

Теори
Классы Компьютеров: персоналки, миникомпьютеры, микрокомпьютеры, мейнфреймы и суперкомпьютеры
3) Компьютерные аппаратные средства ЭВМ могут быть разделены на четыре категории:входные аппаратные средства ЭВМ, обработка аппаратных средств ЭВМ, аппаратные средства ЭВМ хранения, аппаратные средства ЭВМ продукции{выпуска}.
5) Информационные процессы:
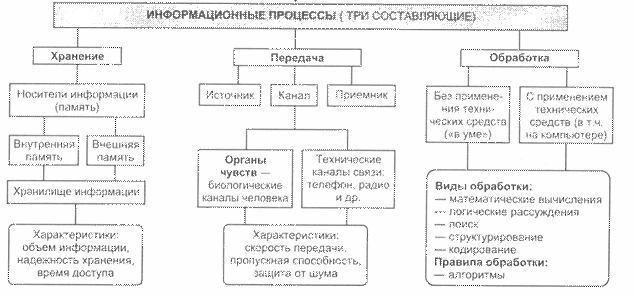
6) Кодировки символов. Типы обработки информации. Кодирование и декодирование.
Компьютерные кодировки:
Для использования с национальными алфавитами и прочими символами, не входящими в ASCII чаще всего стала применяться старшая половина пространства 8-битных кодов (128–255), позволяющее использовать до 128 дополнительных символов, чего достаточно для большинства европейских языков. Каждое семейство языков обладающее одинаковым алфавитом, как правило, обладало собственной кодировкой символов. Часто, из-за отсутствия общего урегулирования появлялось несколько различных кодировок для одного алфавита, что привело к появлению средств перекодирования. Лидером по количеству различных кодировок можно назвать кириллицу: насчитывается около десятка различных кодировок и ещё большее количество вариаций.
Однако в процессе перевода алфавитов других стран оказалось, что для некоторых из них недостаточно 256 символов, предоставляемых расширенной таблицей ASCII.
Для решения этой проблемы было разработано семейство универсальных кодировок — Unicode, содержащего около до миллиона различных символов, и состоящее из UCS (универсальный набор символов), предоставляющего универсальную систему нумерации символов, а также кодировки, регламентирующие порядок передачи и хранения символьной информации:
UTF-8 (UCS-1), кодирующая символы последовательностями от 1 до 6 байт);
UTF-16 (UCS-2), кодирующая символы одним или двумя 16-битными словами;
UTF-32 (UCS-4), кодирующая символы в 32-битные слова;
UTF-7, использующая вставки UTF-16, закодированные в BASE64;
punycode, используемая для кодирования национальных доменных имён.
Кириллические кодировки
ISO 8859-5 — применяется в коммерческих UNIX-системах (Solaris, HP-UX и т.д., также предлагалась для русификации AmigaOS);
Основная кодировка ГОСТ — использовалась на советских ЭВМ;
Альтернативная кодировка ГОСТ (cp866) — используется MS-DOS-программами и в сети FidoNet;
КОИ-7 — использовалась на советских ЭВМ;
КОИ-8 — используется в Интернет и операционных системах Linux и FreeBSD;
Windows-1251 — используется в системе Microsoft Windows;
Ami-1251 — вариация Windows-1251, принятая стандартом для русского перевода ОС AmigaOS;
Кодировка Дмитрия Михайлова — разработана Дмитрием Михайловым для русификации AmigaOS;
Русская кодировка MacOS — используется на компьютерах Macintosh.
Кодирование информации это преобразование формы представления информации с целью ее передачи или хранения. Кодирование это представление символов одного алфавита символами другого. Правила, по которым осуществляется кодирование называются кодом. Под словом понимают последовательность символов,. количество символов в которой называется длиной кода. Слова так же называют кодовыми комбинациями. Если при кодировании получают комбинации одинаковой длины, то такой код называют равномерным, а длину кодовых комбинаций в этом слове называют значимостью кода. Если кодовые комбинации различной длины, то код называется неравномерным.
Процесс обратный кодированию называется декодированием.
Если в коде ни одна более короткая комбинация не является началом более длинной кодовой комбинации, то код называется префиксным.
