения РИ с переменными на доменах существует выражение РА.

!!!№36) Соответствие операций реляционной алгебры выражениям реляционного исчисления.
Два выражения в РА являются эквивалентными
(или
 ),
если представляют одно и тоже отображение,
то есть при подстановке конкретных
значений в выражение E1,
E2 получается один
и тот же результат.
),
если представляют одно и тоже отображение,
то есть при подстановке конкретных
значений в выражение E1,
E2 получается один
и тот же результат.
Законы эквивалентных преобразований:
закон коммутативности для соединения и произведения

F – условное соединение.
закон ассоциативности



каскад проекций

каскад селекций

перестановка селекции и проекции

перестановка селекции и декартова произведения

Следствия:
если F представляется как формула
 ,
то можно записать
,
то можно записать


Перестановка селекции и объединения

Примечание: объединение E1 и Е2 должно иметь одинаковые атрибуты Ai = Aj или указано соответствие атрибутов
Перестановка селекции и разности
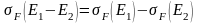
Перестановка проекции и декартова произведения

Перестановка проекции и объединения

В 10 примечания такие же как и в 7, 8.
№37) Языки запросов. Дополнительные возможности ЯМД.
Команды включения, замены
Арифметические операции
Возможные команды присвоения и печати (допускается печать отношения, кот. сконструирована с помощью либо РА либо РИ)
Агрегатные функции
Полным называется язык, в котором моно моделировать отношения с переменными на кортежах или на доменах, либо на базе РА.
Язык, не удовлетворяющий этим условиям, не является полным.
№38) Сравнение алгебраических языков и языков исчисления.
Принято считать, что языки РИ являются языками более высокого уровня, чем языки РА (РА определяет какие операции нужно выполнять, а РИ – предоставляет определить порядок вычислений компилятору).
R (A, B)
S (B, C)
Значение С ассоциированные со значением A = a0 в отношении с атрибутами A, B, C получ. в результате соединений A и B.
Для РА эта фраза:

В исчислении с переменными на доменах:

Преимущество языков РИ относительно, т.к. можно разработать блок оптимизации запросов для языков, основанных на РА. В основном языки базируются на РИ. Наибольшее распространение получили языки смешанного типа.
№39) Общие стратегии оптимизации запросов. Эквивалентность и преобразования выражений.
Временные затраты при выполнении запросов наиболее заметны на операциях соединения, декартово произведения.
R

R 2
(A2,
A3)
2
(A2,
A3)
Если
R2
<<m 
R1 <<n
Общая стратегия оптимизации:
Выполнять операцию селекции по возможности раньше. Это приводит к сокращению промежуточных результатов и как следствие – повышение быстродействия.
Целесообразно обрабатывать файлы перед выполнением операции декартова произведения или соединения. Предварительная обработка заключается в сортировке файла и определении индексов с целью ассоциации одинаковых элементом в каждом из файлов.
Поиск общих подвыражений выражения. Если результат выполнения какого-либо выражения является небольшим, то можно запомнить, а в дальнейшем используется для вычисления других выражений (не всегда применяется).
Сбор в каскады, селекция и проекция. Так как данные операции для 1-го операнда могут выполняться за один просмотр.
Комбинация проекции с предшествующими и последующими двухместными операциями.
Комбинация селекции с предшествующим декартовым произведениями и выполнение этой операции вместо соединения.
Два выражения в РА являются эквивалентными (или ), если представляют одно и тоже отображение, то есть при подстановке конкретных значений в выражение E1, E2 получается один и тот же результат.
Законы эквивалентных преобразований:
закон коммутативности для соединения и произведения
F – условное соединение.
закон ассоциативности
каскад проекций
каскад селекций
перестановка селекции и проекции
перестановка селекции и декартова произведения
Следствия:
если F представляется как формула , то можно записать
Перестановка селекции и объединения
Примечание: объединение E1 и Е2 должно иметь одинаковые атрибуты Ai = Aj или указано соответствие атрибутов
Перестановка селекции и разности
Перестановка проекции и декартова произведения
Перестановка проекции и объединения
В 10 примечания такие же как и в 7, 8.
№40) Понятие свертки. Минимизация конъюнктивных запросов.
Алгебраические способы и декомпозиции, рассмотренные ранее для преобразования запросов дают запросы, которые могут быть обработаны более эффективно. Указанные способы не определяют показатель эффективности обработки запросов.
Проблема нахождения оценки критериев оценки для большинства запросов неразрешима.
Существует класс запросов: конъюнктивные запросы для которых есть методы, обеспечивающие точную оптимизацию.
Критерием является количество соединений и произведений.
Конъюнктивные запросы
Вычисления с переменными на доменах имеют вид:

а – переменные или const
b – переменные
c – const
имеет
вид:


Пример: найти читателей, которые берут книги, опубликованные в городе, в котором они живут.
 m=9
m=9
b1,…,b9 – атрибуты во всех отношениях
a1 – ФИО.
Пример 2: найти названия всех книг, выданных по карте №13 и дату их выдачи.

a1, a2 – название книги и дата выдачи.
Конъюнктивные запросы эквивалентны тогда, когда существует двойное отношение «содержится».

Отношение «содержится», когда имеется свертка.

Свертка имеет место в том случае, если есть отображение f-символов запросов Q1 в символы запроса Q2. Для f существует зависимости:
1.

2.

3.

4.

