

ВОСПРИЯТИЕ
РЕЧИ
Вопросы,
рассматриваемые в настоящем разделе
руководства, отнюдь не исчерпывают
всей проблемы восприятия речи. Они
касаются только самых начальных этапов
преобразования речевой информации
— превращения звукового речевого
сигнала в его фонетический образ.
Изучение этих преобразований необходимо
и, вероятно, достаточно для того, чтобы
выяснить, как человек может превращать
услышанный им звуковой сигнал в
последовательность артикуляторных
движений, т. е. как он может повторить
то, что он услышал.
Вопрос
о преобразованиях информации,
обеспечивающих понимание человеком
смысла сообщения, изучается математической
лингвистикой и психолингвистикой.
Однако система, осуществляющая эти
преобразования (морфологический,
синтаксический и семантический анализ),
обязательно должна иметь в качестве
своих входных сигналов не непосредственно
звуковой поток, а описание его в виде
последовательности фонетических
образов — фонем с дополнительными
указаниями (наличие ударения, характер
интонации и т. д.). Поэтому ясно, что не
зная, как звуковой сигнал превращается
в фонемы, нельзя описать и всего сложного
процесса восприятия речи.
Одна
из основных трудностей рассматриваемого
ниже этапа исследований состояла в
том, что реальность фонем в мозгу
человека еще требовала доказательств.
Для лингвиста фонемы представляют
собой минимальные единицы, используемые
для описания языка. Однако что собой
представляют минимальные единицы,
используемые мозгом для описания речи,
совпадают ли они с фонемами, принятыми
лингвистами, каким сигналам в нервной
системе они соответствуют, как они
формируются в процессе овладения речью
— все эти вопросы не были исследованы,
и они только частично выяснены в
настоящее время. Не ответив на них хотя
бы в первом приближении, нельзя было
ставить и вопроса о том, как звуковой
сигнал преобразуется в фонемы.
Сама
возможность экспериментального
исследования восприятия речи возникла
только благодаря тому, что на протяжении
427Глава 13
двух
последних десятилетий были разработаны
технические (и математические) методы
анализа и синтеза речевых сигналов,
были, заложены основы физиологической
и акустической теории речеобразования.
Элементарные
сведения о речеобразовании, акустических
свойствах речевого сигнала, методах
анализа и синтеза речи излагаются в
разделе «Элементы теории речеобразования».
Овладение этими сведениями является
необходимым для понимания материала,
приводимого в последующих разделах.
ЭЛЕМЕНТЫ
ТЕОРИИ РЕЧЕОБРАЗОВАНИЯ
Основные
принципы речеобразования. Акустический
речевой сигнал возникает в результате
сложных координированных движений,
происходящих в ряде органов, вся
совокупность которых и обозначается
как речевой аппарат (рис. 155, а). Входящие
в его состав легкие со всей дыхательной
мускулатурой обеспечивают развитие
давлений и возникновение воздушных
потоков в речевом тракте. Последний
(рис. 155, б) представляется гортанью и
рядом воздушных полостей, конфигурация
которых существенно изменяется в
процессе речеобразования. Ведущую роль
здесь играют движения нёбной занавески,
языка, губ и нижней челюсти.
Сложная
картина звукового речевого сигнала
является продуктом ряда происходящих
при этом акустических явлений (рис.
155, в). Акустические колебания возникают
в результате определенных взаимодействий
между воздушным потоком и структурами
речевого тракта за счет энергии мышц
дыхательной системы.
Возбуждаемые
колебания могут быть разделены на два
основных типа: почти периодические
колебания, возникающие в результате
работы гортани, и шумовые колебания,
которые связаны с возникновением
вихревых явлений в воздушном потоке,
проходящем через речевой тракт.
Второе
важнейшее акустическое явление — это
действие воздушных полостей речевого
тракта в качестве частотных фильтров.
Конфигурация и величины объемов полостей
речевого тракта определенным образом
изменяются при создании разных звуков.
Благодаря этому спектральная картина
звуковых колебаний, созданных
акустическими источниками, подвергается
соответствующей модификации.
Образование
воздушных потоков, работа механизма
гортани, все движения органов, образующих
речевой тракт («артикуляторов»),
происходят закономерно и координированно.
Благодаря этой динамически слаженной
деятельности и возникают сигналы,
складывающиеся в связную непрерывную
речь. Созданные в речевом тракте
звуковые колебания излучаются наружу.
Подавляющая доля энергии излучается
через ротовое и носовые отверстия,
428
в
Рис.
155. Схема речеобразующего аппарата.
а
— анатомическое изображение; б
—
функциональные элементы; в
—| эквивалентная
блок-схема. На а:
1 —
грудная клетка, 2
—
легкие, 3
— трахея,
4
—
голосовые связки, 5
—
гортанная трубка, 6
—
полость глотки, 7
—
нёбная занавеска, 8
—
полость рта, 9 — полость носа. На б: 1
—
сила дыхательных мышц, 2
—
объем легких, з
—
трахея, 4
—
голосовые связки, 5
—
гортанная трубка, 6 — полость глотки,
7
—
нёбная занавеска, 8
— полость
рта, 9
—
полость носа, 10
—
излучение из ротового отверстия, 11
—
излучение из носовых отверстий. На в:
2, з —
емкость легких и трахеи, 4
—
голосовой источник колебаний, 5, 6
—
емкость гортани и глотки, 7
—
механизм нёбной занавески, 8
—
емкость полости рта, 9 — емкость полостей
носа, 10
—
выходной сигнал ротового тракта, 11
—
выходной сигнал носового тракта, 12
—
шумовой источник.


определенную
роль играет изменение характеристик
излучения, имеющее место при изменении
величины ротового отверстия.
Таким
образом, в процессе речеобразования
имеет место следующая цепочка
явлений: мышечная («моторная») активность
речеобразующего аппарата —
аэродинамические явления — акустические
явления. Рассмотрим более подробно
явления акустические.
Источники
акустической энергии. Воздушный
поток, создаваемый в речевом тракте
благодаря действию дыхательной системы,
может модулироваться тремя способами,
показанными на рис. 156.
Рис.
156. Основные способы модуляции
воздушного
потока, обеспечивающие
возникновение звуков речи
(по:
Stevens, 1964).
а
—
периодическая модуляция колеблющимися
голосовыми связками; б — возникновение
турбулентности в потоке, проходящем
через место резкого сужения речевой
трубки; в — возникновение взрывных
звуков при быстром открывании полной
смычки. Белые
стрелки
— звуковой сигнал, черные
—
место образования звука.
В
результате этого энергия равномерного
воздушного потока в какой-то своей
части преобразуется в акустические
колебания.
Наиболее
мощным источником является гортань,
представляющая собой орган,
приспособленный для создания звуковых
колебаний. Находящиеся внутри полости
гортани две эластичные складки —
голосовые связки — образуют своеобразный
и тонко управляемый клапанный механизм.
При наличии определенных условий —
достаточной величины подсвязочного
давления, сведения и соответствующего
натяжения голосовых связок — последние
приходят в колебательное движение.
Колебания
эти происходят благодаря взаимодействию
сил, направленных в разные стороны.
Сила, создаваемая подсвязочным давлением,
стремится раздвинуть голосовые связки;
благодаря упругости соответственно
натянутых мышцами связок возникает
сила, пытающаяся свести их вместе.
Определенное значение имеет также
эффект Бернулли (возникновение силы,
сближающей стенки канала, если в нем с
большой скоростью протекает поток
жидкости или газа). Площадь отверстия
между голосовыми связками (голосовая
щель) ритмически изменяется. Как правило,
430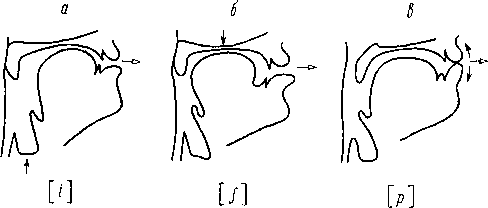
в
течение некоторой доли периода колебаний
голосовая щель оказывается сомкнутой,
воздушный поток полностью прерывается.
Типичной является картина, изображенная
на рис. 157, б,
где представлена осциллограмма объемной
скорости воздуха в сечении голосовой
щели.
Спектр
этих колебаний представляет рис. 157, в.
Расстояния но шкале частот между
отдельными гармоническими компонен
Рис.
157. Характеристики работы голосового
источника.
а
—
схематическое изображение фронтального
сечения гортани в об-
ласти голосовых
связок, движения которых показаны
горизонталь-
ными стрелками; стрелки
внизу показывают напор воздуха, б
—
типичная форма изменений скорости
воздушного потока, возникаю-
щих
благодаря действию колеблющихся
голосовых связок;, по
оси
абсцисс —
время; по
оси ординат —
объемная скорость (^). в
—
спектр
колебаний, осциллограмму которых
изображает рис. б;
по
оси абсцисс —
частота колебаний; по
оси ординат —
интен-
сивность.
тами
линейного спектра определяются частотой,
с которой следуют импульсы. Эта
важнейшая характеристика голосового
источника — основная частота голоса
— характерным образом изменяется
в потоке речи. Существенная доля
информации, которая оказывается
связанной с изменениями основной
частоты голоса, относится к так называемым
просодическим характеристикам речи
(выражение повествовательной,
вопросительной, восклицательной
интонации, ударений словесных и особенно
логических, обозначение незаконченности
или оконченности фразы и др.). Для
мужских голосов типичной областью
изменений основной частоты голоса
является 80—150 гц, для женских — более
высокая область 120—400 гц.
431


В
сложном механизме регулирования высоты
голоса основную роль играют задаваемая
мышцами гортани степень натяжения
голосовых связок и величина подсвязочного
давления, создаваемого дыхательной
системой. Моменты включения и выключения
голосового источника в динамике потока
речи определяются в основном
движениями, сводящими и разводящими
связки. Играет определенную роль и
выравнивание внутриротового давления
с подсвязочным, возникающее при фонации
с наличием полного смыкания артикуляторов
(такие звуки, как1
[b 1, [d], [g]). Возможно, что в кратковременной
остановке фонации при глухих смычных
звуках участвует своеобразный механизм:
открывание дополнительного отверстия
— «шепотного треугольника», находящегося
позади голосовых связок.
Сила
звуковых колебаний, создаваемых
гортанью, зависит от максимальной
величины объемной скорости воздуха,
проходящего через голосовую щель в
момент ее открытия, и в основном
определяется величиной подсвязочного
давления, создаваемого дыхательной
системой. Форма воздушного толчка —
наклоны фронтов треугольника,
изображенного на рис. 157, б, отношение
длительности фазы открытия голосовой
щели к длительности всего периода —
также изменяется в зависимости и от
подсвязочного давления и от степени
натяжения связок. С изменениями формы
импульсов связано изменение спектрального
состава колебаний, возбуждаемых
голосовым источником, что в конечном
итоге также оказывает свое влияние на
характер звукового сигнала речи.
Механизм
возбуждения шумных звуков сводится к
возникновению вихревых явлений —
турбулентности — в потоке воздуха,
проходящем через полости речевого
тракта. Условия возникновения шума
определяются как величиной линейной
скорости частиц воздуха, так и
геометрическими свойствами (величиной
«эффективной площади») канала, в котором
проходит воздушный поток. В речевом
тракте подобные условия возникают при
образовании сужения в каком-либо
сечении речевой трубки и создании
достаточного напора воздуха за этим
сужением.
При
создании таких шумных звуков, как [f ],
[s], [f ] и т. п., называемых фрикативными,
явление соответствует возникновению
шума при продувании воздуха через сопло
(рис. 158, а). Возбуждаются беспорядочные
звуковые колебания, спектр которых
отличается достаточной равномерностью
и значительной протяженностью в
области высоких частот. Подобные
согласные
1
Знаки, используемые для обозначения
звуков речи, как правило, соответствуют
международной фонетической системе.
В отдельных случаях при обозначении
звуков русской речи используются буквы
русского алфавита. Для достижения
однозначности обозначения звуков в
тексте заключены в квадратные скобки.
43?
звуки
можно производить продолжительное
время, поддерживая их характеристики
стационарными.
Наоборот,
краткостью отличаются шумные взрывные
звуки ([р], [t], Ik] и др.). При их артикуляции
производится полное смыкание стенок
в каком-то определенном месте речевого
тракта,
Рис.
158. Характеристики работы шумовых
источни-
ков.
а
—
протекание воздушной струи через
сужение в речевой трубке; б
—
шумовой сигнал, возникающий благодаря
явлению турбулентности; в
—
широкополосный спектр шумового сигнала;
г
—
образование воздушного толчка при
открывании сомкнутых артикуляторов,
за которыми создано дополнительное
давление; 0
—
импульсный сигнал, возникающий в момент
открывания смычки артикуляторов; е
—
спектр импульсного сигнала. По
оси ординат:
на б, д
—
время, на в, е
—
частота; по
оси абсцисс:
на б, в,
д, е —
интенсивность звуковых колебаний.
Стрелки на а, г
характеризуют движение воздушных
потоков.
глубже
места этой «смычки» создается повышенное
давление, и смычка быстро размыкается
(рис. 158, б). Быстрый толчок воздуха
создает короткий импульсный звук.
Если
расположение голосового источника
относительно всех образований речевого
тракта всегда остается неизменным, то
источники шумных и взрывных звуков,
наоборот, могут располагаться в разных
его местах, так как источник связан с
местом образования смычки. Обычно
рассматривают губные (губно-зубные),
переднеязычные, среднеязычные и
заднеязычные смычки. Место положе-
Сенсорные
системы 433
ния
источника является важным различительным
параметром согласных звуков.
Голосовой
и шумовые (фрикативный или взрывной)
источники могут возбуждаться и
одновременно (звонкие согласные).
Временная картина включения и
динамики работы всех этих источников
в слитной речи отличается высокой
степенью координации с движениями
всех органов речеобразующего аппарата.
Частотная
фильтрация в речевом тракте. Звуковые
колебания, возникшие в результате
действия рассмотренных выше акустических
источников, представляют собою как бы
исходный «сырой» материал, подвергающийся
в процессе создания речевого сигнала
дальнейшим преобразованиям. Ведущую
роль здесь играют частотно-избирательные
свойства воздушных полостей всего
речевого тракта. Если звуковые колебания
возбуждаются в некотором ограниченном
объеме, то будут проявляться акустические
резонансные свойства этого объема,
зависящие от его размеров и конфигурации.
Рассматриваемый в этом аспекте речевой
тракт представляет собой последовательно
расположенные полости довольно сложной
конфигурации, к тому же существенно
изменяющиеся в динамике речевого
потока. В акустическом отношении
подобная система является сложным
частотным фильтром с переменными
свойствами.
Современная
акустическая теория речеобразования
(Fant, 1960) показывает, что весь процесс
создания звукового речевого сигнала
может быть сведен к возбуждению
акустических источников и управляемой
фильтрации создаваемых ими сигналов.
Схему происходящих явлений можно
пояснить (рис. 159). Спектральные
составляющие исходных колебаний,
проходя через фильтр, умножаются на
величины соответствующих ординат
частотной характеристики фильтра.
Преобразованный таким образом спектр
и характеризует излучаемый речевой
сигнал.
Фильтрующее
действие речевого тракта зависит от
его геометрической формы и места
расположения акустического источника.
При работе голосового источника место
его расположения не изменяется,
ведущее значение оказывается за
конфигурацией полостей речевого
тракта. Характерный пример представлен
на рис. 160. При фонации звука [i ] к нёбу
поднимается передняя часть спинки
языка, большим оказывается объем
полостей, расположенных сзади от
места этого сужения, малым — объем
между местом сужения и ротовым отверстием;
поднятая кверху нёбная занавеска
«отключает» носовые полости. В результате
«настроенной» таким образом частотной
фильтрации звуковые колебания голосового
источника, спектр которых показан на
рис. 157, характерным образом преобразуются.
Огибающая спектра окончательного
сигнала дана на рис. 160, б. При образовании
звука [а] значительно большим оказывается
объем полостей передней части
речевого тракта, спинка языка удалена
от нёба
434
Рис.
159. Схематическое изображение
преобразований сигнала в речевом
тракте
(по: Fant, 1960).
а
—
сигнал голосового источника; б —
фильтрующая система речевого тракта;
в
—
выходной
речевой сигнал; г
—
спектр сигнала голосового источника;
д
—
вид частотной
характеристики речевого
тракта; е
—
спектр речевого сигнала.
Рис.
160. Схематические изображения конфигурации
артикуляторов (а, в)
и огибающие спектров (б, а) для гласных
звуков [i] и [а] (по: Stevens, 1964).
По
оси абсцисс —
частота в кгц; по
оси ординат —
относительная
интенсивность в дб.
28*

(рис.
160, в);
спектр звукового сигнала существенно
отлипей (рис. 160, г).
Подобного
же рода частотная фильтрация имеет
место и при Действии шумовых источников.
Процесс здесь дополнительно осложняется
изменением места возникновения звука.
В первом приближении источник может
быть привязан к месту смычки артикуляторов.
Фильтрующие свойства речевого тракта
определяются как совокупностями
объемов, расположенных в глубине за
артикуляторной смычкой, так и перед
ней.
При
опускании нёбной занавески в качестве
акустических резонаторов начинают
играть роль и носовые полости. Образование
назальных согласных [т ] и [n ] происходит
при закрытом ротовом отверстии. Звук
излучается через носовые отверстия,
однако влияние полости рта сказывается
в качестве параллельно подключенного
резонатора. Сообщение между ротовым и
носовым трактами может возникать
также и при фонации гласных — при их
«назализации». В данном случае основная
энергия излучается через ротовое
отверстие, но звук приобретает характерную
окраску.
Резонансные
пики, соответствующие набору собственных
частот речевого тракта и проявляющиеся
в картине спектра, называются формантами.
Максимальное число их зависит от общей
длины речевого тракта. Считается,
что у взрослого мужчины их может быть
до 7. Однако важнейшее значение для
различения звуков имеют 2—3 форманты.
К
настоящему времени проведено весьма
значительное число исследований, целью
которых были попытки найти и аналитически
выразить зависимости между важными
для речеобразования акустическими
свойствами и геометрическими размерами
тракта. Основой здесь являются измерения,
осуществляемые с помощью рентгенографической
техники; речевой тракт обычно
аппроксимируется моделью в виде
последовательно соединенных отрезков
труб.
Для
случаев стационарных звуков речи вопрос
разработан достаточно полно (Fant, 1960;
Flanagan, 1965). Созданы модели работы речевого
тракта, весьма удовлетворительно
описывающие основные физические
процессы, имеющие при этом место.
Значительно хуже обстоит дело с
точным описанием и пониманием динамики
всех явлений, происходящих в речевом
тракте в связи с образованием непрерывного
потока живой устной речи.
Динамическая
организация речевого потока. Как
упомянуто выше, современная акустическая
теория речеобразования дает достаточно
хорошее описание тех процессов, которые
имеют место при создании относительно
долго длящихся — стационарных
звуков. Положение, однако, существенным
образом осложняется, если рассматривать
звуковой сигнал естественного потока
речи. Оказывается, что реальный речевой
сигнал не может быть
436
представлен
просто как последовательность примыкающих
дру? к другу сегментов, обладающих
некоторыми стабильными акустическими
свойствами. Изображение услышанной
речи в виде последовательности букв
или даже более богатого набора значков,
принятого в фонетике, является существенно
упрощенным описанием сигнала и
оказывается возможным лишь благодаря
всем сложным преобразованиям информации,
которые происходят при восприятии
речи.
Вопрос
о характере распределения информации
об отдельных фонемах в непрерывном
потоке речи рассматривался Фантом
Рис.
161. Диаграмма, отражающая особенности
динамической спектрограммы
произнесенных слов Santa Claus (по: Fant,
Lindblom, 1961).
По
горизонтали —
различающиеся между собой сегменты,
на кото-
рые разделяется спектрограмма;
по
вертикали —
произнесенные
фонемы. Жирные
линии
показывают сегменты, в которых
имеются
признаки соответствующих
фонем.
и
Линдблумом (Fant, Lindblom, 1961) и Чистович
(1962). Авторы использовали метод
динамической спектрографии (о нем будет
сказано ниже) и пришли к выводу, что
особенности спектрографической
картины, говорящие о наличии того или
иного признака, характеризующего
рассматриваемую фонему, оказываются,
как правило, занимающими участки,
значительно превосходящие ту длительность,
которая может быть отведена в потоке
речи на эту фонему. Участки потока,
несущие данные о соответствующих
фонемах, оказываются существенно
перекрывающимися во времени (рис. 161).
Подобные
особенности картины акустического
сигнала находят свое объяснение при
рассмотрении динамики физиологических
явлений, лежащих в основе речеобразования.
Все имеющие здесь место процессы
представляют собою следствие определен
437
ным
образом организованной мышечной
активности, охватывающей и дыхательную
систему, и собственно речевой аппарат.
Для
производства звуков речи необходимым
условием’является создание достаточного
подсвязочного давления и обеспечение
потоков воздуха в речевом тракте,
обладающих определенными скоростями.
Это выполняется с помощью дыхательной
системы. Дыхание во время речи характерным
образом перестраивается. Как правило,
перед началом речи делается более
глубокий вдох, обеспечивающий наличие
достаточного объема воздуха в легких.
Фаза «речевого выдоха» отличается
существенным повышением внутрилегочного
давления и вместе с тем экономичным
расходом воздуха и значительно
увеличенной по сравнению с обычным
дыханием длительностью.
При
продолжающейся речи моменты вдохов
определенным образом согласуются
с лингвистической конструкцией
произносимого языкового материала.
Производство вдохов, неизбежно ведущих
к возникновению паузы, подчиняется
определенным правилам. Они допускаются
только либо после окончания фразы, либо
в определенных местах внутри
предложения, разделяющих группы слов,
обычно обозначаемые как синтагмы
(Шейнин, 1966).
Величина
и особенности развития во времени
положительного внутрилегочного
давления, необходимого для производства
речи, существенно зависят от таких ее
характеристик, как громкость, интонационная
структура, логические ударения (рис.
162). В значительно меньшей степени
сказывается влияние конкретного
фонемного состава произносимого
материала (Арутюнян, 1966, 1967).
Таким
образом, видно, что организация
акустических сигналов речевого
потока в какой-то мере оказывается
определяемой уже особенностями речевого
дыхания. Это касается прежде всего
таких характеристик, как громкость,
интонация, фразовые ударения, обычно
называемых просодическими. Их влияние
распространяется на отрезки речевого
потока, заведомо большие, нежели
длительность отдельных фонем.
Действия
дыхательной системы определенным
образом координированы с моторной
активностью гортани и периферических
артикуляторов. Если рассматривать
особенности активности гортани как
одного из важнейших участков образования
непрерывного речевого сигнала, то
в механизме управления ею прежде всего
следует выделить движения, определяющие
возникновение фонации, и движения,
регулирующие высоту основного тона
голоса.
Рис.
162. Изменения внутрилегочного давления
(Рд)
и объема воздуха, содержащегося в
легких (7Л)
при произнесении модельной фразы «у
папа папа папа» с изменяющимся логическим
ударением: а
—
на первом, б
—
на втором, в
—
на третьем слове «папа» (по: Арутюнян,
1967).
Лар
—
сигнал ларингофона, Вр
—
отметка времени 1 сек.
438