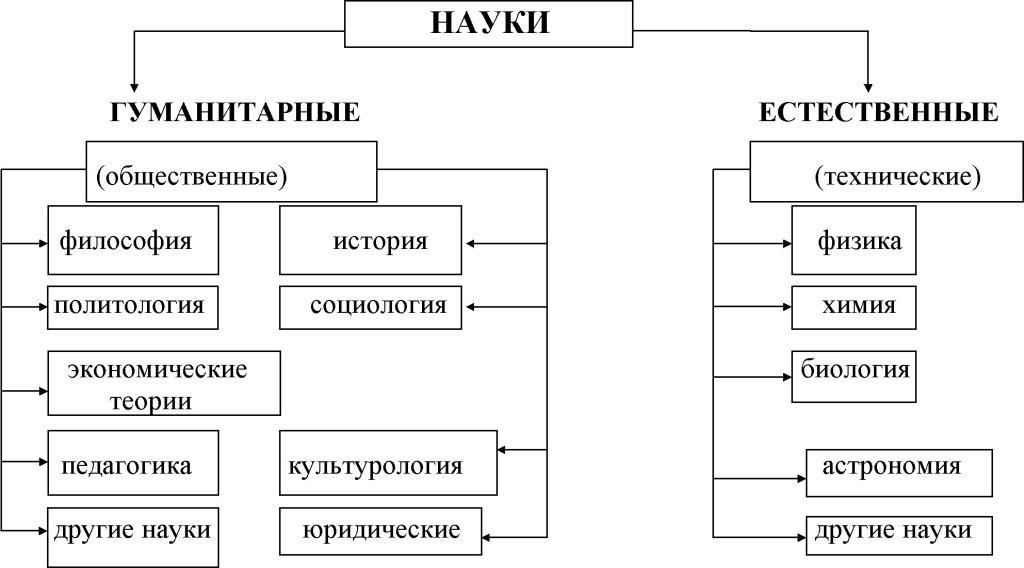
7) Классификация наук.
8) Классификация прикладных программных средств.

9) Основные типы операционной системы и отличия между ними.
1.2. Серверные операционные системы
1.3. Операционные системы для персональных компьютеров.
1.4. Встроенные операционные системы – простые операционные системы, устанавливаемые в принтерах, кассовых аппаратах и других внешних устройствах. Состоят из микроядра и функциональных блоков, обеспечивающих подключение в сеть внешнего устройства. Такие системы, управляющие действиями устройств, работают на машинах, обычно не считающихся компьютерами, например, в телевизорах, микроволновых печах, мобильных телефонах и карманных компьютерах. Карманный компьютер (PDA, Personal Digital Assistant – персональный цифровой помощник) – это маленький компьютер, помещающийся в кармане брюк, выполняющий небольшой набор функций (телефонной записной книжки и блокнота). Данный класс систем часто обладает такими же характеристиками, что и системы реального времени, но при этом имеют особый размер, память и ограничение мощности, что выделяет их в обособленный класс. Например, операционные системы: Palm OS, Windows CE (Consumer Electronics – бытовая техника).
1.5. Операционные системы для смарт-карт – самые маленькие операционные системы, которые работают на смарт-картах. Смарт-карты представляют собой устройства размером с кредитную карту, содержащие центральный процессор. На операционные системы накладываются крайне жесткие ограничения по мощности процессора и памяти. Некоторые из них могут управлять только одной операцией, например электронным платежом, другие выполняют более сложные функции. Часто они являются патентованными системами. Некоторые смарт-карты являются Java-ориентированными. Это означает, что ПЗУ (постоянная память, ROM, Read Only Memory – память только для чтения) смарт-карт содержит интерпретатор виртуальной машины Java (JVM, Java Virtual Machine). Апплеты Java (маленькие программы) загружаются на карту и выполняются JVM-интерпретатором. Некоторые из таких карт могут одновременно управлять несколькими апплетами Java, что приводит к многозадачности и необходимости планирования. Из-за одновременной работы двух и более программ возникает необходимость в управлении ресурсами и защитой. Все эти задачи выполняет операционная система, находящаяся на смарт-карте.