 можно представить
в виде совокупности d1,
d2,…,
dk
тогда имеет место формула:
можно представить
в виде совокупности d1,
d2,…,
dk
тогда имеет место формула:

Теорема 9. Теорема о свертках.

Минимизация конъюнктивных запросов
Теорема 10. Для любого КЗ Q существует КЗ Q0 с наименьшим возможным числом входящих элементов. Любой другой запрос Q0 эквивалентен Q. Имеет min число составляющих (термов) и содержит какие-либо квантируемые переменные наз. взаимоодназным переименованием символов Q0.
Следствие:
Для любого заданного КЗ Q можно найти эквивалент с min числом термов путем удаления из него термов и всех кванторов существования таких, что bi не используется ни в одном из термов.
Пример: дан запрос:

Минимизация запроса:
2, 3, 4 удалять нельзя, так как в них присутствуют константы и переменные а1, а2. Возможно удалить 1, так как b1 и b3 нигде больше не используются, то есть не встречаются в других термах, следовательно нужно удалять их кванторы.

№41) Сетевая модель данных. Записи и наборы в КОДАСИЛ. Достоинства и недостатки сетевой модели.
Язык Codasyl (первая версия 1969 г.) был предназначен для описания сетевых структур данных. Находился в разработке до 80-х годов.
На его базе были созданы ЯОД и ЯМД.
Рассчитан на пользователей, программистов и рассматривается как набор средств и методов для хранения данных. Поэтому для него не существует строгой математической модели описания данных. Большинство больших БД разрабатывалось на этом языке.
Основная идея языка: использование наборов. Он отражается связи 1:М. В наборе выделяется владелец и член набора. Реализация наборов осуществляется с использование связанных списков, рассматриваются функции связи членов с владельцами и наоборот.
Записи CODASYL
Тип представляет собой множество записей, обладающих структурой и другими свойствами, которые специфицированных в данном типе записей.
Со структурной точки зрения представляет собой иерархию, образованную из простейших элементов данных, простых групп таких элементов и повторяющихся групп.
Для повторяющихся групп допускается переменное число повторений и вложенность. В записи могут содержаться произвольные элементы данных, а также производные, которые зависят от значений других переменных (элементы той же записи, элементы записей владельца наборы и т.д.).

Наборы CODASYL
Если существует отображение m:1 записи типа R2, R1, то запись m(S)=r говорит о том, что кортеж S отношения записи R2 является членом набора, владельцем которого является запись r типа R1. Множество всех записей членов набора S, владельцем которого является r и саму r наз. экземпляром набора.
В CODASYL существуют ограничения:
Тип записей. Запись не может быть одновременно владельцем и членом одного и того же набора. Чтобы обойти это ограничение вводятся фиктивные наборы.

Поставщик
ФИО |
Адрес |
Дата рождения |
||
|
|
ч |
м |
г |

Т
Пост_цена
овар-
Назв_товара
Ц ена
ена
ФИО |
Назв_товара |
ц товар_цена ена |
Record Поставщик
1 ФИО char (20)
1 Адрес char (20)
1 Дата_рожд
2 число int (20)
2 м int (20)
2 г int (8)
record Товар
1 назв char (20)
record Цена
ФИО virtual source is Поставщик
ФИО of owner of Поставщик_цена
1 назв_товара virtual source is товар
назв_товара of owner of товар_цена
1 цена int(10)
Наборы SET
Set Пост_цена
owner is Поставщик
member is Цена
set Товар_цена
owner is Товар
member is цена
Для данного типа записи можно определить понятие сингулярного запроса, который обладает двумя свойствами:
типом записи владельца такого набора является специальным тип записи SYSTEM
имеется в точности один экземпляр набора, а все записи данного типа являются членами этого набора. Эти записи автоматически становятся членами набора без специальных указателей.
-
S
 YSTEM
YSTEMПоставщик
Все поставщики
Set все поставщики owner is SYSTEM member поставщик
Древовидные структуры
Тип набора может содержать несколько типов записей. В этом случае набор представляет собой дерево.

Любое n-уровневое дерево может представлять n-1 набор. В этом дереве все, кроме 1-ой и последней записи иные записи могут быть членами и владельцами различных наборов.
Т ри
уровня и два набора.
ри
уровня и два набора.
Достоинства и недостатки
Достоинства:
эффективное обновление и доступ к большим БД
обеспечение разумной скорости при выполнении операций соединения на большом количестве записей
Недостатки:
отсутствие полного языка запросов высокого уровня
нет математического обеспечения аналогичного реляционной алгебре
№42) Иерархическая система на примере DL1.
В отличие от языка CODASYL основной структурой языка DL1 является дерево сегментов.
DL1 был разработан лоя работы с большими БД. Этот язык используется для логического описания БД и для физического.
Физическая БД размещается на носителе в виде дерева. Доступ к данным осуществляется одним из 4-х способов.
Иерархично-последовательностный
индексно-последовательностный
прямой
индексно-прямой
Деревья, в которых используются два первых метода доступа располагаются последовательно, для последних методов используется хэширование (хэш-функции).
На первом уровне могут располагаться несколько типов сегментов, а БД может состоять из нескольких физических деревьев.
Представление сетевых структур в DL1
Существует возможность представить простую и сложную сетевую структуру.
С ложная
сетевая структура:
ложная
сетевая структура:
Введение указателя преобразует сложную сетевую структуры в древовидную
О писание
БД в DL1
писание
БД в DL1
Определение БД
DB NAME = <имя БД> {ACCESS=метод доступа> | LOGICAL}
Описание сегмента
SEGM MANE=<имя сегмента> PARENT = <имя исходного сегмента>
Операторы
DB DGEN
FINISH
END
№43) Физическая организация баз данных (ФБД). Классификация БД.
Логическая БД в DL1 имеет следующую структуру:
З апись
в логической БД определяется как
иерархически связанная совокупность
сегментов. В целом лог. БД – это
совокупность лог. записей. Запись в DL1
соответствует набору в CODASYL.
апись
в логической БД определяется как
иерархически связанная совокупность
сегментов. В целом лог. БД – это
совокупность лог. записей. Запись в DL1
соответствует набору в CODASYL.
Сегмент – это поименованная единица данных, которая содержит одно или несколько полей.
Поле – это мин. поименованный элемент данных.
Существуют лог. БД, которая сконструирована из одной или нескольких физических БД.
Схема физической БД – это дерево типов логических записей.
Описание физической БД включает:
имена сегментов
имена их полей
информация об образуемой сегментами иерархической структуре
спецификация физической организации доступа (метод доступа)
В DL1 физической БД соответствует КМД в РБД, логическая БД соответствует понятиям внешней модели. Поэтому на основе физической структуру можно построить несколько логических БД целиком. Для этих целей используются указатели на соответствующие сегменты.
Пример: есть физическая БД, которая включает две древовидные структуры.
Каталог работ