Основным
движением, обеспечивающим «пуск» —
включение голосового источника при
создании вокализованных звуков (гласных
и звонких согласных), — является сведение
голосовых связок. Последнее
обеспечивает возникновение резкого
сужения в речевом тракте на уровне
голосовой щели и при наличии достаточного
перепада давления на связках ведет к
возникновению колебательных движений
последних.
Изменения
частоты колебаний голосовых связок
обеспечиваются главным образом благодаря
изменениям степени их натяжения, которое
и является основным параметром
«управления». Характерный пример,
показывающий сложность управления
артикуляцией, представляет следующее
явление. При артикуляции глухих
смычных согласных, окруженных гласными
(такие звукосочетания, как [ара]),
несмотря на прекращение фонации во
время смычного звука голосовые связки
остаются в состоянии активного натяжения.
Об этом говорит тот факт, что траектория,
описывающая изменения частоты основного
тона предшествующей и последующей
гласных, оказывается непрерывной даже
на участке смычного согласного, где
колебания голосовых связок останавливаются
(Венцов, 1966). Фонация в этот момент
прекращается благодаря уменьшению
перепада давления на голосовой щели
ниже критической величины, при
которой еще поддерживаются колебательные
движения связок. Это вызывается быстрым
возрастанием положительного давлёния
в ротовой полости. Одно из возможных
объяснений последнего явления сводится
к открытию хрящевой щели («шепотного
треугольника»), находящейся в гортани
позади голосовых связок (Венцов, 1969).
Приведенный
пример снова показывает, что определенные
элементы управления артикуляцией
остаются едиными для участков,
охватывающих ряд фонем.
Основным
видом движений, которые происходят в
находящихся еще более дистально отделах,
является сближение или разведение
стенок в определенных местах трубки,
образующей речевой тракт, и изменение
ее конфигурации. При фонации гласных
звуков имеет место такое положение,
когда сохранен проход воздуха вдоль
всего речевого тракта, а конфигурация
составляющих его полостей определяет
произносимый звук. Для согласных же
звуков характерно образование
резкого сужения или даже возникновение
полного смыкания стенок в некотором
достаточно строго локализованном
для данного звука месте по ходу речевой
трубки. В результате при речи
непрерывно происходят определенным
образом организованные возвратно-поступательные
движения артикуляторов, которые и
являются основой возникновения
чередующейся смены согласных и гласных
звуков, составляющих непрерывный
речевой поток (рис. 163).
Координированная
моторная активность всего речеобразующего
аппарата несомненно предполагает
наличие сложных процессов 440
«программирования»
управляющих сигналов, возникающих в
нервной системе. Исходя из желания
получить хотя бы исходные данные по
этому весьма сложному вопросу, было
проведено исследование, касающееся
главным образом временных особенностей
организации непрерывного речевого
потока (Чистович и др., 1965).
С
помощью системы датчиков, преобразующих
движения артикуляторов, а также
потоки и движения воздуха в электрические
5
1
1
02
ОЛ сек.
Рис.
163. Пример движений артикуляторов,
имеющих место при речеобразо- вании
(произнесение звукосочетания [epip]) (по:
Stevens, 1964).
Данные
получены с помощью измерений серии
кино-рентгенов-
ских кадров. Графики
показывают изменение во времени
вели-
чин, показанных на схематическом
изображении сечения рече-
вого
тракта: Dp
—
расстояние между губами; By — расстояние
по
вертикали от твердого нёба до отмеченной
точки на спинке
языка; Dp
— ширина глотки на некотором уровне
над голосовой
щелью.
сигналы
(рис. 164), имелась возможность получать
достаточный объем экспериментального
материала, описывающего реальную
моторную активность, лежащую в основе
непрерывного акустического потока
речи. Изучались особенности временнбй
организации деятельности артикуляторов
на участках речевого потока разной
протяженности: синтагм, слогов, элементов
слога.
Одним
из выводов исследования явилось
представление о том, что основными
элементами, из которых составляется
связный поток устной речи, являются
слоги, причем слоги открытые, т. е.
оканчивающиеся гласным. Есть основания
полагать, что и при образовании
«программ» артикуляции управляющие
сигналы оказываются в какой-то мере
связанными в группы длительностью
порядка слога. Изучение этих вопросов
помогает в понимании, например, такого
явления, как коартикуляция: переслаивание
441


в
акустической картине признаков,
характерных для звуков, следующих один
за другим в речевом потоке (Ohman, 1966).
Принципы
анализа речевых сигналов. Наибольшее
применение для анализа речевых сигналов
нашли хорошо известные методы частотного
спектрального разложения. Практическое
осуществление метода может быть
пояснено рис. 165. Исходный сложный
Рис.
164. Пример комплексной регистрации
артикуляторных и акустиче-
ских
параметров (Кожевников и Шупляков,
1962).
1
—
сигналы датчика, регистрирующего
смыкание губ; 2
—
сигналы смычки языка с нёбом по
срединной линии; 3
—
сигналы смычки передней части языка с
нёбом в точках, отстоящих на 5 мм от
срединной линии; 4
—
сигналы датчика, регистрирующего поток
воздуха из ротовой щели; 5
—
сигналы датчика, регистрирующего поток
воздуха из носовых отверстий; 6
—
огибающая сигнала ларингофона; 7
—
огибающая сигнала микрофона; 8
—
отметка времени 1 сек. Внизу обозначены
произнесенные слова.
сигнал
S
(t)
подается на вход фильтра <р,' пропускающего
лишь колебания некоторой ограниченной
области частот. Для того чтобы определить
интенсивность отфильтрованных колебаний,
они выпрямляются детектором D
и поступают на фильтр низких частот,
которым обычно является сглаживающая,
интегрирующая цепочка I.
Выходной сигнал может измеряться
стрелочным прибором, подаваться на
электронную вычислительную машину,
регистрироваться тем или иным
способом.
Если
постепенно изменять частоту настройки
фильтра, повторно подавая на его вход
один и тот же изучаемый отрезок сигнала,
или же использовать целый набор фильтров
с близко расположенными частотами
настройки и подавать сигнал одновременно
на входы
442
всей
системы фильтров, то можно разложить
исходный сложный сигнал на целый ряд
компонент и получить его описание,
подобное изображённому на рис. 166. Этот
рисунок представляет изображе-
Рис.
165. Блок-схема простейшего
частотного
анализатора.
Объяснения
в тексте.
ние
процессов, происходящих в анализаторе
в том случае, когда на его вход в момент
времени tQ
было подано напряжение, состоящее
из двух синусоидальных колебаний
различных частот. Видно,
Рис.
166. Процесс установления показаний
анали-
затора во времени (по: Харкевич,
1957).
Ось
С
—
интенсивность колебаний; ось т
—
частота; ось
t
—
время. Остальные объяснения в тексте.
что
должно пройти некоторое время, прежде
чем эти компоненты начнут разделяться.
При спектральном анализе действует
своего рода «принцип неопределенности»,
заключающийся в том, что при увеличении
разрешающей способности по частоте
неизбежно нужно увеличивать время
анализа, а повышение разрешения временных
подробностей сигнала ограничивает
различение его частотных
443![]()
![]()

компонент.
Ситуация приближенно может быть
охарактеризована произведением AFxAJ=l,
где AF — разрешающая способность по
частоте, в гц, — разрешающая способность
по времени, в сек.
Выбор
характеристик фильтров, детектора и
интегрирующей цепочки зависит от задач
производимого анализа. Так, если
необходимо получить исходные данные
для выбора частотных характеристик
каналов связи, по которым передается
речевой сигнал, то время анализа можно
сделать произвольно большим и получить
высокое частотное решение. Наоборот,
производя измерения при достаточно
широких полосах фильтров, можно получить
подробное описание временной
динамики, имея, однако, лишь небольшое
число отсчетов по шкале частот.
Существенным
является вопрос, как представить
результаты анализа такого изменяющегося
во времени сигнала, каковым является
речь. Возможно получать через определенные
промежутки времени изображения с осями
частота—интенсивность. Такие
«спектральные разрезы», последовательно
повторяемые через достаточно короткие
промежутки времени, могут достаточно
точно представить динамику сигнала.
Однако такой вид изображения является
громоздким и недостаточно наглядным.
Широкое
р аспространение в исследованиях речи
получил способ анализа, известный под
названием «видимая речь» или динамическая
спектрография. В наиболее известной
модификации прибора анализируемый
отрезок речи (обычно около 2.5 сек.),
записанный на магнитный носитель,
многократно воспроизводится. На
диаграмме, отражающей результаты
анализа (на тепловой, электрочувствительной
или фотобумаге), вычерчивается линия,
степень черноты которой отражает
интенсивность выходного сигнала
фильтра. С каждым циклом частота
настройки фильтра сдвигается, на
диаграмме вычерчивается новая линия,
несколько сдвинутая от предыдущей. В
результате возникает трехмерное
изображение с осями: время, частота,
интенсивность. В приборах обычно
используется принцип гетеродинного
анализатора, наиболее часто полоса
пропускания фильтра берется довольно
широкой — 300 гц.
Получающаяся
в этих условиях картина (рис. 167) отличается
довольно высоким разрешением во времени.
При работе голосового источника четко
намечаются вертикальные линии (7), каждая
из которых отражает отдельный цикл
колебания голосовых связок. Это является
показателем высокой разрешающей
способности по времени. Вместе с тем
достаточно наглядными оказываются и
особенности распределения интенсивности
по оси частот. Можно наблюдать положение
отдельных формант (2)
и их движение вдоль оси частот (5). Четко
выделяются участки шумных звуков (4),
паузы при полных смычках (5).
При
желании повысить разрешение по оси
частот анализ может производиться и с
помощью более узкополосного фильтра
(обычно
444
45
гц). Определенные ограничения точности
анализа связаны с малым диапазоном
величин, который можно зарегистрировать
по оси интенсивностей в виде изменения
степени почернения материала, на
котором изображаются результаты. Но и
здесь можно достигнуть определенного
улучшения путем предварительного
сжатия диапазона регистрируемых
сигналов. В последнее время для этой
цели применяется также техника нанесения
отметок, обозначающих на диаграмме
различные уровни интенсивности.
^^Изображения сигналов в виде динамических
спектрограмм пользуются заслуженной
популярностью среди исследователей
Рис.
167. Динамическая спектрограмма фразы
«Тоня топила баню».
Вдоль
оси абсцисс
анализируемая фраза (написана в знаках
фонетической транскрипции); по
оси ординат —
частота анализируемого сигнала.
Остальные объяснения в тексте.
речи.
Уже в первых применениях «видимой речи»
большое внимание обращалось на технику
ее чтения (Potter et al., 1947). Однако все-таки
приходится отметить, что в этом
направлении были достигнуты относительно
ограниченные успехи. Достоверность
обнаружения и точность количественной
оценки наблюдаемых параметров оставляет
желать лучшего. Благодаря амплитудной
компрессии пропадает информация,
связанная с изменениями интенсивности
сигнала, далеко не всегда четко выделяются
форманты, с трудом поддается измерению
основная частота голоса.
В
последнее время все большие успехи
достигаются в разработке приемов и
способов автоматизированного выделения
и измерения определенных параметров.
Прежде всего сюда относятся работа
голосового и шумовых источников, частота
основного тона голоса, выделение формант
и слежение за изменениями их частоты.
Особенно большие перспективы в этом
направлении открывает применение
электронных вычислительных машин.
Проводящиеся исследования большей
частью связаны с проблемой автоматиче-
445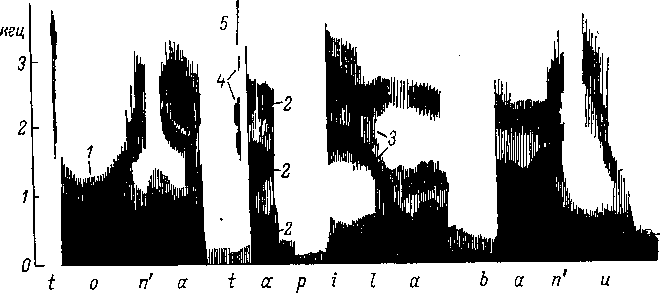
ского
распознавания речи и заслуживают
отдельного рассмотрения.
Принципы
синтеза речевых сигналов. Проблема
искусственного создания звуков речи
привлекает внимание с давних пор. Еще
в конце XVIII в. Кемпеленом была создана
довольно совершенная говорящая машина.
Роль легких выполняли меха, «речевой
тракт» представляли ящички, колеблющиеся
язычки и мягкая трубка, соответствующим
образом управляемые руками оператора.
Машина могла имитировать, вероятно,
более 20 речевых звуков, возможно было
создавать даже некоторые короткие
фразы. Позже были созданы и другие
механические устройства синтеза.
Определенный интерес к подобным
моделям не угас и до настоящего времени
(Ladefoged, 1964; Anthony, 1965).
Однако
существенное развитие способы сицтеза
речевых сигналов получили только
на базе электрических устройств,
использующих достижения электроакустики
и электроники. Известно большое число
разработанных систем, выполненных
разнообразными способами (Сапожков,
1963; Фланаган, 1968), но в принципах
подхода к синтезу можно выделить две
основные группы: полосные методы и
формантные методы.
Полосные
методы синтеза представляют основной
интерес для конструкторов систем
синтетической телефонии. Для того чтобы
сократить частотную полосу канала
связи, по которому требуется передать
речь, может быть применен способ,
осуществляемый в так называемых
полосных вокодерах. Процедура заключается
в анализе сигнала передаваемой речи с
помощью набора порядка 10—20 и более
полосовых фильтров и передачи по каналу
связи данных о изменениях интенсивности
колебаний в каждом из фильтров. На
приемном конце сигнал снова синтезируется
путем, грубо говоря, суммации сигналов,
которые возбуждаются согласно
сигналам управления, передаваемым по
каналу связи, в наборе частотных полос,
эквивалентных таковым в анализаторе
передающего конца.
Для
описываемых в настоящей главе исследований
значительно больший интерес представляют
иные методы синтеза, идущие по пути
аналогии с реальными процессами,
происходящими при речеобразовании,
методы, часто обозначаемые как
формантные. Не имея возможности хоть
в какой-то мере полно охватить все
разнообразные системы, рассмотрим в
качестве примера принципы устройства
типичного современного аналогового
синтезатора, используемого в Лаборатории
передачи речи Стокгольмского
технологического института и
известного под маркой OVE III (Liljen- crants,
1967).
В
синтезаторе (рис. 168) источниками энергии
создаваемых колебаний служат два
генератора. Генератор последовательности
импульсов треугольной формы (7)
представляет голосовой источник. Под
влиянием управляющего сигнала его
частота изменяется,
446
что
отражает изменение основной частоты
голоса. Второй генератор {12)
создает шумовые колебания, воспроизводящие
действие шумовых источников.
Колебания
от генераторов попадают в систему, в
которой основными являются элементы
с управляемым усилением и управляемые
частотные фильтры. Такие фильтры, у
которых под влиянием электрических
управляющих сигналов изменяется как
положение резонансной частоты, так
и ширина полосы пропускания являются
важными элементами формантных
синтезаторов. Эти
Рис.
168. Блок-схема синтезатора речевых
сигналов OVE III
(по: Liljencrants, 1967).
Объяснения
в тексте.
фильтры
моделируют резонансное действие
полостей речевого тракта.
Для
образования гласных звуков служат
четыре таких последовательно
включенных фильтра (4, 5, 6, 7), обеспечивающих
появление в выходном сигнале четырех
формант. Управляемыми параметрами
являются: уровень интенсивности сигнала
от голосового источника; резонансные
частоты и ширина полос всех формантных
фильтров.
Эффект
подключения носовых полостей при
образовании назальных звуков
достигается благодаря прохождению
колебаний голосового источника через
параллельную ветвь, имеющую лишь один
формантный фильтр (8)
и управляемый усилитель (9). Третья ветвь
служит для образования шумных фрикативных
согласных. Она состоит из двух формантных
фильтров {14,
15)
и одного «анти- формантного» фильтра
{13),
производящего подавление частот в
определенной области, положение
которой также изменяется отдельным
управляющим сигналом. Необходимость
введения специаль
447
ных
фильтров для образования шумных звуков
связана с тем, что место положения
шумового источника перемещается по
трубке речевого тракта, шумовые звуки
образуются при разведенных голосовых
связках. Влияние этих факторов делает
акустические условия отличными от тех,
которые имеются при образовании гласных.
Важный
для английского и ряда иных языков
эффект возникновения аспирационного
шума (результат турбулентности,
возникающей в районе голосовой щели
при неколеблющихся голосовых связках)
производится с помощью регулируемого
усилителя (11),
подмешивающего
определенную долю шумовых колебаний
к сигналу голосового источника.
Выходные
сигналы всех трех ветвей — гласных,
назальных и шумных звуков — складываются
на электронном сумматоре (10)
и
образуют выходной речеподобный сигнал.
Подобная
электрическая система воспроизводит
как действие источников акустических
колебаний, так и эффекты частотной
фильтрации, имеющие место в речевом
тракте. Однако для того чтобы производить
связные речевые сигналы, она требует
сложной системы управляющих сигналов.
В
OVE III и ряде иных современных синтезаторов
для этой цели используются цифровые
электронные вычислительные машины.
Если ЦЭВМ имеет память значительного
объема, то с ее помощью могут быть
синтезированы достаточно длинные куски
речи. Однако важнейшей проблемой
остаются те закономерности, которым
должны следовать управляющие сигналы
для создания определенных звуков и
особенно для обеспечения естественных
переходов при сочетании звуков в слитную
речь.
В
данном направлении ведутся интенсивные
исследования, достигнуты значительные
успехи. С помощью ряда разработанных
систем удается получать слитную речь
весьма естественного звучания. Для
аспектов исследования, которых касается
настоящая глава, синтез речеподобных
звуков является очень важным
экспериментальным приемом. С помощью
электронного синтезатора или даже
более упрощенных устройств можно
создавать сложные речеподобные
звуки, все физические характеристики
которых строго задаются. Подобные
сигналы широко используются в
исследованиях восприятия речи.
ФОНЕМНЫЙ
ОБРАЗ РЕЧЕВОГО СИГНАЛА
Гипотезы
о природе фонем. Как
только проблемой восприятия речи начали
заниматься физиологи и психологи,
возник вопрос о том, с какого рода
сигналами в нервной системе могут быть
идентифицированы фонемы. Вопрос имел
отнюдь не праздный характер, так как
от его решения зависел выбор методов
исследования.
448
Развитие
представлений по этому вопросу нашло
отражение в ряде работ, посвященных
защите моторной теории восприятия
речи, ее обсуждению и критике (Liberman,
1957; Stevens, 1960; Liberman et al., 1962; Чистович, 1961,
1962; Fant, 1964; Lane, 1965; Галунов и Чистович,
1965; Liberman et al., 1967).
реакция
Рис.
169. Схематическое представление различных
гипо-
тез о физиологической природе
фонем.
1
—
фонемы отождествляются с кинестетическими
образами, возникающими при осуществлении
артикуляторных движений; 2
— фонемы
отождествляются с моторными командами
к артикуляторным органам; 3
—
фонемы отождествляются с абстрактными
обозначениями, одновременно
представляющими подмножества слуховых
изображений и инструкции к синтезу
(или выбору) артикуляторного комплекса.
Схемы,
показанные на рис. 169, иллюстрируют
эволюцию идей за прошедшее десятилетие.
Сначала фонемы связывались с обратными
кинестетическими сигналами, возникающими
у слушателя при «скрытом» проговаривании
воспринимаемого сообщения (схема 7).
Наличие мышечной активности артикуляторов
при слушании речи было показано
экспериментально (Соколов, 1960). Однако
29
Сенсорные системы
449
эта
точка зрения встречала слишком много
возражений (Lane, 1965; Галунов и Чистович,
1965; MacNeilage, Rootes, 1967) и была вскоре отвергнута.
На
следующем этапе развития представлений
фонемы связывались с моторными
командами к мышцам артикуляторов (схема
3). Эта точка зрения также вызывала
серьезные возражения, так как
характеристики моторных команд
принципиально должны были зависеть от
многих факторов (контекст, громкость
и темп речи, конкретные условия
речеобразования).
В
настоящее время большинством
исследователей принимается, что фонемы
представляют собой абстрактное
надсенсорное и надмоторное описание
речевых элементов (схема 3).
Если рассматривать фонему с точки
зрения речеобразования, она является
набором инструкций к синтезу (или
выбору) артикуляторного комплекса.
Если говорить об акустическом речевом
сигнале, то фонема является обозначением
подмножества сигналов, обладающих
определенными свойствами.
Переход
от слухового описания сигнала (Л на
схеме 3)
к набору инструкций для синтеза
артикуляторного комплекса логически
необходим для того, чтобы человек мог
воспроизвести (повторить) услышанный
им речевой сигнал.
Существенное
допущение, которое делают исследователи,
принимающие схему 3, состоит в том,
что последовательность наборов таких
инструкций, возникшая при восприятии
слова или фразы, не только запоминается
(это не вызывает сомнений), но и является
тем описанием сообщения, с которым
имеют дело следующие блоки анализа
речи, обеспечивающие понимание смысла
сообщения.
Еще
одно допущение состоит в том, что человек
не только запоминает эти наборы
инструкций, но может их сравнивать
между собой (устанавливать их тождество
или различие, степень сходства) и
обозначать символами — буквами.
Предполагается возможным, что число
известных человеку букв меньше числа
различных наборов инструкций —
психологических фонем. .
Эти
допущения лежат в основе методов,
лрцменяющихся для экспериментального
исследования восприятия речи. Методы
включают изучение характеристик
имитации речеподобных сигналов и
обозначения их буквами, парное сравнение
стимулов.
Реальность
фонем как субъективных образов речевых
стимулов. Реальность
фонем как абстрактных описаний (образов)
речевых стимулов, используемых при
запоминании стимулов и сравнении их
между собой, была доказана в основном
методом сравнения функций идентификации
с функциями различения. Этим методом
были получены все данные, касающиеся
согласных.
Согласные.
В экспериментах применялись синтетические
речеподобные стимулы, образующие ряд
по какому-то из полезных акустических
признаков стимула. На рис. 170 приведены
стимулы, применявшиеся в работе Либермана
и др. (Liber
450
man
et al., 1957). Они образуют ряд по значениям
разности между частотой F
2
в начальный момент времени и частотой
F2
на
стационарном участке слога.
Для
получения функций идентификации
стимулы, следующие друг за другом в
случайном порядке, записывались на
магнитофонную ленту и предъявлялись
испытуемым. Испытуемые должны были
записывать в ответ на каждый стимул
букву, обозначающую
Рис.
170. Формантная картина 14 синтетических
стимулов,
применявшихся в работе
Либермана и др. (по: Liberman
et al., 1957).
Нижний
график
является продолжением верхнего.
По оси абсцисс — время,
по
оси ординат —
частота. Цифры 1, 2, . . 14
являются.
условными
обозначениями стимулов. Для стимулов
1—13
показан только начальный участок
стимула, стимул 14
приведен полностью. Нижняя
темная полоса
представляет первую форманту (Г\),
верхняя — вторую форманту (Г2),
Стимулы 1, 2, . . ., 14
отличаются друг от друга по начальному
значению F2
и соответственно по направлению и
скорости изменения F2
на переходном участке.
ту
фонему, на которую этот стимул больше
всего похож. Разрешенный набор букв
был обычно ограничен экспериментатором
(метод форсированного выбора).
Пример
функции идентификации для одного из
испытуемых в работе Либермана и др.
(Liberman et al., 1957) приведен на рис. 171. Можно
видеть, что применявшийся ряд стимулов
разделяется на три области, одна из
них связана с фонемой [Ъ|, вторая —
с фонемой [d], третья — с фонемой [g].
Область стимулов, относимых к одной
фонеме, была названа фонемной категорией.
Естественно,
что при каком-то значении стимула ответы
[Ь] и [d] будут равновероятны. Это значение
называется фонемной границей между
[Ь] и [d] по исследуемому признаку.
29*
451
После
того как функция идентификации (рис.
171) получена, можно проверить предположение,
что при запоминании и сравнении
стимулов испытуемый действительно
пользуется фонемами как субъективными
описаниями этих стимулов. Будем
предъявлять испытуемому триады типа
х.,
x.+l,
х.\ х.,
я.+1,
хм
(или х.,
**7+2,
xi\
xi+v>
^+2), гДе
* “ порядковый номер стимула в ряду по
значениям акустического параметра, и
попросим испытуемого определять, с
первым или со вторым звуком в триаде
совпадает последний звук. Этот метод
называется методом АВХ-сравнения.
Построив такие триады для всех значений
i
и предъявив их испытуемому, мы получим
функцию различения — вероятность
правильного
ответа испы-
туемого в зависимости
от
положения стимулов по
шкале
акустического пара-
метра. Зная
функцию иден-
Рис.
171. Функция идентифи-
кации для
стимулов, изобра-
женных на рис. 170
(по: Li-
berman et al., 1957).
По
оси абсцисс
указан номер сти-
мула, по
оси ординат —
процент
опознавания стимула как
слога,
начинающегося с согласного
[Ь ]
(белые
треугольники), [^] (черные
с белым
треугольники)
и [d] (чер-
ные
треугольники).
тификации,
легко вычислить теоретические значения
функции различения при предположении,
что вся информация о стимуле, которую
испытуемый может запомнить, сводится
к знанию выбранного в ответ на стимул
фонемного символа. Не останавливаясь
на процедуре вычислений (она достаточно
проста), укажем только, каких эффектов
следует ожидать. Если хГ
и ^+1-стимулы
находятся внутри одной и той же
фонемной категории, т. е. воспринимаются
как один и тот же согласный в 100% случаев,
ответы испытуемого должны быть
случайными, значение функции различения
должно быть равно 0*5. Если х.-
и а^+1-стимулы
принадлежат разным категориям, значение
функции различения должно быть больше
0.5. Оно будет равно 1.0, если ^.-стимул
всегда воспринимается как один
согласный, а ;г.+1-стимул
всегда воспринимается как другой
согласный. Иначе говоря, функция
различения должна быть близка к 0.5 на
интервалах, лежащих внутри фонемных
категорий, и она должна иметь пики
вблизи фонемных границ. В работе
Либермана и др. (Liberman et al., 1957) при
исследовании функции различения
применялись стимулы, различающиеся на
одну градацию признака (х^х
i+1),
на две градации (ж., xi+2)
и на три градации (xi9
xi+3).
Полученные данные (для того же испытуе
452
мого,
функция идентификации для которого
приведена на рис. 171) показаны сплошными
кривыми на рис. 172. Пунктирными кривыми
приведены теоретические значения
функции различения, вычисленные на
основании функции идентификации.
Можно
видеть, что, пики вблизи фонемных границ
на экспериментальной функции
различения выражены достаточно
отчетливо, однако испытуемый оказывается
в какой-то мере способным различать
также стимулы, относящиеся к одной и
той же фонемной категории.
В
экспериментах последних лет (Liberman,
1968), когда техника синтеза была,
очевидно, улучшена, было получено лучшее
Рис.
172. Функция различения стимулов,
изображенных на рис. 170
(по: Liberman et
al., 1957).
По
оси абсцисс
указан номер х/ стимула, по
оси ординат —
процент правильных ответов. Сплошная
кривая —
экспериментально полученные значения,
прерывистая
— значения,
вычисленные на основании функции
идентификации. Данные для триад,
образованных из хг-
и х^х
стимулов (график а), из х/ и х/+2
стимулов (график б), и из и xi+з
стимулов (график в).
совпадение
между теоретическими и экспериментальными
значениями функции различения.
Принципиально
аналогичные данные были получены при
исследовании идентификации и
различения начальных глухих и звонких
смычных согласных.
В
различных языках выделяются три группы
смычных согласных: полностью звонкий
согласный, глухой неаспирированный
согласный и глухой аспирированный
согласный. В случае полностью звонкого
согласного (например, русские [b], [d], [g
1) голосовая щель смыкается значительно
раньше размыкания смычки, в случае
глухого аспирированного согласного
(например, английские [р], [t 1, [к])
голосовая щель остается открытой
некоторое время после размыкания
смычки.
В
качестве акустического коррелята этого
признака Лискер и Абрамсон (Lisker, Abramson,
1963, 1964) предложили принять параметр,
названный ими «время начала голоса».
Рис. 173, где приведены спектрограммы
слога с полностью звонким согласным
[di], глухим неаспирированным согласным
[ti] и глухим аспирированным согласным
[thi
], иллюстрирует способ измерения этого
453
параметра
на динамических спектрограммах. За
точку отсчета принимается момент
размыкания смычки согласного,
характеризующийся появлением энергии
в высокочастотной части спектра (шум
взрыва,
появление
энергии в области
второй
и более высо-
ких формант). Нача-
ло
голоса, если он
предшествует
размы-
канию смычки, опре-
деляется
по появле-
нию энергии в об-
ласти
основной ча-
стоты голоса. В слу-
чае
начала голоса
после размыкания
смычки
имеет место
не только появление
энергии
на основной
частоте и
появление
периодического ха-
рактера
всего сигна-
ла, но и резкое уве-
личение
амплитуды
первой форманты и
общей
энергии сиг-
нала.
Слоги,
приведен-
ные на рис. 173, ха-
рактеризуются
по па-
раметру «время на-
Рис.
173. Динамические
спектрограммы (а)
и
энергетические огибаю-
щие (б)
слогов [di], [ti]
и |thi]
(по: Abramson,
1967).
Стрелками
отмечен интервал времени между началом
колебаний голосовых связок и размыканием
преграды в [di] и интервал времени между
появлением шума и началом колебаний
голосовых связок в [ti] и [thi].
По
оси абсцисс
— время, по
оси ординат — интенсивность
(осциллограммы огибающей) или частота
в гц (динамические спектрограммы).
чала
голоса» значениями — 85, 15 и 110 й
мсек. Для исследования восприятия
был синтезирован набор из 37 стимулов,
крайние значения стимулов по параметру
были — 150 и -р 150 мсек., шаг между стимулами
10 мсек, за исключением области от —10
454
до
+50 мсек., где шаг равнялся 5 мсек.
Характеристики двух крайних
стимулов показаны на рис. 174. В данном
случае стимулы соответствуют
слогу с гласным [а ] и переднеязычным
взрывным согласным [d], [t], [th].
Аналогичным образом были синтезированы
слоги с губным согласным.
На
рис. 175 приведены результаты
идентификации губных согласных
группой из 12 слушателей-американцев
(Lisker, Abram- |
|
0 -10 9П |
Z |
|
|
|
|||||
2 ( |
|
774 |
— |
||
3 ( |
|
|
|
||
4 |
|
|
|
||
18 |
4400-5000 |
|
|
|
|
|
|
|
|
|
|
16 |
3350-3840 |
|
|||
|
|
|
|||
74 |
25602930 |
|
|||
12 |
19762230 |
Мннвнннвммвв •^ииииииииив—, |
|||
10 8 ~6~ 4 , 0 |
1500-1705 1150-1305 871-990 609-727 70-190 |
|
|||
j— 1 ( , |
-150
О +150 +300 +W 0 +150 +300 +Ь50 мсек.
Рис.
174. Схематическое изображение характеристик
двух синтетических слогов, один из
которых (слева)
начинается со звонкого согласного, а
другой (справа)
—
с глухого аспирированного согласного
(по: Abramson, 1967).
По
оси абсцисс —
«время начала голоса» в мсек, от условно
принятой точки отсчета, соответствующей
моменту размыкания смычки согласного.
По
осям ординат: 1 —
уровень интенсивности сигнала в дб, 2
— частота основного тона голоса (она
сохраняется постоянной на протяжении
сигнала и равна 114 гц), з
—
вид источника возбуждения (а
—
голосовой, б — шумовой), 4
—
частотный спектр сигнала; он определен
таким образом, что в каждой из 18 полос
(номер
полосы
и ее нижняя
и верхняя
границы
в гц указаны в двух соответствующих
столбцах в левой части рисунка) энергия
сигнала имеет максимальное значение
в областях, отмеченных черным,
и минимальное — вне этих областей.
son,
1967). Столбиками показаны значения по
данному параметру естественных [Ь ] и
[р 1 в английском языке.
На
рис. 176 приведены функции различения,
полученные на группе слушателей-американцев
(Lisker, Abramson, 1967). При определении функции
различения испытуемым предъявлялись
6 возможных триад: х,,
xi+k,
х<; х., xi+k,
xi+k,
xv
xv
xi+k,
xi+k,
xi+k,
x.; xi+k,
xv
xi+k;
xi+k,
x^ xr
(K = 2,
3, 4). Задача испытуемого состояла в
определении того, какой (первый, второй
или третий) стимул в триаде отличается
от двух остальных. Вероятность случайного
отгадывания в этом случае pai на 0.33.
Сравнение рис. 175 и 176
455
Рис.
175. Функции идентификации для синтетических
слогов, упорядочен-
ных по параметру
«время начала голоса», полученные на
группе слушателей-
американцев (по:
Lisker, Abramson, 1967).
По
оси абсцисс —
«время начала голоса» в мсек.: по
оси ординат —
процент опознавания [Ь] (пунктирная
кривая)
и [р] (сплошная
кривая).
Соответственно пунктирными
и черными
столбиками
показаны гистограммы, полученные при
измерении «времени начала голоса» в
естественных [Ы и [р] в слогах СГ,
находящихся в начале слова.
Рис.
176. Функция различения синтетических
слогов, упорядоченных по параметру
«время начала голоса», полученная на
группе слушателей-американцев (по:
Abramson, Lisker, 1967).
Данные
для триад, образованных из xi
и Xi+2
стимулов (сплошная
линия), из
Х{
и Xi+3
стимулов (прерывистая)
и из. Xi
и х^
стимулов (пунктирная).
По оси абсцисс
— среднее значение «времени начала
голоса» в мсек, для х2
и
Xi+j
стимула (/ = 2, 3, 4); по
оси ординат
— количество правильных ответов в
процентах. Вертикальной
линией
показано положение фонемной границы
между [Ь] и [р], определенное в опытах по
идентификации.

