

Метод эталонов
Метод эталонов (классификация) основывается на том что, с помощью обучающей выборки, изначально разделённой на классы, формулируется решающее правило, по которому происходит классификация новых данных. В общем случае решающее правило Y = F (X1,X2,...Xn) такое, что Y = 0 (метка класса) при принадлежности к первому классу (в нашем случае, кризис теплообмена), Y = 1 при принадлежности к другому классу (норма).
В нашей задаче эталонами являются - средние значения спектров "до" и "после" кризиса. Решающим правилом является минимальное расстояние от классифицируемого спектра до центров двух классов (по эталонам). Сравнивая эти расстояния (к какому центру класса расположен ближе классифицируемый спектр), классифицируем его соответствующим образом.
a←34↑[1]s
b←34↓[1]s
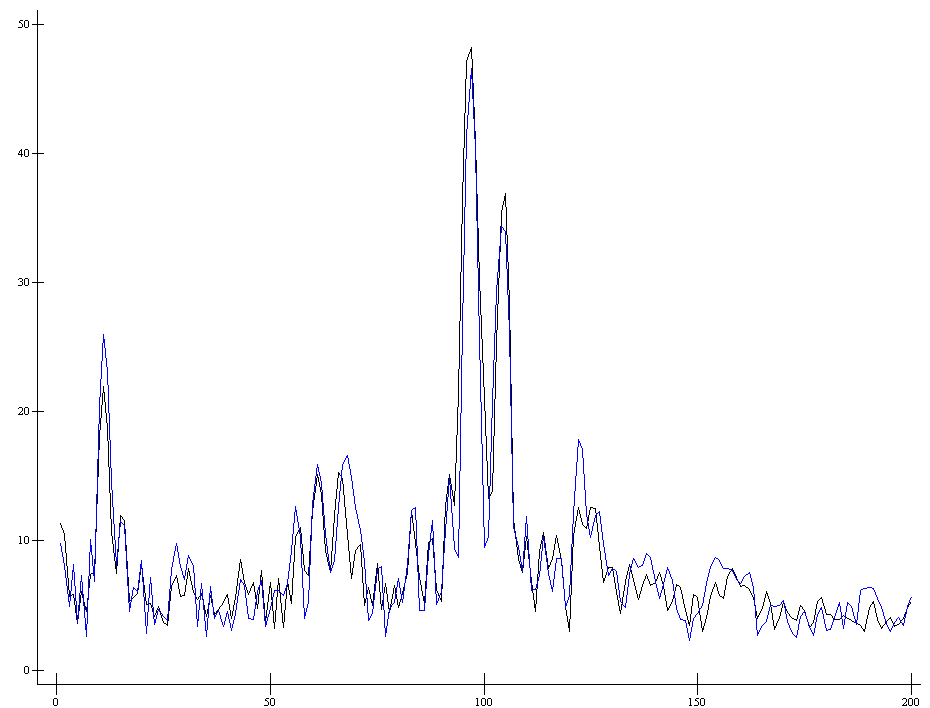
a1 ←(+/[1]a)÷34- средний спектр для нормы
b1← (+/[1]b)÷25 – средний спектр для кризиса
ap207.plot (⍳200)a1 b1
2⍕¨(⊂[2]s)dist a1 – расстояние от каждого спектра до эталона нормы
2⍕¨(⊂[2]s)dist b1 – расстояние от каждого спектра до эталона кризиса
Классификация по минимуму расстояний
Классификация по минимуму расстояний
c≠1+((⊂[2]s) dist a1)>(⊂[2]s) dist b1
1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 –сравнили с вектором C (1 – ошибка, 0 - совпадение)
ss1←(40⍴0 1)/[1]s – четные спектры
ss2←(40⍴1 0)/[1]s – нечетные спектры
∇EtalonLearn
[0] e←c EtalonLearn x;i
[1] e←⍳0
[2] i←1
[3] L:e←e,+/(c=i)/x÷+/c=i
[4] →((⌈/c)≥i←i+1)/L
[5] ∇
c1←(59⍴0 1)/c
⍴c1
29
c2←(59⍴1 0)/c
Обучение(четные спектры):
e←c1 EtalonLearn⊂[2] ss1
⍴e
2
⍴¨e
200 200
ap207.plot (⊂⍳200),e
– средние значения спектров до и после
кризиса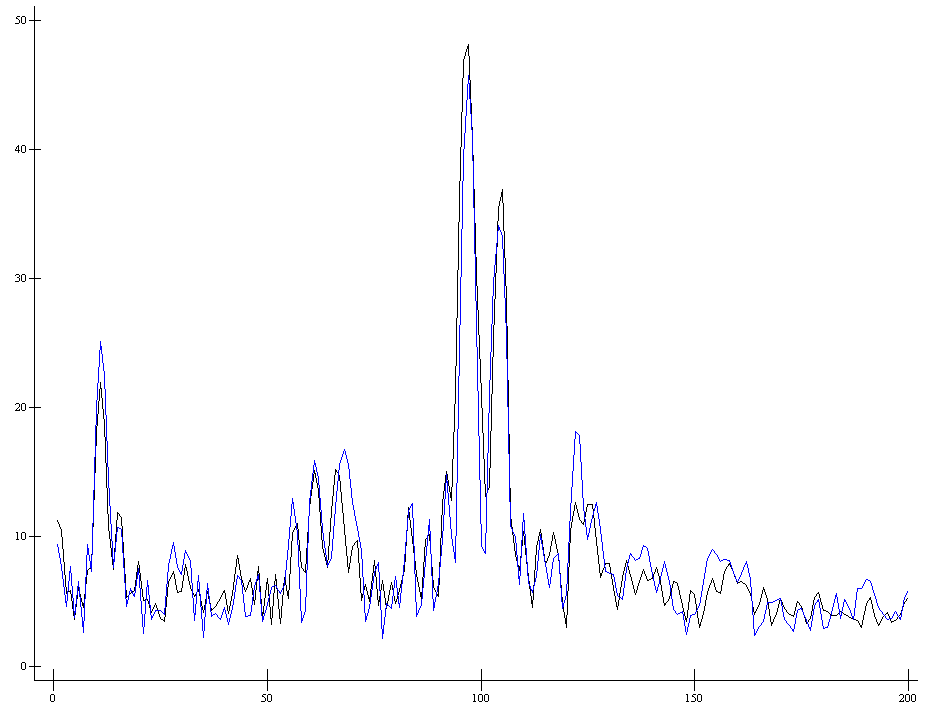
Классификация:
∇EtalonClass
[0] c←e EtalonClass x;r
[1] r←+/¨(e-⊂x)*2