№44) ФБД. Хешированные файлы. Индексированные Файлы. Инвертированные файлы.
Хэш-файлы разделяются на участки. Участок содержит один или несколько блоков. Используется хэш-функция h(v), где v – ключ записи. Функция определяется номером блока участка и адресом участка. Говорят, что хэш-функция хэширует файл, если принимает все значения номеров участков с равной вероятностью. Используется множество алгоритмов вычисления h(v). Рассмотрим следующие:
интерпретирующее значение ключа как последовательность битов, сформированных путем конкатенации всех полей ключа. Эта последовательность имеет фиксированную длину, так как всякое поле имеет фиксированную длину.
делится последовательность битов на группы, которые состоят из фиксированного числа битов. Последнюю группу при необходимость дополняет ноль.
производится сложение группы битов как целых чисел
д
b2
 елим
сумму на число участков. Остаток от
деления будет номером
участка.
елим
сумму на число участков. Остаток от
деления будет номером
участка.
-

b7
b6
b1
b3
b5
Участки все связаны с указателями. Последний блок содержит нулевой указатель. Справочник участка содержит адреса первых блоков участка. Записи в блоках распределяются последовательно. Пространство, необходимое для хранения записи называется субблоком. В начале каждого блока имеется по 1 биту на любой субблок для указателя свободен он или занят.
Индексированный файл
Файл сортируется по значению ключа. Ключ представляет собой строку бит фиксированной длины. При упорядочивании, если ключ целое или фиксированное число рассматривается числовой порядок. Если ключ состоит из нескольких полей, то упорядочивание происходит последовательно по полям. Для ускорения поиска по ключу используется индексированный файл. Исходный файл разделяют на блоки, а файл индексов включает в себя пару (v, b), где v – ключ первой записи в блоке, b – указатель. Разряженный файл сортируется по значению ключа. Для некоторых организаций файл индексов не изменяется.
№45) ФБД. В-деревья. Поиск по не ключевым атрибутам.
В-деревья
Наиболее распространенный подход к организации индексов БД – это техника В-деревьев.
В-дерево – это сбалансированное сильноветвистое дерево во внешней памяти.
Сбалансированность – длина путь от корня дерева к любому его листу одинакова.
Ветвистость – свойство каждого узла дерева ссылаться на большое число узлов потомков.
Ф изическая
организация дерева – это мультисписочная
структура, состоящая из страниц внешней
памяти, то есть каждому узлу соответствует
блок или страниц во внешней памяти.
Внутренние и листовые страницы имеет
разную структуру.
изическая
организация дерева – это мультисписочная
структура, состоящая из страниц внешней
памяти, то есть каждому узлу соответствует
блок или страниц во внешней памяти.
Внутренние и листовые страницы имеет
разную структуру.
Структура внутренней страницы:

При этом имеют место следующие свойства:

Структура листовой страницы:

Все ключи обладают свойствами:

листовые страницы связаны одно- или двунаправленными списком.
Поиск в В-дереве – это прохождение от корня к листу в соответствии с заданным значением ключа. Так как деревья сильно ветвистые и сбалансированные, то для выполнения поиска по любому значению ключа требуется небольшое число обменов с внешней памятью.
Достоинством В-дерева является автоматическое поддержание сбалансированности.
Пример для операции занесения записи:
Поиск листовой страницы (обычный поиск по ключу)
если в В-дереве не содержится ключ с заданными значением, то будет получен номер страницы, где он должен содержаться и ее координаты.
помещение записи на место (буфер ОП). Листовая страница, в которую будет помещена запись, считывается в буфер, осуществляется операция вставки, при этом размер буфера должен превышать размер страницы внешней памяти.
если размер буфера не превосходит размер страницы, то операция затем заканчивается. Буфер может быть вытолкнут во внешнюю память, либо временно сохранен в ОП.
При переполнении буфера выполняется расщепление страницы. Запрашивается новая страница. Используемая часть буфера делится пополам и переписывается во вновь выделенную страницу. В старой странице модифицируются размеры свободной памяти и модифицируются ссылки на страницы.
Для обеспечения доступа от корня к вновь заведенной странице модифицируется внутренняя страница, которая является предком ранее существовавшей, то есть в нее помещается значение ключа и ссылки на новую страницу.
Возможно переполнение внутренней страницы и она также расщепляется на две.
Предельным случаем является переполнение корневой страницы. При расщеплении заводится новая корневая и его глубина увеличивается на 1.
При выполнении операции вставки и удаления свойство сбалансированности сохраняется, а внешняя память расходуется экономно.
При выполнении модификации часто возникают расщепления и слияния. Эффективное использование внешней памяти достигается:
упреждающее расщепление, то есть расщепляются страницы не при переполнении, а раньше.
-
S1