Рис.
177. Функции идентификации для синтетических
слогов, упорядочен-
ных по параметру
«время начала голоса», полученные на
группе слушателей-
таиландцев (по:
Lisker, Abramson, 1967).
По
оси абсцисс —
«время начала голоса» в мсек.; по
оси ординат —
процент опознаний [Ъ]
(пунктирная
кривая),
[р] (сплошная
кривая)
и [ph]
(прерывистая
кривая)*
Соответственно
пунктирными,
сплошными и прерывистыми столбиками
показаны гистограммы, полу-
ченные
при измерении «времени начала голоса»
в естественных [Ъ], [р] и [pj в слогах
СГ,
находящихся в начале слова.
Рис.
178. Функция различения синтетических
слогов, упорядоченных по параметру
«время начала голоса», полученная на
группе слушателей-таиландцев (по:
Abramson, Lisker, 1967).
Данные
для триад, образованных из и х^+2
стимулов (сплошная
линия),
из Xi
и Xi+3
стимулов (прерывистая)
и из Xi
и х^
стимулов (пунктирная).
По оси абсцисс —
среднее значение «времени начала
голоса» в мсек, для Х{
и х/+у стимула (j
= 2, 3, 4); по
оси ординат
— количество правильных ответов в
процентах. Вертикальными
линиями
показаны положения фонемных границ
между [Ь] и [р] (слева)
и между [р] и [ph]
(справа),
определенные в опытах по идентификации.

показывает,
что пик на функции различения совпадает
с положением границы между [Ь ] и [р]
на функции идентификации.
Заключение
о том, что человек пользуется фонемами
в качестве описания стимулов, становится
особенно убедительным благодаря
несовпадению данных, полученных для
носителей английского языка, с данными,
полученными для носителей языка таи.
В этом
Рис.
179. Функции идентификации (нижний
график)
и различения (верхний
график)
для синтетических щелевых согласных
(по: Fujisaki, Kawashima, 1968).
По
оси абсцисс —
значения частоты полюса в кгц,
использованные при синтезе этих
согласных; по
оси ординат на верхнем графике —
процент правильных ответов (АВХ
различения), на
нижнем графике —
процент опознания фонемы (s) кружки
—
данные, полученные для синтетического
слога СГ; крестики
— данные, полученные для изолированного
синтетического щелевого согласного.
Рис.
180. Характеристики ими-
тации
синтетических гласных (по:
Ghistovich et
al., 1966).
По
оси абсцисс —
номер синтетического гласного стимула;
по
оси ординат — значения
частот в кгц первой и второй формант
гласных-стимулов (точки)
и
гласных-реакций (крестики).
Частота форманты для гласных-реакций
определялась как среднее арифметическое
из значений частоты форманты, измеренных
на спектрограммах 36 гласных-реакций,
созданных в ответ на данный гласный-стимул.
языке
имеются все три согласных, различающиеся
по параметру «время начала голоса»:
полностью звонкий согласный, глухой
неаспирированный, глухой аспирированный.
На рис. 177 и 178 приведены функции
идентификации и различения для
таиландцев. В данном случае на функции
различения имеется два пика, близкие
к положению границ между [Ь] и [р ] и [р]
и [ph
1.
В
работе Фужизаки и Кавашимы (Fujisaki,
Kawashima, 1968) исследовалась идентификация
и различение 11 синтетических глухих
фрикативных согласных звуков. Частота
полюса (резо-
458

панса)
задавалась в пределах от 3000 до 7810 гц.
Частота нуля (антирезонанса) была равна
1 /2 частоты полюса. Шумовой стимул
предъявлялся или изолированно, или в
СГ слоге с гласным [е ]. В экспериментах
по различению использовался тот же
метод (АВХ), что и в опытах Либермана и
др. (Liberman et al., 1957) по восприятию места
образования звонких смычных согласных.
Результаты
идентификации стимулов группой из 6
испытуемых приведены на рис. 179, низ.
Стимулы опознавались как фонемы [s ] или
[J ]. Положение границы, судя по графику,
не зависело от того, был ли согласный
изолированным или предъявлялся в слоге.
Функции различения приведены на рис.
179, верх.
Можно видеть достаточно явно выраженный
пик различения на границе между фонемами.
Все
приведенные выше данные не только
доказывают, что у человека имеется
весьма ограниченный набор субъективных
образов согласных, но и что этот набор,
очевидно, совпадает с набором фонем,
принимаемых лингвистами.
Гласные.
Вопрос о субъективных фонетических
образах гласных оказался значительно
более сложным. Сравнение функций
различения с функциями идентификации
не позволило сделать определенных
выводов, так как было показано, что
человек способен различать большое
число градаций стимулов (синтетических
гласных), относимых им к одной и той же
фонемной категории (Fry et al., 1962; Stevens,
1966; Stevens et al., 1969). Этот результат можно
было интерпретировать двояким образом.
Одна возможная интерпретация состояла
в том, что множество фонетических
образов гласных образует континуум.
Воспринимая гласный стимул, человек
определяет по нему, какую конфигурацию
нужно придать своему речевому тракту
для того, чтобы создать звук, наиболее
близкий к услышанному. Параметры этой
«наиболее подходящей» конфигурации
запоминаются и используются в качестве
фонетического описания гласного.
Следует заметить, что эта точка зрения
фактически разделяется большинством
фонетистов, которые верят, что,
прослушав гласный, они могут определить
его точное положение в так называемом
треугольнике гласных, т. е. определить
требуемую величину опускания нижней
челюсти и положение по передне-задней
оси точки максимального подъема спинки
языка.
Другая
возможная интерпретация состояла в
том, что человек способен запоминать
не только фонему (в данном случае следует
говорить о психологических фонемах),
выбранную в результате воздействия
стимула, но и какую-то дополнительную
информацию относительно спектральных
свойств стимула. В естественных условиях
эта информация может иметь отношение
к опознанию индивидуальности диктора.
Для
выбора между этими двумя гипотезами
были предприняты эксперименты по
имитации синтетических гласных
(Chistovich,
459
Fant,
Serpa-Leitao, Tjernlund, 1966). Параметры стимулов
былй подобраны так, чтобы наилучшим
образом отражать акустические свойства
речевого тракта испытуемого, который
должен был имитировать эти стимулы.
Следовательно, все стимулы, которые
предъявлялись испытуемому,
принципиально могли бы быть созданы
Рис.
181. Положение в двухформантной плоскости
синтетических гласных,
использованных
в экспериментах по психологическому
шкалированию (а),
и субъективные
расстояния между синтетическими
гласными, обозначенными
на а
номерами I, 2,
11,12,
и остальными гласными ряда (б) (по:
Голузина
1971).
На
а:
по оси абсцисс —
частота первой форманты, по
оси ординат —
частота второй. Номер около точки
является номером стимула. На б:
по оси абсцисс —
положение гласного (ху) на кривой
рис. а; по
оси ординат
— субъективное расстояние между этим
гласным и гласным, номер которого
(г)
указан на каждом из четырех графиков.
Сплошная
и
пунктирная
кривые
соответствуют разному порядку следования
стимулов в паре (х/ху или хух/).
его
речевым трактом как физической системой.
Задача испытуемого состояла в том,
чтобы с наибольшей возможной точностью
воспроизвести услышанный звук. На
каждый из гласных-стимулов было получено
по 36 гласных-реакций.
На
рис. 180 точками показаны значения частот
двух первых формант синтетических
гласных-стимулов; крестиками показаны
средние значения частот формант
гласных-реакций. Можно видеть, что на
несколько соседних стимулов испытуемый
отвечает одной и той же реакцией. Это
значит, что испытуемому известен только
460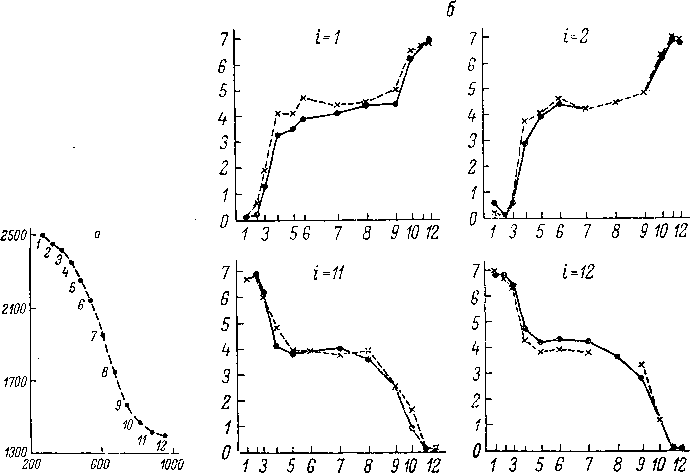
некоторый
конечный набор гласных-реакций, каждой
реакции соответствует определенная
область (категория) на множестве
стимулов.
Доказательство
того, что, запоминая гласный, человек
использует фонему в качестве описания
этого гласного, было получено в
экспериментах по прямому численному
шкалированию субъективного расстояния
между гласными-стимулами, приведенными
на рис. 180 (Голузина, 1971).
Фонемная
идентификация этих стимулов группой
русских слушателей показала, что
стимулы 1—3
воспринимаются как [i ], стимулы 4—9
— как [е], стимулы 10—12
—
как [а].
В
опытах по шкалированию испытуемым
предъявлялись 144 пары, образованные из
12 стимулов. На каждую пару было получено
по 50 ответов (оценок расстояния в
баллах). За субъективное расстояние
для данной пары принималось среднее
арифметическое из этих 50 оценок.
На
рис. 181, б
приведена зависимость субъективного
расстояния от расстояния между стимулами
на двухформантной плоскости (положение
стимулов в двухформантной плоскости
показано на рис. 181, а).
Можно
видеть, что зависимость имеет отчетливый
ступенчатый характер: субъективное
расстояние резко возрастает при
переходе от одной фонемной категории
к другой, оно мало меняется в пределах
фонемной категории.
Это
позволяет утверждать, что испытуемые
пользуются фонемами в качестве
описания стимулов и что расстояния,
которые они указывают, это расстояния
между фонемами.
Однако
такой ступенчатый характер зависимости
ярко выражен лишь в том случае, если
стимулы в оцениваемой паре принадлежат
к разным фонемным категориям. Так, если
один из стимулов в паре относится к
категории [i] (графики для i = l и i = 2 на
рис. 181), а другой к категории [е] или [а],
субъективное расстояние для всех пар
[i]— [е] (/=4, 5, ... 9) примерно одинаково и
существенно меньше, чем расстояние
для пар [Г]—[а] (/=10, И, 12).
Другая
картина наблюдается в том случае, когда
оба стимула в паре относятся к одной и
той же фонемной категории. На рис. 182
приведены зависимости, полученные для
пар [е—е]. Можно видеть, что субъективное
расстояние монотонно возрастает с
увеличением физической разницы между
стимулами. Этого не могло бы быть, если
бы информация о гласном, полученная
при его восприятии, ограничивалась
фонемным символом. Необходимо допустить,
что человек способен на какое-то время
запомнить не только фонему, выбранную
на основании услышанного стимула, но
и какие-то особенности звучания сигнала;
назовем это условно «тембральной
информацией». Если два сравниваемые
стимула оказываются разными фонемами,
тембральная информация является
избыточной и не принимается во внимание
при оценке расстояния.
461
Естественно
думать, что для запоминания фонемы
требуется меньший объем оперативной
памяти, чем для запоминания тембральных
особенностей стимула. Кроме того,
фонемное описание является более
существенным с поведенческой точки
зрения. Отсюда ло
Рис.
182. Субъективные расстояния между
гласными, принадлежащими к одной и той
же фонемной категории (стимулы 4—9
на рис. 181, а).
(ио:
Голузина, 1971).
По
оси абсцисс —
положение гласного (ху) на кривой
рис. 181, а;
по оси ординат —
субъективное расстояние между стимулами
хj
и
Xi.
Каждая пара кривых (сплошная
и прерывистая
кривые)
соответствует набору пар стимулов
с одним и тем же значением х/. Субъективное
расстояние для пар стимулов с j
> г
отложено вверх от горизонтальной
прямой, субъективное расстояние для
пар стимулов с j
< г
отложено вниз.
Рис.
183. Функции идентификации (нижний
график)
и различения (верхний
график)
синтетических гласных (по: Fujisaki, Ка-
washima, 1968).
По
оси абсцисс —
частота в гц первой форманты синтетического
гласного (частота второй форманты
изменяется в пределах от 2350 гц до 1840
гц, понижаясь с возрастанием F*); по
оси ординат на верхнем графике
показано количество правильных ответов
(АВХ различения) в процентах, на
нижнем графике —
количество опознания гласного как
[е] в процентах.
гично
ожидать, что фонемное описание стимула
должно запоминаться лучше и на более
длительный срок, чем тембральное
описание.
В
работе Фужизаки и Кавашимы (Fujisaki,
Kawashima, 1968) исследовалась идентификация
и различение синтетических [i ] и [е ]
гласных в условиях, когда после каждого
стимула следовал дополнительный,
мешающий звук ([а] длительностью 50
мсек.). Полученные результаты оказались
весьма близкими к тем, ко- 462

