

Контрольные вопросы
Приведите определение понятию граф. Разновидности, свойства и назначение графов.
Способы физического и логического представления графов.
Бинарные деревья. Представления и способы обхода.
Применения бинарных деревьев.
Сильноветвящиеся деревья. Представления и области применения.
8. Методы ускорения доступа к данным
8.1. Хеширование данных
В главе 4 были рассмотрены методы доступа к данным, используя алгоритмы поиска. Для ускорения доступа к данным в таблицах можно использовать предварительное упорядочивание таблицы в соответствии со значениями ключей (рис. 8.1). При этом могут быть использованы методы поиска в упорядоченных структурах данных, например, двоичный поиск, что существенно сокращает время поиска данных по значению ключа. Однако при добавлении новой записи требуется переупорядочить таблицу. Потери времени на повторное упорядочивание таблицы могут значительно превышать выигрыш от сокращения времени поиска.
Тем не менее, метод двоичного поиска относится к алгоритмам класса O(log(n)). Например, для установления факта наличия или отсутствия заданного элемента в наборе из 1000 элементов требуется около 10 сравнений, поскольку 210=1024. Двоичный поиск является наиболее эффективным из всех возможных методов, которые требуют использования функции сравнения. Все они используют ключ элемента для перемещения по структуре данных с применением метода, в основе которого лежит сравнение.
Другие подходы к поиску исключает саму процедуру сравнения. Каждый элемент связывается с уникальным индексом, который позволяет обнаружить элемент путем однонаправленного действия, просто извлекая элемент, расположенный в определенной позиции. Преобразование ключа элемента в значение индекса называется хешированием и выполняется с помощью функции хеширования. Массив, используемый для хранения элементов, с которыми используются значения индексов, называют хеш-таблицей.
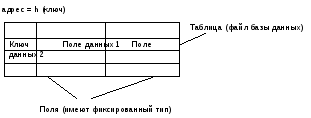
Рис. 8.1. Хеш-таблица.
Выполнение поиска с использованием хеширования требует реализации двух отдельных алгоритмов. Первый шаг состоит в хешировании, в результате которого ключ элемента преобразуется в значение индекса. Идеальной хеш-функцией является такая функция h, которая для любых двух неодинаковых ключей дает неодинаковые адреса:
![]()
Подобрать такую функцию можно, если все возможные значения ключей заранее известны. Такая организация данных называется совершенным хешированием. При заранее неопределенном множестве значений ключей и ограниченной длины таблицы подбор совершенной функции затруднителен. На практике используют хеш-функции, которые не гарантируют выполнение условия. Отображение двух или более ключей на один и тот же индекс называют конфликтом или коллизией. Поэтому требуется второй шаг, определяющий способ разрешения коллизий в случае их возникновения.
Хеш-таблица представляет хороший пример достижения компромисса между быстродействием и занимаемым объемом памяти. При уникальном значении ключей элемента типа word требуется создать 65536 элементов, и при этом можно гарантировать нахождение элемента с заданным значением ключа в результате одной операции. Однако при хранении не более 100 элементов такой подход окажется расточительным, т.к. 99.85% памяти массива не будет использоваться. С другой стороны, можно выделить размер памяти под массив для фактического числа элементов, выполнить сортировку и двоичный поиск. Память будет сэкономлена, но работать такой алгоритм будет значительно медленнее.
Алгоритмы хеширования предлагают компромисс, при котором хеш-таблицы будут занимать больше места, чем требуется для хранения всех элементов, но поиск будет выполняться всего за несколько операций доступа.
С хеш-таблицами выполняют следующие операции: проверка наличия элемента в таблице и удаление элемента из таблицы. Также часто необходимо расширение таблицы для помещения в нее большего числа элементов, чем предполагалось изначально. Заметим, что функционирование хеш-таблицы не предполагает извлечение записей в порядке следования, т.к. физически соседние ключи таблицы указывают на логически далеко расположенные друг от друга элементы.