переименование, то есть поддержание равновесного состояния соседних страниц.
Si+1 |
|
-
S
i-1




Si

Организация мультидоступа к В-деревьям
Является сложной задачей. Решение:
монопольный захват В-дерева на всю операцию модификации. В*, В+.
индексы В-деревьев.
№46) Транзакции. Откат транзакции. Журнализация в БД. Параллельные операции над БД.
Транзакция – последовательность операций над БД, которая рассматривает СУБД как единое целое. Либо транзакция успешно выполняется и СУБД фиксирует это, либо ни одно из изменений не отражается на БД. Понятие транзакции введено для определения логической целостности БД. Пример: ИС сотрудники – отделы. Единственным способом не нарушить целостность БД при выполнении операции приема на работу нового сотрудника – это объединение операций над файлом сотрудники и файлом отделы в одну транзакцию, то есть механизм транзакции обязателен даже для однопользовательских СУБД.
Управление транзакциями в многопользовательских СУБД основывается на понятии сериализации транзакций и сериального плана выполнения транзакций. Под сериализацией параллельно выполняемых транзакций понимается порядок планирования их работы, при котором сумма эффекта смеси транзакций эквивалентна эффекту их последовательного выполнения.
Сериальный план выполнения транзакций – это план, приводящий к их сериализации. Если удается добиться сериализации выполнения смеси транзакций, то для каждого пользователя прервавшего транзакцию или образовавшего новую транзакцию присутствие других транзакций будет незаметно.
Существует ряд алгоритмов сериализации. В централизованных СУБД – это алгоритмы, которые основаны на синхронных захватах объектов БД.
В любом алгоритме возможны ситуации конфликтов транзакций при доступе к объектам (используется откат транзакций).
Журнализация
Основным требованием к СУБД является надежность хранения. Надежность – это возможность восстановления последнего согласованного состояния БД после любого аппаратного или программного сбоя. К аппаратным сбоям относятся:
мягкие сбои (внезапная остановка в связи с отключением питания);
жесткие – полная потеря информации на носителях внешней памяти.
Программные сбои – аварийные завершения работы СУБД по причине ошибки в программе или аппаратного сбоя.
Аварийное завершение пользовательской программы в результате чего транзакция остается незавершенной.
Для восстановления БД в любом случае требуется дополнительная информация, то есть обеспечение надежности требует избыточного хранения, причем дублирование информации БД должно обеспечиваться приоритетным доступом.

