

Лабораторная работа № 5. Выбор удобочитаемого тематического текста из сети Интернет с помощью команд программы Microsoft Word.
Цель работы: научиться подбирать учебную литературу из сети Интернет, используя программу Microsoft Word, а также научится провдитьпроверку удобочитаемости и оценить уровень читателя, необходимый для чтения данного текста:
Задание 1. Найти в сети Интернет текст по теме: «Педагогика», провести проверку удобочитаемости и оценить уровень читателя, необходимый для чтения данного текста, а затем подсчитать, сколько раз в тексте присутствуют специальные термины. Результаты исследования занесите в таблицу, созданную во время выполнения предыдущей лабораторной работы. Сформулируйте и напечатайте вывод о тематической принадлежности текста.
Порядок выполнения задания.
Открыть окно программы Internet Explorer.
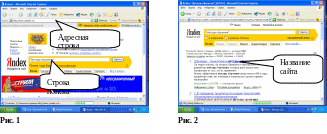
В строке адреса набрать адрес поисковой системы Яндекс: http://www.yandex.ru (Рис. 1).
Набрать в окне поиска слова «Методы обучения» (Рис. 1).
Я
 ндекс
выдаст список сайтов (Рис.2), который
можно прокрутить с помощью линейки
прокрутки справа (Рис.3).
ндекс
выдаст список сайтов (Рис.2), который
можно прокрутить с помощью линейки
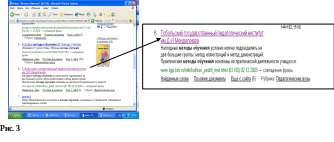
прокрутки справа (Рис.3).Выбрать первый подходящий сайт в списке сайтов, наведя на название курсор мыши и нажав ЛКМ. Откроется окно сайта, например, такое, как на рис 4.
Выделим текст статьи с помощью курсора мыши. (Рис.5)
Скопируем выделенный текст в буфер обмена.
О
 ткроем
новый документ программы Word.
ткроем
новый документ программы Word.Вставим скопированный текст в новый документ.
Сохраним документ.
Проверим удобочитаемость текста.
Откроем документ «Таблица», созданный при выполнении предыдущих лабораторных работ.
Занесем результаты в таблицу, записав в первом столбце название и адрес сайта.
Если уровень образованности для чтения данного текста меньше 8, не будем работать с этим текстом больше.
Е
 сли
образованности для чтения данного
текста больше 8, разбить последнюю
ячейку четвертой строки таблицы на
два столбца и пять строк.
сли
образованности для чтения данного
текста больше 8, разбить последнюю
ячейку четвертой строки таблицы на
два столбца и пять строк.
Завести в новый левый столбец построчно все термины «метод», «обучение», «педагогический процесс», «прием», «педагогическая задача», «педагог», «воспитание». (Можно скопировать).
Подсчитать количество вхождений терминов: «метод», «обучение», «педагогический процесс», «прием», «педагогическая задача», «педагог», «воспитание».
Занести результаты в таблицу.
Произвести поиск слов «Структура РСЧС» и «Средства индивидуальной защиты» и для найденных сайтов повторить пункты 5 – 18.
Напечатать вывод о тематической пригодности данных текстов.
Сохранить документ «Таблица»
Закрыть все окна.
Макрокоманды
Установка параметра проверки статистики удобочитаемости.
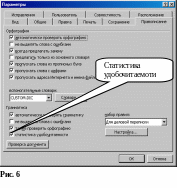
Для установки параметра проверки статистики удобочитаемости необходимо выполнить команду «Сервис» –> «Параметры» и перейти на вкладку «Правописание». В открывшемся окне (Рис.6) найти параметр «Статистика удобочитаемости» (Левый нижний угол), и, если в окошке левее надписи нет галочки, навести на это окошко курсор мыши и нажать ЛКМ. Галочка должна появиться.
Д алее
в тексте будем говорить: установите
параметр проверки статистики
удобочитаемости.
алее
в тексте будем говорить: установите
параметр проверки статистики
удобочитаемости.
Сбор статистики удобочитаемости. Для проверки правописания нужно выполнить команду «Сервис» –> «Правописание». Откроется окно, изображенное на Рис.7. Нажимая многократно на кнопку «Пропустить все», дождаться, пока на экране не появится окно «Статистика удобочитаемости» (Рис.8).
Выполнить сканирование и распознавание документов в программе Fine Reader 7.
Д ля
сканирования документа необходимо
включить сканер нажатием клавиши, если
сканер не включается сразу после
включения в сеть (это типичный случай).
Далее необходимо вставить лист в сканер
в направлении лампы. Затем запустить
программу Fine Reader.
ля
сканирования документа необходимо
включить сканер нажатием клавиши, если
сканер не включается сразу после
включения в сеть (это типичный случай).
Далее необходимо вставить лист в сканер
в направлении лампы. Затем запустить
программу Fine Reader.
Откроется окно программы, изображенное на рис. 9. В четвертой строке программы изображены пиктограммы основных операций:
S
 can&Read
– сканировать и распознать. Наиболее
часто используемый режим работы. Сканер
считывает картинку с изображением
текста в оперативную память,
а
затем программа распознает буквы в
изображении и предлагает распознанный
текст для проверки и правки, а затем
сохранении в выбранной программе
(Выбирайте лучше всего Microsoft Word и правку
делайте там же).
can&Read
– сканировать и распознать. Наиболее
часто используемый режим работы. Сканер
считывает картинку с изображением
текста в оперативную память,
а
затем программа распознает буквы в
изображении и предлагает распознанный
текст для проверки и правки, а затем
сохранении в выбранной программе
(Выбирайте лучше всего Microsoft Word и правку
делайте там же).Сканировать. Только сканирование изображения и сохранение в выбранной программе.
