

№1) Понятие данных, банка данных, БД, СУБД. Администратор БД.
Основные понятия и определения
«Информация» происходит от латинского information, что означает сведения. Необходимы системы, где бы информация хранилась и извлекалась бы для обработки.
Информационные системы (ИС) - системы, позволяющие пользователю хранить информацию и обмениваться ею.
ИС разделяют на две группы:
системы информационного обеспечения;
системы, имеющие самостоятельное целевое назначение (область применения).
Системы 1 группы входят во все АСУ, АСУП, САПР. Ко 2-й группе систем относятся системы информационно-справочные (ИСС), информационно-поисковые (ИПС), информационно-управляющие системы (ИУС). В ИСС и ИПС информация представляется в определенном формате, который удовлетворяет пользователя и выдается по его требованию.
Банк данных - хранилище специально подготовленной информации, необходимой для принятия решений различной категории потребителей в различные моменты времени (в «узкой» трактовке).
Банк данных - это записанные в памяти системы по одним критериям информационные данные одной предметной области с отражением взаимосвязей и организацией прямого доступа пользователей (в «широкой» трактовке).
Предметная область (ПО) – область применения конкретного банка (совокупность описания объектов, представляющих интерес для пользователя).
Данные - это информация, фиксированная в определенной форме для последующей обработки, передачи и хранения.
Различают два аспекта данных:
инфологический;
датологический.
Инфологический аспект связан со смысловым содержанием данных без учета их представления в памяти машины.
Датологический аспект связан с представлением данных в памяти машины.
База данных (БД) - это совокупность взаимосвязанных, хранящихся вместе данных при наличии такой минимальной избыточности, которая допускает их оптимальное использование для одного или нескольких приложений. Данные организуются так, чтобы ои были независимы от программных средств. Добавление (модификация) данных должна осуществляться общим управляемым способом.
Система управления базой данных (СУБД) - это программное обеспечение для использования и модификации БД одним или несколькими лицами.
Функции СУБД:
Главная: обеспечить пользователя инструментарием, позволяющим оперировать данными в абстрактной форме, не связанными со способами хранения. СУБД представляет собой интерпретатор языка высокого уровня.
Обеспечение секретности.
Защита целостности данных (СУБД может осуществлять проверку на ограничение и не противоречивость данных).
Синхронизация (защита от одновременного доступа несколькими пользователями к одному элементу данных).
Защита от отказов и восстановление (обеспечение создания копий для восстановления БД после устранения причин сбоя).
Банк данных как АИС
Состав банка данных
Основные компоненты банка данных: БД, СУБД, администратор БД (АБД), словарь данных, обслуживающий персонал, вычислительная система.
1)БД - датологическое представление информационной модели предметной области.
2)СУБД - программа, полностью управляющая доступом к БД. СУБД включает трансляторы (интерпретаторы) с языка описания данных (ЯОД) и языка манипулирования данными (ЯМД).
ЯОД - язык высокого уровня, предназначенный для задания схемы БД, то есть описывающий типы данных, их структуру и взаимосвязь между ними. Это декларативный язык.
ЯМД - язык запросов - система команд, осуществляющая манипулирование данными. В зависимости от способа реализации
ЯМД СУБД делят на: СУБД с включающим языком; СУБД с базовым языком.
В качестве включающего языка используются языки программирования высокого уровня. В СУБД с базовым языком разрабатывается собственный алгоритмический язык, который кроме операций манипулирования данными должен выполнять арифметические операции и операции ввода/вывода. Разрабатываются языки запросов, рассчитанные на пользователей непрограммистов. Смешанный тип систем использует базовый и включающий языки.
3)Словарь данных - специальная система, предназначенная для хранения единообразной и централизованной информацией обо всех ресурсах конкретного банка данных.
В словаре данных содержится следующая информация
а) об объектах, их свойствах и отношениях;
б) о данных из БД (наименования, структура, связи);
в) о возможных значениях и форматов данных;
г) об источниках поступления данных;
д) о кодах защиты и разграничения доступа и т. д.
4)Администратор базы данных (АБД) - лицо или группа лиц, реализующих управление БД.
Состав группы АБД: а) группа сопровождения; б) группа контроля функционирования банком данных; в) эксперт по языкам запросов; г) эксперт по прикладным программам;
д) эксперт по системным вопросам;
е) эксперт по вопросам эксплуатации. Классификация задач, решаемых АБД
Таблица1
Классификация Задачи |
Приложения |
Системы |
Административные задачи |
определение операционных целей; определение политики доступа; стандартизация элементов данных; задание приоритетных приложений |
выбор программного и аппаратного обеспечения; определение политики восстановления БД; стандартизация программирования |
Технические задачи |
создание и определение данных; разработка структур данных; обучение пользователей; ведение словаря данных; документирование БД |
сопровождение БД; разработка физических структур; регулирование эксплутационных характеристик; отслеживание эксплуатации БД |
Прикладные задачи рассчитаны на пользователя, связаны с содержанием и использованием БД. Системные задачи имеют дело с аппаратной средой и эксплуатацией БД.
№2) Этапы развития БД. Требования к организации БД. Этапы проектирования БД.
Выделяют 4 этапа. Первый этап:
логический файл данных физический файл данных
|
|
|
|
|
|
|
программное обеспечение в/в |
|

Рис. 2. Простые файлы данных (начало 60-х годов).
На этом этапе обработка данных сводилась к вводу/выводу. Данные размещались в файлах последовательно, носителями были магнитные ленты. Любое изменение данных, аппаратных средств приводило к изменению прикладных программ. Логическая структура данных соответствовала физической. Данные использовались только для одного приложения, существовало большое количество копий данных (большая избыточность). Обработка велась в пакетном режиме, не был использован режим реального времени.
Второй этап:
л огический
файл данных физический файл
данных
огический
файл данных физический файл
данных
|
|
|
|
Методы |
|
|
доступа |
|
|
|
|


Рис. 3. Методы доступа (конец 60-х годов).
На этом этапе достигнута независимость прикладных программ от аппаратных средств. Существует несложная зависимость между физической и логической структурами данных. На данном этапе используются следующие методы доступа к наборам данных: прямой; последовательный; индексно-последовательный.
Данные представляются в виде наборов записей. Допускается изменение содержания данных без изменения структуры, это не вызывает изменений прикладных программ. Высокая избыточность. Возможна обработка данных в пакетном режиме и режиме реального времени.
Третий этап:
Логические файлы
прикладных программистов Физическая БД
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|


Рис. 4. Управление данными (начало 70-х годов).
Появление первых СУБД связано с возрастанием объема обрабатываемой информации. Возникла необходимость добавления полей и увеличения размера БД. Поэтому элементами данных стали поля записи. Изменение физической структуры БД не вело к изменению логической структуры (физическая независимость данных). За счет использования одних и тех же данных в различных приложениях была уменьшена избыточность (из имеющихся наборов сегментов могли формировать различные записи).
Ч етвертый
этап:
етвертый
этап:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|