-
БД
Журнал изменений БД.
Журнал – это особая часть БД, недоступная пользователям СУБД и поддерживаемая в нескольких копиях на различных носителях, в которую поступает записи обо всех изменениях основной части БД.
В разных СУБД журнализация ведется на разных уровнях:
запись в журнале соответствует операции логического изменения БД.
запись в журнале соответствует min внутренней операции модификации страницы внешней памяти.
совмещение 1 и 2.
Во всех случаях поддерживается операция упреждающей записи в журнал WAL-протокол. Эта стратегия заключается в том, что запись об изменении объекта БД попадает во внешнюю память журнала раньше, чем измененный объект попадет во внешнюю память основной части БД. При использовании WAL-протокола во всех случаях решаются проблемы любого сбоя.
Самая простая ситуация восстановления – индивидуальный откат транзакций (для этого общесистемный журнал не требуется), для каждой транзакции поддерживается собственный журнал операций модификации. Откат производится путем проведения обратных операций до конца локального журнала.
В большинстве СУБД локальный журнал не поддерживается, а откат транзакции проводится по общесистемному журналу. В этом случае все записи от одной транзакции связывают обратным списком.
При мягком сбое во внешней памяти могут находиться объекты модификации транзакции, но не законченные к моменту сбоя и могут отсутствовать объекты модифицируемые транзакциями, которые к моменту сбоя завершились (по причине использования буфера ОП, содержимое которого при мягком сбое пропадает). В этом случае используется WAL-протокол.
Целью процесса восстановления после мягкого сбоя является состояние внешней памяти, основной части БД, которое возникло бы при фиксации во внешней памяти изменений всех завершившихся транзакций и не содержало бы следов незаконченных транзакций
№47) Клиент-серверные системы. Общая структура, функции.
Архитектура клиент-сервер (КС)
Архитектура КС обеспечивает простое и дешевое решения проблемы коллективного доступа как к БД в локальной сети, так и для других целей.
Системы БД, основанные на архитектуре КС является приближением к распределенным системам БД.
Клиенты и серверы локальных сетей
В основе распределения локальных сетей лежит идея разделения ресурсов. Функциональное разделение компонентов состоит в:
Доступ к ресурсам удаленного компьютера
Возможность получения от этого компьютера определенного сервиса (сервис специфичен для конкретной системы и его программные средства нецелесообразно дублировать в нескольких узлах)
Функциональное разделение приводит к различиям узлов системы, следовательно, выделения сервера и рабочих станций локальных сетей.
Рабочая станция предназначена для непосредственной работы пользователя или определенной категории пользователя и соответствующей локальной потребности пользователя.
Особенности рабочей станции (РС):
Объем ОП
Наличие и объем дисковой памяти (достаточно популярны бездисковые РС, использующие дисковую память сервера)
Характеристики процессора и монитора
Сервер локальной сети должен обладать ресурсами соответствующими его функциональному назначению и потребностям самой сети. В связи с ориентацией на открытые системы говорят о логических серверах (набор ресурсов и программных средств, обеспечивающие услуги над этим ресурсами).Логические серверы не обязательно располагаются на разных компьютерах.Особенностью логического сервера является то, что если сервер поместить на отбельный компьютер, то это можно без модификации его самого и прикладных программ.
Примеры серверов:
Сервер телекоммуникаций, который обеспечивает услуги локальной сети с внешним миром.
Вычислительный сервер, который дает возможность производить сложные вычисления, которые не под силу выполнить РС.
Дисковый сервер, который обладает расширенными ресурсами внешней памяти и предоставляет их для использования РС и другими серверами.
Файловый сервер – поддерживает общее хранилище файлов для всех РС.
Сервер БД (СУБД) – принимающий запросы по локальной сети и возвращающий результаты.
Клиент локальной сети, запрашивающий услуги у некоторого сервера и сервер – это компоненты локальной сети, принимающей запросы на услуги, осуществляемые в отношении клиента.
Клиент-серверная
организация обработки данных
№48) Серверы СУБД. Проблема выбора аппаратно-программной платформы и конфигурации сервера БД.
Появление в 80-х годах персональных компьютеров (ПК) и локальных сетей ПК самым серьезным образом изменило организацию корпоративных вычислений. Однако и сегодня освоение сетевых вычислений в масштабе предприятия и Internet продолжает оставаться не простой задачей. В отличие от традиционной, хорошо управляемой и безопасной среды вычислений предприятия, построенной на базе универсальной вычислительной машины (мейнфрейм) с подсоединенными к ней терминалами, среда локальных сетей ПК плохо контролируется, плохо управляется и небезопасна. С другой стороны, расширенные средства сетевой организации делают возможным разделение бизнес-информации внутри групп индивидуальных пользователей и между ними, внутри и вне корпорации и облегчают организацию информационных процессов в масштабе предприятия. Чтобы ликвидировать брешь между отдельными локальными сетями ПК и традиционными средствами вычислений, а также для организации распределенных вычислений в масштабе предприятия появилась модель вычислений на базе рабочих групп.
Как правило, термины серверы рабочих групп и сетевые серверы используются взаимозаменяемо. Сервер рабочей группы может быть сервером, построенным на одном процессоре компании Intel, или суперсервером (с несколькими ЦП), подобным изделиям компаний Compaq, HP, IBM и DEC, работающим под управлением операционной системы Windows NT. Это может быть также UNIX-сервер начального уровня компаний Sun, HP, IBM и DEC.
По мере постепенного вовлечения локальных сетей в процесс создания корпоративной вычислительной среды, требования к серверам рабочих групп начинают включать в себя требования, предъявляемые к серверам масштаба предприятия. Для этого прежде всего требуется более мощная сетевая операционная система. Таким образом, в настоящее время между поставщиками UNIX-систем, а также систем на базе Windows NT, увеличивается реальная конкуренция.
Рынок северов локальных сетей/рабочих групп представляет собой быстро растущий сегмент рынка. В период 1995-1996 годов мировой рынок серверов локальных сетей вырос на 32% по количеству поставок и на 39% по прибыли. Аналитическая компания IDC считает, что в период 1995-2000 года ежегодные темпы роста в этом секторе рынка будут составлять 16.1% по числу поставок и 16.9% - по прибыли. При этом IDC прогнозирует ежегодные темпы роста количества поставок мало масштабируемых UNIX-систем в 13%, а темпы роста количества поставок UNIX ПК в 8.9%.