[2] c←r⍳⌊/r
[3] ∇
cl←(⊂e) EtalonClass¨⊂[2]ss2
c2≡cl-совпадают ли вектора с и cl
0 -нет
+/c2≠cl – сколько ошибок
5
+/(c2=1)∧cl=2 – ложная тревога
3
+/(c2=2)∧cl=1 – пропуск цели
2
Метод Перцептрона
Необходимо подобрать такие коэффициенты, чтобы при умножении на них объектов одного класса 1 получался положительный результат R, а при умножении на них объектов второго класса 2 получался отрицательный результат R. Когда весовые коэффициенты задаются в первый раз, то их можно брать случайным образом, тут возможны следующие три варианта:
Если элементы класса 1 умноженные на «весы» дали положительный результат R, а элементы класса 2 умноженные на «весы» дали отрицательный результат, т.е. подтверждается их принадлежность к классам, то w’(k+1)=w(k) – весы остаются прежними.
Если элементы класса 1 умноженные на весы дали отрицательный результат, т.е. произошла ошибка, то мы можем ее исправить, если w’(k+1)=w(k)+cx(k).
Если элементы класса 2 умноженные на весы дали положительный результат, т.е. произошла ошибка, то мы можем ее исправить, если w’(k+1)=w(k)-cx(k).
Теперь проводим эксперимент N раз, т.е. до того момента, когда перемножив на веса элементы класса 1 и элементы класса 2 нам ни разу не пришлось их исправлять.
Обучение:
∇Perceptron
[0] w←c Perceptron x;i;w0;z
[1] x←x,¨1
[2] w←(⍴↑x)⍴0
[3] START:w0←w
[4] i←1
[5] L:z←w+.×i⊃x
[6] ⍎((c[i]=1)∧z≤0)/'w←w+i⊃x'
[7] ⍎((c[i]=2)∧z≥0)/'w←w-i⊃x'
[8] →((⍴x)≥i←i+1)/L
[9] →(~w≡w0)/START
[10] ∇
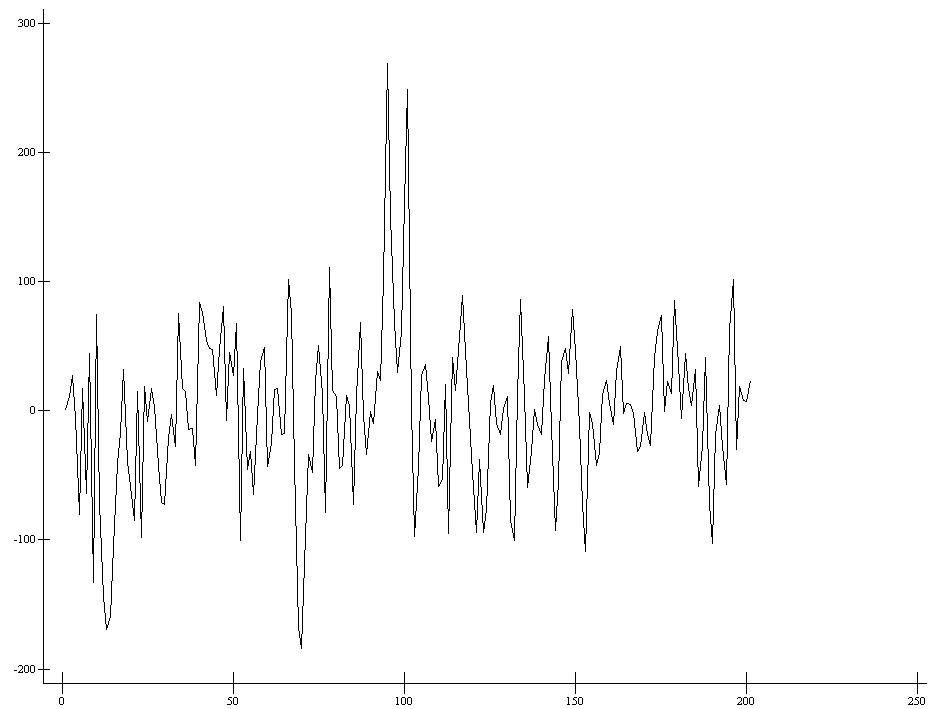
w←c1 Perceptron ⊂[2]ss1
⍴w
201
ap207.plot w
Классификация:
∇PerceptronClass
[0] c←w PerceptronClass x
[1] c←w+.×1,x
[2] c←1+c<0
[3] ∇
cl←(⊂w)PerceptronClass¨⊂[2]ss2
cl≡c2
1
+/cl≠c2 – количество ошибок
0
+/(c2=1)∧cl=2 - ложная тревога
0
+/(c2=2)∧cl=1 – пропуск цели
0