

2.2.1 Класифікація послідовних даних
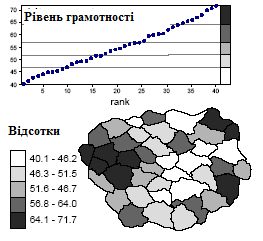
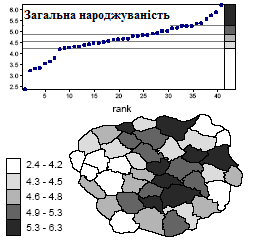
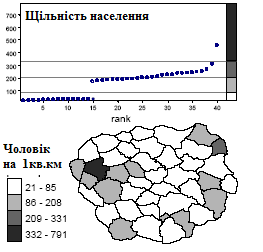
Один з простих методів класифікації полягає в розділенні області значень даних на рівні інтервали (рис. 2.16 - 2.18). Картограф спочатку визначає, яка кількість класів використовуватиметься. Після цього інтервал значень - максимальне мінус мінімальне - ділиться на число класів для отримання кроку розділення. До першого класу відносяться значення від мінімального до мінімального плюс крок, а подальші класи виходять збільшенням меж попереднього на один крок. Якщо в легенді межі приводяться з невеликим числом знаків, може потрібно округлення.
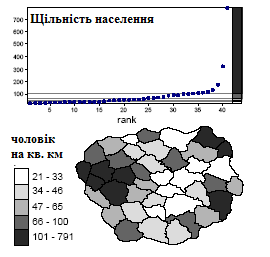
У разі щільності населення найменше число рівне 21, а найбільше - 791. Таким чином, довжина інтервалу змін рівна 770. Якщо ми хочемо ввести п'ять інтервалів, крок розділення буде рівний 770 / 5 = 154. Отже, перший клас лежить між 21 і 175, другий - між 176 і 329 і т.д.
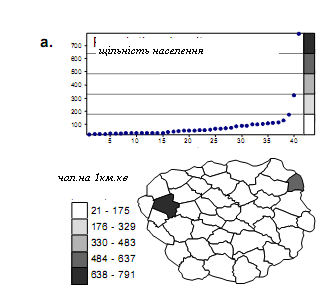
Рис. 2.16. Результат застосування класифікації за рівними інтервалами для картографування щільності населення
На прикладі карти щільності населення (рис. 2.16) видно, які проблеми можуть виникнути в цьому випадку. На вибір інтервалів сильний вплив зробило одне дуже велике число. Крок, що вийшов в результаті, настільки великий, що перший же клас містить всі крапки, окрім двох. Очевидно, що в цьому випадку ми одержимо карту з невисокою інформативністю.
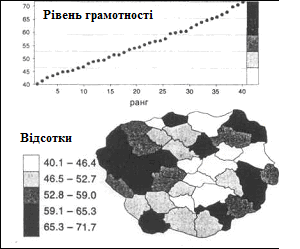
Рис. 2.17. Результат застосування класифікації за рівними інтервалами для картографування рівня грамотності
Цей же метод працює набагато краще у разі рівня грамотності, який розподілений рівномірніше. Множина даних ділиться на класи, що містять приблизно однакову кількість спостережень, і результуюча карта дає хороше уявлення про розподіл письменності по районах.
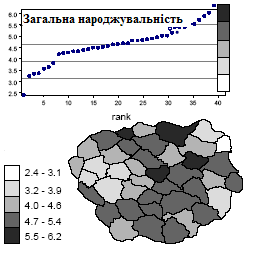
Нарешті, карта народжуваності (рис. 2. 18) демонструє приблизно ті ж проблеми, що і карта щільності населення, хоч і в меншому масштабі. У нижньому інтервалі міститься тільки одне спостереження, і на карті в деякому розумінні домінують значення середніх інтервалів. Проте по збігу в даному випадку межі між другим і третім і між четвертим і п'ятим класами достатньо точно потрапили на розрив в розподілі даних.
