

5 курс / ОЗИЗО Общественное здоровье и здравоохранение / Статистический_анализ_данных_в_медицинских_исследованиях_в_2_ч_Красько
.pdfВ литературе обычно приводятся данные о двустороннем доверительном интервале. Говорят, что рассчитан 1 α % интервал для некоторого параметра
распределения. Например, 95% доверительный интервал для среднего. Указание в тексте публикации значений нижней и верхней границы свидетельствует о том, что интервал двусторонний. Как правило, в публикациях приводится в первую очередь среднее, стандартное отклонение или стандартная ошибка среднего, доверительные интервалы приводятся как дополнительная вспомогательная информация.
Медиана
Точечная оценка. Если значения переменной, полученной в исследовании, упорядочить по возрастанию, то медиана – это значение переменной, которое делит упорядоченную совокупность наблюдений пополам, так что одна половина значений в этой совокупности лежит ниже медианы, а другая их половина – выше медианы. Если совокупность образована нечетным числом значений наблюдаемой переменной, то медиана равна значению переменной, являющемуся серединой упорядоченной совокупности наблюдений. Если же совокупность образована четным числом значений, то медиана определяется значением, лежащим посередине между двумя значениями, находящимися в центре упорядоченной совокупности наблюдений. Медиана – мера положения, используется, когда переменная порядковая или количественная. Медиана нечувствительна к величине крайних значений упорядоченной совокупности наблюдений.
Точечная оценка медианы рассчитывается следующим образом:
Пусть x1 ,x2 , ,xn представляют n значений переменной исследования.
Медиана – центр |
значений, которые упорядочены по возрастанию |
||||
x 1 ,x 2 , ,x n |
x 1 x 2 x n . |
|
|
||
Если n |
~ |
x n 1 2 |
|
|
|
– нечетное x |
|
|
|||
|
~ |
|
x n 2 x n 2 1 |
|
|
Если n |
– четное x |
|
|
|
. |
|
2 |
|
|||
|
|
|
|
|
|
В публикациях приводится медиана, когда распределение переменной исследования отлично от закона нормального распределения. Иногда приводится среднее и медиана, чтобы дать понять читателям, что выборочная переменная не подчиняется закону нормального распределения.
Доверительный интервал для медианы
Интервальная оценка. При расчете точечной оценки медианы выборка по
переменной |
исследования |
упорядочивается |
по возрастанию |
x 1 ,x 2 , ,x n |
||||||||||
x 1 x 2 x n , и каждый член ряда получает свой порядковый номер (номер |
||||||||||||||
взят в скобки при каждом x ). |
|
|
~ |
|
|
|
||||||||
При |
n |
50 доверительный интервал для медианы |
приблизительно |
|||||||||||
x |
||||||||||||||
определяется порядковым номером k , |
|
|
|
|
|
|||||||||
xL xk , xU xn k 1 , |
|
|
|
|
|
|
||||||||
k 1 n z |
|
|
|
1 , с округлением k до меньшего целого числа, |
|
|
||||||||
|
|
n |
|
|
||||||||||
2 |
|
γ |
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|||
где |
zγ |
– |
|
значение -квантиля нормального распределения, |
γ 1 α |
для |
||||||||
|
|
|
|
|
|
|
|
|
|
|
|
2 |
|
|
двустороннего |
|
|
интервала, |
т.е. для α 0,05 |
γ 0,975, |
для |
одностороннего |
|||||||
интервалаγ 1 α .
51

При n 50 можно воспользоваться специальными таблицами или статистическими пакетами.
Доверительные интервалы для медианы редко встречаются в медикобиологических публикациях.
Квартили и квантили
Точечные оценки. Перцентиль – значение данных, которые больше или равны заданному проценту от значений данных выборки. В математических терминах p -ый перцентиль – такое значение данных, которое больше или равно p % всех
данных и меньше или равно (1 p )% данных. Поэтому, если значение x – p -ый перцентиль, то p % значений в наборе данных меньше или равны x , и (100 p )%
значений больше или равны x . Квантиль – это тот же перцентиль, выраженный не в процентах, а в частях ( от 0 до 1).
Квартили (25% и 75% перцентили), а также медиана (50% перцентиль), обеспечивают разбиение упорядоченной количественной выборки на 4 подмножества равной численности. Вычисление данных показателей производится по правилам, принятым для вычисления медианы.
Верхний квартиль (Q75) представляет собой 75% перцентиль выборки. Нижний квартиль (Q25) представляет собой 25% перцентиль выборки.