торые
ранее наблюдались для согласных. Из
рис. 183 видно, что на функции различения
имеется отчетливый пик, соответствующий
границе между фонемами [i ] и [е ]. Различение
стимулов, лежащих внутри фонемной
категории, оказывается плохим.
Итак,
полученные данные позволяют сделать
вывод, что множество фонетических
образов гласных также является
дискретным. По сравнению с согласными
вопрос более сложен тем, что, во- первых,
число психологических гласных фонем
может не совпадать с числом лингвистических
фонем и, во-вторых, человек способен на
короткое время запоминать не только
фонему, но и тембраль- ное описание.
Набор
психологических фонем. Сам
факт классификации речевых сигналов
при их восприятии является экспериментально
доказанным, вопрос о числе классов —
психологических фонем пока остается
открытым.
Несомненно,
что число психологических фонем не
может быть меньше числа фонем, принимаемых
лингвистами. Однако вполне возможно
предположить, что одной лингвистической
фонеме соответствует группа из
нескольких психологических фонем. Дело
в том, что лингвист обычно стремится к
тому, чтобы число фонем, принимаемых
им для описания данного языка, было
минимальным. Последовательно проводя
эту точку зрения, представители
московской фонетической школы
предлагают считать русские [ы] и [i ]
одной и той же фонемой. Так как [ы] и [i]
не встречаются в одинаковом окружении,
использование одного и того же символа
для их описания не приводит к появлению
неоднозначности сообщения. Вместе
с тем не вызывает сомнения, что [ы ] и
[i] относятся к разным психологическим
фонемам — им соответствуют различные
артикуляторные комплексы, избирательно
связанные у русского человека с двумя
разными категориями акустических
стимулов и с разными буквами.
В
работе Вербицкой (Вербицкая, 1965) и
Бондарко и др. (Бондарко и др., 1966) была
сделана попытка выяснить, сколько
классов гласных различает в русской
речи носитель русского языка.
Стимулами
служили сегменты естественных гласных,
вырезанные с помощью электронного
ключа из различных русских слов и
звукосочетаний. Испытуемым (50 человек)
предлагалось записывать эти стимулы
русскими или латинскими буквами с
добавлением диакритических знаков
в случае необходимости.
По
характеру полученных ответов можно
было совершенно надежно утверждать,
что гласные между твердыми и между
мягкими согласными относятся
испытуемыми к разным звуковым типам.
Исследование акустических особенностей
гласных в положении между мягкими
согласными показало, что они касаются
преимущественно второй форманты.
Частота F2
даже в точке минимума оказывается
существенно выше того значения, которое
463
она
принимает в соответствующем гласном,
произнесенном изолированно или
между твердыми согласными. Судя по
данным, приводимым авторами, эти
различия в F
%
особенно четко проявляются для гласного
[и] между мягкими и твердыми согласными
(например, тюль и тут).
В
упомянутой работе Бондарко и др. (1966)
такой же метод был применен для
исследования типов согласных, выделяемых
русскими слушателями. Целью
экспериментов являлось выяснение
вопроса, не выделяются ли огубленные
(произносимые в слогах с [о] и [и]) и
неогубленные согласные (в слоге с [а])
в отдельные классы. Результаты опытов
не дали положительного ответа. Вместе
с тем они показали, что при парном
сравнении человек легко различает эти
согласные.
Субъективное
пространство фонем. Рассмотрим,
как можно описать фонему, принимая, что
она обозначает, во-первых, некоторое
подмножество речевых сигналов, обладающих
заданными свойствами, и, во-вторых,
указания к синтезу артикуляторного
комплекса.
Один
из возможных способов описания состоит
в том, что каждая фонема представляется
символом, и этот символ никак не связан
с остальными символами.
Другой
способ состоит в том, что каждая фонема
описывается перечислением ее значений
по нескольким «дифференциальным»
признакам; при этом число признаков
существенно меньше числа фонем. Идея
такого описания фонем принадлежит
Трубецкому (1960), она была далее развита
Якобсоном, Фантом и Халле (Ja- kobson et al.,
1952).
Логичность
таких представлений достаточно очевидна,
если рассматривать фонему как указания
к синтезу артикуляторного комплекса.
Эти указания можно представить как
набор элементарных инструкций
относительно поведения разных органов
(губ, языка, голосовых связок).
Идея
об упорядоченности множества фонем,
сформулированная лингвистами,
находит свое подтверждение и в собственно
лингвистических закономерностях
(позиционные и комбинаторные изменения
звуков, исторические чередования и т.
д.). Описание этих закономерностей
является более экономным, если
представлять фонему не отдельным
символом, а перечислением ее значений
по дифференциальным признакам.
В
ряде работ, выполненных за последние
годы, были получены данные в пользу
того, что человек действительно
запоминает фонему в виде набора
значений по ряду признаков.
Для
того чтобы понять экспериментальные
подходы к этой проблеме, рассмотрим, к
каким следствиям логически приводит
переход от описания фонемы с помощью
символа к описанию ее набором значений
по признакам,
464
Примем
для простоты, что признаки двоичны (это
допущение делается Якобсоном и др.).
Придав каждому признаку определенный
порядковый номер, любой русский согласный
звук можно тогда представить кодовой
последовательностью из п
двоичных чисел (нулей или единиц), где
п
—
число признаков.
При
этом появляется возможность сравнения
разных согласных между собой и определения
расстояния между ними. Это значит, что
множество фонем можно рассматривать
как пространство.
Расстояние
между двумя согласными можно определить,
например, как число признаков, по
которым эти согласные имеют разные
значения.
Пользуясь
описанием русских согласных в терминах
дифференциальных признаков Якобсона
и др. (см.: Halle, 1959), легко построить матрицу
расстояний между всеми согласными.
Если
теперь экспериментально определить у
русских испытуемых матрицу субъективных
расстояний между согласными, можно
сравнить эти две матрицы. Если они
окажутся близкими, это будет
свидетельствовать в пользу дифференциальных
признаков, выбранных Халле.
Один
из методов экспериментального определения
матрицы расстояний состоит в том, что
испытуемым предлагается прямо в баллах
указать расстояние для каждой пары
фонем (согласные и гласные рассматриваются
отдельно).
Для
перехода от полученной совокупности
ответов к численной оценке расстояния
используются методы, разработанные
теорией психологического шкалирования
(Torgerson, 1958).
Интересный
метод, предложенный Викельгреном
(Wickelgren, 1965, 1966), базируется на предположении,
что при случайных искажениях кодовой
последовательности, возникающих,
например, при ее хранении в памяти, она
чаще всего будет переходить в те
последовательности, которые к ней
наиболее близки. Метод состоит в
следующем: испытуемым предлагается
прослушать серию из нескольких
звукосочетаний и затем по памяти их
воспроизвести или записать. В результате
многократного повторения таких
экспериментов строится матрица ошибок,
отражающая вероятности замены каждой
данной фонемы на все другие фонемы.
При
дальнейшем анализе данных предполагается,
что вероятность замены одной фонемы
на другую является монотонной убывающей
функцией от расстояния между фонемами.
Экспериментальные
данные, полученные для ряда языков
(Peters, 1963; Wickelgren, 1965, 1966; Галунов, 1967;
Hanson, 1967; Kasuyaet al., 1968), показали, что для
каждой^ фонемы действительно
существует «окрестность» наиболее
близких к ней фонем.
На
основании полученной матрицы расстояний
обычно строится соответствующая ей
геометрическая модель, которая
трактуется как модель субъективного
пространства фонем.
3()
Сенсорные системы
465
Модель
субъективного пространства японских
гласных (Ка- suya et al., 1968) приведена на
рис. 184. Эта модель является трехмерной,
ее оси ах,
«2,
рассматриваются как субъективные па
раметры
гласных.
Необходимо
обратить внимание на то, что непосредственным
результатом эксперимента является
матрица расстояний; модель,
построенная
на осно-
вании этой матрицы,
является
определен-
ной и достаточно
спе-
цифической трактов-
кой
результатов экс-
перимента.
Специфич-
ность этой трактовки
состоит
в том, что
априорно, без каких-
либо
доказательств,
принимаются два
весьма
существенных
допущения: 1) каж-
Рис.
184. Модель субъ-
ективного
пространства
японских гласных
(Ка-
suy а et al., 1968).
Четыре
верхних графика
построены
по данным от-
дельных испытуемых,
ниж-
ний
график
построен по
средним данным. аи
а2,
а3
—
оси субъективного про-
странства.
Точкой
показано
положение гласных [и],
[о],
[а], [е], [i] в субъективном
пространстве;
конец
верти-
кали,
опущенной из точки,
указывает
ее проекцию на
аГ,
а2-п
лоск ость.
дый
из параметров (осей пространства)
является непрерывным; 2) на пространстве
действует евклидова метрика.
Первое
из этих допущений находится в очевидном
противоречии с экспериментально
доказанным фактом, что множество фонем
не только конечно, но и достаточно мало.
Поэтому
научная ценность геометрических моделей
пространства фонем пока что вызывает
сомнения. Одной из наиболее существенных
теоретических задач в этой области
является разработка моделей с дискретной
метрикой.
Высота,
громкость и длительность как субъективные
признаки речевого стимула, Не
может быть сомнений в том, что ре- 466
Iпение
об ударении и интонаций основывается
па результатах сравнения двух или
более гласных (слогов) по длительности,
громкости и высоте. Это заставляет
предполагать, что для каждого отдельного
слога длительность, громкость и высота
запоминаются в форме чисел или значений
по некоторым непрерывным шкалам. Это
со-
Рис.
185. Характеристики имитации высоты
сигнала
(по: Чистович и др., 1968).
а
—
зависимость между средним значением
частоты основного тона звуков-реакций
(по
оси ординат)
и частотой стимула (по
оси абсцисс)', б —
стандартное отклонение значений частоты
основного тона звуков-реакций (по
оси ординат)
как функция от частоты имитируемого
стимула; в
—
суммарная гистограмма значений частоты
основного тона для всех звуков-реакций,
полученных в эксперименте. По
оси ординат —
частота основного тона, по
оси абсцисс —
число случаев.
ответствует
представлениям классической психоакустики
о существовании у человека непрерывных
субъективных шкал для этих параметров.
Исследования
характеристик имитации высоты, громкости
и длительности подтвердили правильность
этих представлений.
В
опытах по имитации изучалась зависимость
значения звука-реакции по определенному
физическому параметру (основная
частота, уровень интенсивности,
длительность) от зпаче- пия звука-стимула
по тому же параметру.
На
рис. 185 приведены характеристики имитации
высоты, полученные в экспериментах
Люблинской (Чистович и др., 1968). На графике
а
показана зависимость между частотой
стимула и
467
30*
средней
частотой реакций, вызванных этим
стимулом. Можно видеть, что эта
зависимость является монотонной. На
графике б
показано
стандартное отклонение реакций как
функция от частоты стимула. Видно,
что зависимость от частоты стимула
выражена слабо. График в
демонстрирует суммарную гистограмму
всех полученных в эксперименте реакций.
Можно видеть, что число пиков на
гистограмме равно числу стимулов,
значения пиков совпадают со средним
значением реакции на соответствующие
стимулы. Такая картина может
наблюдаться в том случае, если множество
реакций является непрерывным или если
число дискретных реакций существенно
больше числа стимулов и эти реакции
образуют одномерный ряд. В обоих случаях
зависимость реакции от стимула можно
аппроксимировать с помощью монотонной
непрерывной функции.
При
исследовании непрерывных преобразований
прежде всего встает вопрос о том, имеется
ли постоянная и однозначная связь между
физическими свойствами сигнала и его
описаниями в нервной системе или же
характер этой связи меняется в зависимости
от задачи, которую решает человек, и от
особенностей всего ансамбля сигналов,
с которым он имеет дело в каждом
конкретном случае.
Эксперименты
показали, что при требовании имитировать
высоту звуков, частота которых лежит
в пределах диапазона голоса, большинство
испытуемых создает с относительно
малыми случайными отклонениями
звуки с той же основной частотой, что
и частота предъявляемых стимулов
(Люблинская, 1968). Поведение испытуемых
не изменяется при изменении ансамбля
сигналов, предъявляемых в опыте. Факт
сохранения во всех случаях связи «один
к одному» между частотами стимулов и
реакций заставляет считать, что в
описании стимула сохраняется информация
об абсолютном значении частоты.
Иная
картина была обнаружена в опытах по
имитации высоты «немузыкальными»
испытуемыми (Люблинская, 1968) и в опытах
по имитации громкости звука (Малинникова,
1968). Рис. 186 показывает результаты
имитации громкости сигналов в условиях,
когда весь диапазон интенсивностей
сигналов составляет 40 и 8 дб. Можно
видеть, что в случае узкого диапазона
стимулов наклон прямой, описывающей
связь между стимулом и реакцией,
существенно возрастает. То же явление
наблюдалось и в опытах по имитации
высоты «немузыкальными» испытуемыми.
Увеличение
наклона прямой, возникающее при сужении
диапазона предъявляемых стимулов,
соответствует увеличению расстояния
между изображениями сигналов и,
следовательно, повышает их различимость.
Зная величину наклона и дисперсию
случайных отклонений, имеющих место
при преобразовании; можно рассчитать
ожидаемую различимость стимулов.
Оказалось, что теоретически рассчитанная
различимость хорошо совпадает
468
с
различимостью, Экспериментально
определенной в опытах по субъективному
сравнению громкостей сигналов
(Малинникова, 1968). В опытах по субъективному
сравнению использовались те же два
ансамбля сигналов (с диапазонами 40 и 8
дб), что и в опытах по имитации.
Совпадение результатов этих двух опытов
говорит о том, что изменение наклона
осуществляется на этапе преобразования
стимула в его субъективный образ, а не
на этапе превращения образа в
двигательную артикуляторную реакцию.
При постоянстве ансамбля стимулов
уменьшение наклона кривой наблюдалось
для всех трех параметров (высота,
громкость, дли
тельность)
в условиях, описы-
ваемых как
рассеивание внима-
ния. Конкретно
условия состо-
яли в том, что испытуемому
Рис.
186. Характеристики имитации
громкости
щелевого согласного (Ма-
линникова,
1968).
По
оси абсцисс —
интенсивность в дб от
условного
уровня имитируемого стимула;
по оси
ординат —
среднее значение ин-
тенсивности
звуков-реакций. Точки
—
ре-
зультаты имитации набора стимулов,
рас-
положенных в узком диапазоне
уровней
интенсивности; крестики
—
результаты
имитации набора стимулов,
расположен-
ных в широком диапазоне
уровней ин-
тенсивности.
нужно
было одновременно имитировать не один,
а все три параметра стимула (Федорова,
1968).
Уменьшение
наклона прямой, аппроксимирующей
зависимость длительности гласного-реакции
от гласного-стимула, наблюдалось
также на больных с диагнозом сенсорной
афазии. Существенно, что больные с
диагнозом моторной афазии обнаруживали
характерную для здоровых людей
зависимость (Авакян, 1968).
Факт
изменения наклона означает, что между
сигналом и его описанием в нервной
системе по данному параметру нет
однозначного соответствия. По
значению описания нельзя восстановить
абсолютных значений стимула. Однако
порядок расположения стимулов по
физической шкале несомненно сохраняется
в описании, сохраняются и относительные
величины разностей между стимулами
в последовательности. Это следует из
того, что для всех трех исследованных
параметров оказалась возможной линейная
аппроксимация: R—a-\-bs,
где R
—
значение реакции по данному параметру,
s — значение стимула. Для частоты и
длительности используется линейный
масштаб (герцы и секунды), для интенсивности
— логарифмический (децибелы).
Для
распознавания просодических характеристик
сообщения (т. е. ударений, интонации)
несомненно существенны только от
469
носительные
различия частоты, длительности и
интенсивности звуков в последовательности.
Абсолютные значения флюктуируют
чрезвычайно сильно и зависят от множества
факторов, не имеющих какого-либо
отношения к содержанию сообщения
(индивидуальные особенности диктора,
темп его речи, акустические условия
помещения и т. д.).
Приведенные
данные показывают, что для описания
речевого сигнала по высоте, громкости
и длительности используются принципиально
другие преобразования, чем для
параллельного описания этого сигнала
в терминах фонем.
СЛУХОВОЕ
ОПИСАНИЕ РЕЧЕВОГО СИГНАЛА
Исследование
связи между акустическими признаками
сигнала и фонемами. В разделе
«Фонемный образ речевого сигнала» были
приведены экспериментальные доказательства
того, что фонемы действительно являются
субъективными образами речевых
стимулов. Запомнив фонему, человек тем
самым запоминает не данный конкретный
звуковой сигнал, а категорию сигналов,
к которой он принадлежит. Число таких
возможных категорий — психологических
фонем — весьма ограниченно и,
вероятно, лишь немногим превышает число
фонем, принимаемых лингвистами.
Как
известно, важнейшей задачей психоакустики
является установление зависимости
(связи) между описанием сигнала с помощью
физических (математических) методов и
описанием сигнала человеческим мозгом
(субъективное описание). В исследованных
психоакустикой случаях эту зависимость
можно было считать непрерывной (частота
— высота, уровень интенсивности —
громкость).
Совершенно
иначе обстоит дело, когда требуется
указать связь между физическим описанием
речевого сигнала и фонемой. Изменение
сигнала не приводит к изменению его
субъективной интерпретации до тех
пор, пока сигнал не выйдет за пределы
данной фонемной категории. Как только
это произойдет, интерпретация изменится
скачком.
Вопрос
о том, каким образом можно указывать
связь между описанием сигнала по ряду
физических параметров и обозначениями
классов сигналов, рассматривается в
теории распознавания образов (см. обзор:
Загоруйко, 1966).
Обычно
это делается с помощью задания линейных
решающих функций вида
и
= d1X1
^2^2 + • • • + ^пхп
+
где
xv.
. . . хп
—
значения описания сигнала по п
параметрам, d0,
dv
. . dn
— постоянные коэффициенты.
470
При
U
> 0 сигнал считается принадлежащим к
одному классу, при U
<0 — к другому.
При
U=0
нет оснований Предпочесть один или
другой класс; множество сигналов, для
которых £7—0, соответствует границе
между двумя классами. Эта граница
представляет собой гиперплоскость
в пространстве физических параметров
сигналов, Естественно использовать
такой же подход для описания связи
между физическими параметрами стимулов
и фонемами как субъективными
описаниями стимулов. Для этого необходимо
экспериментально определить границы
между всеми возможными фонемными
категориями и аппроксимировать их с
помощью соответствующих решающих
функций.
В
простейшем случае, когда различение
двух фонем базируется на одном
единственном физическом параметре
сигнала (xj), решающее правило приобретает
вид:
выбери
фонему А,
если x±<^d,
выбери
фонему В,
если x%>d,
d
представляет собой фонемную границу;
в эксперименту по фонемной идентификации
она определяется как такое значение
стимула по параметру xv
при котором фонемы А
и В
выбираются с равной вероятностью.
Быстрым
методом определения положения фонемной
границы является метод активного поиска
(Chistovich, Fant, Serpa-Leitao, 1966; Чистович, 1968).
Испытуемый сам управляет синтезатором
речеподобных стимулов, изменяя значения
сигнала по одному или нескольким
связанным параметрам. Испытуемый ищет
такое значение параметра, при котором
происходит смена одной фонемы на другую.
Для одного определения границы
испытуемому требуется прослушать
30—50 стимулов, на что уходит 1—2 мин.
Определения границы повторяются
несколько раз. Результатом эксперимента
являются среднее положение границы и
стандартное отклонение.
Проблема
выбора адекватного описания речевого
сигнала. Исследование
связи между физическими признаками
речевого сигнала и фонемами не
представляло бы большого труда, если
бы сами физические признаки были четко
определены. Однако набор признаков,
которые кажется возможным применить
для описания речевого сигнала, чрезвычайно
широк.
Вопрос
о том, какие из признаков являются
удачными, а какие нет, нельзя решить
исходя из чисто теоретических соображений.
История развития исследований по
проблеме автоматического распознавания
речи показала, что выбор системы
признаков, т, е, формы описания
сигнала, является наиболее сложной и
пока что нерешенной задачей.
В
настоящее время большинство исследователей
согласны с тем, что выбираемая система
физических признаков должна
471
максимально
приближаться к системе признаков,
используемых слуховой системой для
описания речевого сигнала.
Это
практически означает, что основной
задачей изучения восприятия речи
становится выяснение способов слухового
описания речевого стимула.
Казалось
бы, на этот вопрос должна отвечать
физиология слуха и психоакустика.
Однако реально данные этих областей
исследования позволяют пока только
несколько ограничить
Рис.
187. Предполагаемая последовательность
обработки инфор-
мации при восприятии
речевого сигнала.
I
—
этап преобразования звуковых сигналов
в пространственно-временной рисунок
импульсации в слуховом нерве; II — этап
выделения признаков речевого сигнала;
III — этап измерения свойств выделенных
признаков; IV — этап фонетической
интерпретации признаков. 1
—
механизмы внутреннего уха; 2
—
механизмы выделения основных признаков
речевого сигнала; 3
—
механизмы членения непрерывного
речевого сигнала; 4
— механизмы
измерения свойств выделенных признаков;
5
—
механизмы выбора фонем; 6
— звуковой речевой сигнал; 7
—
импульсация в слуховом нерве,
организованная по пространственно-временному
принципу; 8
— выделенные
признаки речевого сигнала; 9
—
сигналы членения речевой потока,
управляющие механизмами измерения
свойств признаков; 10
— результаты
измерения свойств признаков; 11
—
выбираемые фонемы с приписанными им
вероятностями.
область
предварительных гипотез о возможных
способах слухового описания сигнала.
Дополнительные ограничения накладываются
имеющимися сведениями об акустике речи
и накопленным опытом по автоматическому
распознаванию.
Первая,
насколько нам известно, попытка
представителей этих
различных
областей исследования совместно
сформулировать достаточно развернутую
гипотезу о слуховой обработке речевых
сигналов была предпринята группой
советских специалистов (Бондарко и
др., 1968).
Было
сделано предположение, что слуховая
система представляет собой
специализированное устройство для
анализа сложных нестационарных сигналов
типа речевых, использующее ряд
параллельных нейронных обнаружителей
признаков. Последовательность
предполагаемых этапов анализа показаца
на рис. 187,
472
На
первом этапе анализа сигнал преобразуется
в пространственно-временной рисунок
импульсации в слуховом нерве. На втором
этапе анализа происходит выделение
определенных признаков этого рисунка.
В
случае периодического сигнала (гласные,
звонкие согласные) временной рисунок
импульсации должен характеризоваться
пиками плотности импульсации, следующими
с частотой основного тона. В случае
шумового сигнала интервалы времени
между соседними нервными импульсами
должны случайно флюктуировать.
Постулируется наличие нейронных схем,
избирательно реагирующих на периодическую
и «случайную» импульсацию, а также
схем, выходные сигналы которых отражают
частоту (период) основного тона.
Предполагается, что эти схемы
малоинерционны и их выходные сигналы
отражают «мгновенные» (усредненные за
достаточно короткие отрезки времени)
значения речевого сигнала.
Пространственный
рисунок плотности импульсации должен
в случае речевых сигналов характеризоваться
одним или несколькими максимумами.
Предполагается существование нейронных
схем (схемы латерального торможения),
выходные сигналы которых отражают
положение этих максимумов по оси частот
(проекции улитки). Эти схемы также
не должны быть слишком инерционными.
Постулируется
также текущее измерение суммарной (за
короткие интервалы времени) импульсации
и наличие специальных схем, вырабатывающих
«сигналы членения», отвечающих в
моменты резкого изменения
пространственного рисунка распределения
импульсации.
Сигналы,
отражающие частоту основного тона,
частотное положение максимумов,
интенсивность звука закономерно
изменяются во времени. Предполагается,
что на следующем. этапе слуховой
обработки информации производится
выделение локальных признаков этих
функций времени. Вероятно, что к таким
признакам относятся направление
изменения кривой (знак производной),
скорость изменения (величина производной),
значение функции в некоторых особых
точках, в частности в точке перегиба
(в момент изменения знака производной).
Высказано
предположение, что измерители этих
признаков работают по принципу пиковых
приборов с управлением от сигналов
членения. Сигналы членения обеспечивают
считывание и сброс данных с измерителей
и передачу данных в оперативную память.
В. таком случае переход к дискретному
по времени посег- ментному описанию
речевого потока логически предшествует
фонетической интерпретации. При
фонетической интерпретации используется
последовательность из нескольких
соседних сегментов.
473
Легко
заметить, что предложенная схема
является чисто функциональной.
Выделяемые в ней уровни обработки
информации являются логическими, они
могут быть весьма сложно связанными с
анатомическими уровнями слуховой
системы.
Вопрос
о том, может ли данная схема различать
речевые сигналы, пока остается
открытым. Создание действующей
электронной или математической
модели, соответствующей этой гипотезе,
Л2
^.З^.З^Лч
00010000100001001000
Рис.
188. Иллюстрация трех методов описания
речевого сигнала, применяемых при
автоматическом распознавании.
а
—
метод полной спектральной огибающей.
Описанием сигнала является энергия
в частотной полосе (J) как функция от
средней частоты полосы (/). б — полосный
метод. Описанием сигнала является набор
разностей уровней энергии (обозначены
как jDb
2,
. . ., D3t
4
и показаны черными
вертикальными линиями)
в нескольких фиксированных широких
частотных полосах (Вг.
. .,
В4).
Ширина
белого столбика
соответствует ширине полосы, высота
—
значению энергии сигнала в этой полосе,
в
—
формантный метод. Описанием сигнала
является указание положения по шкале
частот (Г)
максимумов (Ft,
. . ., F.t)
на спектральной огибающей сигнала;
в строке нулей и единиц условно обозначены
результаты автоматического обнаружения
частотных максимумов (указаны
единицами).
Остальные объяснения в тексте.
требует
задания многочисленных параметров,
определение которых потребует
большой экспериментальной работы.
Слуховое
описание стационарного речевого сигнала
со сложным спектром. В
настоящее время существует три основных
гипотезы о слуховом описании
стационарных сигналов со сложным
спектром. Они нашли отражение в
соответствующих трех методах, применяемых
при автоматическом распознавании речи:
метод полной спектральной огибающей,
полосный метод и формантный метод.
Схемы,
приведенные на рис. 188, иллюстрируют
различия между этими методами. Начальные
преобразования сигнала во всех трех
случаях аналогичны — сигнал поступает
на гребенку фильтров, на выходе
которых стоят квадратичные детекторы
474


