

3. Информация
3.1. Основные понятия
Все формулировки информации основаны на том, что это динамический объект, не существующий в природе сам по себе, а образующийся в ходе взаимодействия материальных объектов, описываемых количественными данными. Он существует ровно столько, сколько длится это взаимодействие, а все остальное время пребывает в виде количественных данных. Приведём некоторые из формулировок этого понятия.
Информация – это нематериальная сущность, при помощи которой можно описывать все явления материального мира.
Информация – отражение предметного мира, выражаемого в виде сигналов и знаков.
Информация – это некоторые сведения, совокупность каких-либо данных, знаний.
Согласно Федеральному закону РФ «Об информации, информационных технологиях и о защите информации»:
«1) информация – сведения (сообщения, данные) независимо от формы их представления;
2) информационные технологии – процессы, методы поиска, сбора, хранения, обработки, предоставления, распространения информации и способы осуществления таких процессов и методов»;
В некоторых законодательных актах, например, в статьях УК РФ по преступлениям в сфере компьютерной информации, приводится определение «компьютерная информация». Понятие этого определения дается в Соглашении о сотрудничестве государств – участников Содружества Независимых Государств в борьбе с преступлениями в сфере компьютерной информации (от 1 июня 2001 г.). Согласно пункту б) статьи 1 названного Соглашения компьютерная информация – это информация, находящаяся в памяти компьютера, на машинных или иных носителях в форме, доступной восприятию ЭВМ, или передающаяся по каналам связи.
К настоящему времени сложилось два подхода к понятию информация: алфавитный и содержательный.
Согласно алфавитному подходу информация – это некоторые сведения, совокупность каких-либо данных, знаний.
Согласно содержательному подходу информация – это нематериальная сущность, отражение предметного мира, выражаемого в виде сигналов и знаков.
3.2. Основные единицы измерения информации
В информатике и вычислительной технике принята система представления данных двоичным кодом. Наименьшей единицей такого представления является бит.
Бит – это бинарная единица, которая может принимать два значения: 0 или 1.
Существуют другие, более крупные единицы измерения информации.
Байт – это группа взаимосвязанных битов. 1 байт = 8 бит.
1 Килобайт (Кб)=210 байт = 1024 байт.
1 Мегабайт (Мб) = 1024 Кб.
1 Гигабайт (Гб) =1024 Мб.
1 Терабайт (Тб) = 1024 Гб.
Кроме перечисленных есть другие, более крупные единицы измерения информации.
Скорость передачи информации измеряется в битах в секунду и бодах. Бит/сек – это скорость передачи непосредственно самой информации, а бод – скорость передачи сигнала (характеризует быстродействие устройства, передающего информацию, например, модема).
3.3. Расчёт количества информации
При алфавитном подходе к понятию информация под количеством информации, содержащемся в текстовом сообщении, подразумевается размер этого сообщения, выраженный в битах или других единицах измерения информации.
Дл определения количества информации необходимо подсчитать количество символов, содержащихся в текстовом сообщении (включая цифры, пробелы, знаки препинания и пунктуации). Один символ текстового сообщения будет соответствовать определённому количеству байт, принятому в данной кодировке. В русскоязычном тексте один символ, как правило, кодируется одним байтом. Поэтому количество информации в тексте будет соответствовать количеству подсчитанных символов.
Пример. Считая, что один символ кодируется одним байтом, определить, чему равен информационный объём в битах и в килобайтах следующего предложения:
Информация это сведения независимо от формы их представления.
Решение. После подсчёта в данном предложении оказалось 63 символа, т.е. информационный объём предложения равен 63 байтам. Для перевода байтов в биты, необходимо 63 байта умножить на 8 и в результате будет получено 504 бита. Для того чтобы перевести байты в килобайты, 63 байта нужно разделить на 1024, в результате чего будет получено 0,0615234375 килобайта.
В теории информации понятие количества информации связано со степенью новизны сведений о каком-то событии, которая, в свою очередь, является следствием неопределенности исхода этого события.
Однако если исход какого-либо события состоит из N равновероятных вариантов, то количество информации, которое содержится в нём, можно вычислить по формуле, предложенной в 1928 г. американским инженером Р. Хартли:

где I – количество информации; N – количество равновероятных вариантов исхода какого-либо события.
Иными словами при равновероятных вариантах исхода какого-либо события количество информации равно степени, в которую необходимо возвести 2, чтобы получить число равновероятных вариантов, т.е. 2I = N.
При равновероятных вариантах исхода какого-либо события для того чтобы определить количество информации, содержащейся в этом событии, достаточно задать минимальное количество элементарных вопросов, для того чтобы выведать эту информацию. Ответ, на задаваемый вопрос, «да», или «нет» будет являться 1 битом информации.
Примеры:
1. Сколько информации содержит в себе сообщение о выпадении «орла» или «решки» после подбрасывания монеты?
Ответ: 1 бит.
2. В игре участвовал 1 игрок. Сколько информации несёт в себе сообщение о победителе?