Рынок серверов рабочих групп по их функциональному назначению может быть поделен на две основные части: с одной стороны это файл-серверы и принт-серверы, а с другой - серверы приложений. Из этих двух частей рынка серверов рабочих групп подавляющее большинство поставленных в прошлом систем составляют файл-серверы (в мировом масштабе 71% в 1995 году), но область серверов приложений представляет собой огромный потенциал для роста в будущем. В 1995 году количество поставок серверов приложений составило 29% от общего числа поставленных в мире сетевых серверов, причем большинство этих серверов использовались в качестве серверов баз данных. IDC прогнозирует рост доли этого типа серверов до 42% к 2000 году. Доля файл-серверов сократится до 58%.
Серверы приложений для рабочих групп могут поддерживать следующие типы приложений:
Приложения рабочих групп - календарь, расписание, поток работ, управление документами.
Средства организации совместных работ - Lotus notes, электронные конференции.
Прикладные сервисы для приложений клиент/сервер.
Коммуникационные серверы (удаленный доступ и маршрутизация).
Internet.
Доступ к распределенной информации/данным.
Традиционные сервисы локальных сетей - разделение файлов/принтеров.
Управление системой/дистанционное управление.
Электронная почта.
В 1995 году наиболее быстро растущим сегментом на рынке серверов приложений были серверы баз данных, которые составили 33% поставок всех серверов приложений. IDC прогнозирует в период с 1995 по 2000 год ежегодный рост поставок серверов баз данных на уровне 22%, рост поставок серверов рабочих групп для управления потоками работ - на уровне 36%, а серверов Internet - на уровне 99%.
Основу следующего уровня современных информационных систем предприятий и организаций составляют корпоративные серверы различного функционального назначения, построенные на базе операционной системы Unix. Архитектура этих систем варьируется в широких пределах в зависимости от масштаба решаемых задач и размеров предприятия. Двумя основными проблемами построения вычислительных систем для критически важных приложений, связанных с обработкой транзакций, управлением базами данных и обслуживанием телекоммуникаций, являются обеспечение высокой производительности и продолжительного функционирования систем. Наиболее эффективный способ достижения заданного уровня производительности - применение параллельных масштабируемых архитектур. Задача обеспечения продолжительного функционирования системы имеет три составляющих: надежность, готовность и удобство обслуживания. Все эти три составляющих предполагают, в первую очередь, борьбу с неисправностями системы, порождаемыми отказами и сбоями в ее работе. Эта борьба ведется по всем трем направлениям, которые взаимосвязаны и применяются совместно.
Повышение надежности основано на принципе предотвращения неисправностей путем снижения интенсивности отказов и сбоев за счет применения электронных схем и компонентов с высокой и сверхвысокой степенью интеграции, снижения уровня помех, облегченных режимов работы схем, обеспечение тепловых режимов их работы, а также за счет совершенствования методов сборки аппаратуры. Повышение уровня готовности предполагает подавление в определенных пределах влияния отказов и сбоев на работу системы с помощью средств контроля и коррекции ошибок, а также средств автоматического восстановления вычислительного процесса после проявления неисправности, включая аппаратурную и программную избыточность, на основе которой реализуются различные варианты отказоустойчивых архитектур. Повышение готовности есть способ борьбы за снижение времени простоя системы. Основные эксплуатационные характеристики системы существенно зависят от удобства ее обслуживания, в частности от ремонтопригодности, контролепригодности и т.д.
В последние годы в литературе по вычислительной технике все чаще употребляется термин "системы высокой готовности" (High Availability Systems). Все типы систем высокой готовности имеют общую цель - минимизацию времени простоя. Имеется два типа времени простоя компьютера: плановое и неплановое. Минимизация каждого из них требует различной стратегии и технологии. Плановое время простоя обычно включает время, принятое руководством, для проведения работ по модернизации системы и для ее обслуживания. Неплановое время простоя является результатом отказа системы или компонента. Хотя системы высокой готовности возможно больше ассоциируются с минимизацией неплановых простоев, они оказываются также полезными для уменьшения планового времени простоя.
Существует несколько типов систем высокой готовности, отличающиеся своими функциональными возможностями и стоимостью. Следует отметить, что высокая готовность не дается бесплатно. Стоимость систем высокой готовности на много превышает стоимость обычных систем. Вероятно поэтому наибольшее распространение в мире получили кластерные системы, благодаря тому, что они обеспечивают достаточно высокий уровень готовности систем при относительно низких затратах. Термин "кластеризация" на сегодня в компьютерной промышленности имеет много различных значений. Строгое определение могло бы звучать так: "реализация объединения машин, представляющегося единым целым для операционной системы, системного программного обеспечения, прикладных программ и пользователей". Машины, кластеризованные вместе таким способом могут при отказе одного процессора очень быстро перераспределить работу на другие процессоры внутри кластера. Это, возможно, наиболее важная задача многих поставщиков систем высокой готовности.
Первой концепцию кластерной системы анонсировала компания DEC, определив ее как группу объединенных между собой вычислительных машин, представляющих собой единый узел обработки информации. По существу VAX-кластер представляет собой слабосвязанную многомашинную систему с общей внешней памятью, обеспечивающую единый механизм управления и администрирования. В настоящее время на смену VAX-кластерам приходят UNIX-кластеры. При этом VAX-кластеры предлагают проверенный набор решений, который устанавливает критерии для оценки подобных систем.
VAX-кластер обладает следующими свойствами:
Разделение ресурсов. Компьютеры VAX в кластере могут разделять доступ к общим ленточным и дисковым накопителям. Все компьютеры VAX в кластере могут обращаться к отдельным файлам данных как к локальным.
Высокая готовность. Если происходит отказ одного из VAX-компьютеров, задания его пользователей автоматически могут быть перенесены на другой компьютер кластера. Если в системе имеется несколько контроллеров внешних накопителей и один из них отказывает, другие контроллеры автоматически подхватывают его работу.
Высокая пропускная способность. Ряд прикладных систем могут пользоваться возможностью параллельного выполнения заданий на нескольких компьютерах кластера.
Удобство обслуживания системы. Общие базы данных могут обслуживаться с единственного места. Прикладные программы могут инсталлироваться только однажды на общих дисках кластера и разделяться между всеми компьютерами кластера.
Расширяемость. Увеличение вычислительной мощности кластера достигается подключением к нему дополнительных VAX-компьютеров. Дополнительные накопители на магнитных дисках и магнитных лентах становятся доступными для всех компьютеров, входящих в кластер.
Работа любой кластерной системы определяется двумя главными компонентами: высокоскоростным механизмом связи процессоров между собой и системным программным обеспечением, которое обеспечивает клиентам прозрачный доступ к системному сервису.