В публикациях иногда приводятся значения Q25 и Q75 наряду с Q50 –
медианой, когда распределение изучаемой величины отлично от закона нормального распределения. Иногда также приводится Q95 или Q97 например, для
того, чтобы использовать потом такие данные, как референтные. Например, по группе здоровых исследуемых даны Q50 и Q97 диастолического давления. Далее
эти данные могут использоваться для того, чтобы показать, что в исследуемой группе (пациентов с некоторым заболеванием), существует значительное количество случаев с диастолическим давлением выше, чем Q97.
Интерквартильный размах
Точечная оценка. Интерквартильный размах – это разность между верхним и нижним квартилями выборки.
IR Q75 Q25.
Приводится в публикациях. Означает, что половина значений показателя/фактора в исследуемой выборке лежит в пределах интерквартильного размаха.
Мода
Точечная оценка. Мода – это наиболее часто встречающееся в определенной совокупности наблюдений значение показателя/фактора. Также является мерой положения; может использоваться в случае категориальных, порядковых и количественных переменных.
Дисперсия
Точечная оценка. Дисперсия является мерой рассеяния. Точечная оценка по выборке (выборочная дисперсия) рассчитывается как:
s2 |
1 xi x 2 |
, |
|
n |
|
n 1 i 1
где n – численность выборки,
xi , i 1,2, ,n – значения переменной в выборке.
52
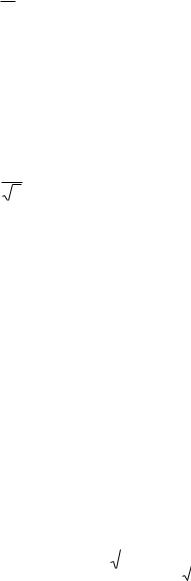
x – выборочное среднее.
Эта формула выборочной оценки дисперсии получена в предположении нормального распределения количественной переменной. Вычисленную по данной формуле оценку допустимо применять только для нормально распределенной количественной переменной, но не для переменных в других шкалах измерения и с другими функциями распределения. Выборочная дисперсия измеряет рассеяние среднего в выборке. Большая дисперсия подразумевает, что множество данных не сгруппировано около среднего. Маленькая дисперсия подразумевает, что большинство данных находится около среднего. На выборочную дисперсию влияют экстремальные значения и значения, которые находятся ниже порога чувствительности метода измерения.
Стандартное отклонение
Точечная оценка. Стандартным отклонением (среднеквадратичным отклонением, с.к.о.) называют корень квадратный из дисперсии. Вычисление стандартного отклонения производится по формуле:
s 
 s2 ,
s2 ,
где s2 – выборочная дисперсия.
В медико-биологических публикациях s часто обозначают как SD (standard deviation).
Стандартная ошибка среднего
Точечная оценка. Стандартная ошибка среднего SE (standard error) определяется по формуле:
SE sn ,
где s – выборочное стандартное отклонение, n – численность выборки.
Традиционно запись, характеризующая среднее значение и его стандартную ошибку, представляется в виде x SE .
Пропорция
Точечная оценка. Если в исследовании имеется биноминальная переменная, которая кодируется как “1” – состояние (событие), которое интересует исследователя, “0” – противоположное состояние, то точечная оценка пропорции по выборке рассчитывается как:
πˆ kn , где
k – количество интересующих исходов в выборке, n – численность выборки.
Дисперсия пропорции
Точечная оценка. Рассчитывается как: s2 πˆ 1 – πˆ .
|
|
|
s |
|
. |
||
Соответственно s |
s2 , SE |
||||||
|
|
|
|||||
|
|
|
|
n |
|||
53

Доверительный интервал для пропорции
Интервальная оценка. Доверительный интервал для пропорции рассчитывается упрощенно (биноминальное распределение аппроксимируется нормальным распределением), если k 4 и n k 4.
|
k |
1 z2 |
– z |
k n– k |
1 z2 |
|
|
|
|
|||||||
Нижняя граница: π L |
|
|
2 γ |
|
γ |
n |
4 |
γ |
|
|
|
|||||
|
|
|
|
|
|
|
|
. |
|
|
|
|
||||
|
|
|
|
n z2 |
|
|
|
|
|
|||||||
|
|
|
|
|
|
|
γ |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||
|
|
k 1 z2 |
z |
|
k n – k 1 z2 |
|
|
|
||||||||
Верхняя граница: πU |
|
2 γ |
γ |
|
n |
4 |
γ |
|
|
|
||||||
|
|
|
|
|
|
. |
|
|
|
|||||||
|
|
|
n z2 |
|
|
|
|
|
||||||||
|
|
|
|
|
|
|
γ |
|
|
|
|
|
|
|
|
|
k – количество интересующих исходов в выборке; |
|
|
|
|||||||||||||
n – численность выборки; |
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
zγ – значение -квантиля |
нормального |
распределения, |
γ 1 α |
2 |
для |
|||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
двустороннего интервала, т.е. |
для |
|
α 0,05 |
γ 0,975, для |
одностороннего |
|||||||||||
интервалаγ 1 α .
