

Вопрос 1
Ответ 1
Вопрос 2
Ответ 2
Рис. 2. Выборочный каскад
Таким образом, два полученных ответа полностью снимают неопределенность. Подобная процедура позволяет определить количество информации в любом сообщении, интерпретация которого может быть сведена к парному выбору. Например, цепочке символов некоторого алфавита, использованного для представления сообщения.
На основе (15) нетрудно получить частное следствие для ситуации, когда все nисходов равновероятны. В этом случае
 , (16)
, (16)
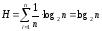 , (17)
, (17)
 . (18)
. (18)
Формула (18) была выведена еще в 1928 г. американским инженером Р.Хартли. Она связывает количество равновероятных событий n и количество информации в сообщении, что любое из этих событий произошло. Частным случаем применения формулы (18) приn=2kявляется
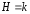 . (19)
. (19)
Пример: Случайным образом вынимается карта из колоды в 32 карты. Какое количество информации требуется, чтобы угадать, что это за карта?
Решение: Для данной ситуацииn=25, следовательно,k=5 иH=5 бит. Последовательность бинарных вопросов придумайте самостоятельно.
Попытаемся понять смысл полученных результатов. Необходимо выделить ряд моментов.
1. Формула (15) является статистическим определением понятия информация, поскольку в него входят вероятности возможных исходов опыта. По сути, мы даем операционное определение новой величины, то есть устанавливаем процедуру (способ) измерения величины. В науке (научном знании) именно такой метод введения новых терминов считается предпочтительным, поскольку то, что не может быть измерено, не может быть проверено и, следовательно, заслуживает меньшего доверия.
Если изначально исходов было n1, а в результате передачи информацииHнеопределенность уменьшилась и число исходов сталоn2 (очевидно,n2n1), то из (15) легко получить:
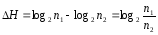 . (20)
. (20)
Таким образом, можно утверждать, что информация – это то, что понижает неопределенность некоторого опыта с неоднозначным исходом, причем соответствующее количество информации равно логарифму отношения числа возможных исходов до и после получения информации.
2. Энтропию, таким образом, можно определить как меру недостатка информации в системе; она выражает общее количество отсутствующей информации о структуре (строении) системы. Наибольшая энтропия у равновесной полностью беспорядочной системы – о состоянии такой системы наша осведомленность минимальна. Упорядочение системы (наведение какого-то порядка) связано с получением некоторой дополнительной информации и уменьшением энтропии.
3. Объективность информации. Одна и та же информация может иметь различную оценку с точки зрения значимости (важности, ценности) разными потребителями. Определяющей в такой оценке оказывается содержание (смысл) сообщения6. Однако при решении задач технического характера содержание сообщения роли не играет. Например, задача телеграфной (и любой другой) линии связи – точно и безошибочно передать сообщение без анализа того, насколько ценной для получателя оказывается переданная информация. Техническое устройство не может оценить важности информации – его задача безошибочно передать или сохранить информацию. Выше мы определили информацию как результат выбора. Такое определение является объективным,а связанная с ним количественная мера информации – одинаковой для любого потребителя. То есть появляется возможность объективного измерения информации, при этом результат измерения – абсолютен. Это служит предпосылкой для решения технических задач. Как мы увидим далее, количество информации можно связать с числом символов (букв) в сообщении. Мы уже говорили, чтоинформатика формулирует законы для формальных информационных процессов, то есть таких, где смысл и ценность информации выводится за рамки рассмотрения и никак не отслеживается. Это связано с тем, что нельзя предложить абсолютной и единой для всех меры ценности информации. С точки зрения информатики страница из учебника информатики или из «Войны и мира» и страница, записанная бессмысленными значками, содержат одинаковое количество информации. Другими словами, в теории информации информация отделяется от знания человека, которое связано с оценками смысла информации и которое не имеет количественной меры. По этой причине утверждение, что информация – это знание о чем-либо, является ошибочным в данном контексте. При этом, жертвуя смысловой (семантической) стороной информации, мы получаем объективные методы измерения количества информации, а также имеем возможность описывать информационные процессы математическими уравнениями. Это очень важно для решения проблем передачи, обработки и хранения информации с помощью технических устройств.
4. Пусть некоторый опыт имеет два исхода AиB, причем,pA=0,99 , аpB=0,01. В случае исходаAмы получим количество информацииHA= –log20,99=0,0145 бит. В случае исходаBколичество информации оказывается равнымHB= –log20,01=6,644 бит. Другими словами,больше информации связано с теми исходами, которые маловероятны. Действительно, то, что наступит именноAмы почти наверняка знали и до опыта; поэтому реализация такого исхода очень мало добавляет к нашей осведомленности. Наоборот, исходB– весьма редкий; информации с ним связано больше (осуществилось трудно ожидаемое событие). Однако такое большое количество информации мы будет при повторах опыта получать редко, поскольку мала вероятностьB. Среднее же количество информацииH=0,99HA+0,01HB0,081.
При передаче дискретных (текстовых) сообщений по каналу связи появление конкретного знака (буквы) в конкретном месте сообщения на приемном конце – событие случайное. Следовательно, узнавание (отождествление) знака требует получения некоторой порции информации. Попробуем оценить ее.
Сначала будем считать, что появление всех знаков (букв) алфавита в сообщении равновероятны. Тогда для английского алфавита ne=26. Для русского алфавитаnr=33. Из (18) имеем:
He=log226=4,700 бит,
Hr=log233=5,044 бит.