Распознать. Распознавание текста, который изображен на рисунке, ранее отсканированном и сохраненном в файле.
Сохранить. Сохранение результатов, если Вы ранее их не сохранили.
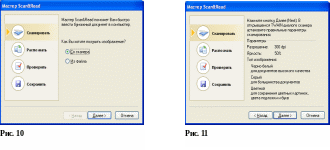
Д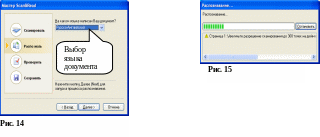 ля
стандартной работы наводите курсор
мыши на первую пиктограмму и нажимаете
ЛКМ. Открывается окно мастера сканирования
(Рис.10). Нажмите кнопку «Далее» (если
сначала нужно отсканировать лист).
Появится окно, изображенное на рис.11. В
окне представлены параметры сканирования,
которые предлагается установить в:
программе сканирования, рассчитанной
на конкретный тип сканера. Нажмите
кнопку «Далее». Появится окно с надписью
«Идет сканирование». Затем автоматически
запустится программа сканирования,
созданная специально для данного
устройства сканирования: TWAIN-драйвер.
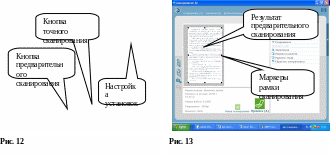
Для сканеров фирмы Hewlett Packard раскрывает
окно, представленное на рис.12. Все TWAIN –
драйверы обязательно имеют два типа
кнопок. Первый тип – кнопки настройки
сканирования, например, разрешения.
Второй тип – кнопки грубого и точного
сканирования. Сначала запускается
грубое сканирование автоматом или после
нажатия соответствующей кнопки (разные
TWAIN –драйверы по-разному устроены), а
затем после коррекции области сканирования
с помощью рамок, нажимается кнопка
точного сканирования.
ля
стандартной работы наводите курсор
мыши на первую пиктограмму и нажимаете
ЛКМ. Открывается окно мастера сканирования
(Рис.10). Нажмите кнопку «Далее» (если
сначала нужно отсканировать лист).
Появится окно, изображенное на рис.11. В
окне представлены параметры сканирования,
которые предлагается установить в:
программе сканирования, рассчитанной
на конкретный тип сканера. Нажмите
кнопку «Далее». Появится окно с надписью
«Идет сканирование». Затем автоматически
запустится программа сканирования,
созданная специально для данного
устройства сканирования: TWAIN-драйвер.
Для сканеров фирмы Hewlett Packard раскрывает
окно, представленное на рис.12. Все TWAIN –
драйверы обязательно имеют два типа
кнопок. Первый тип – кнопки настройки
сканирования, например, разрешения.
Второй тип – кнопки грубого и точного
сканирования. Сначала запускается
грубое сканирование автоматом или после
нажатия соответствующей кнопки (разные
TWAIN –драйверы по-разному устроены), а
затем после коррекции области сканирования
с помощью рамок, нажимается кнопка
точного сканирования.
TWAIN –драйвер фирмы Hewlett Packard для грубого сканирования запускается автоматически, точное сканирование запускается нажатием на кнопку «Принять»(Рис.12). Затем опять осуществляется возврат в программу Fine Reader, открывается окно мастера, который предлагает распознавание текста (Рис.14). В окне выбирается язык распознавания. Затем нажимается кнопка «Далее». Запускается программа распознавания текста. Она занимает некоторое время. В это время на экране находится окно, изображенное на рис. 15. Затем появляется окно, представленное на рис.16. Следует опять нажать кнопку «Далее». В окне, изображенном на рисунке 17 лучше отказаться от проверки текста в программе Fine Reader , для чего нужно навести курсор мыши на кнопку-кружок левее слова «Нет» и нажать ЛКМ. Затем опять нажимаем кнопку «Далее». Появляется окно, изображенное на рис.18. Программа предлагает сохранить отсканированный и распознанный текст в одной из перечисленных в списке программ. Следует выбрать программу Microsoft Word и нажать кнопку далее. На панели задач внизу экрана появится пиктограмма нового документа Word, а программа Fine Reader предложит повторить сканирование новой страницы. Положите в сканер новый лист и повторите все операции.Если сканирование закончилось, нажмите кнопку «Отмена».
П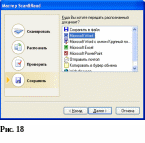 одсчет
количества вхождений заданного фрагмента
текста в документ.
одсчет
количества вхождений заданного фрагмента
текста в документ.
Д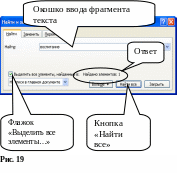 ля
подсчета вхождений некоторого заданного
слова, или заданного словосочетания,
или части слова в документ необходимо
выполнить команду
ля
подсчета вхождений некоторого заданного
слова, или заданного словосочетания,
или части слова в документ необходимо
выполнить команду
«Правка» –> «Найти». Откроется окно «Найти и заменить», похожее на представленное на рис. 8. Для того, чтобы сразу подсчитать количество вхождений заданного фрагмента текста, нужно установить флажок «Выделить все элементы, найденные в …», для чего следует навести курсор мыши на изображение флажка и нажать ЛКМ. В этом режиме появляется кнопка «Найти все». Далее следует в окошке ввода ввести искомый фрагмент, набрав текст с клавиатуры. Если в окошке ввода нет мигающего текстового курсора, следует навести курсор мыши на изображения окошка и нажать ЛКМ, а затем набрать текст. Осталось навести курсор мыши на кнопку «Найти все» и нажать ЛКМ. В окне в строке расположения флажка появится результат «Найдено элементов: »