

0 Запрещенные кодовые комбинации00
111
110
101
011
Тогда по принятой комбинации 011 и факту её попадания в запрещенную кодовую комбинацию ошибка будет обнаружена, а зная, что подмножество запрещенных комбинаций соответствует разрешенной комбинации 111, мы можем исправить принятую комбинацию на разрешенную. Код при этих условиях обладает свойствами исправления ошибок. В общем случае для обеспечения возможности исправления всех ошибок кратности до t включительно при декодировании при методе максимального правдоподобия, каждая из ошибок декодирования должна приводить к запрещенной комбинации, относящейся к подмножеству исходных разрешенных кодовых комбинаций:
![]() -
граница
исправления ошибок кратностью t.
-
граница
исправления ошибок кратностью t.
Общая граница обнаружения и исправления ошибок с соответствующей кратностью:
![]() .
.
Таким образом, задача построения помехоустойчивой корректирующей способностью сводится к обеспечению необходимого минимального кодового расстояния. Увеличение минимального кодового расстояния приводит к росту избыточности кода, при этом желательно, чтобы число проверочных символов было минимальным. Это противоречие разрешается через определение верхней и нижней границ числа проверочных символов.
В настоящее время известен ряд границ, которые устанавливают взаимосвязь между кодовым расстоянием и числом проверочных символов. Кроме того, эти границы позволяют определить вероятность ошибки декодирования.
Граница Хемминга находится из соотношения известного для числа разрешенных комбинаций:
![]() ,
где
n=k+r
– число символов; t
=
,
где
n=k+r
– число символов; t
=![]() - кратность исправляемых ошибок;
- кратность исправляемых ошибок; -
число сочетаний из n
по i.
-
число сочетаний из n
по i.
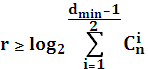
Применение
границы Хемминга дает результаты близкие
к оптимальным для высокоскоростных
кодов ![]() > 0,3.
> 0,3.
Для
низкоскоростных кодов, т.е. R
=![]() ≤ 0,3, границу числа проверочных символов
называют границей
Плоткина:
≤ 0,3, границу числа проверочных символов
называют границей
Плоткина:
![]()
Граница Варшамова – Гильберта:
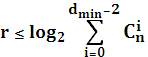
Таким образом, граница Хемминга и Плоткина определяют необходимое количество проверочных символов, а граница Варшамова- Гильберта достаточное их количество.
Если количество проверочных символов выбрано так, что оно удовлетворяет эти границам, то код считается близким к оптимальному.
Коды, в которых число проверочных символов выбирается равным границам Хемминга или Плоткина называется совершенным или полноупакованным.
5.3.Линейные (систематические) коды.
5.3.1.Механизмы кодирования и синдромного декодирования.
В линейных систематических кодах информационные символы при кодировании не изменяются, а проверочные символы получаются в результате суммирования по модулю 2 определенного числа информационных символов.
Запишем
некоторые разрешенные кодовые комбинации
систематического кода (n,
k)![]() ,
где
,
где ![]() -
информационные символы;
-
информационные символы; ![]() -
проверочные символы.
-
проверочные символы.
Тогда
![]() ,
где
,
где ![]() - некоторый коэффициент принимающий
значение 0 или 1 в зависимости от того,
участвует или нет данный информационный
символ
- некоторый коэффициент принимающий
значение 0 или 1 в зависимости от того,
участвует или нет данный информационный
символ ![]() в формировании проверочного символа
в формировании проверочного символа
![]() .
.
Обнаружение и исправление ошибок систематическим кодом сводится к определению и последующему анализу синдрома или вектора ошибок.
Под
синдромом понимают некую совокупность
символов ![]() сформированную, путем сложения по
модулю 2 принятых проверочных символов
и вычисленных проверочных символов.
Вычисленные проверочные символы
получаются из принятых информационных
символов
сформированную, путем сложения по
модулю 2 принятых проверочных символов
и вычисленных проверочных символов.
Вычисленные проверочные символы
получаются из принятых информационных
символов ![]() по
тому же правилу, которое используется
для формирования проверочных символов.
по
тому же правилу, которое используется
для формирования проверочных символов.
![]()
Если при приеме информационных и проверочных символов (принятое считается полная кодовая комбинация, состоящая из информационных и проверочных символов) не произошло ошибок, то принятые вычисленные проверочные символы будут совпадать. В этом случае все разряды синдрома будут равны нулю. Таким образом, нулевой синдром соответствует случаю отсутствия ошибок.
Если в принятых кодовых комбинациях есть ошибки, то в разрядах синдрома появятся 1. Это и есть способ обнаружения ошибок систематическим кодом, который лежит в основе синдромного декодирования.
Если
код имеет минимальное кодовое расстояние
![]() ,
то такой код способен исправлять ошибки.
Это значит, что по виду синдрома можно
определить номер ошибочной позиции
принятой кодовой комбинации.
,
то такой код способен исправлять ошибки.
Это значит, что по виду синдрома можно
определить номер ошибочной позиции
принятой кодовой комбинации.
Процедура
построения систематического кода,
способного обнаруживать ошибки, сводится
к выбору весовых коэффициентов ![]() так, чтобы синдром, рассматриваемый
как двоичное число, указывал на номер
ошибочной позиции.
так, чтобы синдром, рассматриваемый
как двоичное число, указывал на номер
ошибочной позиции.
Пусть
требуется построить систематический
код длиной n=7,
способный исправлять одиночные ошибки,
т.е. ![]() =2t+1=3.
Пользуясь условием границы Хемминга,
найдем минимальное число проверочных
символов:
=2t+1=3.
Пользуясь условием границы Хемминга,
найдем минимальное число проверочных
символов:
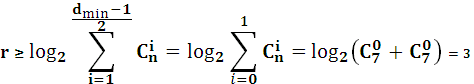
Выберем
r=3,
следовательно, код (7,4)- совершенный и
близкий к оптимальному. Тогда кодовая
комбинация ![]() - это и есть кодовая комбинация (7,4). Для
нашего случая получим:
- это и есть кодовая комбинация (7,4). Для
нашего случая получим:
![]() ,
,
![]() ,
,
![]() .
.
Найдем
весовые коэффициенты ![]() .
Для этого запишем все возможные
трехразрядные кодовые комбинации
синдрома:
.
Для этого запишем все возможные
трехразрядные кодовые комбинации
синдрома:
000, 001, 010, 100, 011, 101, 110, 111
Если ошибки отсутствуют, то синдром должен быть нулевым. Допустим, что появление одной 1 в синдроме будет связано с ошибками в проверочных символах кодовой комбинации. Тогда