логическая независимость данных физическая независимость данных
Рис. 5. Современные системы БД
ГЛПД - глобальное логическое представление данных.
С возрастанием обрабатываемого объема данных стало необходимым изменять и логическую структуру данных. Возникла задача 2-х уровней независимости данных (физической и логической). Логическая независимость данных означает, что общая логическая структура данных может быть изменена без изменения прикладных программ. Физическая независимость данных означает, что физическое расположение (организация) данных может изменяться, не вызывая при этом изменений общей логической структуры и прикладных программ.
Требования к организации БДОсновные требования:
Многократное использование данных. Пользователи, которые по-разному понимают данные, могут их по разному использовать.
Сохранение затрат умственного труда. Существующие программы и структуры данных не изменяются при внесении изменений в БД.
Низкие затраты. Низкая стоимость хранения и использования данных, минимизация затрат на внесение изменений в БД.
Уменьшение избыточности данных. Требование новых приложений удовлетворяется за счет уже имеющихся данных, а не путем создания новых файлов.
Производительность. Запросы на данные удовлетворяются с такой скоростью, которая требуется для использования данных.
Простота. Пользователи могут удалить и понять какие данные имеются в их распоряжении.
Легкость использования. Пользователи имеют простой доступ к данным , сложный осуществляет СУБД.
Гибкость использования. Обращение к данным или их использование осуществляется с приложением различных методов доступа.
Быстрая обработка непредсказуемых запросов. Случайные запросы на данные обрабатываются с помощью языка высокого уровня запросов или генератора отсчетов, а не прикладными программами, написанными программистами.
Простота внесения изменений . База данных может изменяться и увеличиваться без нарушения имеющихся способов использования данных.
Достоверность данных и соответствие их одному уровню обновления. Система запрещает наличие одной и той же версии элементов данных.
Секретность. Несанкционированный доступ к данным не возможен. Одни и те же данные получают пользователи различных уровней различными путями.
Защита от уничтожения и искажения. Данные защищают от сбоя, вмешательств и т. д.
Готовность. Пользователь быстро получает данные, когда ему это необходимо.
Дополнительные требования:
Физическая независимость данных.
Логическая независимость данных.
Контролируемая избыточность.
Обеспечение требуемой скорости доступа.
Обеспечение требуемой скорости поиска.
Стандартизация данных в пределах учреждения.
Словарь данных.
Наличие интерфейса высокого уровня для связи с пользователем.
Наличие языка взаимодействия пользователя с системой.
Контроль целостности данных.
Восстановление данных после сбоев.
Настройка.
Вспомогательные средства для проектирования и управления.
Автоматическая реорганизация или перемещение.
Процесс проектирования БД
Ц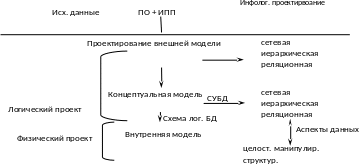 ель
проектирования:
создать точную и защищенную БД, на основе
которой можно гарантировать эффективное
построение прикладных программ.
ель
проектирования:
создать точную и защищенную БД, на основе
которой можно гарантировать эффективное
построение прикладных программ.
Схема Физ. БД
Рис. 6. Процесс проектирования БД.
ИПП - информационные потребности пользователя.
Процесс проектирования БД состоит из 2-х этапов:
проектирование логической БД;
проектирование физической БД.
При проектировании логической БД производится анализ ПО и информационных потребностей пользователя. Пользовательские требования выражаются рядом внешних моделей - представлений. Проектирование внешней модели заключается в формализации этих представлений. КМД соответствует общему представлению о БД, то есть она включает представление о структуре данных, их целостности и манипулировании данными. Преобразование ВМД в КМД определяется выбором СУБД. Как внешняя так и концептуальная модель может быть 3-х видов:
1)сетевая;2)иерархическая;3)реляционная.
Физическое проектирование связано с фактической реализацией БД. Оно определяет рациональный выбор структуры хранения данных и методов доступа к ним. Результат физического проектирования - внутренняя модель данных.
При проектировании БД рассматривают 3 уровня абстракции:
физический;2)концептуальный;3)представления.
№3) Основные понятия, используемые для описания БД. Схемы и подсхемы как способ описания логической структуры данных.
Терминология, используемая для описания БД
Объект - элемент, информацию о котором мы сохраняем. Он может быть материальным и нематериальным. Атрибут - свойство объекта.
Наименьшей единицей данных является отдельное значение данных, которое называется атомарным. Домен - множество атомарных значений одного атрибута.
Отношение - таблица, обладающая следующими свойствами:
каждый элемент таблицы представляет собой один элемент данных (отсутствие повторяющихся групп);
все столбцы однородны (то есть элементы столбца имеют одинаковую природу);
столбцам однозначно присвоены имена;
в таблице нет двух одинаковых строк;
в операциях с такой таблицей все строку и столбцы могут рассматриваться в любом порядке не зависимо от их смысла и содержания.
Кортеж - строка такой таблицы.
Ключ - атрибут (совокупность атрибутов), используемый для идентификации записей или кортежа.
Основной ключ - ключ, который используется для уникальной идентификации записей (первичный ключ).
Дополнительный (вторичный) ключ - не идентифицирует уникальную запись, но идентифицирует все записи, обладающие одним определенным свойством.
Внешний ключ - это атрибут или комбинация атрибутов отношения R2 ,значение которых обязательно должно совпадать со значением первичного ключа некоторого другого отношения R1.
Экземпляр записи - это значение в конкретной сроке таблицы.
Таблица 2
Формальные термины |
Неформальные термины |
отношения |
таблицы |
кортеж |
запись, строка |
атрибут |
столбец |
Наиболее простой способ представления элементов данных и связей между ними - двумерный файл.
Пример:
С
4
 лужащий
лужащий
-
№


 слу-жащ.
слу-жащ.Ф
 амилия
служащ.
амилия
служащ.Должностьслужащ.
Код спе-циальн.
№ от-дела
Зар-плата
01
Иванов
инженер
08
1
1000
0