![]()
и
интеграторы (сглаживающие цепочки).
Таким образом, описанием сигнала,
получаемым в результате этой первичной
обработки, является значение энергии
в частотной полосе как функция от
средней частоты полосы (номера фильтра).
Если гребенка состоит из 50 фильтров,
то любой стационарный сигнал
представляется 50-мерным вектором,
т. е. набором из 50 чисел.
Метод
полной спектральной огибающей принимает,
что столь же подробно описываются и
эталоны, например образы идеальных
гласных, сохраняемые в памяти устройства.
Если число фильтров равно 50, то каждый
гласный-эталон также будет представлен
50-мерным вектором. Процедура распознавания
состоит в том, что описание входного
сигнала сравнивается с описанием
эталонов; выбирается тот эталон, который
окажется наиболее близким.
И
полосный, и формантный методы предполагают
дополнительную обработку результатов
начального преобразования, позволяющую
существенно упростить и сократить
описание.
При
полосном методе (Варшавский, 1964)
сокращение описания достигается за
счет того, что предварительные фильтры
объединяются в группы (полосы) — В
В2,
В3,
В±
на рис. 188; суммарная энергия на выходе
одной такой полосы сравнивается с
энергией на выходе другой полосы.
Разность уровней энергии для нескольких
из таких пар полос (ZJ-ц 2;
Dr
3;
D2
3;
Z>2
4;
D3
4
на
рис. 188) является описанием входного
сигнала.
Сокращение
описания при формантном методе
достигается за счет Того, что тем или
иным способом определяются частотные
положения максимумов на кривой,
характеризующей отклик на сигнал
гребенки предварительных фильтров.
Один из простейших методов состоит в
том, что энергия на выходе каждого из
фильтров гребенки сравнивается с суммой
энергий на выходе ближайших справа и
слева фильтров. Если энергия среднего
фильтра превышает половину суммарной
энергии соседей, индицируется наличие
максимума.
В
результате такого преобразования
сигнал может быть описан в простом
«пространственном» коде, соответствующем
п-раз- рядному двоичному числу (п равно
числу предварительных фильтров); 1
— обозначает наличие максимума, 0 —
его отсутствие. Это показано внизу рис.
188. Другая возможность состоит в том,
что максимумам приписываются их
порядковые номера и для каждого из них
указывается его положение по шкале
частот (рис. 188, в).
Такое описание может совпадать с широко
распространенным описанием сигнала
в терминах частот его формант.
Существенное
преимущество двух последних методов
по сравнению с первым состоит не
только в том, что описание является
более экономным, но и что выделяемые
признаки позволяют использовать весьма
простые правила разделения гласных на
475
группы.
На рис. 189 приведены средние спектры
шести русских гласных (Варшавский и
Чистович, 1959). Можно видеть, что с помощью
как полосного, так и формантного метода
их можно прежде всего разделить на две
группы ([u], [oj, [а] и [i], [е], [ы]). Для разделения
внутри этих групп можно воспользоваться
особенностями спектра в области до
1000 гц.
Рис.
189. Средние огибающие спектров шести
русских гласных [и], [оJ, [а], [е], [ы], [i],
произнесенных 40 дикторами (20 мужчинами
и 20 женщинами) в словах «тупо», «тока»,
«хата», «цеха», «тыкать» и «пики» (по:
Варшавский, Чистович, 1959).
По
оси абсцисс —
частота в кгц; по
оси ординат —
нормированный
уровень энергии в дб.
Преимуществом
формантного метода перед двумя остальными
является то, что он мало чувствителен
к искажениям энергетических отношений
в спектре сигнала при условии, конечно,
что эти искажения не настолько велики,
чтобы какой-то из спектральных
максимумов вообще перестал обнаруживаться.
Результаты
ряда экспериментальных работ по
исследованию восприятия синтетических
речевых стимулов позволяют думать, что
из трех перечисленных методов наиболее
вероятным является формантный (описание
в терминах спектральных максимумов).
В
работе Мушникова и Чистович (1971а)
определялось, зависит ли фонемная
граница между [i] и [е] по частоте первой
форманты от частоты и уровня интенсивности
второй форманты. Зависимость могла
отсутствовать, если для описания
гласного применяется формантный или
полосный метод; она обязательно должна
была иметь место, если используется
метод
476
полной
спектральной огибающей (средние спектры
[i] и [ej на рис. 189 отличаются друг от друга
не только в низкочастотной, но и в
высокочастотной области). Экспериментальные
данные показали отсутствие зависимости.
Граница между [i] и [е] в двухформантной
плоскости оказалась представленной
прямой, параллельной оси F2
(рис. 190). На рис. 191 приведены данные
нескольких других работ, в которых были
получены значения фонемной границы
между [i] и [е]. В этих работах группе
испытуемых предъявлялся набор
стимулов, соответствующий одной из
траекторий в пространстве F2,
определялась фонемная идентификация
гласного (Janota, 1967; Fujisaki, Kawashima, 1968; Stevens
et al., 1969; Голузина, 1969). Из рис. 191 следует,
что значение границы по Fj оказалось
очень близким при самых различных
траекториях. Любопытно также, что
языковая принадлежность испытуемых
как будто бы не имеет значения, т. е.
граница оказывается универсальной.
В
работе Линдквиста и Паули (Lindqvist, Pauli,
1968) было показано, что отношения между
амплитудой первой форманты, с одной
стороны, и амплитудами второй и третьей
формант — с другой, не имеют значения
и для различения гласных [й], fy], [i].
Стимулы
с постоянным значением Fr
и переменным значением \JF2,
F3
(F3jF2
= const) были сначала синтезированы с
нормальными для речевого тракта
амплитудными отношениями. Затем с
помощью фильтров первая форманта была
или подавлена, или усилена на 12.5 дб по
сравнению с нормой. Функции идентификации,
полученные в этих двух условиях,
оказались совпадающими.
Приведенные
данные показывают, что для различения
двух гласных фонем используется не
весь спектр сигнала, а только признаки
определенных участков спектра. Для
различения [i] и [е] используются признаки
низкочастотной области спектра, для
различения [й], [у], [i] — признаки спектра
в области частот примерно 1600—3000 гц.
Данные
о том, что признаком является спектральный
максимум (его частотное положение),
были получены в других работах.
Шуплякову
(Шупляков, 1966, 1968) удалось доказать, что
человек измеряет значение частоты
первого спектрального максимума в
естественных и синтетических щелевых
согласных [s] и [j*]. Этот максимум указан
стрелкой на рис. 192, изображающем спектры
естественных [s] и [J]; он соответствует
второй форманте речевого тракта.
Оказалось,
что частота максимума несет двоякую
информацию: она определяет музыкальную
высоту звука и позволяет различить
твердые и мягкие согласные. Доказательством
того, что в данном случае измеряется
именно частота спектрального максимума,
а не разность уровней энергии в паре
соседних частотных полос, является
следующее: изменение амплитуды максимума
не имеет
477
Рис.
190. Положение гра-
ницы между [i] и [е]
в фор-
мантной Fx-,
/’2~плоскости
(по:
Мушников, Чистович,
1971а).
Точки
—
средние значения гра-
ницы по данным
трех русских
испытуемых. Измерения
произ-
водились методом активного
поиска.
Установка частоты F2
осуществлялась
эксперимента-
тором; испытуемый
управлял
частотой Ft.
значения,
пока он выше порога обнаружения;
положение фонем-
ной границы между
твердыми и мягкими согласными по
частоте
максимума одинаково для [s]
и [J] , форма спектра которых
в остальном
резко различна, причем не только вдали
от максимума,
но и в непосредственной
близости от него.
В
работе Мушникова и Чистович (Мушников
и Чистович,
19716) исследовалось
различение звуков типа [и], [о] и [i],
[е].
На основании средних спектров,
приведенных на рис. 189, можно
предложить
два разных способа раз-
личения этих
фонем. Одно состоит
в том, что [i], [е]
выбираются тогда,
когда у сигнала
есть спектральный
максимум в области
1200—2400 гц; для
выбора [и], [о] необходимо
отсутствие
максимума в этой области.
Другой спо-
соб, предлагаемый полосным
методом,
основан на сравнении энергии
в этой
области спектра с энергией в
нижней
полосе частот.
В
работе применялись двухформант-
ные
синтетические гласные с фикси-
рованной
по уровню и частоте пер-
вой формантой.
При разных значениях
Fг
определялась минимальная ампли-
туда
второй форманты, при которой
гласный
начинает звучать как [i] или
[е].
Полученные результаты показали,
что
фонемная граница соответствует по-
рогу
обнаружения спектрального мак-
симума.
Исходя
из гипотезы спектраль-
ных максимумов
следует ожидать,
что человек может
обнаружить ис-
ключение из спектра
гласного толь-
ко
тех гармоник, которые лежат вблизи
формантных частот. Именно эти
гармоники определяют наличие максимума
и его положение по частоте. Кроме того,
если частотное
положение
спектральных максимумов является
полезным признаком для распознавания
фонем, логично ожидать, что
удовлетворительная фонемная
разборчивость может быть достигнута
при аппроксимации гласного комплексом,
состоящим из очень малого числа гармоник,
частоты которых соответствуют частотам
формант.
Эти
эффекты были экспериментально исследованы
в работе Хирато и др. (Hirato et al., 1968).
В
одной из серий экспериментов испытуемые
сравнивали стандартный четырехформантный
гласный звук [а], значе-
478
пия
амплитуд 32 гармоник которого показаны
точками, соеди-
ненными жирной кривой
на рис. 193, с переменным сигналом.
Переменный
сигнал представлял со-
бой тот же
самый гласный с той
разницей, что
амплитуда одной из
его гармоник была
уменьшена.
Определялось, на сколько
децибел
нужно уменьшить амплитуду
гар-
моники для того, чтобы испытуе-
мый
обнаружил различие в звуча-
нии между
стандартным и пере-
менным сигналами.
Такие измерения 2000-
проводились
почти для всех гар-
моник гласного.
Минимальное за-
мечаемое уменьшение
амплитуды
Рис.
191. Положение границы между [i] и
[е] в
Fr-,
У2-плоскости
у испытуемых
с разной языковой
принадлежностью.
I | I
- ' -
300 ООО 500
гц
По
оси абсцисс —
частота первой форманты F,; по
оси ординат —
частота второй фор манты F2.
Вертикальной
прямой
показаны данные рис. 190 (Мушииков,
Чистович, 1971а), полученные методом
активного поиска. Остальные данные
получены методом фонемной идентификации.
Точкой указано то значение Fn
F2,
при котором [i] и Le] идентифицируются
в равном числе случаев. 1
—
испытуемые чехи (Janota, 1967), 2
— испытуемые японцы (Fujisaki, Kawasliima, 1968),
две
точки
соответствуют двум сериям измерений,
проведенным с разного типа синтезаторами;
з
— испытуемые шведы и испытуемые
американцы (Stevens et al., 1969); 4
—
испытуемые русские (Голузина, 1971).
L-J
I I I I I I I 1.1 1 1111 1 1 L—I 1 1 1 I L—1—1....L—1_ 1
L.J.
l)
0.6 1 2 5 10 20кги,
Рис.
192. Спектры естественных изолированно
произнесенных согласных
[s] и [J]. (По:
Шупляков, 1966).
По
горизонтали —
частота колебаний в кгц; по
вертикали —
относительная интенсивность. Точкой
указан спектральный максимум,
соответствующий второй форманте.
479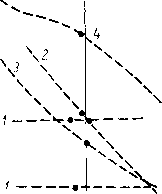