10) Функции операционной системы.
Основная функция всех ОС - посредническая. Она заключается в обеспечении интерфейсов:
пользователя (между пользователем и программно-аппаратными средствами
между программным и аппаратным обеспечением
между разными видами программного обеспечения
Обеспечение автоматического запуска
Все ОС обеспечивают свой автоматический запуск. Для дисковых ОС в специальной(системной) области диска создаётся запись программного кода. Обращение к этому коду происходит из BIOS. Завершая свою работу программы BIOS дают команду на загрузку и исполнение системной области диска. Диск с системной областью называется системным. На компьютере должен быть как минимум один системный диск.
Оганизация файловой системы
Управление приложениями.
Работа с приложениями - наиболее важная часть работы ОС. С точки зрения управления приложениями различают однозадачные и многозадачные ОС. Однозадачные ОС передают все ресурсы компьютера одной задаче. Большинство современных ОС многозадачные. Они управляют распределением рессурсов между задачами и обеспечивают:
-возможность одновременной или поочерёдной работы нескольких приложений;
-возможность обмена данными между приложениями;
-восможность совместного использования ресурсов несколькими приложениями.
Взаимодействие с аппаратным обеспечением.
Средства аппаратного обеспечения отличаются гигантским многообразием. Существуют сотни различных моделей видеокарт, звуковых карт, принтеров, сканеров и т.д. Ни один разработчик программного обеспечения не может предусмотреть все варианты взаимодейчтвия своей программы, например, с принтером. Поэтому каждый разработчик оборудования прикладывает к нему специальные пролграммы-драйверы. Управление взаимодействием пркладных программ с драйверами - одна из функций ОС.
Обслуживание компьютера
Обслуживание компьютера - одна из важных функций ОС.
Средства проверки диска бывают двух типов - проверка целостности файловой структуры и проверка физической поверхности диска. Ошибки файловой структуры устраняются средствами ОС. Физические дефекты ОС локализует и исключает их из активной работы. Возможность ошибок файловой системы зависит от её типа. Например, схема организации работы в NTFS вообще исключает воз можность появления ошибок в файловой структуре. В системе FAT часто появляются ошибки типа "потерянных кластеров" или "общих кластеров".
11) Файловая система. Тип файлов и их расширение.
Фа́йловая систе́ма (англ. file system) — порядок, определяющий способ организации, хранения и именования данных на носителях информации в компьютерах, а также в другом электронном оборудовании: цифровых фотоаппаратах, мобильных телефонах и т. п. Файловая система определяет формат содержимого и способ физического хранения информации, которую принято группировать в виде файлов. Конкретная файловая система определяет размер имени файла (папки), максимальный возможный размер файла и раздела, набор атрибутов файла. Некоторые файловые системы предоставляют сервисные возможности, например, разграничение доступа или шифрование файлов.
12) Виды программного обеспечения.
Общее программное обеспечение
Операционная система
Системы программирования
Программы технического обслуживания
Прикладное программное обеспечение
Системы управления базами данных
Системы искусственного интеллекта
Системы автоматического проектирования
Системы электронного документооборота
Информационное хранилище
Геоинформационная система
Средства использования
Электронные таблицы
Графический редактор
Текстовый редактор
Электронная почта
Электронный офис
Видеоконференция
Система групповой работы
Корпоративные информационные системы
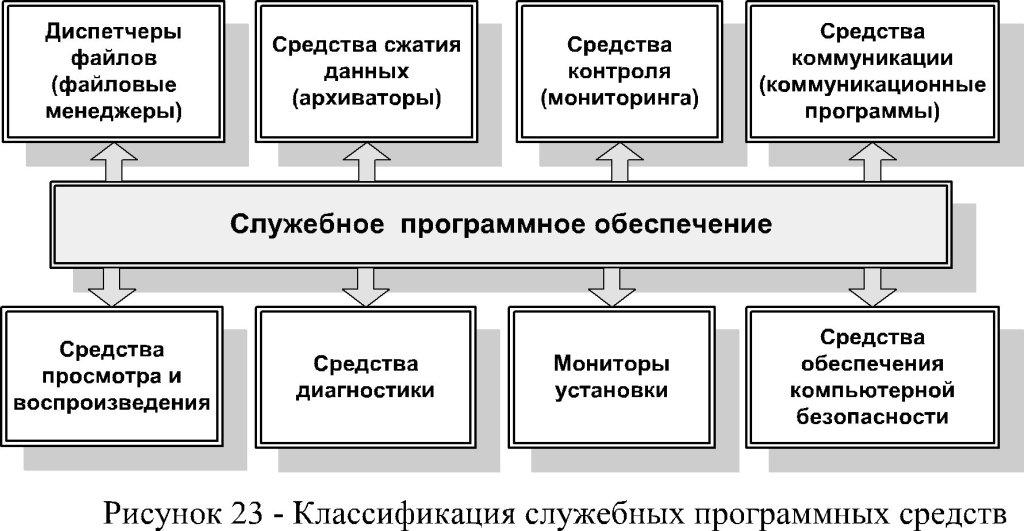
13) Классификация служебных программных средств.