133вввввввввввв
2Петров
лаборант
05
2
500
03
Сидоров
лаборант
05
2
400
04
Козлов
инженер
08
2
1200
2
3
5
6
Кортеж.2. Возможный ключ. 3.Домен.4.Имена атрибутов.5.Первичный ключ.
Вторичный ключ.
Отдел
-
№ отдела
Руководитель
1
А
2
Б
№ отдела - внешний ключ отношения «Служащий» при наличии отношения «отдел».
Существует 2 способа представления информации:
Прямой - каждый кортеж содержит все атрибуты данного объекта.
Инверсия первого - этот способ необходим для получения идентификаторов объектов, связанных с каким-то конкретным атрибутом.
Первый способ позволяет определить какими свойствами обладает данный объект. Второй способ определяет какие объекты обладают данным свойством.
Полностью инвертированный файл - это файл, который хранит идентификаторы объектов, связанные с конкретным значением каждого атрибута.
Частично инвертируемый файл хранит идентификаторы объекта, связанные со значением некоторых атрибутов.
Инвертируемый список - файл, хранящий идентификаторы, связанные с одним атрибутом.Пример:
Инвертируемый список для отношения «Служащий»:
-
Код специальности
№ служащего
08
01
04
05
02
03
Схемы и подсхемы, как способ описания логической структуры данных
Если бы БД была предназначена только для хранения информации, то ее структура была бы очень проста. Сложность обусловлена наличием связей между элементами данных, поэтому необходимо формальное описание структуры данных.
Описание логической БД называется схемой. Схема представляет собой таблицу типов используемых данных, она содержит имена объектов и атрибутов и указывает связи между ними. В схему могут быть помещены конкретные данные. Если схема содержит значения элементов данных, то ее называют экземпляром схемы. Схема изображается в виде диаграммы, состоящей из блоков. Термин «схема» используется для определения полной таблицы всех типов элементов данных и записей, которые хранятся в БД. Термин «подсхемы» определяет описание данных, которые используются прикладной программой. На базе одной схемы могут быть построены несколько подсхем.
Схема состоит из блоков, в которых указываются поля записи, ключевое поле подчеркивается, над блоком ставится имя объекта. Блоки между собой связаны стрелками-связями. Блоки изображаются в виде прямоугольников, очерченных сплошной линией для записей и пунктирной для агрегатов данных. Между блоками могут быть изображены перекрестные ссылки, указывающие на связи между таблицами (они изображаются пунктирной линией). Если перекрестные ссылки опущены в схеме или подсхеме ,то потеря информации не происходит. Ссылки необходимы для организации быстрого поиска информации. Линии связи показывают на дополнительную передачу информации.
Тип агрегат содержит ограниченное число записей.
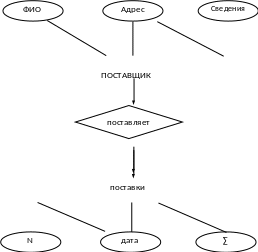
Пример : система закупки в упрощенном виде.
заказ на закупку
№ заказа |
№ постав-щика |
имя поставщика |
адрес поставщика |
дата поставки |
дата заказа |
итого |
с пецификация
заказа
пецификация
заказа
-
№ партии товара
наименование партии
заказанное количество
цена
Рис. 7. Подсхема программиста А.
товар на складе
-
№
 партии товара
партии товаранаименование партии товара
количество товара
с пецификация
заказа
пецификация
заказа
-
№ заказа
имя поставщика
заказанное количество
дата заказа
дата поставки
Рис. 8. Подсхема программиста Б.
На основе этих подсхем строим схему.
заказ на закупку
-
№
 заказа
заказа№поставщика
дата заказа
дата поставки
и
 того
того
статья закупки1:
-
№
 партии товара
партии товараз
 аказанное
количество
аказанное
количествоцена
поставщик:
-
№ поставщика
и
 мя
поставщика
мя
поставщикаадрес поставщика
сведения о поставщике
статья закупки2:
-
№ партии товара
цена
время поставки
партия товара:
-
№ партии
название партии
расценка
к
 оличество
оличество
-
номер заказа
Рис. 9. Схема логической структуры БД.
№4) Типы связей между элементами данных.
Типы связей:
 1:1 (один к одному).
Пример: муж жена;
1:1 (один к одному).
Пример: муж жена;1:М (один ко многим). Пример: муж жена;
М:1 (многие к одному). Пример: муж жена;
М:М (многие ко многим). Пример: муж жена.
№5) Алгоритм построения схемы логической структуры данных.
Построение схемы
Правила построения схемы:
отображать различия между именами записей, именами элементов и другими именами;
изображать объединение элементов данных в агрегаты данных;
отображать отличия между агрегатами данных и записями;
отмечать идентификаторы записей;
представлять ясно типы связей;
связи отличать от перекрестных ссылок;
связи между записями именовать или нумеровать;
не использовать повторяющиеся имена.
Записи изображаются с помощью прямоугольников со сплошными сторонами, а агрегаты - прямоугольниками с пунктирными сторонами. Имена записей и агрегатов идут вне прямоугольников, имена атрибутов внутри прямоугольников. Идентификаторы подчеркиваются.
Алгоритм построения схемы логической структуры данных.
1)Рассмотреть все связи между блоками исходной схемы, объединить в один блок все блоки, связанные как 1:1.
2)Блок исходной схемы, который является начальным или имеет связь 1:М, М:1, М:М, определяет объект (отношение); блок , имеющий только связь 1:1 определяет атрибут.
3)Выяснить какие из блоков имеют тип записи, какие тип агрегата.
4)В качестве ключей использовать уникальные имена.
-
Л ичность

ФИО |
|
дата рожд. |
|
Адрес |
|
п рофессия |
|
р ебенок |


код |
|
специал |
|
имя |
|
возраст |
Личность
-
Ф ИО
дата рождения
адрес


ребенок
п рофессия
-
код
с
ИМЯ
возраст
пециальност
№6) Виды описания данных.
Четыре вида описания данных

№7) Способы представления исходной информации: ЕR-диаграммы, диа-граммы Бахмана, овал - диаграммы.
Неформальная модель предметной области, которая используется на этапе инфологического проектирования, является исходной для логического проектирования - это модель типа «объект- связь».
Назначение этой модели - семантическое описание предметной области, а также представление информации для выбора вида моделей (сетевой, древовидной, реляционной) и структур данных для следующих этапов проектирования БД.
Наиболее распространенными являются 3 вида описания неформальной модели:
ER - диаграммы;
диаграммы Бахмана;
овал - диаграммы.
ER – диаграммы
Принятые обозначения:
прямоугольник обозначает объект; 2. овал - атрибут;
ромб - связь; 3.объекты и атрибуты связаны ребрами, связи между объектами обозначаются дугами;
 4.ключевой
атрибут подчеркивается.
4.ключевой
атрибут подчеркивается.
Рис. 12.
Диаграммы Бахмана
Принятые обозначения:
прямоугольник - объект, внутри прямоугольника пишется имя объекта и в круглых скобках могут быть перечислены атрибуты;
объекты связаны между собой направленными ребрами, связи подписываются;
диаграммы предназначены для древовидных, сетевых структур, поэтому всегда существует исходный объект и подчиненный объект.
-
Организация (наименование, адрес)
работает
-
сотрудник (ФИО)
Рис. 13.
Овал – диаграммы
Принятые обозначения:
атрибуты представляются в овалах, ключевой атрибут подчеркивается;
с