гармоййкй
принималось за дифференциальный порог.
Данные, полученные для двух испытуемых,
приведены на рис. 193 (нижняя
кривая).
Крестиками показаны те гармоники, где
дифференциального порога вообще не
удалось определить, т. е. гармонику
можно было полностью исключить, и
испытуемый этого не обнаруживал.
Можно видеть, что к этой категории
относятся все
Рис.
193. Огибающая спектра стандартного
гласного [а]
(кривая а)
и результаты измерения дифференциального
порога
по интенсивности (кривая б)
для отдельных гармо-
ник в этом
спектре (по: Hirato et al., 1968).
По
горизонтальной оси —
частота в кгц; по
вертикальной оси справа показан
относительный уровень гармоник в
спектре стандартного гласного [а], слева
показано, на сколько дб должна быть
уменьшена амплитуда гармоники для
того, чтобы звук отличался по звучанию
от стандарта. Кружки
—
среднее, по данным двух испытуемых,
минимальное уменьшение уровня гармоники;
треугольники
— минимальное
уменьшение уровня гармоники, обнаруживаемое
одним из испытуемых, второй испытуемый
вообще не обнаруживает факта исключения
данной гармоники! из спектра* гласного;
крестики
—
оба испытуемых не обнаруживают факта
исключения данной гармоники из спектра
гласного.
гармоники
высокочастотной области спектра
гласного, за исключением гармоник
на частотах формант. Низкий дифференциальный
порог наблюдается на гармониках,
соответствующих частотам F2)
F3i
F±,
а также второй гармонике гласного. В
некотором противоречии с формантной
гипотезой находится то, что все гармоники
в области ниже 500 гц являются
обнаруживаемыми — дифференциальный
порог на них возможно определить.
Это будет обсуждаться дальше при
рассмотрении вопроса о частотной
избирательности системы, осуществляющей
анализ гласного и выделение максимумов.
480
В
другой серии опытов были синтезированы
наборы упрощенных гласных ([и], [о],
[а], [е], [i]), содержащих различное число
гармоник. Гармоники каждого гласного
были упорядочены в ряд согласно убыванию
их амплитуды. Увеличение числа гармоник
в упрощенном гласном осуществлялось
путем добавления к уже использованным
гармоникам следующей в ряду по амплитуде.
На рис. 194 показана зависимость
разборчивости гласного от числа гармоник
{верхняя
часть рисунка)
и приведены гласные с наименьшим
числом гармоник, опознававшиеся с
вероят-
Рис.
194. Разборчивость синтетического
гласного ([a], [i], [и], [е]) в зависимости
от числа гармоник, присутствующих в
его спектре {верхняя
часть рисунка),
и спектры гласных стимулов, содержащих
наименьшее число гармоник и
распознававшихся с вероятностью, не
меньшей 0.9 (нижняя
часть)
(по: Hirato et al., 1968).
На
верхней части рисунка: по оси абсцисс
—
число гармоник в спектре гласного; по
оси ординат —
процент правильных опознаний. На
нижней части рисунка кривыми
показаны огибающие спектров стандартных
гласных стимулов, содержащих все 32
гармоники: Гх,
Г2,
Fs,
F, —
частоты формант. Вертикальны
ми столбиками
показаны те гармоники, которые содержались
в спектре максимально упрощенных
стимулов.
ностью
более 0.9. Можно видеть, что двух или трех
гармоник оказывается уже достаточно.
Таким
образом, в настоящее время уже можно
принять без особого риска ошибиться,
что слуховая обработка сигнала со
сложным спектром включает какую-то
процедуру, обеспечивающую выделение
спектральных максимумов. Распространенное
предположение состоит в том, что это
достигается с помощью механизма
латерального торможения.
Чрезвычайно
существенной интегральной характеристикой
системы, производящей выделение
максимумов, является разрешающая
способность, т. е. минимальное расстояние
по частоте между составляющими или
пиками на спектре, при котором каждому
из них соответствует свой максимум.
Прямые
эксперименты для определения разрешающей
спо
31
Сенсорные
системы 481
собности
слуховой системы в указанном выше
смысле слова были сделаны Пломпом
(Plomp, 1964) и Пломпом и Мимценом (Plomp, Mimpen,
1968). Авторы пытались определить, какое
расстояние между составляющими (равного
уровня над порогом) в сложном звуке
необходимо для их выделения при
восприятии. С этой целью была применена
методика опыта, схематически изображенная
на рис. 195. Испытуемый, переключая ключ,
мог поочередно слушать три сигнала.
Один из них состоял из 12 гармоник (они
представлены 12 вертикальными линиями
среднего ряда), два других были чистыми
тонами (они представлены вертикаль-
Рис.
195. Иллюстрация метода, использованного
для определения
различимости
отдельных гармоник в сложном сигнале
(по: Plomp,
Mimpen, 1968).
Слева
—
условное изображение переключателя
Источника звука. Остальные
объяснения
в тексте.
ными
линиями, расположенными выше и ниже
среднего ряда). Один чистый тон имел ту
же частоту, что и одна из гармоник. Тон,
показанный вверху на рис. 195, совпадает
по частоте с четвертой гармоникой
в сложном звуке. Второй чистый тон
(внизу на рис. 195) находился по частоте
на равном расстоянии между соседними
гармониками (в данном случае между
четвертой и пятой гармониками).
Испытуемому предлагалось выбрать то
положение ключа, при котором тон
совпадает по частоте с гармоникой.
Если испытуемый справлялся с этой
задачей, считалось, что он выделяет
гармоники. Измерения проводились на 8
первых гармониках в диапазоне основных
частот от 44 до 2000 гц. В результате
была получена зависимость минимальной
разности частот между составляющими,
необходимой для их раздельного
восприятия, от положения этих составляющих
по оси частот. Она показана пунктирной
кривой на рис. 196.
Полученная
зависимость оказалась весьма близкой
к известной зависимости критической
полосы от ее средней частоты (сплошная
кривая
на рис. 196). Из рис. 196 следует, что для
выделения составляющих необходимо,
чтобы разность их частот составляла
примерно 20% от их средней частоты.
482![]()
В
применении к гласным это означает, что
в области частот выше 1500 гц не только
для мужских, но и для женских голосов
гармоники уже не должны разделяться и
спектральные максимумы должны
определяться формантами. В области
частот ниже 500 гц, напротив того, каждой
гармонике и для женских и для мужских
голосов может соответствовать
самостоятельный
гц
Рис.
196. Минимальная разность частот между
сосед-
ними составляющими в сложном
звуке (по
оси ординат),
необходимая
для их выделения при восприятии, в
зави-
симости от их положения по
шкале частот (по
оси-
абсцисс)
(по: Plomp, Mimpen, 1968).
Кружки
—
экспериментальные данные; пунктирная
кривая —
аппроксимирующая
зависимость; сплошная
кривая —
зависи-
мость ширины критической
полосы от центральной частоты, по
данным
Цвикера и др. (Zwicker et al., 1957).
спектральный
максимум (если, конечно, амплитуда
спектральной составляющей является
достаточной).
На
рис. 193 были приведены данные Хирато и
др. (Hirato et al., 1968), позволяющие предполагать,
что, действительно, испытуемые
обнаруживали присутствие в спектре
[а] всех пяти нижних гармоник, примерно
одинаковых в данном случае по амплитуде.
31*
483
Если
в области низких частот число спектральных
максимумов, выделяемых слухом в
гласном звуке, может оказаться больше
числа формант, для высокочастотной
части спектра можно ожидать обратной
картины — представления двух близко
расположенных формант одним
спектральным максимумом. Данные о
критическом расстоянии между формантами
были получены в работе Фуджимуры
(Fujimura, 1967). Фуджимура исследовал
6
восприятие
шведскими слуша-
телями синтетических
гласных
с постоянной Fr
= 270 гц и пе-
ременными F2
и F3.
F2
и
F3
были
связаны между собой
таким образом,
что отношение
разности их частот к
их сред-
F3
— F2
нему
геометрическому 77V777
принимало одно
из четырех
Рис.
197. Зависимость опознавания
синтетического
гласноподобного сти-
мула как
шведского гласного [и]
от частоты
/^-стимула при разных
расстояниях по
частоте между F2
и
F3.
Графики построены по данным
Фуджимуры
(Fujimura, 1967) и Линд-
квиста и Паули
(Lindqvist, Pauli,
1968).
По
оси абсцисс —
частота F2
в гц; по
оси ординат —
относительное число случаев (в процентах)
опознания стимула как гласного [и];
расстояние между F2
и F3
выражено как
~~
х
100%. На а:
данные Линдквиста и Паули (точки)
для D
= 9%; данные (F3F2) '2
Фуджимуры
для JD=9% (крестики)
и для П=14% (треугольники);
на б;
данные Линдквиста и Паули (точки)
для D=9%; данные Фуджимуры для D=20%
(треугольники)
и для 0=26% (кружки).
фиксированных
значений: 9, 14, 20, 26°/0.
Средняя геометрическая частота
менялась в пределах от 1600 до 3000 гц.
Шведский
язык представлял интерес потому, что
в нем есть гласный [и], который отличается
от соседних с ним гласных [и] и [i] не
только абсолютными значениями F2
и F3,
но и тем, что эти две форманты расположены
очень близко друг к другу. Можно было
ожидать, что отличительным признаком
этого гласного является наличие
именно одного, но не более чем одного,
спектрального максимума в характерной
частотной области. Если это так,
восприятие [и] может служить хорошим
индикатором того, объединяются ли обе
форманты в один спектральный максимум,
или нет.
На
рис. 197 вверху приведены данные работы
Фуджимуры и более поздней работы
Линдквиста и Паули (Lindqvist, Pauli, 484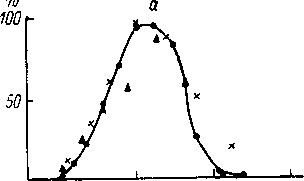

1968),
полученные для стимулов с расстоянием
между F2
и F%,
заведомо
меньшим критической полосы (9 и 14%). Можно
видеть, что данные хорошо совпадают,
идентификация [и] достигает 100%.
На
рис. 197 внизу приведены те же данные
Линдквиста и Па-
Рис.
198. Частота постоянного тона в короткой
посылке, приравниваемого по высоте
к сигналу, частота которого меняется
во времени от 1.0 кгц до 1.5 кгц. (левая
часть рисунка)
или от 1.5 кгц до 1 кгц (правая
часть рисунка)
(по: Heinz et al., 1967).
По
оси абсцисс —
длительность посылок
(она одинакова
для сигналов с по-
стоянной и меняющейся
частотой);
по
оси ординат —
частота постоянного
тона.
ули,
а также данные Фуджи- муры для расстояний
между F2
и
F3,
равных 20 и 26%.
Можно
видеть, что для расстояния в 26%
идентификация
резко
снижена, хотя форма зависимости от
частоты F2
остается прежней. Это говорит о том,
что здесь вмешивается действие неко
Рис.
199. Остаточная маскировка, вызванная
постоянным тоном с частотой 1500 гц
(кривая
с черными кружками)
и сигналом, из^- меняющимся по частоте
от 1000 гц до 1500 гц (кривая
с белыми кружками)
(по: Heinz et al., 1967).
По
оси абсцисс —
частота тестирующего тона, по
оси ординат —
разность уровней интенсивности
между тестирующим тоном и маскером.
Горизонталь-
ной стрелкой
показаны направление и диапазон
изменений частоты меняющегося по
частоте маскера. Вертикальная
линия,
отмеченная стрелкой
сверху,
показывает медиану распределения
частот чистых тонов, приравненных
по высоте к меняющемуся маскеру.
торого
дополнительного независимого признака,
понижающего вероятность выбора [и].
Таким признаком в данном случае может
быть только наличие двух максимумов.
Данные для 20% расстояния между
формантами указывают на то, что 20%
находятся где-то около порога (кривая
занимает промежуточное положение).
Это
хорошо согласуется с приведенными выше
данными Пломпа и Мимпена.
Итак,
сейчас уже можно говорить о том, что
слуховая система не только выделяет
спектральные максимумы в речевом сиг
485

нале,
но и что она действует при этом как
анализирующее устройство с достаточно
высокой разрешающей способностью.
Слуховое
описание изменяющегося во времени
сигнала. Характерной
особенностью слога по сравнению с
изолированным гласным является то,
что значения частот формант, основного
тона и интенсивности существенно
изменяются во времени, причем эти
изменения носят отнюдь не случайный,
но вполне закономерный характер.
Вопрос
о том, как при восприятии описывается
сигнал, параметры которого изменяются
во времени, отнюдь не является решенным.
Одна
из гипотез состоит в том, что временная
картина описывается и запоминается
полностью: для каждого из параметров
используются временные отсчеты,
берущиеся, например, через каждые 5
мсек. Таким образом, изменение параметра
на протяжении слога представляется
набором чисел, отражающих значения
параметра в последовательные моменты
времени.
Другая
гипотеза состоит в том, что кривые,
отражающие изменения параметров во
времени, описываются в восприятии
набором признаков этих кривых. К таким
признакам могут относиться значения
параметра в определенных особых точках,
направление изменения параметра,
скорость изменения.
Основные
трудности, связанные с первой гипотезой,
состоят не только в том, что для
запоминания полного временного описания
требуется большая оперативная память,
но и в том, что необходимо допустить
какие-то процедуры нормирования
изображения во времени (типа сжатия
или растяжения кривых) и привязки его
к какому-то опорному сигналу.
Для
доказательства второй гипотезы
необходимо показать, что человек не
только различает разные по временной
картине сигналы, но что он использует
при их классификации совершенно
определенные признаки кривых изменения
параметра во времени.
Выделение
особых точек в изменяющемся сигнале.
В двух работах исследовалось, чем при
восприятии характеризуется сигнал с
повышающейся и понижающейся во времени
частотой. В работе Брэди и др. (Brady et al.,
1961) сигнал создавался путем возбуждения
(с частотой 100 гц) перестраивающегося
во времени контура. Резонансная частота
контура менялась с 1500 до 1000 гц или с
1000 до 1500 гц. Испытуемый подстраивал
частоту второго контура (с постоянной
на протяжении сигнала резонансной
частотой) так, чтобы звуки были наиболее
похожими. Оказалось, что испытуемый
устанавливал частоту, близкую к
конечному значению резонансной частоты
переменного сигнала.
Близкий
по характеру эксперимент был проделан
Хейнцем и др. (Heinz et al., 1967). Стимулами
служили короткие (20 и 50 мсек.) посылки
тона, частота которого менялась за
время по
486
сылки
от 1500 до 1000 гц или от 1000 до 1500 гц. Испытуемый
подбирал частоту постоянного тона (той
же длительности) так, чтобы сигналы
совпали по высоте. Полученные данные
(суммарные для трех испытуемых) приведены
на рис. 198. Можно видеть, что частота
постоянного тона устанавливается
близкой к конечному значению частоты
меняющегося сигнала. Соответствие
является лучшим для посылок с длительностью
50 мсек. Данные говорят о том, что слуховое
измерение частоты малоинерционно.
В
работе Хейнца и др. было также произведено
определение остаточной маскировки,
вызванной изменяющимся тоном (1000— 1500
гц, длительность 50 мсек.). Тестирующий
тональный импульс имел длительность
20 мсек, и следовал через 5 мсек, после
маскера. Результаты приведены на рис.
199. Маскировка имеет максимум на
частоте, близкой к конечной частоте
маскера, что хорошо согласуется с
данными первого эксперимента.
В
работе Линдблума и Стаддерт-Кеннеди
(Lindblom, Stud- dert-Kennedy, 1967) исследовалось
восприятие стационарных синтетических
гласных и синтетических слогов типа
согласный— гласный—согласный. Начальный
и конечный согласный в слоге совпадали
между собой и соответствовали или [w]
(эта группа стимулов обозначалась как
[w] T[w], где Г — исследуемый гласный),
или [j] (эта группа стимулов обозначалась
как [j] Г[]].
Примеры
динамических спектрограмм [w] P[w] и [j]
P[j] стимулов приведены на рис. 200. Стимулы
синтезировались по следующей схеме.
На начальном и конечном участке стимула,
каждый из которых равнялся 20 мсек.,
значения F2,
F3
были постоянными и составляли для [w]
T[w]: /\=250, F800,
F3=2200
гц, а для [j] Г [j] - /\=250, 7^2=2200,
^3=2900гц.
Временной рисунок стимула был сделан
таким, что вторая половина стимула
была зеркальным отражением первой.
Кривая FT
представляла выпуклую параболу со
значением 7^=350 гц
в
точке максимума. Кривые F2
и F3
для [w] Г [w] соответствовали выпуклой
параболе, для [j] Г[]] — вогнутой. Переменными
параметрами стимулов были значения
F
F3
в точках максимума (|w] T[w]) или минимума
([j] F[j]). Всего использовалось 20 связанных
значений F2
и F3,
изображенных на рис. 201. Эти же значения
использовались при синтезе стационарных
гласных.
От
испытуемых (10 американцев) требовалось
определить, на fi] или [и] больше похож
гласный (в слоге или изолированный).
Целью эксперимента являлось сравнение
положения фонемных границ между [и]
и [i] для изолированных гласных и слогов.
Очевидно,
что для совпадения границ необходимо
выполнение двух условий: 1) в качестве
слуховой характеристикиF
2
и F3
в стимулах типа [wj Tfw] и [j] F[j] используются
их значения в точках максимума или
минимума; 2) фонемный интерпретатор
использует одни и те же решающие правила
для изолированных гласных, слогов [w]
T[w] и слогов [j] Г[j].
487
кгц
[w]r[w]
(ЖЛ
100
мсек.
Рис.
200. Динамические спектрограммы
синтетических слогов ([w] Г [w ] и [j] Г
[j]), применявшихся в исследовании
Линдблума и Стаддерт-Кеннеди (Lindblom,
Studdert-Kennedy, 1967).
По
оси абсцисс —
время, по
оси ординат —
частота. Дли-
тельность гласного на
верхних спектрограммах
составляет
200 мсек., на
нижних спектрограммах —
100 мсек, (отме-
чено
стрелками).
Остальные объяснения в тексте.
Полученные
результаты заставляют думать, что
первое условие действительно выполняется,
а второе — нет.
Оказалось,
что среднее по всем испытуемым положение
границы для изолированных гласных
и слогов [jJ Г [j] практически
кги,
2.0
F2
1 1 I I
2.2
2.4 2.6
2.8 кгц
1.5-
1.5 2.0кгц
F2
Рис.
201. Связь между зна-
чениями частот
третьей
(по
оси абсцисс)
и второй
(по
оси ординат)
фор-
манты в синтетических
стимулах,
применявшихся
в работе Линдблума и
Стад-
дерт-Кеннеди (Lindblom,
Studdert-Kennedy,
1967).
Маленькими
точками
показаны
значения Г2,
F*
на гласном
(им соответствуют
стационар-
ные значения в
изолированных
гласных, значения в
точке
максимума в слогах [w]r
[w],
значения в точке минимума
в
слогах [J] Г []]); большая
точка
внизу
показывает значе-
ния F2
и
F3
на участке соглас-
ного Ew] в слоге
[w]r [w],
большая
точка вверху —
зна-
чения F2
и F3
на участке со-
гласного [J] в слоге []
]Г [J1.
Рис.
202. Положение границы между [i] и
[u] по
F2
в
изолированных гласных (точки)
и
в слогах [w] Г [w] (крестики)
у
разных
испытуемых (по: Lindblom,
Studdert-Kennedy,
1967).
По
оси абсцисс —
положение границы для гласных
длительностью
200 мсек.; по
оси ординат —
для глас-
ных длительностью 100 мсек.
одинаково
— 1644 гц в первом случае и
1634 гц — во
втором (данные вычислены
нами по
таблицам, приведенным
в статье).
Интересно отметить, что это
совпадает
с положением границы по F
2
между
твердыми и мягкими согласны-
ми [s] и
[J] (1642 и 1648 гц), по данным
Шуплякова
(Шупляков, 1968). Данные
для [w] Tfw]
оказались более сложными.
На рис.
202 точками показаны значе-
ния
границ у отдельных испытуемых для
изолированных гласных, крестиками
— для [w] T[w]. Из рис. 202 видно, что трое
испытуемых, очевидно, пользуются для
[w] T[w] той же границей, что и для
изолированных гласных, семь испытуемых
используют более низкую (по F2
и F3)
границу. По объединенным данным для
этих семи испытуемых она составляет в
среднем 1376 гц по F2.
489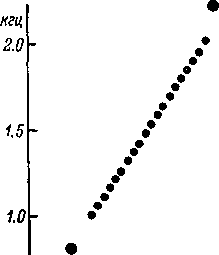
![]()
Авторы
рассматривают весьма сложные гипотезы
относительно механизма полученного
сдвига границы. В свете данных Бондарко
и др. (Бондарко и др., 1966), изложенных
ранее, нам кажется возможным предположить,
что в области между этими разными
положениями границы находится
дополнительная категория — психологическая
фонема, которая в некоторых языках
играет
Рис.
203. Характеристики стимулов, применявшихся
в экспериментах
Либермана и др. (по:
Liberman et al., 1954).
А
—
варианты переходов второй форманты; Б
— два варианта переходов первой
форманты; В
—
варианты комбинаций формант и
соответствующие им гласные. На А:
по оси ординат
указана частота в гц. Цифры
около кривых указывают значения
переходов в условных единицах. Знаком
(—) обозначены отрицательные переходы,
знаком (+) — положительные; на Б:
по оси абсцисс —
время в сек., по
оси ординат — частота
в гц; на В — варианты комбинаций значений
частот Г, и F2
на стационарном участке стимула и
фонетические обозначения соответствующих
им гласных [I], [е],[е], [а], [о], [о], [и]. Внизу
в скобках
приведено английское слово с указанным
гласным. По
оси ординат —
частота в гц. Цифры
над горизонтальными черточками
— точное значение частоты формант
(нижняя
черточка —
первой форманты, верхняя
—
второй).
самостоятельную
роль. По данным Фанта (Fant, 1959), ею может
быть шведское их
(|н]). В условиях форсированного выбора
она может интерпретироваться как та
или другая из ближайших к ней разрешенных
фонем ([i] или [и]) в зависимости от
контекста и существующих у испытуемого
представлений о сходстве между
психологическими фонемами.
Данные
приведенных трех работ позволяют
достаточно определенно утверждать,
что человек выделяет особые точки в
кривой изменения частоты форманты во
времени. Что является особыми точками
в естественной речи и как формально
описать правилу их выделения, пока
сказать еще нельзя.
490
[i]
[e] И W M M [u] [i]
[e]
И И [о] [о] [a]
Рис.
204. Результаты идентификации стимулов,
показанных на рис. 203.
а
—
стимулы, с выраженным переходом б —
стимулы с маловыраженным переходом
F,. Левые
половины рисунков
соответствуют случаю, когда испытуемым
было разрешено пользоваться в ответах
согласными [Ь], [d], [g], правые
половины рисунков —
согласными [р], [t], [к]. Каждый столбец
(три
расположенных друг под другом
прямоугольника) соответствует
определенному гласному, фонетическое
обозначение которого приведено под
столбцом. Внутри каждого прямоугольника
показана зависимость между значением
перехода второй форманты (цифры
по вертикали в центре рисунка)
и числом идентификаций стимула
(цифры
по горизонтали)
с тем согласным, который указан слева
или справа у соответствующей строки.
Так, рельеф в верхнем левом прямоугольнике
(строка [Ь ] столбец [i] на а)
показывает, что при значении перехода,
равном — 4,испытуемые опознают согласный
как [Ь] во всех 66 случаях; при повышении
значения перехода второй форманты
количество опознаний [Ъ] уменьшается.