14) Алгоритм. Определение и правила изображения блок-схем.
15) Правила для составления схем алгоритмов. Блок-схема алгоритма и его преимущество.
16) Типы алгоритмов. Одномерный и двумерный массив.
17) Подход к измерению информации. Мера Хартли и неопределенности.
Подходы к измерению информации
При всем многообразии подходов к определению понятия информации, с позиций измерения информации нас интересуют два из них: определение К. Шеннона, применяемое в математической теории информации, и определение А. Н. Колмогорова, применяемое в отраслях информатики, связанных с использованием компьютеров (computer science).
В содержательном подходе возможна качественная оценка информации: новая, срочная, важная и т.д. Согласно Шеннону, информативность сообщения характеризуется содержащейся в нем полезной информацией - той частью сообщения, которая снимает полностью или уменьшает неопределенность какой-либо ситуации. Неопределенность некоторого события - это количество возможных исходов данного события. Так, например, неопределенность погоды на завтра обычно заключается в диапазоне температуры воздуха и возможности выпадения осадков.
Содержательный подход часто называют субъективным, так как разные люди (субъекты) информацию об одном и том же предмете оценивают по-разному. Но если число исходов не зависит от суждений людей (случай бросания кубика или монеты), то информация о наступлении одного из возможных исходов является объективной.
Алфавитный подход основан на том, что всякое сообщение можно закодировать с помощью конечной последовательности символов некоторого алфавита. С позиций computer science носителями информации являются любые последовательности символов, которые хранятся, передаются и обрабатываются с помощью компьютера. Согласно Колмогорову, информативность последовательности символов не зависит от содержания сообщения, а определяется минимально необходимым количеством символов для ее кодирования. Алфавитный подход является объективным, т.е. он не зависит от субъекта, воспринимающего сообщение. Смысл сообщения учитывается на этапе выбора алфавита кодирования либо не учитывается вообще. На первый взгляд определения Шеннона и Колмогорова кажутся разными, тем не менее, они хорошо согласуются при выборе единиц измерения.
18) Представление чисел в различных системах счисления.
В общем случае в позиционной системе с основанием P имеется ровно P разных цифр в диапазоне от 0 до P-1. Так в десятичной системе счисления используется 10 цифр: от 0 до 9. В двоичной – всего две цифры 0 и 1, а в шестнадцатеричной – 16 цифр. Поскольку обычных цифр для шестнадцатеричной системы недостаточно, то для цифр после 9 используются буквы латинского алфавита от A до F. Общий вид представления числа в позиционной системе счисления с основанием P следующий:
19) Представление данных в ПК.
Любая информация (числовая, текстовая, звуковая, графическая и т.д.) в компьютере представляется (кодируется) в так называемой двоичной форме. Как оперативная, так и внешняя память, где и хранится вся информация, могут рассматриваться, как достаточно длинные последовательности из нулей и единиц. Под внешней памятью подразумеваются такие носители информации, как магнитные и оптические диски, ленты и т.п.