В настоящее время широкое распространение получила также технология параллельных баз данных. Эта технология позволяет множеству процессоров разделять доступ к единственной базе данных. Распределение заданий по множеству процессорных ресурсов и параллельное их выполнение позволяет достичь более высокого уровня пропускной способности транзакций, поддерживать большее число одновременно работающих пользователей и ускорить выполнение сложных запросов. Существуют три различных типа архитектуры, которые поддерживают параллельные базы данных:
Симметричная многопроцессорная архитектура с общей памятью (Shared Memory SMP Architecture). Эта архитектура поддерживает единую базу данных, работающую на многопроцессорном сервере под управлением одной операционной системы. Увеличение производительности таких систем обеспечивается наращиванием числа процессоров, устройств оперативной и внешней памяти.
Архитектура с общими (разделяемыми) дисками (Shared Disk Architecture). Это типичный случай построения кластерной системы. Эта архитектура поддерживает единую базу данных при работе с несколькими компьютерами, объединенными в кластер (обычно такие компьютеры называются узлами кластера), каждый из которых работает под управлением своей копии операционной системы. В таких системах все узлы разделяют доступ к общим дискам, на которых собственно и располагается единая база данных. Производительность таких систем может увеличиваться как путем наращивания числа процессоров и объемов оперативной памяти в каждом узле кластера, так и посредством увеличения количества самих узлов.
Архитектура без разделения ресурсов (Shared Nothing Architecture). Как и в архитектуре с общими дисками, в этой архитектуре поддерживается единый образ базы данных при работе с несколькими компьютерами, работающими под управлением своих копий операционной системы. Однако в этой архитектуре каждый узел системы имеет собственную оперативную память и собственные диски, которые не разделяются между отдельными узлами системы. Практически в таких системах разделяется только общий коммуникационный канал между узлами системы. Производительность таких систем может увеличиваться путем добавления процессоров, объемов оперативной и внешней (дисковой) памяти в каждом узле, а также путем наращивания количества таких узлов.
Таким образом, среда для работы параллельной базы данных обладает двумя важными свойствами: высокой готовностью и высокой производительностью. В случае кластерной организации несколько компьютеров или узлов кластера работают с единой базой данных. В случае отказа одного из таких узлов, оставшиеся узлы могут взять на себя задания, выполнявшиеся на отказавшем узле, не останавливая общий процесс работы с базой данных. Поскольку логически в каждом узле системы имеется образ базы данных, доступ к базе данных будет обеспечиваться до тех пор, пока в системе имеется по крайней мере один исправный узел. Производительность системы легко масштабируется, т.е. добавление дополнительных процессоров, объемов оперативной и дисковой памяти, и новых узлов в системе может выполняться в любое время, когда это действительно требуется.
Параллельные базы данных находят широкое применение в системах обработки транзакций в режиме on-line, системах поддержки принятия решений и часто используются при работе с критически важными для работы предприятий и организаций приложениями, которые эксплуатируются по 24 часа в сутки.
№49) Основы конфигурирования серверов баз данных. Архитекрута СУБД.
Одним из наиболее распространенных классов прикладных систем для серверов, выпускаемых большинством компаний-производителей компьютерной техники, являются системы управления базами данных (СУБД). Серверы СУБД значительно более сложны, чем серверы сетевых файловых систем NFS. Стандартный язык реляционных СУБД (SQL) намного богаче, чем набор операций NFS. Более того, имеется несколько популярных коммерческих реализаций СУБД, доступных на серверах различных компаний, каждая из которых имеет совершенно различные характеристики. Вследствие этого последующий материал будет носить достаточно общий характер.
Дело в том, что почти невозможно корректно ответить на вопрос: "Сколько пользователей данного типа будет поддерживать данная система?". В общем случае скорее можно решить, что определенная конфигурация системы не может выполнить данную задачу, чем решить, что данная конфигурация сможет с ней справиться. Например, достаточно просто определить, что система с одним дисковым накопителем не сможет достичь пропускной способности в 130 обращений в секунду при выполнении операций произвольного доступа к диску, поскольку один диск за одну секунду сможет обработать только 65 таких обращений. Однако система с двумя такими дисками либо сможет, либо не сможет справиться с такой нагрузкой, поскольку может случиться, что в системе имеется какое-либо другое узкое место, вовсе не связанное с дисковой подсистемой.
Как приложения, ориентированные на использование баз данных, так и сами СУБД сильно различаются по своей организации. Если системы на базе файловых серверов сравнительно просто разделить по типу рабочей нагрузки на два принципиально различных класса (с интенсивной обработкой атрибутов файлов и с интенсивной обработкой самих данных), то провести подобную классификацию среди приложений баз данных и СУБД просто невозможно.
Хотя на сегодня имеется целый ряд различных архитектур баз данных, рынок UNIX-систем, кажется, остановился главным образом на реляционной модели. Абсолютное большинство инсталлированных сегодня систем реляционные, поскольку эта архитектура выбрана такими производителями как Oracle, Sybase, Ingres, Informix, Progress, Empress и DBase. ADABAS компании Software AG - иерархическая система, хотя может обрабатывать стандартный SQL.
Но даже с учетом того, что подавляющее большинство систем работает по одной и той же концептуально общей схеме, между различными продуктами имеются большие архитектурные различия. Возможно наиболее существенным является реализация самой СУБД.
Можно выделить два основных класса систем: системы, построенные по принципу "2N" (или "один-к-одному"), и многопотоковые системы (рис. 2.1). В более старых 2N-реализациях для каждого клиента на сервере используется отдельный процесс, даже если программа-клиент физически выполняется на отдельной системе. Таким образом, для работы каждого клиентского приложения используются два процесса - один на сервере и один на клиентской системе. Многопотоковые приложения как раз и разработаны для того, чтобы существенно снизить дополнительные расходы на организацию управления таким большим количеством процессов. Обычно они предполагают наличие одного кластера из нескольких процессов (от одного до пяти), работающих на серверной системе. Эти процессы имеют внутреннюю многопотоковую организацию, что обеспечивает обслуживание запросов множества клиентов. Большинство основных поставщиков СУБД в настоящее время используют многопотоковую реализацию или двигаются в этом направлении.