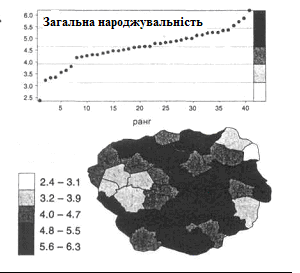
Рис. 2.18. Результат застосування класифікації за рівними інтервалами для картографування народжуваності
Окрім рівних інтервалів існують інші методи класифікації послідовних даних. У одному з них пропонується використовувати геометричну прогресію, наприклад 0-2, 2-4, 4-8, 8-16 і т.д. Цей підхід може дати добрі результати у разі змінних з асиметричним розподілом, наприклад для щільності населення.
2.2.2 Статистична класифікація даних
Один з методів класифікації полягає в тому, щоб вибирати інтервали, що містять приблизно рівну кількість спостережень. Це можна зробити, використовуючи статистичне поняття квантилів, які ділять множину даних на класи, з однаковим числом спостережень. Якщо класів чотири, вони називаються квартілямі, якщо класів п'ять - квантилями і т.д.
Для того, щоб розрахувати квантилі, кількість спостережень ділиться на вибране число класів і при необхідності округляється до найближчого цілого п. Потім на ранговому графіку перші п спостережень відносяться до першого класу, наступні п - до другого і т.д. Відхилення, що виникли за рахунок округлення, відносяться до першого або останньому класу.
Метод тематичного картографування за квантилями реалізований в багатьох ГІС, тому він набув велику популярність при виробництві карт.
Приведені три приклади (рис. 2.19) виглядають цілком прийнятними. Завдяки вдалому розподіленню даних між класами всі карти добре використовують весь діапазон відтінків сірого.
|
|
|
|
|
Рис. 2.19. Результат застосування класифікації за квантилями для картографування щільності населення, рівня грамотності та народжуваності | ||
Карта розподілу даних класифікація для рівня грамотності виглядає цілком прийнятною. Насправді ця карта лише трохи відрізняється від карти з використанням методу рівних інтервалів.
Проте у разі карт щільності населення і народжуваності можна бачити, що метод може поміщати близькі значення змінної в різні класи. Наприклад, у разі народжуваності два спостереження, що мають найбільші значення в нижньому класі (2,4-4,2), набагато ближче до спостережень другого класу, чим першого. Більш того, з трьох спостережень, що мають значення 5,3, одне приписується до четвертого класу, а два - до п'ятого (деякі ГІС пом'якшують умову рівних кількостей спостережень, щоб уникнути таких випадків).
Тому карти з використанням квантилів слід застосовувати з обережністю. Досить часто близькі значення можуть опинитися в різних класах, а далекі один від одного - в одному. І не дивлячись на те, що одержані карти виглядають цілком прийнятними, враження може бути недостовірним.
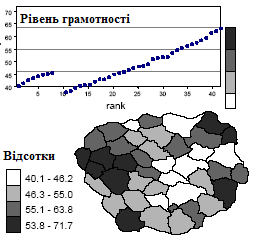
Ще один метод статистичної класифікації заснований на загальних характеристиках розподілу даних. Один з варіантів полягає в тому, щоб визначати межі класів з використанням стандартного відхилення, що оцінюється за розподілом змінної. Стандартне відхилення обчислюється як квадратний корінь з дисперсії. Дисперсія рівна середньому квадрату відхилення значень змінної від її глобального середнього. Наприклад, для рівня грамотності стандартне відхилення дорівнює 8.9.
Отже, класи, засновані на стандартному відхиленні, показують, як окремі спостереження, наприклад райони, співвідносяться з середнім значенням для всієї області або країни.
Класи одержують, додаючи стандартне відхилення до середнього або віднімаючи його від середнього значення (для рівня грамотності середнє дорівнює 55). Таким чином, ширина всіх класів однакова, як і в методі рівних інтервалів.