 вязи
представляются в виде направленных
ребер между овалами.
вязи
представляются в виде направленных
ребер между овалами.
 Число членов
экипажа Количество мест в самолете
Тип самолета
Число членов
экипажа Количество мест в самолете
Тип самолета


№ самолета


 №
рейса
№
рейса



Количество свободных мест Пункт отправления Пункт назначения
Рис. 14.
№8) Определение сетевой и древовидной структур данных.
Наиболее распространены 3 типа структур и моделей данных:
иерархическая или древовидная;
сетевая;
реляционная (плоские файлы).
8.1 Иерархические структуры данных
Дерево представляет собой иерархию элементов, называемых узлами. Дерево может быть определено как иерархия узлов с двоичными связями , такими что:
самый верхний уровень иерархии имеет один узел, называемый корнем;
все узлы, кроме корня, связываются с одним и только одним узлом на более высоком уровне иерархии по отношению к ним самим.
Иерархическим файлом называется файл, в котором записи связаны в виде древовидной структуры.
Использование древовидной модели осуществляется, когда имеются связи один ко многим, т.е. от порожденного элемента к исходному существует простой переход.
Древовидные структуры бывают :
однородными (каждый узел представлен одним и тем же типом);
неоднородными.
Пример:
 отдел
отдел



 служащий работа заказчик
служащий работа заказчик
Рис. 15. Двухуровневое дерево с разнотипными записями.
Дерево может быть переменной или фиксированной глубины. Обычно СУБД работает с неоднородными деревьями фиксированной глубины.
8.2 Сетевые структуры данных
Если порожденный элемент в отношении между данными имеет более одного исходного элемента, то это отношение описывается в виде сетевой структуры.
Сетевая структура является однородной, если каждый ее узел может быть представлен одним и тем же типом записи.
Структура является сетевой, если она включает следующие моменты:
на входе блока имеются несколько связей 1:М

А


2 )имеются
циклы А
)имеются
циклы А
Ц иклом называется ситуация ,
когда предшественник одновременно Б
я вляется и последователем.
3
 )наличие
петель
)наличие
петель
А
Петля - это цикл, состоящий из одного типа записи.
4 )наличие
связи М:М.
)наличие
связи М:М.
Е сли
сетевая структура имеет А
сли
сетевая структура имеет А
связи М:М, то ее называют
с ложной сетевой структурой; Б
в противном случае - простой сетевой структурой.
№9) Преобразование сложной сетевой структуры в древовидную структуру данных. Цель преобразования.
Любую простую сетевую структуру можно преобразовать в древовидную, введя избыточность.
Пример1:




 1 1
1 1
 2 3 2 3
2 3 2 3
 4 4 4
4 4 4
Рис. 18.П ример2:

 1 1
1 1
2 2
3 3
1
Рис. 19.
Пример3:
1

 2 3 1 2
3
2 3 1 2
3









 4 5 4 4 5 5 8
4 5 4 4 5 5 8











6 7 8 6 7 6 7 7 8 7 8
Рис. 20.
Формально количество деревьев определяется числом блоков, на которые не указывают двойные стрелки.
№10) Множественные отношения.
Множественные отношения
Рассмотренные ранее отношения были бинарные, то есть между данными существовал один тип отношений (на связях не было пометок). Если между объектами существуют несколько типов отношений, тогда связь необходимо помечать. Пример:
ж енщина
енщина
женаты /помолвлены/разведены/незнакомы
м ужчина
ужчина
Для формализации множественных отношений необходимо ввести дополнительный файл описания связей. Тогда:
Женщина
ФИО женщ. |
Сведения о женщ. |
м ужчина
+ связь + тип связи
ужчина
+ связь + тип связи
ФИО муж. |
сведения о муж. |
|
ФИО женщ. |
ФИО муж. |
Тип связи |
|
№ типа связи |
наименова-ние связи |
Рис.21.
Категории схем сетевых и иерархических структур
Категории схем Таблица 3
|
двухуровневые |
схемы |
многоуровневые |
схемы |
схема с |
||
без ветвления |
с ветвлением |
без ветвления |
с ветвлением |
циклом |
|||
д струк-туры
|
|
|
|
|
|
||
простые сетевые
|
|
|
|
|
|
||
сложные сетевые
|
|
|
|
|
|
||
п
|
|
|
|
|
|
||