Единицей измерения информации является бит (BInary digiT) -- именно такое количество информации содержится в ответе на вопрос: нуль или один? Более крупными единицами измерения информации являются байт, килобайт (Kbyte), мегабайт (Mbyte), гигабайт (Gbyte) и терабайт (Tbyte). Один байт (byte) состоит из восьми бит, а каждая последующая величина больше предыдущей в 1024 раза.
Байта достаточно для хранения 256 различных значений, что позволяет размещать в нем любой из алфавитно-цифровых символов, если только мы можем ограничиться языками с небольшими алфавитами типа русского или английского. Первые 128 символов (занимающие семь младших бит) стандартизированы с помощью кодировки ASCII (American Standart Code for Information Interchange). Хуже обстоит дело с кодировками русского текста (символы русского алфавита расположены во второй половине таблицы из 256 символов) -- их несколько, а наиболее распространенные из них сейчас две -- Windows-1251 и KOI8-R.
20) Алгоритм перевода правильных дробей из одной системы счисления в другую.
21) Алгоритм перевода целых чисел из одной системы счисления в другую.
22) Система счисления – это способ записи чисел. Обычно, числа записываются с помощью специальных знаков – цифр (хотя и не всегда). Если вы никогда не изучали данный вопрос, то, по крайней мере, вам должны быть известны две системы счисления – это арабская и римская. В первой используются цифры 0, 1, 2, 3, 4, 5, 6, 7, 8, 9 и это позиционная система счисления. А во второй – I, V, X, L, C, D, M и это непозиционная система счисления.
В позиционных системах счисления количество, обозначаемое цифрой в числе, зависит от ее позиции, а в непозиционных – нет. Например:
11 – здесь первая единица обозначает десять, а вторая – 1. II – здесь обе единицы обозначают единицу.
23) Основные логические операции.
Логическое отрицание (инверсия)
|
A |
-A |
|
0 |
1 |
|
1 |
0 |
|
A |
B |
A+B |
|
0 |
0 |
0 |
|
0 |
1 |
1 |
|
1 |
0 |
1 |
|
1 |
1 |
1 |
|
A |
B |
A*B |
|
0 |
0 |
0 |
|
0 |
1 |
0 |
|
1 |
0 |
0 |
|
1 |
1 |
1 |
Логическое следование (импликация)
|
A |
B |
AB |
|
0 |
0 |
1 |
|
0 |
1 |
1 |
|
1 |
0 |
0 |
|
1 |
1 |
1 |
Логическая операция эквивалентности
|
A |
B |
F |
|
1 |
1 |
1 |
|
1 |
0 |
0 |
|
0 |
1 |
0 |
|
0 |
0 |
1 |
Логическая операция mod2
|
A |
B |
F |
|
1 |
1 |
0 |
|
1 |
0 |
1 |
|
0 |
1 |
1 |
|
0 |
0 |
0 |
24) Алгебра логики. Закон логики.
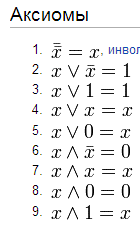

25) Языки компьютера. Естественные и формальные языки.
Естественныминазываются “обычные”, “разговорные” языки, которые складываются стихийно и в течение долгого времени. История каждого такого языка неотделима от истории народа, владеющего им. Естественный язык, предназначенный, прежде всего, для повседневного общения, имеет целый ряд своеобразных черт:
· почти все слова имеют не одно, а несколько значений;
· часто встречаются слова с неточным и неясным содержанием;
· значения отдельных слов и выражений зависят не только от них самих, но и от их окружения (контекста);
· распространены синонимы (разное звучание - одинаковый смысл) и омонимы (одинаковое звучание - разный смысл);
· одни и те же предметы могут иметь несколько названий;
· есть слова, не обозначающие никаких предметов;
· многие соглашения относительно употребления слов не формулируются явно, а только предполагаются и для каждого правила есть исключения и т.д.
Основными функциямиестественного языка являются:
· коммуникативная (функция общения);
· когнитивная (познавательная функция);
· эмоциональная (функция формирования личности);
· директивная (функция воздействия).
Искусственныеязыки создаются людьми для специальных целей либо для определенных групп людей: язык математики, морской семафор, язык программирования. Характерной особенностью искусственных языков является однозначная определенность их словаря, правил образования выражений и правил придания им значений.