Определение
направления сдвига спектрального
максимума. Достаточно надежные данные
о том, что направление смещения по
частоте спектрального максимума играет
роль самостоятельного полезного
признака, были получены в ряде работ.
В
работе Либермана и др. (Liberman et al., 1954)
исследовалось значение характера
перехода второй форманты для различения
места образования смычного согласного.
На
рис. 203 приведены характеристики
применявшихся стимулов. Рис. 203, В
показывает значения Fx
л F2
на стационарном участке звука, рис.
203, А
—
варианты переходов. Если начальная
частота F
2
ниже значения F2
на стационарном участке, переход
обозначался как отрицательный, если
выше — как положительный. Рис. 203, Б
показывает два варианта переходов Fx.
При
возрастании Fr
во времени (слева) стимулы были более
близкими к слогам с начальным звонким
согласным.
От
испытуемых требовалось идентифицировать
стимул со слогом, начинающимся с
[b], [dj, [g] (одна серия опытов) или с [р ],
[t], [к] (вторая серия опытов).
Полученные
результаты приведены на рис. 204. Из него
следует, что вне зависимости от
абсолютного значения F2
(характера гласного) при возрастании
F2
(отрицательный переход) стимулы
определяются как слоги с [р ] или [Ь
]; при понижении F2
испытуемые воспринимают [t], [d] или [k],
[g]. Дальнейшие эксперименты (Harris et al.,
1958; Hoffman, 1958) показали, что для различения
[t], [d] и [k], [g] используется еще характер
перехода F3.
Необходимо
отметить, что сотрудники Хаскинских
лабораторий (Нью-Йорк) попытались
объяснить полученные ими данные (рис.
204) с помощью чрезвычайно сложной
гипотезы «локуса» (Delattre et al., 1955). Хотя
эта гипотеза обычно рассматривается
как относящаяся к восприятию, она имеет
достаточно отчетливый смысл лишь в
плане выбора параметров переходов
формант при синтезе согласных.
Делатр,
Либерман и Купер (Delattre et al., 1955) предложили
следующую схему синтеза, поясняемую
рис. 205. На основании согласной фонемы
выбирается одно из трех возможных
начальных значений второй форманты
(F2).
Это значение и названо авторами
«локусом». Обозначим его Fr
На основании гласного выбирается
значение F2
на стационарном участке (F8).
Если закономерность изменения F2
во времени задана и задано также полное
время перехода (Г), то величины Fl
и Fs
однозначно определяют как направление,
так и скорость перехода. Однако
эксперименты показали, что необходимо
еще задать и реальную длительность
перехода (компонент * сигнала,'
соответствующий переходному участку
F^
должен быть выраженным лишь на отрезке
времени D, меньшем Г). Кроме того,
оказалось, что само значение следует
492
выбирать
йё только на оснований согласного, но
и с уйетом гласного (Delattre et al., 1955;
Liberman et al., 1967).
Никаких
данных в пользу того, что при распознавании
согласных в нервной системе человека
производится «вычисление» местоположения
Fv
получено не было. Более того, легко
заметить,
Рис.
205. Схема синтеза переходов второй
форманты, использующая представление
о «локусах».
По
оси абсцисс —
время (О, по
оси ординат —
частота;
F^,
Fi2,
— три возможных значения «локуса»
второй форманты. Характер синтезируемого
согласного определяет выбор одного из
указанных трех значений «локуса»; FSi,
FSi,
FS3~
значения
Fz
на стационарном участке стимула, выбор
одного из них определяется характером
синтезируемого гласного; Т
—
полное время перехода; D
—
реальная длительность перехода, т. е.
время от начала акустического сигнала
до начала стационарного участка
гласного. Остальные объяснения в тексте.
Рис.
206. Положение границы между [р] и [t] в
пространстве двух параметров стимула:
частоты спектрального максимума
гласного (по
оси абсцисс)
и средней частоты полосового шума
(по
оси ординат)
(по: Кожевников и др., 1971).
Данные
двух испытуемых (крестики
и кружки).
что
для вычисления значения Fn
принятого
при синтезе, слушатель
должен
располагать априорной ин-
формацией
о значении Т,
выбран-
ном экспериментатором. Так
как
он заведомо не имеет этой
информа-
ции, гипотеза о восприятии
локуса
неизбежно должна быть
отвергнута.
Если
обратиться непосредственно к исходным
экспериментальным данным Либермана
и др. (Liberman et al., 1954), то можно заметить
очень простую закономерность. Она
состоит в том, что сигналы, характеризующиеся
подъемом F2
во времени, определяются как слоги,
начинающиеся с губного согласного
([р], [Ь ]). При понижении же F2
выбирается язычный согласный ([t], [d ])
или [k], [g]. Это наводит на мысль, что
слуховая система определяет
направление изменения частотного
положения спектраль
493

ного
максимума и что именно этот признак
используется для Классификации
гласных на губные и язычные.
Очевидно,
что если человек способен различать
направление изменения спектрального
максимума, он должен это делать
независимо от того, с помощью
периодического или шумового возбуждения
образован этот максимум. Результаты
экспериментов Купера и др. (Cooper et al.,
1952) по восприятию последовательностей,
состоящих из короткой посылки
узкополосного шума и стационарного
гласного, позволяли предположить, что
в этом случае человек действительно
пользуется не столько абсолютным
значением частоты шума, сколько
направлением изменения частотного
положения максимума в момент перехода
от шума к гласному. Если средняя
частота шума была близка к F2
гласного, последовательность
воспринималась как слог [р ]Г при^ш<^2
и
как [к ]Г или [t ]Г при F^^F^.
Эти
эксперименты были повторены в несколько
модифицированном виде Кожевниковым
и др. (Кожевников и др., 1971). Гласноподобный
сегмент состоял из 3—6 гармоник, одна
из которых превышала остальные не
менее чем на 20 дб. Частота этой гармоники
принималась за частоту спектрального
максимума гласного. Посылка полосового
шума, непосредственно предшествующая
гласному, устанавливалась по
длительности и уровню интенсивности
такой, чтобы максимально уменьшить
сходство стимула со слогом, начинающимся
с [к]. Задача испытуемого состояла в
том, чтобы, управляя средней частотой
полосового шума, найти границу между
[р ] и [tl.
Полученные
данные приведены на рис. 206. Можно видеть,
что положение границы достаточно хорошо
совпадает с частотой спектрального
максимума гласного. Это подтверждает
предположение, что полезным признаком
является направление изменения частоты:
повышение частоты дает [р ], понижение
— [t].
Нужно
отметить, что, по данным Стивенса
(Stevens, 1967), направление смещения во
времени положения максимума концентрации
энергии является наиболее надежным
признаком для разделения естественных
[Ь ], [ш] от [d ], [п] по спектральной картине.
Для объективного выделения [g ] необходимо
использовать дополнительный признак
— малую, в начальный момент времени,
ширину выделенной спектральной области
с максимумом, совпадающим с частотой
спектрального максимума гласного.
Данные
О’Коннора и др. (O’Connor et al., 1957) и данные
Лискера (Lisker, 1957) говорят о том, что
направление изменения F2
и
F3
является полезным признаком и для
различения [j ], [г], [1], [w]. Однако в данном
случае абсолютные значения формант
на стационарном участке этих согласных
также, очевидно, играют существенную
роль.
Определение
величины перепада интенсивности.
Первые указания на то, что величина
изменения
494
интенсивности
при переходе от согласного к гласному
играет роль полезного признака, были
получены Хейнцем и Стивенсом (Heinz,
Stevens, 1961) в опытах по синтезу слогов с
щелевым согласным. Было обнаружено,
что при одном и том же спектре шума
согласный воспринимается как [s ], если
перепад интенсивности составляет 5 дб,
и как [s] или [о], если перепад интенсивности
составляет 25 дб.
Данные
Кузьмина и Лисенко (1971а) показывают,
что этот признак не только без сомнения
выделяется слухом, но и играет существенную
роль в различении согласных. Авторы
применяли
в
качестве стимулов
синтетические
гласные,
амплитуда которых уве-
Рис.
207. Зависимость иден-
тификации
последователь-
ности из двух
примыкаю-
щих сегментов синтетиче-
ского
гласного [а] от ве-
личины разности
уровней
интенсивности между вто-
рым
и первым сегментами
стимула (по
оси абсцисс)
(по:
Кузьмин и Лисенко,
1971а).
Уровень
интенсивности второго сегмента постоянен
и составляет или 61 дб над средним порогом
слышимости (сплошные
кривые)
или 53 дб над порогом (пунктирные
кривые). По оси ординат —
процент опознания стимула как гласного
[а] (кривые,
около которых стоит символ [а]), как
слога, начинающегося согласным [1]
(кривые,
отмеченные символом [1]), и как слога,
начинающегося согласным [т] или [п]
(кривые,
отмеченные символом [т, и]).
личивалась
ступенькой через заданный интервал
времени от начала стимула. Оказалось,
что если величина ступеньки превышает
3—6 дб, стимулы воспринимаются как слоги
СГ; характер согласного зависит от
величины ступеньки. Данные, полученные
для синтетического гласного [а ],
приведены на рис. 207. Контрольные
эксперименты показали, что эффект не
зависит от абсолютного уровня сигнала
и сохраняется при изменении качества
(спектра) гласного.
Определение
скачка основного тона. В экспериментах
(Чистович, 1968а-—в) было обнаружено, что
изменение частоты основного тона на
переходе от согласного к гласному в
синтетическом слоге используется для
различения [Ь ] и [ш]. В опытах применялся
метод активного поиска границы между
[Ь] и [ш]. Основная частота на одном из
сегментов стимула устанавливалась
экспериментатором, испытуемый
устанавливал значение FQ
на втором сегменте, соответствующее
границе между [bj и [т].
495
Полученные
результаты приведены на рис. 208. Можно
видеть, что граница соответствует в
среднем повышению основной частоты на
10% при переходе от сегмента согласного
к сегменту гласного.
Весь
комплекс приведенных выше данных
позволяет сделать вывод, что из двух
гипотез о слуховом описании изменяющегося
во времени сигнала более вероятной
является вторая. Иначе говоря, приходится
думать, что слуховая система текущим
образом выделяет и измеряет
определенные признаки, характеризую-
Рис.
208. Положение границы между [Ь] и [т] в
пространстве двух параметров стимула:
частоты основного тона (Fo)
на сегменте собственно согласного (по
оси абсцисс)
и частоты основного тона на сегменте
гласного (по
оси ординат) (по:
Чистович, 1968а).
щие
изменения сигнала во времени. Значения
сигнала по этим признакам на какое-то
время запоминаются и используются для
принятия фонемных решений.
При
таком способе описания удается избежать
тех трудностей, которые неизбежно
возникли бы, если бы временная картина
описывалась полностью (временными
отсчетами). Снимается вопрос о
необходимости временной нормализации,
требования к точности членения
потока на сегменты становятся значительно
менее жесткими.
Принципиальным
преимуществом такого способа описания
является также то, что оно допускает
возможность параллельного и независимого
распознавания гласного и согласного.
Например,
496
значения
частот формант в точке максимума или
минимума используются для распознавания
гласного. Значения направления
изменения частот формант, определенные
примерно в то же самое время, используются
для распознавания согласного.
Если
бы временная картина описывалась
полностью, единицами распознавания
должны были быть по меньшей мере слоги.
Вместе с тем ряд данных (Чистович и др.,
1965) говорит о том, что человек распознает
именно фонемы, используя для этого
информацию, распределенную на
протяжении примерно слогового отрезка.
ПРОЦЕДУРА
РАСПОЗНАВАНИЯ ФОНЕМ.
ОБУЧЕНИЕ.
ЛОКАЛИЗАЦИЯ
Переход
от слухового описания речевого сигнала
к фонеме. В
настоящее время еще не существует
модели, описывающей процедуру
распознавания фонем. Имеющиеся
экспериментальные данные содержат
довольно мало сведений о том, как
конкретно организована эта процедура,
они скорее указывают, каким требованиям
она должна удовлетворять.
Одно
из важнейших требований состоит в том,
что процедура должна обеспечивать сбор
информации, содержащейся в слуховых
признаках различной природы и
распределенной по времени на участке
сигнала, равном по длительности примерно
одному слогу.
Другое
важное требование состоит в том, что
отсутствие распознавания элемента
не должно приводить к его пропуску —
в запомненной последовательности фонем
должно быть указано, что на таком-то ее
месте был нераспознанный (частично
распознанный) элемент.
Наконец,
еще одним существенным требованием
является способность к адаптации,
подстройке к частному ансамблю сигналов,
представляющему определенного диктора.
В
настоящем разделе будут сначала
приведены данные, свидетельствующие
о том, что эти требования действительно
выполняются при восприятии, затем
будут рассмотрены некоторые гипотезы
о процедуре распознавания фонем.
Данные
о том, что при восприятии происходит
накопление информации о согласном,
находящемся на разных участках слога,
были получены во многих работах с
синтезированными сигналами и с
выделенными отрезками естественной
речи (Дукельский, 1962; Люблинская, 1966;
Malecot, 1956; Nakata, 1959; Heinz, Stevens, 1961; Ohman, 1962, и
др.). Показано, что информация о согласном,
находящемся в интервокальном положении,
содержится в переходном участке от
гласного к согласному, на участке
собственно согласного, на переходе от
согласного к гласному. Эта информация
заключена в признаках стационарного
участка собственно соглас
32
Сенсорные системы
497
ного
(спектр, длительность, периодический
или шумовой характер) и в динамических
признаках (направление сдвига
спектрального максимума, перепад
интенсивности, изменение основной
частоты переходного участка).
Исключение или искажение каждого из
признаков приводит к понижению
разборчивости и появлению систематических
ошибок.
Рассмотрим
более подробно, как распределяется во
времени информация о согласном в
изолированном слоге СГ (согласный-
гласный). В качестве точки отсчета
примем момент размыкания смычки (щели)
при артикуляции данного согласного.
Сегмент звукового сигнала, предшествующий
этому моменту времени, будем называть
сегментом собственно согласного,
последующий сегмент назовем переходным
сегментом. С точки зрения относительной
роли этих двух сегментов все согласные
можно разделить на несколько групп.
В
глухих смычных согласных ([р], [t], [к])
сегмент собственно согласного вообще
отсутствует, так как звуковой сигнал
появляется только в момент размыкания
смычки.
В
звонких смычных согласных ([b], [d], [g ])
сегмент собственно согласного сам
по себе почти не несет информации.
Предъявленный изолированно, он не
вызывает у человека ассоциаций с
каким-либо согласным звуком, воспринимаясь
как неопределенное гудение.
Последовательность, образованная из
такого сегмента и участка стационарного
гласного, восприниматеся как слог,
начинающийся со звонкого согласного,
характер этого звонкого согласного
определяется динамическими признаками
последовательности (перепад
интенсивности, основной частоты).
Сегмент
собственно согласного, выделенный из
слогов с согласными ([m], [n], [1]), уже
несет сведения для выбора фонемы, однако
их далеко недостаточно для безошибочного
распознавания: [ш] и [п] еще не
различаются, [1] принимается за гласный
[и]. Наконец, в случае фрикативных
согласных [s], [j], [z], [g] сегмент собственно
согласного несет почти всю необходимую
информацию для выбора фонемы.
Исходя
из приведенных данных, естественно
ожидать, что задержка фонемного
решения (если ее считать от момента
размыкания смычки в согласном-стимуле)
должна быть разной для разных групп
согласных. Были проведены эксперименты
(Чистович и др., 1965), в которых диктор с
соответствующими датчиками для
регистрации артикуляторных параметров
читал таблицы слогов СГ, четверо
испытуемых, находящихся рядом с диктором,
но не видящих его, записывали согласный
карандашом на металлических пластинах.
Контакт карандаша с пластиной замыкал
электрическую цепь и приводил к
появлению сигнала, который записывался
на ленте чернилопишущего осциллографа
параллельно с артикуляторными
сигналами от диктора. Измерялись
интервалы времени между размыканием
смычки (щели) соглас-
498
кого
у диктора и началом записи буквы
испытуемым. Таблица
состояла из
слогов, начинающихся с согласных [t],
[t'], [d],
[d'], [И, [Г], [n], [n'], [z], [z'], [s], [s'] 2
и кончающихся глас-
ными [u], [о], [а].
На каждый согласный было получено
по
240 ответов (записей согласного
русской буквой). Зависимость
средней
величины задержки записи буквы от
качества согласного
приведена на
рис. 209. Можно видеть, что задержка
максимальна
для [t], [t'] и минимальна
для [s], [s'], [z], [z' ]. Так как
задержка
для [s], [s'], [z], [z']
меньше
времени простой психи-
ческой реакции
на звуковой
сигнал, можно утверждать,
что
фонемное решение об этих
со-
гласных в ряде случаев при-
нимается
испытуемым до того,
как он услышит
переход от
согласного к гласному,
т. е.
на основании сегмента собст-
венно
согласного. Для осталь-
Рис.
209. Зависимость среднего значения
задержки
буквенной записи соглас-
ного от
качества согласного (по: Чисто-
вич
и др., 1965).
По
оси ординат —
значение задержки интервала времени
между моментом размыкания смычки (щели)
согласного у диктора и началом записи
буквы испытуемым. Под
осью абсцисс столбиками
выписаны согласные, объединившиеся в
группы при вычислении среднего
значения задержки; косые
штрихи
обозначают мягкость согласного.
ных
согласных решение принимается только
после восприятия переходного сегмента.
Задержка его тем меньше, чем больше
информации содержалось в сегменте
собственно согласного.
Полученные
данные совместимы с предположением,
что человек работает как фонемное
распознающее устройство, выдающее
результат в тот момент времени, когда
накопленная информация о фонеме
достигнет определенного достаточно
высокого значения. Однако недостатком
таких схем является то, что они могут
пропускать отдельные фонемы (если
информации о них недостаточно) и искажать
тем самым порядковый номер фонемы в
последовательности. Ниже будут
приведены данные, свидетельствующие
о том, что человек как распознающая
система этим дефектом не обладает.
В
экспериментах Клаас (Чистович и др.,
1965) исследовался характер ошибок,
совершаемых при распознавании фраз,
подвергнутых сильным искажениям.
Только 30% из переданных фраз были
распознаны правильно.
2
Штрих над символом обозначает мягкость
соответствующего звука.
32* 499
Анализ
ошибочно принятых фраз показал, что
они в большинстве случаев совпадали
с переданными по числу слогов и положению
ударений, хотя значительно отличались
по звуковому составу. Например,
наблюдались замены «зеленый крокодил»
на «на-
Рис.
210. Осциллограмма сочетания [ара] при
быстром повто-
рении (по: Чистович и
др., 1965). _
Три
нижние кривые
соответствуют артикуляторным параметрам
диктора, верхние
—
испытуемого: гг
—
губная смычка, регистрируемая при
помощи контактного датчика, к
1
— касание языком точки датчика
«искусственное нёбо», расположенной
у переднего края (признак, характеризующий
артикуляцию переднеязычных согласных);
вн
—
ток воздуха из носовых отверстий,
регистрируемый при помощи рупорного
датчика; лар
—
огибающая сигнала ларингофонного
тракта; микр
—
огибающая сигнала микрофонного
тракта; вертикальными
линиями
отмечены начало и конец губной смычки
диктора; штрих
над первым [а] в сочетании [ара! указывает
на то, что ударение сделано на первом
гласном.
верно
приходил», «больной выздоровел» на
«багром вытянули», «мировой рекорд»
на «недовольный кот».
Воспроизведение
числа слогов говорит о том, что слушатели
каким-то образом следили за чередованием
гласных и согласных в воспринимаемой
последовательности.
500
Прямая
демонстрация способности человека
следить за сменой гласных и согласных
была получена в экспериментах по
текущей имитации звукосочетаний
(Чистович и др., 1962). Диктор с соответствующими
датчиками для регистрации артикуляторных
параметров читал перед микрофоном
таблицу звукосочетаний. Находящийся
в другой комнате испытуемый — также с
датчиками — слышал звукосочетания
через телефон и текущим образом (т.
е. с минимальной задержкой, на которую
он способен, их имитировал). Артикуляторные
сигналы как от диктора, так и от
испытуемого параллельно записывались
на ленте чернилопишущего осциллографа.
Пример записи сочетания [ара] приведен
на рис. 210. Можно видеть, что имитация
согласного начинается значительно
раньше, чем окончится согласный диктора,
т. е. заведомо до того, как вся информация
о согласном будет получена. Задержка
начала согласного испытуемого от начала
согласного диктора оказалась очень
малой (120—140 мсек.) и не зависящей от
качества согласного. Такого поведения
можно было бы ожидать от схемы
автоматического распознавания фонем
с низким порогом срабатывания. Однако
при низком пороге срабатывания
неизбежно большое число ошибок.
Действительно,
оказалось, что при текущей имитации
испытуемые совершают большое число
ошибок, часто ведут себя так, как если
бы они произносили два согласных
одновременно (одновременно образуют
губную и язычную смычки). Очень интересным
фактом является то, что ошибки исправляются
на протяжении имитации согласного —
начав с неправильных движений, испытуемый
затем заменяет их на нужные, так что
артикуляторное состояние, достигаемое
к концу согласного, уже достаточно
хорошо соответствует согласному,
произносимому диктором.
Таким
образом, человек ведет себя так, как
если бы в нем были совмещены минимум
два фонемных распознающих устройства:
одно с низким порогом срабатывания,
гарантирующее отсутствие пропуска
фонем, и другое с высоким порогом,
обеспечивающее накопление информации
во времени и достаточную надежность
распознавания.
Способность
подстройки к «диктору» была показана
в трех работах (Ladefoged, Broadbent, 1957; Ladefoged,
1962; Fujisaki, Kawashima, 1967). В первых двух работах
исследовалось восприятие тестирующих
слов типа [beet, bit, bet, bat], которые были
синтезированы в контексте различных
вариантов «ключевой» фразы. Варианты
«ключевой» фразы были получены
(синтезированы) на основании
копирования одной естественной фразы
с повышением или понижением ее формантных
частот. Этим моделировалось изменение
размеров речевого тракта, т. е. разные
варианты соответствовали разным
дикторам, отличающимся друг от друга
размерами речевого тракта. В каждый из
вариантов ключевой фразы были включены
поочередно все тестирующие
501
эффект
видно,
слова.
Результаты показали, что восприятие
слова закономерно
изменяется в
зависимости от характеристик «ключевой»
фразы.
В работе Фужизаки и Кавашимы
(Fujisaki, Kawashima, 1967)
исследовалась
идентификация наборов изолированных
синтети-
ческих гласных, соответствующих
двум траекториям в формант-
ной F
/^-плоскости. Определялась зависимость
положения фо-
немной границы в Fv
/^-плоскости от таких параметров
гласных,
как основная частота и
частоты верхних формант. Было обнару-
жено,
что фонемная граница сдвигается вверх
при повышении
основной частоты
голоса и частот верхних формант.
Последний
более
четко выражен в случае шепотных гласных.
Оче-
что эффект, полученный в работах
Лейдфогеда и Брод-
бента, тоже можно
трактовать
как сдвиг фонемной
границы.
9
9 Легко заметить, что говоря
\ / 0
слуховом описании речевого
в
Рис-
Схема, позволяющая «физио-
I
2
логически>>
представить сходство между
/
/ * сигналом и фонемой.
i К
А,
2 ““ коэффициенты связи нейронов ряда
х2
с
нейроном А.
Кв
и Kg
2 ~
коэффициенты
X? связи
нейронов рядов Хх
и X, с нейроном В.
6 Остальные
объяснения в тексте.
о
4
сигнала,
мы употребляем термины, имеющие
достаточно очевидный физический
смысл: частотное положение спектрального
максимума, знак его изменения во
времени и т.д. В настоящем разделе мы
вынуждены были употреблять такие
понятия, как информация или сведения
о фонеме, не определяя, какой конкретный
смысл вкладывается в них в данном
случае. Интуитивно понятно, что сведения
о фонеме могут содержаться в разных
слуховых признаках сигнала и что
они могут накапливаться во времени.
Однако понятно также, что реальная
физическая (физиологическая) система
имеет дело только с сигналами, именно
их она может суммировать, вычитать
и т. д.
Для
того чтобы описать связь между значениями
сигнала по слуховым признакам в
последовательных отрезках времени и
фонемами, кажется необходимым
допустить существование некоторых
промежуточных переменных (сигналов),
отражающих величину «сходства» с
фонемой.
На
рис. 211 приведена элементарная схема,
позволяющая наглядно представить,
что можно было бы понимать под «сходством».
Эта схема является очень частной, однако
уже на ее примере можно показать, какие
вопросы возникают при допущении
существования «сходства».
502
На
рис. 211 вдоль осей Хх
и Х2
расположены ряды нейронов (обозначены
кружками), представляющие проекции
параметров Хх
и Х2
в слуховой системе. Например, таким
параметром может быть частота одной
из формант. А
и В
являются нейронами, представляющими
две разные, соседние по параметрам Х±
и Х2
фонемы.
Каждый из нейронов-фонем связан со
множеством нейронов в обоих рядах,
причем так, что коэффициенты связи
нейрона В
возрастают
слева направо, а коэффициенты связи
нейрона А
убывают.
Если
принять, что при действии речевого
сигнала может возбудиться только
один из нейронов в каждом ряду и величина
его возбуждения равна 1, величина
возбуждения на входе нейрона- фонемы
будет представлена суммой значений
коэффициентов связи, которые имеют
возбудившиеся нейроны. Эта величина и
может быть названа потенциальным
сходством звука с фонемой по параметрам
Х1?
Х2.
Потенциальное сходство по одному
параметру будет представлено просто
коэффициентом связи.
Можно
ввести еще понятие реального сходства,
понимая под ним разность между величиной
возбуждения на входе нейрона- фонемы
и значением его порога, который может
изменяться в зависимости от каких-то
дополнительных условий.
Экспериментальные
данные о том, что для указания связи
между акустическим параметром сигнала
и фонемой нужно ввести функцию сходства
и недостаточно только привести значение
фонемной границы, были получены при
исследовании времени реакции
фонемного выбора. В экспериментах
применялись синтетические гласные
или согласные, значения стимулов
менялись по полезным акустическим
параметрам (Studdert-Kennedy et al., 1963). Было
показано, что время двигательной
реакции, связанной с выбором фонемы,
закономерно возрастает вблизи фонемной
границы.
Хотя
эти данные и представляются субъективно
понятными («чем больше звук похож на
определенную фонему, тем быстрее можно
принять решение»), но разработанной
модели, связывающей время реакции
с величиной сходства, пока что нет. В
работе Алекина и др. (1962) было выдвинуто
предположение, что в момент начала
стимула образуется некоторый специальный
сигнал — «сигнал членения», который
используется для управления порогами
нейронов-фонем.
Выбор
фонемы происходит в тот момент времени,
когда возбуждение на входе одной из
фонем окажется равным порогу. Эта схема,
позволяющая объяснить увеличение
времени реакции вблизи фонемных границ,
привлекательна тем, что она обеспечивает
автоматический выбор из множества
фонем той, на которую сигнал больше
всего «похож». Сравнения друг с другом
значений «сходства» сигнала с разными
фонемами при этом не требуется. Обратимся
снова к схеме рис. 211. Легко заметить,
что эта схема
503
не
предполагает жесткой фонемной границы
по каждому из параметров сигнала.
Фонемная граница определяется здесь
как такое значение сигнала по данному
параметру, при котором для обеих
соседних фонем величина реального
сходства будет одинаковой. Так как
реальное сходство зависит от порога
возбудимости нейрона-фонемы и от
значений сигнала по другим параметрам,
положение фонемной границы должно
изменяться.
Указания
на то, что положение фонемной границы
может зависеть от ансамбля сигналов,
предъявляемых в эксперименте,
содержатся в данных, полученных
несколькими авторами (Fry et al., 1962;
Lindner, 1966; Hiki et al., 1968). Эти авторы наблюдали
явление контраста, заключающееся в
том, что стимул, находящийся вблизи
средней фонемной границы между А
и В, воспринимается как А,
если он следует за В,
и как В,
если он следует за Л.
Прямое
экспериментальное доказательство
зависимости положения фонемной
границы от предъявляемого ансамбля
сигналов было получено Кузьминым и
Лисенко (Кузьмин, Лисенко, 19716). В одном
из вариантов опытов были использованы
синтетические гласные, применявшиеся
ранее в экспериментах по имитации
(Chistovich,Fant, Serpa-Leitao, Tjernlund, 1966; рис. 180) и
в экспериментах по шкалированию
субъективных расстояний (Голузина,
1971; рис. 181). За исходный набор было
принято 8 стимулов, их номера и
значения приведены в табл. 12.
Таблица
12
Значения
формант синтетических гласных в гц |
№ стимула |
|||||||
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
|
л .... |
270 |
320 |
375 |
430 |
480 |
540 |
605 |
670 |
f2 .... |
2500 |
2450 |
2420 |
2350 |
2250 |
2140 |
1950 |
1750 |
Из
стимулов табл. 12 было составлено две
тестовые таблицы. Первая из них
представляла случайную последовательность
шести первых гласных, вторая— случайную
последовательность шести последних
гласных. Стимулы, обозначаемые номерами
3, 4, 5, 6, входили в обе таблицы. Каждый
гласный повторялся в таблице 20 раз.
Таблицы предъявлялись двум группам
слушателей. Испытуемый должен был
реагировать поворотом ключа в одну
сторону при [i], в другую — при [е]. На
рис. 212, «приведены полученные функции
идентификации, а на рис. 212, б
— зависимости
среднего времени реакции от значения
стимула.
504
Можно
видеть, что сдвиг вверх по шкале диапазона
применяемых стимулов приводит к
тому, что фонемная граница также
смещается вверх.
В
работе Харрис и др. (Harris et al., 1958)
исследовалась зависимость распознавания
места образования согласных от двух
акустических признаков: перехода второй
и перехода третьей форманты. Авторы
пришли к выводу, что эффект перехода
третьей форманты может быть проще всего
описан как сдвиг фонемной границы по
параметру перехода второй форманты.
На рис. 213
приведены
значения границы
[b], [d] по переходу
F2
в за-
висимости от значения стимула
по
переходу F3.
В
работе Чистович (1968)
была сделана
попытка исследо-
вать, как объединяется
инфор-
мация о двух параметрах,
по-
лезных для различения [Ь] и
[т].
Одним из параметров был
относительный
уровень состав-
Рис.
212. Влияние диапазона значе-
ний
предъявляемых гласных-стиму-
лов на
функцию идентификации и
функцию
времени реакции.
а
—
функция идентификации для [е] при разных
диапазонах стимулов (сплошная
и пунктирная
кривые —
две разные группы испытуемых); б —
зависимость времени реакции от
частоты Ft
гласного-стимула при разных диапазонах
стимулов. По
оси абсцисс графиков
а и б показана частота первой форманты
гласного в гц; по
оси ординат
на а
— процент
ответов Ее 1, на б — отношение (в %)
среднего времени реакции на данный
стимул к среднему времени реакций по
всему набору стимулов.
ляющей
с частотой 1000 гц в спектре сигнала на
сегменте собственно согласного. Другим
— была величина изменения Fo
при
переходе от сегмента согласного к
сегменту гласного.
В
первой группе экспериментов применялся
метод активного поиска границы между
[Ь] и [т]. Опыт ставился таким образом,
что экспериментатор управлял одним из
параметров сигнала, испытуемый искал
границу по другому параметру. Полученные
данные приведены на рис. 214. Можно видеть,
что все пространство сигналов
оказалось разделенным на четыре области:
левая верхняя из них (IV)
соответствует [Ь ], нижняя правая (II)
— [ш].
Две остальные области (I
и III)
соответствуют неопределенным
сигналам, которые испытуемый в зависимости
от своей установки мог воспринимать
или как [Ь ], или как [т]. Так, сигналы из
верхней правой области воспринимались
испытуемым как [т ], когда он искал
границу по спектральному признаку, и
они же
505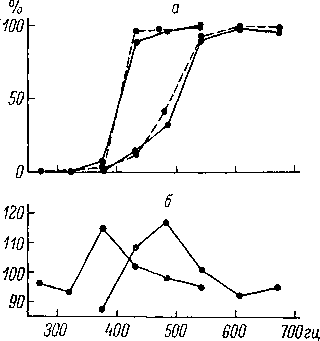
воспринимались
как [b], когда он искал границу по признаку
Fq.
Такие четыре области никак не могли бы
возникнуть, если бы распознающая система
обладала постоянными характеристиками.
Вместе с тем такой эффект мог бы быть
получен при направленном (зависящем
от задачи) управлении порогами нейронов
в схеме рис. 211.
Вторая
серия экспериментов была направлена
на определение относительной значимости
обоих параметров. Испытуемым предъ-
Рис.
213. Характеристики стимулов,
применявшихся Харрис и др. (Harris et al.,
1958) при исследовании роли переходов
второй и третьей форманты в распознавании
места образования согласных (а),
и граница между [Ь] и [d] в пространстве
параметров переходов первой и второй
форманты (б).
На
а:
слева —
схематическое изображение одного
трехформантного (Г)5
Г2,
Г3)
стимула (по
оси абсцисс —
время, по
оси ординат
— частота в гц, цифры
указывают выбранные значения
переходов), справа
—
характеристики набора исследованных
переходов F2
и
F3,
цифры указывают значения переходов.
На б: по
оси абсцисс —
значение перехода Г3;
по
оси ординат —
значение перехода F2,
являлись
12 сигналов, показанных точками на рис.
214. Испытуемые должны были определить
в баллах субъективное расстояние
между услышанным звуком и фонемой (в
одних случаях [Ь ], в других — [ш]). Если
бы веса обоих параметров были одинаковыми,
сигналы из областей I
и III
должны были бы оцениваться как
субъективно равно удаленные от [Ь ] и
[ш]. В случае большего веса спектрального
параметра звуки из области I
должны
быть более близки к [т ], чем к [Ь ], а звуки
из области III
должны
быть более близки к [Ь], чем к [т]. При
большем относительном весе параметра
основной частоты должна наблюдаться
обратная картина.
506