Ответ: 0 бит.
3. В игре участвовало 4 игрока. Сколько информации несёт в себе сообщение о победителе?
Ответ: 2 бита.
Так как каждый из вариантов (событий) имеет равновероятный исход p = 1/N, то отсюда N = 1/p. Здесь p – вероятность события. Тогда формулу Хартли можно записать так:
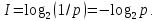
При расчётах по формуле Хартли не учитывается возможность того, что варианты исхода какого-либо события могут иметь разную вероятность. Даже при подбрасывании монеты существует вероятность, хотя и незначительная, что монета после падения может встать на ребро.
В 1948 г. американский инженер и математик К Шеннон предложил формулу для вычисления количества информации для событий с различными вероятностями [32]. Вероятностный подход к расчёту количества информации основан на понятии энтропии в смысле К. Шеннона.
Энтропия дискретной случайной величины (мера неопределённости) – это минимум среднего количества бит, которое нужно передать по каналу связи о текущем состоянии данной дискретной случайной величины. Рассчитывается по формуле:
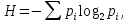
где pi – вероятность события.
При вероятностном подходе, предложенном К. Шенноном, для расчёта количества информации используются следующие формулы.
Для одной дискретной случайной величины X, заданной законом распределения pi:
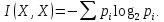
Для дискретных случайных величин X и Y, заданных законами распределения pi, qj и их совместным распределением pij, количество информации содержащейся в X относительно Y равно:
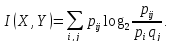
Данная формула учитывает то обстоятельство, что, например, в каком-либо текстовом сообщении некоторые символы или слова могут иметь разную вероятность их появления, зависящую от предыдущего символа или слова. В некотором предложении после слова «передовик», вероятнее всего, последует слово «производства».
Пример: Найти количество информации, содержащееся в следующем текстовом сообщении, состоящем из 551 буквы.
Информация это те сведения, которые помогают ориентироваться в окружающем нас мире. В настоящее время информация нужна как воздух, вода и пища. Но если в предыдущие века человек имел дело только с «ручейками» информации, то теперь его окружают бездонные «моря» разнообразных сведений, способные поглотить необразованного специалиста в своих пучинах. Легко преодолеть ручей. Но чтобы переплыть море, нужны корабли и навигационные карты, нужна наука о кораблях и кораблевождении. «Информатика» это наука о навигации в «Тихом океане» информации, а электронные вычислительные машины (компьютеры) океанские лайнеры, покоряющие информационные просторы.
Решение:
1. Находим закон распределения букв, содержащихся в заданном текстовом сообщении (см. табл. 1).
Таблица 1 – Распределение букв, содержащихся в заданном текстовом сообщении
|
Буква |
а |
б |
в |
г |
д |
е |
ж |
з |
и |
й |
к |
|
Количество данной буквы в тексте |
44 |
8 |
19 |
7 |
10 |
51 |
6 |
5 |
46 |
4 |
23 |
|
p |
0,08 |
0,01 |
0,03 |
0,01 |
0,02 |
0,09 |
0,01 |
0,01 |
0,08 |
0,01 |
0,04 |
|
Буква |
л |
м |
н |
о |
п |
р |
с |
т |
у |
ф |
|
|
Количество данной буквы в тексте |
17 |
17 |
44 |
62 |
14 |
34 |
15 |
25 |
12 |
6 |
|
|
p |
0,03 |
0,03 |
0,08 |
0,11 |
0,03 |
0,06 |
0,03 |
0,05 |
0,02 |
0,01 |
|
|
Буква |
х |
ц |
ч |
ш |
щ |
ы |
ь |
э |
ю |
я |
|
|
Количество данной буквы в тексте |
6 |
8 |
6 |
1 |
5 |
18 |
8 |
3 |
5 |
9 |
|
|
p |
0,01 |
0,01 |
0,01 |
0,00 |
0,01 |
0,03 |
0,01 |
0,01 |
0,01 |
0,02 |
|
Примечание: p = количество данной буквы в тексте / общее количество букв.
2. Рассчитываем количество информации:
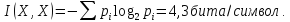
Ответ: В заданном текстовом сообщении содержится информации 4, 3 бита/символ.
3.4. Кодирование информации
Информация передается с помощью языков в виде непрерывных и дискретных сигналов. Основа любого языка – алфавит, т.е. конечный набор знаков (символов) любой природы, из которых конструируются сообщения на данном языке. Алфавит может быть латинский, русский, десятичных чисел, двоичный и т.д.
Кодирование – это представление символов одного алфавита символами другого. Простейшим алфавитом, достаточным для кодирования любого другого, является алфавит, состоящий из двух символов 0 и 1, т. е. двоичный алфавит.
При кодировании буквам алфавита ставится в соответствие числовой код, обычно в десятеричной или шестнадцатеричной системах счисления. Буквы и соответствующие им коды хранятся в специальных таблицах, которые называются таблицами кодировок. Одной из распространённых таблиц кодировок является ASCII (American Standard Code for Information Interchange). В этой таблице русская буква А, например, кодируется числом 128 в десятичной системе счисления, а закодированное слово «информация» в двоичной системе счисления будет состоять из 80 бит: 10101000 10101101 11100100 10101110 11100000 10101100 10100000 11100110 10101000 111011111.