Любой язык –– и естественный и искусственный –– обладает набором определенных правил. Они могут быть явно и строго сформулированными (формализованными), а могут допускать различные варианты их использования.
Формализованный(формальный)язык –– язык, характеризующийся точными правилами построения выражений и их понимания. Он строится в соответствии с четкими правилами, обеспечивая непротиворечивое, точное и компактное отображение свойств и отношений изучаемой предметной области (моделируемых объектов).
26) Система управления базами данных. Модель СУБД.
Систе́ма управле́ния ба́зами да́нных (СУБД) — совокупность программных и лингвистических средств общего или специального назначения, обеспечивающих управление созданием и использованием баз данных.
Основные функции СУБД
управление данными во внешней памяти (на дисках);
управление данными в оперативной памяти с использованием дискового кэша;
журнализация изменений, резервное копирование и восстановление базы данных после сбоев;
поддержка языков БД (язык определения данных, язык манипулирования данными).
Обычно современная СУБД содержит следующие компоненты:
ядро, которое отвечает за управление данными во внешней и оперативной памяти, и журнализацию,
процессор языка базы данных, обеспечивающий оптимизацию запросов на извлечение и изменение данных и создание, как правило, машинно-независимого исполняемого внутреннего кода,
подсистему поддержки времени исполнения, которая интерпретирует программы манипуляции данными, создающие пользовательский интерфейс с СУБД
а также сервисные программы (внешние утилиты), обеспечивающие ряд дополнительных возможностей по обслуживанию информационной системы.
Классификации субд По модели данных
Примеры:
Иерархические - построенные по принципу дерева
Сетевые - те же самые иерархические, но с заплатками некоторых проблем и сетевой работой
Реляционные - БД, построенная на отношениях(связях), чаще всего нормализованнная.
Объектно-ориентированные - элементы представляются в виде объектов, что очень удобно при исп. ООП
Объектно-реляционные.
По степени распределённости
Локальные СУБД (все части локальной СУБД размещаются на одном компьютере)
Распределённые СУБД (части СУБД могут размещаться на двух и более компьютерах).
По способу доступа к бд
Файл-серверные
В файл-серверных СУБД файлы данных располагаются централизованно на файл-сервере. СУБД располагается на каждом клиентском компьютере (рабочей станции). Доступ СУБД к данным осуществляется через локальную сеть. Синхронизация чтений и обновлений осуществляется посредством файловых блокировок. Преимуществом этой архитектуры является низкая нагрузка на процессор файлового сервера. Недостатки: потенциально высокая загрузка локальной сети; затруднённость или невозможность централизованного управления; затруднённость или невозможность обеспечения таких важных характеристик как высокая надёжность, высокая доступность и высокая безопасность. Применяются чаще всего в локальных приложениях, которые используют функции управления БД; в системах с низкой интенсивностью обработки данных и низкими пиковыми нагрузками на БД.
На данный момент файл-серверная технология считается устаревшей, а её использование в крупных информационных системах — недостатком[2].
Примеры: Microsoft Access, Paradox, dBase, FoxPro, Visual FoxPro.
Клиент-серверные
Клиент-серверная СУБД располагается на сервере вместе с БД и осуществляет доступ к БД непосредственно, в монопольном режиме. Все клиентские запросы на обработку данных обрабатываются клиент-серверной СУБД централизованно. Недостаток клиент-серверных СУБД состоит в повышенных требованиях к серверу. Достоинства: потенциально более низкая загрузка локальной сети; удобство централизованного управления; удобство обеспечения таких важных характеристик как высокая надёжность, высокая доступность и высокаябезопасность.
Примеры: Oracle, Firebird, Interbase, IBM DB2, Informix, MS SQL Server, Sybase Adaptive Server Enterprise, PostgreSQL, MySQL, Caché, ЛИНТЕР.
Встраиваемые
Встраиваемая СУБД — СУБД, которая может поставляться как составная часть некоторого программного продукта, не требуя процедуры самостоятельной установки. Встраиваемая СУБД предназначена для локального хранения данных своего приложения и не рассчитана на коллективное использование в сети. Физически встраиваемая СУБД чаще всего реализована в виде подключаемой библиотеки. Доступ к данным со стороны приложения может происходить через SQL либо через специальные программные интерфейсы.