 рево-видные
рево-видные










 етли
(одно-уровне-вые циклы)
етли
(одно-уровне-вые циклы)
№11) Реляционная модель.
(реляционная модель)
Одним из простейших способов представления данных являются таблицы (плоские файлы). Они просты, удобны, наглядны, легко запоминаются.
Процесс приведения древовидной структуры к табличной форме называется нормализацией. Это понятие ввел Кодд.
Задача преобразования древовидной структуры к табличной форме состоит в ведении избыточности. В результате получаем первую нормальную форму (1НФ). Существуют 7НФ. Приведение к каждой из последующих нормальных форм связано с устранением избыточности.
В теории БД таблица называется отношением, а реляционную БД называют совокупностью отношений.
Таблица представляет собой множество кортежей. Если таблица имеет n - столбцов, то ее называют отношением степени n. Таблица, состоящая из 2-х столбцов называется бинарным отношением; из 3-х столбцов - тернарным отношением; из n столбцов - n-арным отношением.
В математике отношение R определяется как множество строк на множествах S1, S2, ..., Sn, таких что первый элемент каждой строки принадлежит S1, второй элемент - S2, ..., последний - Sn. Для описания таких таблиц используют обозначения реляционной алгебры и реляционных исчислений. С логической точки зрения реляционная БД - это множество двумерных таблиц с операциями извлечения и объединения столбцов.
№12) Получение 1НФ из древовидной структуры.
Получение 1НФ из древовидной структуры сводится к устранению повторяющихся групп. Основой этого этапа нормализации является определение ключей.
Пример:заказ
-
№ заказа
ФИО
адрес поставки
дата поставки
т овар
-
№ заказа
наименование товара
цена товара
Достаточно перенести ключ из отношения заказа в отношение товар.
Заказ
-
№ заказа
ФИО
адрес поставки
дата поставки
товар
-
№ заказа
№ товара
наименование товара
цена товара
Заказ (№ заказа, ФИО, адрес поставки, дата поставки).
Товар (№ заказа, № товара, наименование товара, цена).
Свойства, которыми должен обладать ключ:
однозначная идентификация кортежа;
отсутствие избыточности (то есть никакой атрибут нельзя удалить из ключа, не нарушая при этом свойства однозначной идентификации).
Для одного отношения могут существовать несколько наборов атрибутов, обладающих указанными двумя свойствами. Такие наборы называют возможными ключами; тот ключ, который фактически будет использован для индексации кортежа, называют первичным или основным ключом. Для первичного ключа необходимо выбирать атрибуты так, чтобы был заранее известен диапазон значений и количество этих атрибутов было наименьшим.
Правило формирования ключа:
Ключ некоторого отношения должен содержать ключ отношения, соответствующего вышестоящей вершине дерева, если он уже не является атрибутом этого отношения. Если при этом не выполняется второе свойство, то ключ предшествующего отношения становится не ключевым атрибутом последующего отношения.
Примечание:
результатом нормализации является отношение, имеющее свои ключи; если есть отношения с одинаковыми ключами, то их объединяют.
Пример:отдел
-
№ отдела
ФИО руководителя
бюджет
работа служащий
№ работы |
наименование |
сведения |
|
№ служащ. |
ФИО |
домаш. адрес |
и зменения оклада
-
оклад
дата изменения оклада
1НФ:
отдел (№ отдела, ФИО руководителя*, бюджет)
работа (№ отдела*, № работы*, наименование работы*, сведения )
служащий (№ служащего*, № отдела, домашний адрес, ФИО*)
изменения оклада (№ служащего, дата изменения, оклад )
№13) Сравнение моделей на базе сетевой, иерархической и реляцион-ной структур.
Для сравнения структур данных существует два критерия:
Легкость использования. Основная часть издержек, особенно в малых БД, содержащих порядка нескольких тысяч записей, и средних БД, содержащих порядка нескольких десятков тысяч записей, приходится на написание прикладных программ и формирование запросов.
Эффективность. Для больших БД издержки приходятся на стоимость памяти и машинного времени, поэтому необходима эффективная реализация.
Исходя из этих критериев, для больших БД используют сетевую или иерархическую структуры, а для малых БД и средних БД - реляционную структуру.
№14) Целостность данных.
Реляционная БД - это набор экземпляров конечных отношений. Схема реляционной БД может быть представлена в виде совокупности следующих отношений:
 R1(A11,
A12,
..., A1n)
R1(A11,
A12,
..., A1n)
...
R2(Am1, Am2, ..., Amk)
Главная задача проектирования реляционной БД:
понизить избыточность и повысить надежность БД. При этом основное место отводится целостности данных, то есть ограничениям на зависимости между атрибутами отношений.
Существуют два вида ограничений:
ограничение, которое зависит от семантики элементов домена (значение элемента должно находиться в каком-либо диапазоне, либо должны выполняться какие-либо зависимости между различными атрибутами одного кортежа)
ограничение, связанное с равенством значений атрибутов различных отношений (связь таблиц по внешнему ключу, то есть первичный ключ всегда должен быть определен, а значения внешнего ключа могут быть определены , а могут быть и не определены)
К таким ограничениям относят функциональные зависимости, многозначные зависимости и зависимости соединения.
№15) Определение функциональной зависимости (F-зависимости).
Функциональные зависимости
(F - зависимости)
Введем следующие обозначения:
A, B, C - обозначения атрибута;
X, Y, Z - множество атрибутов;
a, b, c, x, y, z - значения атрибутов;
R, S, V - отношения;
U- универсальное отношение;
XY - объединение множеств атрибутов X и Y.
Определение функциональной зависимости
Пусть X и Y - атрибуты отношения R.
Атрибут X функционально зависит от атрибута Y, если в каждый момент времени каждому значению X соответствует одно и то же значение Y:
f : X Y
Если имеем запись X#Y ,то это означает, что между ними нет F- зависимости.
Если XY и YX, то говорят, что между X и Y взаимооднозначное соответствие.
Пример:
деятельность программиста (№ программиста*, № программы*, ФИО программиста*, название программы*, затраченное время на разработку программы).
Деятельность программиста:
№ программиста*
№ программы*
программы*
ФИО программиста*
название программы*
затр. время на разр. прогр.
№16) Определение полной функциональной зависимости.
Атрибут Y отношения R называется полностью зависимым от атрибута X, если он полностью зависит от всех атрибутов множества X, но не зависит от какого-либо подмножества X.
№17) Аксиомы функциональных зависимостей.
Пусть задано для отношения R множество функциональных зависимостей
F = { F1, F2, ..., Fn }
Замыкание множества F+ есть множество всех зависимостей, выводимых из множества F. Часто ставится задача определить принадлежит ли зависимость X Y множеству F+. Для этого необходимо из имеющихся зависимостей F вывести зависимость X Y. Для этого необходимо иметь правила вывода, Множество таких правил должно обладать свойствами полноты и надежности.
Свойство полноты означает, что при заданном множестве зависимостей F, правила позволяют вывести все зависимости, принадлежащие F+.
Свойство надежности означает, что, используя эти правила, мы не можем вывести из F какую-либо зависимость, которая бы не принадлежала F+.
Множество таких правил называют аксиомами Амстронга.
Пусть дано: U, множество атрибутов X, Y, Z, W, и множество функциональных зависимостей F.
Аксиома 1(рефлексивность):
если X Y U то X Y, такие зависимости называют тривиальными (то есть правая часть содержится в левой: А А, АС А).
Аксиома 2 (пополнение):
если X Y и Z U, то ZX ZU
Аксиома 3 (транзитивность):
если XY и Y Z. то X Z
Кроме этих аксиом, существуют правила:
Правило 1 (объединение):
если X Y и X Z , то X YZ.
Правило 2 (псевдотранзитивность):
если X Y и WY Z , то WX Z
Правило 3 (декомпозиция):
если X Y и Z Y , то X Z.
№18) Свойства аксиом Армстронга.
Лемма 1: аксиомы Амстронга являются надежными.
Лемма 2: функциональная зависимость X Y следует из аксиом Амсронга, и если только если Y X+. X+ является замыканием множества атрибутов X на множестве F. X+ есть множество атрибутов А, таких, что зависимость XA может быть выведена из F по аксиомам Амстронга.
Теорема: аксиомы Амстронга являются надежными и полными
№19) Вычисление замыкания множества функциональных зависимостей.
Вычисление F+ трудоемкая задача.
Если есть F={XB1, XB2, ..., XBm}, чтобы получить множество F+, необходимо сформировать множество зависимостей вида XY, где Y - комбинация атрибутов {B1, B2, ..., Bm}, количество комбинаций два в степени m.