Полученные
данные приведены на рис. 215. Можно
видеть,
что у одного испытуемого
веса обоих параметров примерно
оди-
наковы — звукам из областей I
и III
соответствуют близкие
оценки,
сигналы определяются как почти равно
удаленные от
[Ь] и [т]. У двух других
испытуемых спектральный параметр
имеет
значительно больший вес, чем параметр
основной частоты.
гц Пока
трудно пред-
50г f видеть,
какое разнооб-
45
- разие
моделей будет
Рис.
214. Положение границ между [Ь]
и [т],
определенных методом активного
поиска,
в пространстве двух параметров
(по:
Чистович, 19686).
По
оси абсцисс —
уровень интенсивности состав-
ляющей
1000 гц в спектре сегмента согласного
(14);
по
оси ординат —
величина прироста час-
тоты основного
тона сигнала на переходе от сег-
мента
согласного к сегменту гласного
(ДГ0).
Сплошной
кривой
с крестиками
показана граница
между [Ь] и [щ],
определенная в опыте, когда
испытуемы^:
управлял величиной J4,
пунктир-
ной
кривой с кружками —
когда он управлял
величиной ДГ0-
Точками
с цифрами
показаны
значения 12 стимулов,
использованных в экспери-
менте по
шкалированию (см. рис. 215). I—IV
—
условные
обозначения областей между
фонемными
границами. Остальные
объяснения в тексте.
Рис.
215. Субъективные
расстояния в баллах
между
стимулами, показанными
на
рис. 213, а,
и фонемами
[Ь]
и [ш].
По
оси абсцисс: Db —
расстоя-
ние стимула от [Ь], по
оси
ординат: Dm
— расстояние сти-
мула от [ш]. Разными
знач-
ками
указаны величины, полу-
ченные для
четырех групп сти-
мулов (области
I—IV
на
рис. 214). Разные
кривые
полу-
чены от разных испытуемых.
предложено
для описания процесса распознавания
фонем. Однако маловероятно, что в этих
моделях удастся обойтись без таких
характеристик, как функция сходства с
фонемой по каждому из параметров,
относительные веса параметров, порог
(чувствительность) нейрона-фонемы.
Кажется очень заманчивым предположить,
что различные контекстуальные влияния
в восприятии речи осуществляются с
помощью управления порогами нейронов-
фонем и что относительные веса параметров
различны в разных языках и устанавливаются
в процессе обучения. Эти предположения
вполне доступны экспериментальной
проверке,
507
которая,
можно надеяться, и будет предпринята
в ближайшем будущем.
Развитие
восприятия речи в раннем детском
возрасте. В литературе
высказывались две различные гипотезы
относительно механизма образования
фонем в процессе обучения речи (Liberman,
1957). Одна из них обозначается как гипотеза
приобретенного сходства, другая —
как гипотеза приобретенных различий.
Согласно
первой из них, ребенок сначала отличает
друг от друга значительно большее
множество речевых сигналов, чем это
необходимо для фонемной классификации.
Далее на этом множестве образуются
области, связанные с различными
артикуляторными реакциями. Обозначения
этих областей представляют собой
фонемы. Они начинают дальше использоваться
в качестве сокращенного описания
стимула при запоминании звуковой
последовательности (слово, фраза).
Согласно
второй гипотезе, ребенок сначала
различает меньшее множество речевых
сигналов, чем необходимо для фонемной
классификации. Так как при этом ему не
удается правильно реагировать на
предъявляемые сигналы (речевые сообщения
взрослых), стимулируется создание новых
схем обработки информации (новых
признаков). Сохраняются и совершенствуются
те схемы, которые обеспечивают правильное
реагирование.
Первая
гипотеза допускает возможность
самообучения у ребенка в процессе
подражания звукам, произносимым
взрослыми. Сигналом ошибки в этом случае
может быть расхождение между слуховым
изображением звука, созданного взрослым,
и звука, воспроизведенного в ответ на
него самим ребенком. Роль взрослого
на этом этапе процесса обучения может
сводиться к тому, что он является
источником речевых сигналов.
Вторая
гипотеза предполагает, что взрослый
выступает в роли активного учителя, не
только создающего речевые сигналы, но
и сообщающего ребенку информацию о
том, правильно ли он реагировал на эти
сигналы.
Одна
из существенных теоретических трудностей
исследования становления речи у
ребенка заключается в необходимости
разграничения явлений, связанных
действительно с обучением, от явлений,
связанных с созреванием нервной системы.
В
монографии Леннеберга (Lenneberg, 1967)
приводится ряд интересных данных
относительно развития речеобразования,
заставляющих признать, что на первом
году жизни речеобразо- вание является
в значительной мере автономным (мало
зависит от восприятия) и отражает
процессы созревания нервной системы.
Основная
особенность развития речеобразования
состоит в том, что в возрасте около 6
месяцев ребенок переходит от одного
типа координации речевых движений к
другому. Начиная с трех месяцев и до
шести месяцев ребенок производит
достаточно длительные гласноподобные
звуки. Координация движений, необхо
508
димая
для создания таких звуков, не должна,
очевидно, существенно отличаться от
таковой при крике. Разница с криком
может быть преимущественно количественной
и касаться в основном работы гортани
и дыхательной системы.
В
возрасте около шести месяцев ребенок
начинает осуществлять слогоподобные
артикуляторные комплексы, характеризующиеся
тем, что язык, губы, нёбная занавеска
совершают цикл движений типа смыкание
— размыкание. Для производства таких
движений требуется уже определенная
схема временной организации комплекса
и установление реципрокных отношений
между мышцами антагонистами. Как
говорилось выше, слог является основным
элементом речи взрослого человека.
Существенно,
что возраст, в котором ребенок переходит
от гласноподобных к слогоподобным
звукам, не зависит от того, является ли
ребенок нормально слышащим или глухим
(Lenneberg, 1967). Исключение возможности
создать звуковой сигнал (дети с
трахеотомией) также, по мнению Леннеберга,
не влияет на смену гласноподобных
артикуляций на слогоподобные.
Спонтанные
слогоподобные комплексы создаются
ребенком на протяжении всего периода
его развития, предшествующего появлению
слов, имеющих отчетливо коммуникативный
характер (возраст 1.5—2.0 года).
Отмечаемая
Леннебергом разница между глухим и
нормально слышащим ребенком состоит
в том, что последний создает большее
разнообразие сигналов, он как бы играет
со звуками.
Около
10 месяцев наблюдаются активные попытки
имитации сигналов, произносимых
взрослыми, но, как пишет Леннеберг, эти
попытки обычно не являются полностью
успешными.
Первое,
насколько нам известно, надежное
статистическое исследование характеристик
слогов, спонтанно создаваемых маленькими
детьми, было выполнено Престоном и др.
(Preston et al., 1967; Preston, Yeni-Komshian, 1967). Авторы
исследовали слоги типа смычный
согласный—гласный, записанные при
спонтанном произнесении их детьми
арабами и детьми американцами в возрасте
около одного года. Американцы и арабы
были выбраны для сравнения по той
причине, что в английском языке
используется противопоставление
глухого неаспирированного согласного
глухому аспирированному, тогда как у
арабов глухой неаспирированный согласный
противопоставляется звонкому согласному.
Таким образом, один тип согласного
имеется в обоих языках, два других типа
имеются каждый только в одном языке.
Авторов
интересовало, проявляются ли эти
языковые различия в лепете годовалых
детей. Результат оказался отрицательным.
И дети арабы, и дети американцы создавали
в основном согласные того типа, который
присутствует в обоих языках. Таким
образом, можно было сделать вывод,
что слогоподобные комплексы, спонтанно
создаваемые ребенком в возрасте около
года, еще
509
не
зависят от языка, на котором говорят в
семье ребенка. Кроме того, вместо двух
типов согласных, используемых взрослыми,
ребенок производит только один, очевидно
наиболее простой тип согласного. Это
очень важный вывод, так как он означает,
что в процессе обучения языку происходит
выработка новых двигательных координаций
и «словарь» артикуляторных комплексов
расширяется.
Исследование
американских детей в возрасте около
двух лет показало, что у них уже
наблюдаются характерные для английского
языка различия между аспирированными
и неаспириро- ванными согласными.
Существенно, что этих различий не было
обнаружено у слабо слышащих американских
детей такого же или более старшего
возраста; различия появились после
того, как дети стали пользоваться
слуховыми протезами.
Таким
образом, кажется очевидным, что
обусловленные языком различия в
артикуляции слоговых комплексов
вырабатываются ребенком благодаря
слуховому контролю. Естественнее всего
предположить, что ребенок пытается
подражать произношению взрослых и
что сигналом, используемым при отработке
собственного артикуляторного комплекса,
является расхождение между слуховым
описанием слога взрослого и слога
самого ребенка. Это означает, что ребенок
должен быть способен улавливать на
слух разницу между слогами, т. е. его
восприятие или не должно быть
категориальным, или число различаемых
категорий должно быть больше числа
фонемных категорий у взрослого.
Экспериментальная
проверка способности ребенка различать
разные типы согласных может быть
осуществлена методом исследования
имитации. К сожалению, такие опыты были
проведены только на более старших
детях — в возрасте около трех лет
(Winterkorn et al., 1967). Опыты проводились на
детях американцах; стимулами служили
синтетические слоги. Оказалось, что
дети классифицируют стимулы так же,
как взрослые американцы, положение
границы между категориями стимулов
совпало с положением фонемной границы
у взрослых.
Доказательство
того, что дети различают и могут
имитировать большее число категорий
звуков, чем это требуется, исходя из
числа лингвистических фонем, было
получено Алякринским (Алякринский,
1963). В работе, проведенной на русских
детях 4—7 лет, исследовалась имитация
естественных русских и английских
гласных. Ни один из детей не обучался
английскому языку. Исходный набор
включал 6 русских и 6 английских гласных.
На основе этих гласных была образована
тестовая последовательность из 36
гласных, которые были наговорены
преподавателем фонетики английского
языка и записаны на пленку. Гласные,
созданные детьми при имитации этих
стимулов, были прослушаны группой
опытных фонетиков. Они при записи
обозначали русские гласные русскими
буквами, а английские гласные — фонетиче
510
скими
знаками. Полученные данные приведены
на рис. 216. Можно видеть, что дети оказались
способными сразу же, без тренировки
воспроизвести ряд английских гласных.
Приведенные
выше данные лучше согласуются с гипотезой
приобретенного сходства, чем с гипотезой
приобретенных различий, Приходится
думать, что в процессе обучения речи
происходит увеличение набора
артикуляторных комплексов и сокращение
множества звуковых сигналов — объединение
их в более крупные категории.
Рис.
216. Результаты оценки фонетистами
гласных звуков, созданных
детьми
при имитации английских гласных (верхний
ряд на графике)
и
русских гласных (нижний
ряд)
(по: Алякринский, 1963).
Символ
около каждого круга
обозначает оценку фонетистами исходного
имитируемого
гласного; символы
в секторах
круга обозначают оценки, данные
фонетистами тем
гласным, которые
произнесли дети. Размеры секторов
указывают, какой процент
из гласных,
произнесенных детьми, получил данную
оценку.
Для
выяснения того, как согласованы эти
два процесса и каково их взаимодействие,
важно знать, существуют ли какие-то
врожденные связи (отношения) между
речевыми сигналами и артикуляторными
реакциями. Иначе говоря, встает вопрос
о том, располагает ли ребенок какой-то
врожденной информацией с самого
начала обучения, или обучение начинается
с полного незнания. С этой точки
зрения очень интересны результаты,
полученные в работе Лях (Лях, 1968).
Изучалось подражание совсем маленьких
детей (2—8 месяцев) экспериментатору,
произносившему гласные [и] и [а] в трех
вариантах опыта: беззвучное произнесение,
нормальное произнесение вслух,
произнесение с закрытым от ребенка
лицом.
Оказалось,
что ребенок подражает мимике
экспериментатора — открывает рот в
ответ на [а] и вытягивает губы в ответ
на [и]. Эта мимическая реакция в ряде
случаев сопровождается фонацией,
создаваемые ребенком звуки напоминают
[а] и [и]. Количество подражательных
реакций, вероятность появления фонации
и соответствие реакций стимулам
увеличиваются, если гласные произносятся
вслух, т. е. ребенок может не только
видеть мимику,
511


![]()