Примеры: OpenEdge, SQLite, BerkeleyDB, Firebird Embedded, Microsoft SQL Server Compact, ЛИНТЕР.
27) Структура, типы и основные объекты базы данных.
Основу базы данных составляют хранящиеся в ней данные. Однако в базе данных Access есть и другие важные компоненты, которые принято называть объектами:
Таблицы - содержат данные.
Запросы - позволяют задавать условия для отбора данных и вносить изменения в данные.
Формы - позволяют просматривать и редактировать информацию.
Страницы - файлы в формате HTML (Hypertext Markup Language - язык разметки гипертекста), позволяющие просматривать данные Access с помощью браузера Интернет Explorer.
Отчеты - позволяют обобщать и распечатывать информацию.
Макросы - выполняют одну или несколько операций автоматически.
28) Структура реляционной базы данных. Связи между таблицами и примеры.
Реляционная база данных — база данных, основанная на реляционной модели данных. Слово «реляционный» происходит от англ. relation (отношение). Для работы с реляционными БД применяют реляционные СУБД.
Реляционная модель данных (РМД) — логическая модель данных, прикладная теория построения баз данных, которая является приложением к задачам обработки данных таких разделов математики как теории множеств и логика первого порядка.
На реляционной модели данных строятся реляционные базы данных.
Реляционная модель данных включает следующие компоненты:
Структурный аспект (составляющая) — данные в базе данных представляют собой набор отношений.
Аспект (составляющая) целостности — отношения (таблицы) отвечают определенным условиям целостности. РМД поддерживает декларативные ограничения целостности уровня домена (типа данных), уровня отношения и уровня базы данных.
Аспект (составляющая) обработки (манипулирования) — РМД поддерживает операторы манипулирования отношениями (реляционная алгебра, реляционное исчисление).
Кроме того, в состав реляционной модели данных включают теорию нормализации.
Термин «реляционный» означает, что теория основана на математическом понятии отношение (relation). В качестве неформального синонима термину «отношение» часто встречается слово таблица. Необходимо помнить, что «таблица» есть понятие нестрогое и неформальное и часто означает не «отношение» как абстрактное понятие, а визуальное представление отношения на бумаге или экране. Некорректное и нестрогое использование термина «таблица» вместо термина «отношение» нередко приводит к недопониманию. Наиболее частая ошибка состоит в рассуждениях о том, что РМД имеет дело с «плоскими», или «двумерными» таблицами, тогда как таковыми могут быть только визуальные представления таблиц. Отношения же являются абстракциями, и не могут быть ни «плоскими», ни «неплоскими».
Для лучшего понимания РМД следует отметить три важных обстоятельства:
модель является логической, то есть отношения являются логическими (абстрактными), а не физическими (хранимыми) структурами;
для реляционных баз данных верен информационный принцип: всё информационное наполнение базы данных представлено одним и только одним способом, а именно — явным заданием значений атрибутов в кортежах отношений; в частности, нет никаких указателей (адресов), связывающих одно значение с другим;
наличие реляционной алгебры позволяет реализовать декларативное программирование и декларативное описание ограничений целостности, в дополнение к навигационному (процедурному) программированию и процедурной проверке условий.
Принципы реляционной модели были сформулированы в 1969—1970 годах Э. Ф. Коддом (E. F. Codd). Идеи Кодда были впервые публично изложены в статье «A Relational Model of Data for Large Shared Data Banks»[1], ставшей классической.
Строгое изложение теории реляционных баз данных (реляционной модели данных) в современном понимании можно найти в книге К. Дж. Дейта. «C. J. Date. An Introduction to Database Systems» («Дейт, К. Дж. Введение в системы баз данных»).
Наиболее известными альтернативами реляционной модели являются иерархическая модель, и сетевая модель. Некоторые системы, использующие эти старые архитектуры, используются до сих пор. Кроме того, можно упомянуть об объектно-ориентированной модели, на которой строятся так называемые объектно-ориентированные СУБД, хотя однозначного и общепринятого определения такой модели нет.