Алгоритм построения замыкания X+:
Дано: F, U, X.
Алгоритм сводится к нахождению множеств Х(0), Х(1), ..., Х(n).
X(0):=X; i:=0;
формируем Х(i+1) присоединяя к X(i) атрибуты из правой части функциональной зависимости, в левой части которой стоитмножество атрибутов, являющихся подмножеством X(i);
i:=i+1; и переходим к пункту 2 до тех пор, пока X(i)#X(i+1);
X+:=X(i+1).
Пример:
Дано: F={ABC, DEG, CA, BEC, BCD, CGBD, ADCB, CEAG}
X = BD
Найти: X+.
1) X(0):=BD DEG
X(1):=BDEG BEC
X(2):=BCDEG CA, BCA, CEAG
X(3):=ABCDEG
X+:=ABCDEG
BD(любая комбинация из X+) - эта зависимость принадлежит F+.
№20) Покрытие множеств зависимостей.
Пусть F, G множества зависимостей для U. F и G эквивалентны, если совпадают множества F+ и G+.
Проверка эквивалентности F и G:
для каждой зависимости XY множества F определяют содержится ли эта зависимость в G+. Для этого находим замыкание X+ относительно G+, и если YX+, тогда эта зависимость XY принадлежит G+. Проверяем принадлежность всех зависимостей из F G+, если все зависимости принадлежат G+, то G покрывает F. Выполняем аналогичную проверку для всех зависимостей G к F+. Если F покрывает G и G покрывает F, то F и G эквивалентны.
Условия минимальности множества зависимостей F:
все зависимости во множестве F имеют вид XA, то есть в правой части стоит один атрибут;
не для какой зависимости XA ее удаление из F не приведет к получению эквивалентного множества;
не существует такой зависимости XA, для которой выполняется условие эквивалентности (F-{XA})(ZA) и F, где ZX.
Пример:
Дано: F={ AB C, D EG, CA, BEC, BCD, CGBD, ACDB, CEAG }
Найти минимальное покрытие.
AB C D E DG
CA BEC BCD
CGB CGD ACDB
CEA CEG
Находим зависимости, для которых в результате вывода получается зависимость, которая уже присутствует в заданном множестве F.
Можно проверить: CA, CGD CGADCG, ACDB СGB. Удаляя CGB, получаем минимальное покрытие.
№21) Операция объединения и проекции схем отношений.
Существует две основные операции над БД: проекция и объединение.
1) Проекция - выделение в таблице определенных столбцов:
служащий
№ служащ. |
ФИО |
№ отдела |
адрес |
зарплата |
1 |
Иванов |
1 |
Севастополь |
100 |
2 |
Петров |
2 |
Москва |
200 |
3 |
Сидоров |
1 |
Севастополь |
100 |
4 |
Семенов |
1 |
Севастополь |
5 |
5 |
Яковлев |
3 |
Киев |
35 |
служащий отдел
№ служащ. |
ФИО |
№ отдела |
зар-плата |
|
адрес |
№ отдела |
1 |
Иванов |
1 |
100 |
|
Севастополь |
1 |
2 |
Петров |
2 |
200 |
|
Москва |
2 |
3 |
Сидоров |
1 |
100 |
|
Киев |
3 |
4 |
Семенов |
1 |
5 |
|
|
|
5 |
Яковлев |
3 |
35 |
|
|
|
Операция объединения - операция обратная операции проекции, состоящая в объединении нескольких таблиц:
Пример:
Заключенный статья
№ заключения |
ФИО заключенного |
Адрес заключения |
№ статьи |
|
№ статьи |
название |
101 |
Иванов |
Киев |
10 |
|
10 |
грабеж |
203 |
Петров |
Москва |
11 |
|
11 |
кража |
107 |
Козлов |
Москва |
11 |
|
|
|
преступление
-
№ заключенного
дата заключения
место заключения
101
01.01.97
Лондон
203
02.03.97
Париж
107
30.10.96
Париж
Объединяем три таблицы в одну.
*№ заключ. |
ФИО заключ. |
Адрес заключ. |
№ статьи |
название статьи |
дата заклю-чения |
место заклю-чения |
101 |
Иванов |
Киев |
10 |
грабеж |
01.01.97 |
Лондон |
203 |
Петров |
Москва |
11 |
кража |
02.03.97 |
Париж |
107 |
Козлов |
Москва |
11 |
кража |
30.10.96 |
Париж |
Рис. 27.
№22) Понятие декомпозиции, свойства декомпозиции.
Понятие декомпозиции схем и ее свойства
Декомпозиция схемы отношений R=(A1, A2, ..., An) представляется множеством отношений =(R1, R2, ... , Rm) таких, что R=R1R2...Rm. Причем R1, R2, ... , Rm необязательно являются непересекающимися.
Декомпозиция имеет два свойства:
соединение без потерь информации;
сохранение зависимостей.
Н
 е
каждая декомпозиция обладает этими
двумя свойствами. Говорят, что декомпозиция
обладает свойством соединения без
потерь информации, если естественное
соединение R=R1
R2
... Rm
дает исходное отношение. Говорят, что
декомпозиция обладает свойством
сохранения зависимости, если множество
зависимостей F
выводимо из схем отношений Ri.
е
каждая декомпозиция обладает этими
двумя свойствами. Говорят, что декомпозиция
обладает свойством соединения без
потерь информации, если естественное
соединение R=R1
R2
... Rm
дает исходное отношение. Говорят, что
декомпозиция обладает свойством
сохранения зависимости, если множество
зависимостей F
выводимо из схем отношений Ri.
№23) Проверка свойства декомпозиции соединения без потерь.
Входные данные: схема отношения R на множестве атрибутов A1, ..., Аn, декомпозиция =(R1, ..., Rn), множество F функциональных зависимостей.
Выходные данные: решение о том, обладает ли декомпозиция свойством соединения без потерь.
Алгоритм:
строим таблицу с n столбцами и m строками;
столбец j соответствует атрибуту Aj, строка i соответствует схеме отношений Ri, на пересечении j-го столбца и i-й строки помещается символ aj, если атрибут Aj принадлежит схеме отношений Ri, иначе ставится символ bij;
рассматриваем полученную таблицу, анализируя зависимость XY, ищем строки, для которых совпадают значения по всем столбцам, соответствующим X. При обнаружении таких строк отождествляем их символы в столбцах, соответствующих Y. При этом, если оба символа bij и bil , то делаем их равными либо bij, либо bil; если один из символов равен aj, то все другие символы приравниваем к aj.
Повторяем до тех пор, пока не рассмотрим все зависимости из F.
Если какая-либо строка будет состоять только из символов aj, то такая декомпозиция обладает искомым свойством, иначе - не обладает.
Пример:
R={N, I, O, A}, R1={N, I, O}, R2={O, A}, F={NIO, OA}
-
N
I
O
A
N
I
O
A
R1
a1
a2
a3
b14
R1
a1
a2
a3
a4
R2
b21
b22
a3
a4
R2
b21
b12
a3
a4
Рис. 28.
Данный алгоритм используется при декомпозиции на множестве отношений. Если имеем два отношения в декомпозиции, то используется теорема:
Если =(R1,R2) - декомпозиция R и F - множество функциональных зависимостей, то обладает свойством соединения без потерь относительно F, если
(R1R2)(R1-R2) либо (R1R2)( R2-R1 )
Полученная зависимость не обязательно должна принадлежать F, но должна принадлежать F+.
Пример:
Дано: =( R1,R2), R1={N, I, O}, R2={O, A}, F={NI O, O A}.
R1R2=0, R2-R1=A, таким образом OA принадлежит F, что и требовалось доказать.
№24) Декомпозиции, сохраняющие зависимости.
Формально проекцией F на множество атрибутов Z называется множество зависимостей из XY в F+ таких, что XYZ.
Декомпозиция обладает свойством сохранения зависимостей, если из объединения всех зависимостей, принадлежащих проекции F на Ri (i=1...n), логически следуют все зависимости F.
Сохранение зависимостей из F необходимо, так как при нарушении зависимостей:
могут обнаружится такие текущие значения Ri, которые не удовлетворяют F, даже в случае, когда обладает свойством соединения без потерь;
каждое обновление Ri потребовало бы осуществления соединения для проверки выполнения ограничения целостности для отношения R в соответствии множествам зависимостей F.
Пример: дано R={G, A, I};G - город; A - адрес; I - индекс;
F={GAI, IG}
={R1, R2}, R1={A, I}, R2={I, G}
R1R2=I R2-R1=G IG
Декомпозиция обладает свойством соединения без потерь, но не обладает свойством сохранения зависимостей , поскольку , не может быть получена зависимость GAI.
№25) Определение многозначной зависимости.
Определение многозначной зависимости
Пусть дано отношение R и множество атрибутов X, Y, которые являются подмножеством R
X, Y R.
Говорят, что X мультиопределяет Y
f : X Y,
если заданному значению X соответствует множество, состоящее из или более значений Y, при чем Y значения никаким образом не связаны с множеством атрибутов R - X - Y. Если имеется многозначная зависимость, то для нее должны выполняться следующие условия.
Пусть существует два кортежа s и t в отношении R и XY, и пусть s [X] =t [X] , тогда должно существовать два других кортежа v и u таких, что:
u [X] = v [X] = s[ X] = t [X];
u [Y] = s [Y] u [R-X-Y] = t [R-X-Y];
v [Y] = T[Y] v [R-X-Y] = s [R-X-Y].
То есть, если поменять в кортежах s и t местами значения атрибутов множества Y, то получим два кортежа, которые также должны принадлежать отношению R.
Пример:
Пусть дана схема отношений R={C, T, H, S, G, A}, где C - курс; T - учитель; H - день недели и время; S - студент; G - оценка; A - аудитория, где проводятся занятия.
|
C |
T |
H |
S |
G |
A |
s |
1 |
Иванов |
понедельник - 900 |
Петров |
5 |
420 |
u |
1 |
Иванов |
понедельник - 900 |
Сидоров |
4 |
420 |
t |
1 |
Иванов |
среда - 1200 |
Петров |
5 |
421 |
v |
1 |
Иванов |