То есть при равновероятном распределении букв получается, что любой знак русского алфавита несет больше информации, чем знак английского. Например, русская «а» несет больше информации, чем «a» английская! Это, безусловно, не означает, что английский язык – язык Шекспира и Диккенса – беднее, чем язык Пушкина и Достоевского. Лингвистическое «богатство» языка определяется количеством слов в нем и их сочетаний, а это никак не связано с числом букв в алфавите. С точки зрения техники это означает, что сообщения из равного количества символов будет иметь разную длину (и соответственно, время передачи) и большими они окажутся у сообщений на русском языке.
Приведенные оценки информационной емкости букв соответствуют предположению об их одинаковой вероятности появления в сообщении. На самом деле это не так, и относительная частота появления в тексте разных букв различна (таблица 5).
|
Буква |
о |
е |
а |
и |
т |
н |
с |
р |
|
Отн.частота |
0,110 |
0,087 |
0,075 |
0,075 |
0,065 |
0,065 |
0,055 |
0,048 |
|
Буква |
в |
л |
к |
м |
д |
п |
у |
я |
|
Отн.частота |
0,046 |
0,042 |
0,034 |
0,031 |
0,030 |
0,028 |
0,025 |
0,022 |
|
Буква |
ы |
з |
ь,ъ |
б |
г |
ч |
й |
х |
|
Отн.частота |
0,019 |
0,018 |
0,017 |
0,017 |
0,016 |
0,015 |
0,012 |
0,011 |
|
Буква |
ж |
ю |
ш |
ц |
щ |
э |
ф |
|
|
Отн.частота |
0,009 |
0,007 |
0,007 |
0,005 |
0,004 |
0,003 |
0,002 |
|
Таблица 5. Средние частоты букв для русского алфавита.
Можно поставить вопрос: каково среднее количество информации, приходящее на один знак алфавита, с учетом не равной вероятности их появления в сообщении (текстах)? На основе (15) имеем:
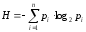 , (21)
, (21)
где pi– вероятность (относительная частота)i-го знака данного алфавита,H– средняя информация, приходящаяся на один знак.
Это и есть знаменитая формула К.Шеннона, с работы которого «Математическая теория связи», написанной в 1948 г., принято начинать отсчет возраста теории информации как самостоятельной науки7.
Необходимо заметить, что формула Шеннона справедлива только в том случае, если вероятность piдля данного знака одинакова в различных сообщениях. То, что это может быть не так, легко убедиться, если мы возьмем какое-либо короткое (с малым числом знаков) сообщение («Мама мыла раму»), то относительная частота букв не будет совпадать с приведенной в таблице 5. Поэтому вероятности знаков (относительные частоты) определяются для сообщений (текстов), содержащих много символов с тем, чтобы проявились статистические закономерности, неизменные с течением времени.
Сообщения, в которых вероятность появления знака не меняется с течением времени, называются шенноновскими. Теория информации строится именно для таких сообщений, поэтому в дальнейшем мы будем считать это исходным положением (условием применимости) теории.
Применение формулы (21) к алфавиту русского языка дает значение средней информации на знак H=4,460 бит, для английского языкаH=4,143 бит, для французскогоH=3.986 бит, для немецкогоH=4,096 бит. В этих оценках, как и в таблице 5, пробел не включен в алфавит, его включение приводит к коррекции данных таблицы и, соответственно, значенийH.
В любом случае, и для русского, и для английского языков учет вероятностей появления букв в сообщениях приводит к уменьшению среднего «информационного содержания» буквы, что, кстати, подтверждает справедливость формулы (11). Несовпадение значений средней информации для английского, французского и немецкого языков, основанных на одном алфавите, связано с тем, что частоты появления одинаковых букв в них различаются.
Значение средней информации на букву может быть еще уменьшено учетом корреляций, то есть связей между буквами в словах. Дело в том, что буквы в словах появляются не в любых сочетаниях; это понижает неопределенность угадывания следующей буквы после нескольких, например, в русском языке нет слов, в которых встречается сочетаниещцилифъ.И напротив, после некоторых сочетаний можно с большей определенностью, чем чистый случай, судить о появлении следующей буквы, например, после распространенного сочетанияпр- всегда следует гласная буква, а их в русском языке 10 и, следовательно, вероятность угадывания следующей буквы есть 1/10, а не 1/33. Учет в английских словах двухбуквенных сочетаний понижает среднюю информацию на знак до значенияH=3,32 бит, учет трехбуквенных – доH=3,1 бит; экстраполяция, позволяющая учесть все сочетания, дает значениеH=2,14 бит.
Введем величину, которую будем называть избыточностью языка:
 , (22)
, (22)
где H– средняя информация на знак при представлении информации с помощью алфавита данного языка, аHlim –предельнаянаименьшая информация на знак в данном языке. Исследования, проведенные Шенноном, показали, что для английского языкаHlim1,41,5 бит, что по отношению кH0=4,143 дает избыточность около 0,64. Это означает, что в принципе возможно почтитрехкратноесокращение языка без ущерба для его содержательной стороны и выразительности. Например, мы знаем, что в телеграммах используются сокращения «ЗПТ» и «ТЧК» вместо полных слов без ущерба для смысла. Однако такое «экономичное» представление слов снижает разборчивость сообщений и возможность понимания речи при наличии шума (а это одна из проблем передачи информации по реальным каналам связи).
Информационная избыточность естественных языков (и, соответственно, передаваемых сообщений) легла в основу подхода Шеннона к анализу криптозащищенных систем.