Для рівня грамотності перший клас (40.1 - 46.2) відповідає значенням, який менше середнього на величину від одного до двох стандартних відхилень. Оскільки розподіл змінної даних компактний, всі значення лежать в межах плюс/мінус два стандартні відхилення від середніх, і потрібно тільки чотири класи. Як видно з рис. 2.20, ця процедура ділить значення рівня грамотності на класи, що містять приблизно рівну кількість спостережень, що дає карту з хорошим візуальним контрастом.
|
|
|
|
|
Рис. 2.20. Результат застосування класифікації на основі стандартного відхилення для картографування щільності населення, рівня грамотності та народжуваності | ||
Проте у разі щільності населення такий підхід дає набагато гірші результати. Із-за присутності великого числа малих значень, середня щільність населення досить низька (82.4), при цьому стандартне відхилення достатньо велике (124.8). В цьому випадку перший клас, відповідний значенням, що відрізняються від середнього на одне стандартне відхилення в меншу сторону, повинен був би лежати між 39.5 і 84. З іншого боку, максимальне значення (791) відрізняється від середнього більш ніж на п'ять стандартних відхилень, і нам довелося б вводити багато додаткових класів, більшість з яких виявилася б порожньою. Натомість в максимальний клас для цієї карти включені всі значення, що відхиляються від середнього більш ніж на одне стандартне відхилення. Очевидно, що для цього показника використання стандартного відхилення не можна вважати вдалим.
У разі народжуваності стандартне відхилення працює трохи краще. Тут середнє дорівнює 4.6, а стандартне відхилення дорівнює 0.8. Проте в саму нижню категорію (віддалену більш ніж на два стандартні відхилення від середніх) потрапляє тільки одне дуже маленьке число 2.4.
Метод класифікації з використанням стандартного відхилення інтуїтивно привабливий із-за тісного зв'язку з методами статистики. Він добре працює з нормально розподіленими даними, що мають відносно низьку дисперсію, так що всі дані укладаються не більше ніж в шість класів.
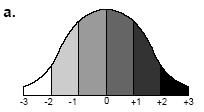
Стандартні відхилення можна використовувати для відображення різного роду трендів в множині даних (рис 2.21). У прикладах, приведених на рис 2.20, використовується шкала відтінків сірого - від світлого до темного. Карта може підкреслювати зміну щільності населення, рівня грамотності або темпів народжуваності від низьких значень до високих відповідно до поділу на класи, як показано на рис 2.21 а. Слід відмітити, що це найбільш рідкісний варіант використання класифікації із застосуванням стандартного відхилення.
|
|
|
|
|
Рис. 2.21. Призначення кольору класам, що визначені з використанням стандартного відхилення | ||
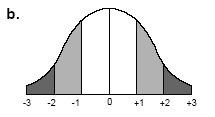
Частіше цей метод використовується, щоб підкреслити тенденції, пов'язані з відхиленнями. Наприклад, при оцінці рівнів доходу нам може знадобитися виділити найбідніші і найбагатші райони. В цьому випадку ми можемо використовувати яскраві кольори або інтенсивні текстури для значень, що відхиляються від середнього більш ніж на одне або два стандартні відхилення, а для значень в центрі розподілу використовувати приглушені тони (рис.2.21 b).
Якщо нас цікавить тільки відстань від середньої, незалежно від того, чи лежать значення вище або нижче за середнє, можна використовувати одні і ті ж кольори з обох боків. Якщо ж бажано розрізняти значення вище або нижче за середнє, то повинні розрізнятися кольори або текстури з різних сторін від середнього. Наприклад, на карті, віддрукованій в кольорі, для класів нижче за середнє можна використовувати відтінки червоного від світлого до темного, а для класів вище за середнього відповідні сині тони.
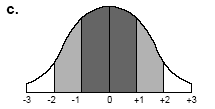
В деяких випадках може знадобитися виділити середні інтервали (рис.2.21 с). Наприклад McEachrco (1994) розглядав карту Північної Ірландії, опубліковану Fothergill and Vincent (1985), на якій показано розподіл процентного співвідношення протестантів і католиків. На цій карті значення, близькі до 50%, що означають приблизну рівність чисельності протестантів і католиків, виділені яскравим кольором (жовтим). Території, в котрих явно переважають або католики, або протестанть забарвлені в більш приглушені тони (зелений і оранжевий, відповідно).