среда - 1200 |
Сидоров |
4 |
421 |
Рис. 29.
Здесь существует многозначная зависимость CHA.
Многозначные зависимости определяются только семантикой отношения.
№26) Аксиомы многозначных зависимостей.
Аксиома 4: (дополнения для многозначных зависимостей)
если XY, то XU-X-Y
Аксиома 5: (пополнение для многозначных зависимостей)
если XY VW, то XWVY .
Аксиома 6: (транзитивность для многозначных зависимостей)
если XY YZ , то XZ-Y
Существуют две аксиомы, связывающие многозначные зависимости с функциональными зависимостями.
Аксиома 7:
если X Y, то XY
то есть функциональная зависимость является частным случаем многозначной зависимости.
Аксиома 8:
если XY , ZY, W не пересекается с Y, WZ
то XZ .
№27) Многозначные зависимости. Базис зависимостей.
Многозначные зависимости - это зависимости между ключевыми атрибутами.
Теорема :
аксиомы 1 - 8 являются надежными и полными для функциональных и многозначных зависимостей .
Пусть D - множество функциональных и многозначных зависимостей, рассматриваемых на множестве атрибутов.
D+ - множество функциональных и многозначных зависимостей, выводимых из D, то есть каждое отношение на V, которое удовлетворяет D, удовлетворяет также зависимостям из D+, тогда D+ в точности является множеством зависимостей, которые выводятся из D по аксиомам 1 - 8.
Правила для многозначных зависимостей:
объединения
если X Y, XZ ,то XYZ;
псевдотранзитивности
если XY , WYZ ,то WXZ - WY;
смешанное правило транзитивности
если XY, XYZ ,то XZ - Y;
правило декомпозиции
если XY, XZ ,то X Y Z, X Y - Z, X Z - Y;
Теорема :
Пусть U - множество всех атрибутов, тогда можно построить разбиения множества U - X на подмножества Y1, Y2, ..., Yk, такие что для Z, являющимся Z U - X, имеем XZ если и только если Z являестся объединением некоторых Yi.
Множества Y1, Y2, ..., Yk называют базисом зависимостей для X относительно D.
Если имеем функциональные зависимости XZ , то Z{A1, A2,..., An} и базис Yi{A1, A2,..., An}.
Для функциональнызх зависимостей множество Yi состоит из одного атрибута, а для многозначных зависимостей множество Yi состоит из нескольких атрибуто
№28) Проверка свойства декомпозиции соединения без потерь информации для многозначных зависимостей.
Замыкание множества функциональных и многозначных зависимостей
Нахождение множеств D+ , логически выводимого из D, производится при помощи аксиом 1 - 8. Аксиомы применяются ко множеству D до тех пор, пока возможен вывод новых зависимостей.
Задача состоит в следующем: определить следует ли из D зависимость XY либо XY, этот процесс трудоемкий.
Для этого необходимо построить базис зависимостей для X. Если Y - X есть объединение каких-либо Yi, то данная зависимость принадлежит D+.
Для вычисления базиса зависимостей X относительно D достаточно найти базис относительно множества многозначных зависимостей M, которое состоит из:
из всех многозначных зависимостей D;
из привиденных функциональных зависимостей XZ к виду XY1, XY2, ..., XYl, где Yi { A1, A2,..., An }
Для вычисления базиса зависимостей существует алгоритм Бири.
Соединение без потерь
Данный алгоритм является обобщенным алгоритмом, учитывающим существование как функциональных, так и многозначных зависимостей.
Строим таблицу из величин a, b как в алгоритме проверки для функциональных зависимостей.
Строим совокупность функциональных таблиц, считая некоторую таблицу Т уже построенной и либо
а) отождествляем два символа вследствие функциональной зависимости как в аналогичном алгоритме, или
б) выбираем многозначную зависимость XY и две строки t1 и t2 таких, что t1[X] = t2[X], строим новую строку u такую, что
u [X] = t1[X] = t2 [X]
u [Y] = t1 [Y]
u [R - X - Y] = t2 [R - X - Y]
и добавляем ее в таблицу, если ее там еще нет.
так как мы не добавляем никаких новых a и b, то множество таких таблиц будет конечно. Если какя-либо из таблиц будет иметь строку, содержащую только а, то рассмотренная декомпозиция обладает свойством соединения без потерь.
Теорема :
Пусть R - схема отношения, - декомпозиция на два отношения R1 и R2 , а D - множество функциональных и многозначных зависимостей, то говорят, что декомпозиция обладает свойстом соединения без потерь, если :
(R1 R2 ) (R1 - R2)
(R1 R2 ) (R2 - R1)
№29) Зависимости соединения. J, ЕJ, ЕМV - зависимости.
Многозначные зависимости, справедливые для проекции любого вероятностного отношения r для R на подмножестве X, но не имеющего места в самом r называют встроенными многозначными зависимостями (EMV)..
X Y ( Z ), т.е. X мультиопределяет Y в контексте Z.
Пример:
R(C, BC, S, Y), где C - курс. BC - вспомогательный курс, S - студент, Y - год.
C |
BC |
S |
Y |
1 |
301 |
Петров |
1976 |
1 |
302 |
Петров |
1978 |
1 |
301 |
Сидоров |
1979 |
1 |
302 |
Сидоров |
1976 |
Рис. 30.
C B C (Y) или C S (Y)
Зависимости соединения (EJ,J)
Многозначные зависимости являются попыткой выделить декомпозицию, обладающую свойством соединения без потерь. В этом случае такая декомпозиция может обладать этим свойством для всех отношений декомпозиций, но не обладать им для некоторого подмножества отношений декомпозиции. Поэтому необходимо определить декомпозиции, которые обладают свойством соединения без потерь, то есть найти так называемые J - зависимости. Нахождение такой декомпозиции приводит к получению 5НФ (PJ - формы).
Многозначные зависимости являются частным случаем J - зависимости; J - зависимости являются частным случаем EJ - зависимости, встроенной зависимости соединения.
Отношение R имеет EJ - зависимость, если существует несколько проекций для этого отношения, обладающих J - зависимостями, но в целом отношение не удовлетворяет J - зависимости.
Для зависимостей соединения :(J и EJ - зависимостей) нет полной автоматизации. Выводимость для этого класса не разрешима.
№30) Назначение нормализации и этапы нормализации.
Нормализация – это разбиение отношения на два или более обладающими лучшими свойствами при включении модификации или удаление данных.
Окончательная цель нормализации – это получение такого проекта БД в которой каждый факт появляется лишь в одном месте, то есть max исключена избыточность информации (избыточность больше всего влияет не на объем памяти, а на удалении противоречивости данных).
Нормализованная таблица автоматически считается приведенной в 1 НФ. Таким образом, понятие «нормализованная» и находящаяся в 1НФ эквивалентны.
На практике термин нормализованная используется в смысле полной нормализации, то есть приведение к другим более высоким формам.
Каждая нормальная форма является более ограниченной, но и более желательной, чем предшествующая. Это связано с тем, что (N + 1) НФ не обладает положительными свойствами, характерными для N-ой формы. Общий смысл дополнительного условия, налагаемого на (N + 1) НФ по отношению к N состоит в исключении некоторых непривлекательных особенностей. Теория нормализации основывается на:
наличии зависимостей между полями, которые подразделяются на многозначные и функциональные.
Нормализация необходима для решения проблемы рационального выбора вариантов схем отношений из возможного множества альтернативных вариантов.
Схема отношений должна удовлетворять следующим требованиям:
выбранные для отношения первичные ключи должны быть минимальными; 2) выбранный состав отношений БД должен быть минимален, то есть отличаться минимальной избыточностью атрибутов;
при выполнении операций модификации, удаления и включения не должно быть трудностей;
перестройка набора отношений, приведение новых типов данных должна быть минимальной;
разброс времени ответа на различные запросы к БД должен быть небольшим.
Методы нормализации базируются на понятиях функциональных зависимостей, многозначных зависимостей и зависимостей соединения.
В ыделяют 7 этапов нормализации, соответственно 7 НФ:
-устранение повторяющихся групп
-
1 НФ
-устранение неполных функциональных зависимостей
-
2 НФ
-устранение транзитивных функциональных зависимостей
-
3 НФ
-устранение многозначных зависимостей
-
4 НФ
-устранение встроенных многозначных зависимостей
-
5НФ
- устранение J - зависимостей
-
6НФ
- устранение EJ – зависимостей
-
7
Рис. 31. Этапы нормализации.
НФ
№31) Определение 1НФ, 2НФ и приведение к 2НФ.
Отношение находится в 1НФ тогда и только тогда, когда ни одна из его строк не содержит в любом своем поле более одного значения и не одно из ключевых полей не пусто.
Таблица находится во 2НФ, если она удовлетворяет определению первой и все ее поля не входящие в первичный ключ связаны полной функциональной зависимостью с первичным ключом.