Рис. 2.1. Архитектура СУБД
№50) Характеристики рабочей нагрузки (тесты TPC). Выбор конфигурации сервера СУБД.
В отличие от NFS, где примерно можно понять, какая нагрузка навязывается серверу, без знания деталей приложения, охарактеризовать нагрузку, генерируемую приложением базы данных, невозможно без детальной информации о том, что же в действительности приложение делает. Даже имея подобные сведения, приходится сделать множество предположений о том, как сама СУБД будет обращаться к данным, насколько эффективным может оказаться дисковый кэш СУБД при выполнении определенных транзакций, или даже о том, какова может быть смесь транзакций.
На сегодня в промышленности приняты следующие типы характеристик нагрузки, генерируемой приложением базы данных: "легкая", "средняя", "тяжелая" и "очень тяжелая". Категория "легкая" приравнивается к рабочим нагрузкам, которые доминируют в операциях, подобным транзакциям дебит/кредит, определенным в оценочных тестах TPC-A. Нагрузками "средней" тяжести считаются транзакции, определенные стандартом теста TPC-C. Тяжелыми рабочими нагрузками считаются нагрузки, которые ассоциируются с очень большими приложениями, такими как Oracle*Financials. Такие нагрузки по крайней мере в 5-10 раз тяжелее, чем принятые в тесте TCP-A, а некоторые являются даже еще более тяжелыми.
Основным классом приложений, которые попадают в категорию "очень тяжелой" нагрузки, являются системы поддержки принятия решений. Из-за очень больших различий в природе запросов к системе поддержки принятия решений, администраторы баз данных или самой СУБД сталкиваются с очень большими проблемами по обеспечению широкомасштабной, полезной оптимизации. Запросы к системе поддержки принятия решений часто приводят к формированию существенно большего числа запросов к нижележащей системе из-за необходимости выполнения многонаправленных соединений, агрегатирования, сортировки и т.п. Тест TPC-D был специально разработан для оценки работы приложений поддержки принятия решений.
№51) СУБД InterBase. Манипулирование данными. Агрегатные запросы, коррелированные вложенные подзапросы.
Агрегатные функции – это функции, которые работают не с одним значением, взятым из строки таблицы, а с группой значений.
Общий алгоритм, по которому работают агрегатные функции следующий:
производится упорядочивание таблицы по тем полям, по которым осуществляется группировка;
от каждой сформированной группы вычисляется требуемое значение, которое и заносится в результат.
Существуют следующие агрегатные функции:
COUNT считает количество строк, которые вернул запрос;
SUM суммирует значение всех полей, по указанному атрибуту;
AVG находит среднее значение поля, по указанному атрибуту;
MAX находит максимальное значение поля, по указанному атрибуту;
MIN находит минимальное значение поля, по указанному атрибуту.
В случае если таблица рассматривается целиком, в списке вывода запроса присутствуют только агрегатные функции.
В случае если производится группировка таблицы по какому-то полю, в списке вывода могут присутствовать те поля, относительно которых таблица группируется и агрегатные функции. При этом все поля, не охваченные агрегатными функциями, должны быть перечислены в предложении GROUP BY.
Предположим, что необходимо найти сделку с максимальной стоимостью для каждого торгового агента. Можно сделать персональный запрос для каждого из них, выбрав MAX(amt) из таблицы сделок. Можно записать следующий запрос:
SELECT snum, MAX (amt) FROM Orders GROUP BY snum;
HAVING подобен WHERE – он задает условия отбора групп строк так же, как это делает WHERE для каждой строки.
Внимание! В предложении HAVING нельзя проверять имена атрибутов на какое-либо условие – для этого существует WHERE. То, что проверяется в HAVING должно иметь только одно значение для группы.
Например, если необходимо узнать, какие торговые агенты имеют заработок от одной сделки более чем 3000, и в какой день, можно использовать запрос вида:
SELECT snum, odate, MAX (amt)
FROM Orders
GROUP BY snum, odate
HAVING MAX (amt) > 3000.00
№52) СУБД InterBase. Манипулирование данными. Триггеры, генераторы, представления.
Пользовательское представление - это объект базы данных, представляющий из себя запрос на выборку, каким - либо образом комбинирующий информацию из базовых таблиц базы данных. Часто о представлениях говорят как о "виртуальных" таблицах. Физически данные из исходных таблиц в представления не переносятся, но со стороны представления выглядят как полноправные таблицы.
Представление может быть составлено из:
подмножества столбцов одной таблицы (выводятся не все столбцы таблицы)
подмножества строк одной таблицы (выводятся не все строки таблицы)
подмножества строк и столбцов одной таблицы
подмножества строк и столбцов нескольких таблиц (объединения)