Большинство статистических пакетов рассчитывают доверительный интервал для пропорции при любых условиях.
Ремарка: Вариант расчета с аппроксимацией биноминального распределения нормальным не является единственным. Реализация расчета в статистическом пакете также может быть не единственна.
Интенсивность
Точечная оценка. Если исследователь на протяжении времени t наблюдал события в выборке, то точечная оценка интенсивности рассчитывается как:
λˆ kt , где
k – количество интересующих исходов в выборке, t – время наблюдения.
Пример: в когортном исследовании приняло участие 600 человек, из них 100 наблюдалось в течение года, 200 – в течении 2 лет, 300 – в течение трех лет. Тогда количество человеко-лет наблюдения составит: t =100×1+200×2+300×3=1400 .
Дисперсия интенсивности
Точечная оценка. Дисперсия интенсивности равна D λˆ .
Доверительный интервал для интенсивности
Интервальная оценка. Если произошло количество событий k за время t , то
0, k 0; |
|
|
|
|
|
|
|
Нижняя граница:λL |
2 |
|
,2k , k 0; |
0,5χ 1–α |
2 |
||
|
|
|
|
Верхняя граница: λU 0,5χ 2α 2 ,2k 2 ,
54

где χ 2 |
есть значение -квантиля 2 -распределения с v |
степенями свободы. |
|||
γ ,v |
|
|
|
|
|
Для нижней границы γ 1 α |
2 |
(т.е. для 0,05 0,975), |
v 2k и для верхней |
||
|
|
|
|
|
|
границы γ α |
2 |
, v 2k 2. |
|
|
|
|
|
|
|
|
|
7.1.5. |
Представление данных в исследованиях |
|
|||
Очень часто исследователи задают вопрос о том, как правильно описать данные для публикации, отчета, как представить дескриптивные (описательные) статистики данных.
Очень многое зависит от …здравого смысла. Например, возраст пациентов – интересен возрастной охват. Имеет смысл привести минимальный и максимальный возраст. Однако если исследование предполагало, к примеру, детей в возрасте 11-14 лет, то минимум и максимум не нужны.
Количество наблюдений также может сыграть роль в представлении данных. Например, если у вас 5 пациентов, то описывать их показатели медианой и квартилями не имеет смысла. Понятно, что это будут три серединных значения. Возможно, проще перечислить наблюдаемые значения показателя или дать минимум, максимум и серединное значение (медиану).
Исходя из практики автора, можно рекомендовать следующее:
При описании когорты пациентов размером до 20-30 человек, количественные показатели, не подчиняющиеся закону нормального распределения можно представить медианой, минимумом и максимумом. При размере когорты свыше 20-30 - количественные показатели, не подчиняющиеся закону нормального распределения можно представить медианой и квартилями.
В случае нормального распределения количественные показатели можно представить средним и стандартным отклонением независимо от размера выборки.
Но правило “здравого смысла” не отвергаем, например, длительность наблюдения за пациентами традиционно представляется медианой, минимумом и максимумом независимо от количества пациентов в исследовании, поскольку эти данные дадут возможность оценить, как долго продолжалось исследование. Аналогично можно поступить и с возрастным показателем в естественной выборке. В целевой выборке те показатели, которые были условием включения в целевую выборку, описывать не имеет смысла.
При описании данных лабораторного эксперимента (см. Раздел 22) мы полагаем, что все наблюдения были сделаны в одинаковых условиях, измерения проведены по одной и той же методике. Чаще всего количественные показатели в этом случае имеют нормальное или логнормальное распределение и отклонения от среднего вызваны случайными факторами. Стандартное отклонение в этом случае чаще и в большей степени несет информацию об ошибке измерений, нежели о биологической вариации параметра. Поэтому в лабораторных экспериментах указывают среднее показателя, которое и хотели измерить в условиях эксперимента, а также ошибку среднего или 95 % доверительный интервал среднего.
Частотные характеристики, как правило, описываются процентами, однако при малой частоте имеет смысл привести не только процент, но и абсолютное значение, например, “из 1200 пациентов 2 (менее 0,2 %) получили осложнения”.
Часто возникает вопрос об округлении расчетных оценок. Правила таковы: если мы расчитали стандартное отклонение (стандартную ошибку), то сначала округляем это число. Если первая значащая цифра 1 или 2 – округляем до двух
55

значащих цифр стандартное отклонение (стандартную ошибку), затем до тех же позиций округляем саму оценку. Если первая значащая цифра 3-9, то округляем до первой значащей цифры стандартное отклонение (стандартную ошибку) и до той же позиции знака округляем саму оценку.