Для кодирования русских букв используются следующие таблицы кодировок:
KOI8-R – вариант кодировки КОИ-8 (KOI8) для описания русского алфавита (КОИ-8 – код обмена информацией, 8 битов. Это восьмибитовая ASCII-совместимая кодовая страница, разработанная для кодирования букв кириллических алфавитов);
Windows-1251 набор символов и кодировка, являющаяся стандартной 8-битной кодировкой для всех русских версий Microsoft Windows;
Unicode (Юникод или Уникод) – стандарт кодирования символов, позволяющий представить знаки практически всех письменных языков, в которой для кодирования символов отводится от 1 до 6 бит на символ;
ISO 8859-5 – 8-битная кодовая страница из семейства кодовых страниц стандарта ISO-8859 для представления кириллицы. Устанавливается на некоторых иностранных системах для русского языка и др.
При сжатии и передаче информации по каналам без шума применяется эффективное кодирование, которое базируется на основной теореме К. Шеннона для каналов без шума. В этой теореме К. Шеннон доказал, что сообщения, составленные из букв некоторого алфавита, можно закодировать так, что среднее число двоичных символов на букву будет сколь угодно близко к энтропии источника этих сообщений, но не меньше этой величины.
Сущность эффективного кодирования заключается в том, что, учитывая статистические свойства какого-либо сообщения, можно минимизировать среднее число двоичных символов, требующихся для выражения одной буквы сообщения, что при отсутствии шума позволяет уменьшить время передачи или объем запоминающего устройства. Этот вид кодирования используется в архиваторах для сжатия информации. К числу эффективных кодов относятся коды: Шеннона-Фэно, Хаффмана и другие.
Пример. Построить эффективный код для сообщения в виде слова «информация».
Решение. Для построения кода воспользуемся методикой Шеннона-Фэно. По этой методике код строится следующим образом. Буквы алфавита сообщений выписываются в таблицу в порядке убывания вероятностей (см. табл. 2). Затем они разделяются на две группы так, чтобы суммы вероятностей в каждой из групп были по возможности одинаковы (см. табл. 3). Всем буквам верхней половины в качестве первого символа приписывается 1, а всем нижним – 0. Каждая из полученных групп разбивается на две подгруппы с одинаковыми суммарными вероятностями и т. д. Процесс повторяется до тех пор, пока в каждой подгруппе останется по одной букве.
Таблица 2 – Таблица статистического распределения букв
|
Буква |
и |
н |
ф |
о |
Р |
м |
а |
ц |
я |
|
p |
2/10 |
1/10 |
1/10 |
1/10 |
1/10 |
1/10 |
1/10 |
1/10 |
1/10 |
Таблица 3 – Таблица кодирования
|
и |
2/10 |
1 |
1 |
|
|
|
н |
1/10 |
1 |
0 |
1 |
|
|
ф |
1/10 |
1 |
0 |
0 |
1 |
|
о |
1/10 |
1 |
0 |
0 |
0 |
|
р |
1/10 |
0 |
1 |
1 |
|
|
м |
1/10 |
0 |
1 |
0 |
|
|
а |
1/10 |
0 |
0 |
1 |
|
|
ц |
1/10 |
0 |
0 |
0 |
1 |
|
я |
1/10 |
0 |
0 |
0 |
0 |
Ответ: и – 11; н – 101; ф – 1001; о – 1000; р – 011; м – 010; а – 001; ц – 0001; я – 0000.
Таким образом, в двоичном виде закодированное с помощью кода Шеннона-Фэно слово «информация» будет содержать 30 бит и выглядеть так: 111011001100001101000100010000 (30 бит).
3.5. Помехозащитное кодирование
Помехоустойчивое кодирование базируется на основной теореме К. Шеннона для дискретного канала с шумом. Эта теорема заключается в следующем: при любой скорости передачи двоичных символов меньшей, чем пропускная способность канала, существует такой код, при котором вероятность ошибочного декодирования будет сколь угодно мала. Вероятность ошибки не может быть сделана произвольно малой, если скорость передачи больше пропускной способности канала.
При помехозащитном кодировании в код вводится избыточность, которая позволяет так выбрать передаваемые последовательности символов, чтобы они удовлетворяли дополнительным условиям, проверка которых на приемной стороне дает возможность обнаружить и исправить ошибки.
Помехозащитные коды используются как для исправления ошибок (корректирующие коды), так и для их обнаружения.
К числу помехозащитных кодов относятся: код Хэмминга, полиноминальные, циклические избыточные CRC-коды (Cyclical Redundancy Check) и другие
CRC-коды используются очень широко: модемами, телекоммуникационными программами, программами архивации и проверки целостности данных, в сотовых телефонах и многими другими программными и аппаратными компонентами вычислительных систем.