Ко 2НФ приведение заключается в необходимости произвести разбиение на несколько таблиц. В примере с поставщиками необходимо разбить на две: Поставщики и Города.
Поставщики
-
№
поставщик
город
Города
-
город
страна
Зависимость от части первичного ключа приводит к:
включение данных (пока не появится поставщик из Вильнюса нельзя зафиксировать, что это город Литвы)
удаление данных (исключение конкретного поставщика приводит к потере информации о местонахождении города)
обновление данных (при изменении названия страны приходится просматривать множество строк, поскольку много различных поставщиков живут в этой стране)
Для упрощения нормализации подобных таблиц целесообразно использовать рекомендацию: для проведения нормализации таблиц, в которых введены цифровые заменители составных или текстовых первичных ключей (внешних ключей) следует на время нормализации изменять их на исходные, а после окончания нормализации восстанавливать.
№32) Определение 3НФ и приведение к 3НФ. НФБК.
Определение 3НФ и приведение к 3НФ.
Таблица находится в 3НФ, если она удовлетворяет 2НФ и не одно из ее не ключевых полей не зависит функционально от другого не ключевого поля.
Для разбиения таблицы «Поставщики» все части этого проекта удовлетворяют определению 2НФ, а так как в них нет не ключевых полей, зависящих друг от друга, то все они находятся в 3НФ. Это не относится к таблице «Блюда», так как после ввода первичного ключа № блюда появились не ключевые поля с функциональными связями: Блюдо → Вид, Продукт → Калорийность.

-
№
Блюдо
Вид
Продукт
Калорийность
В этом случае приведение к 3НФ будет заключаться в разбиении на 4 таблицы.
Блюда (№, Блюдо);
Вид (№, Вид);
Продукт (№ прод., Продукт);
Калорийность (№ прод., калорийность).
Эта проблема, которая может возникнуть не только из-за введения кодированных первичных ключей, но и по другим причинам, решается посредством более строгого определения 3НФ. 3НФ имеет определение с помощью отсутствия транзитивных зависимостей
3НФ:
R → 3НФ, если не существует:
Ключа Х для R;
Множества атрибутов Y R;
Непервичного атрибута A из R
A X, Y, чтобы:
X → Y справедливо в R
Y → A справедливо в R, но
Y → Xне имеет смысла в R.