Например: рост составил 181,375 12,79 см, округляется 181 12 см; рост составил 181,375 34,58 см, округляется 180 30 см.
Если вы представляете эмпирические величины, например, медиана, квартили, минимум, максимум, то представление идет с точностью шкалы, в которой измеряли данную величину. Например, есть измерения 10; 8,7; 9,2; 11,4; 3,5; 6; 4,5. Медиана выборки составила 8,7.
Правила носят рекомендательный характер, есть стандарты СТ СЭВ 543-77 "Числа. Правила записи и округления", СТБ 1988-2009 (Государственный стандарт Республики Беларусь). Также рекомендации можете найти в книге Ланг Т.А., Сесик М., Как описывать статистику в медицине.
7.2.Графическое представление данных
Для “взгляда” на то, как ведет себя переменная в исследовании, удобно и полезно использовать графические представления. Они очень разнообразны, однако описаны ниже будут только основные.
7.2.1. Количественные данные
Графики частот/гистограмма
Два самых известных графических метода для общего взгляда на распределение данных – это график частот и гистограмма. И график частот, и гистограмма основаны на одних и тех же принципах представления данных: деление диапазона данных на интервалы, расчет количества точек, попавших в интервал, и отображение количества точек, как высоты на столбиковой диаграмме. Однако есть небольшие различия между гистограммой и графиком частот. На графике частот относительная высота полос представляет относительную плотность данных. В гистограмме площадь полосы представляет относительную плотность данных. Различие между двумя графиками становится более заметным, когда используются неравные размеры интервалов.
Гистограмма и график частот помогают оценить симметрию и изменчивость (вариабельность) данных. Если данные симметричны, то структура графика будет симметрична относительно центральной точки, такой как среднее. Гистограмма и график частот показывают, скошены ли данные и направление уклона (асимметрии).
Визуальное изображение на гистограмме или графике частот может быть весьма чувствительно к выбору ширины интервала. Выбор числа интервалов определяет, показывает ли гистограмма
Переменная
Рис.7-1. Пример графика частот
56

больше деталей для малых интервалов, или данные распределения будут выглядеть более сглажено (Рис 7–1).
“Ящик с усами” |
|
|
|
|
|
|
|
|
|
“Ящик с усами” (рис. 7–2) является схематичной |
|
|
|
|
|||||
диаграммой, |
|
полезной |
для |
визуализации |
основных |
* |
|
||
статистических характеристик (параметров) распределения |
|
|
|
|
|||||
данных. Эта диаграмма полезна в ситуациях, где нет |
|
|
|
|
|||||
|
|
|
|
||||||
необходимости |
|
или где |
невозможно изобразить |
все детали |
|
+ |
|
||
распределения. “Ящик с усами” состоит центрального блока, |
|
|
|||||||
|
|
|
|
||||||
разделенного вертикальной и горизонтальной линиями. |
|
|
|
|
|||||
|
|
|
|
||||||
Традиционно шкала самих данных идет снизу вверх, от меньших |
|
|
|
|
|||||
значений к большим. Высота центрального блока указывает |
|
|
|
|
|||||
расположение большой части данных (центральные 50 %), в то |
|
|
|
|
|||||
время как длина вертикальных “усов” показывает, насколько |
|
|
|
|
|||||
|
|
|
|
||||||
вытянуты хвосты распределения. У ширины блока нет никакого |
|
|
|
|
|||||
специфического |
значения; график |
может быть |
узким или |
* |
|
||||
широким1. Выборочная медиана – горизонтальная линия, |
|
||||||||
|
|
|
|
||||||
разделяющая блок, и среднее выборки обозначается знаком ‘+’. |
Рис.7-2. Пример |
||||||||
Любые необычно малые или большие данные точки показаны '*' |
“ящика с усами” |
||||||||
на графике. “Ящик с усами” может использоваться для оценки |
|
|
|
|
|||||
симметрии |
данных. |
Если |
распределение |
является |
|
|
|
|
|
симметричным, то блок разделен на две равные половины медианой среднее будет находиться на линии медианы, усы будут одинаковой длины и число экстремальных точек данных будет представлено одинаково на каждом конце.
Таким образом, из графического представления может быть получена информация о местоположении распределение (медиана, среднее), рассеяния (центральный блок – это интерквартильный размах), интервал изменения (крайние значения распределения), наличие выбросов, некоторая информация о форме распределения (взаиморасположение медианы и среднего).
График квантиль-квантиль
График квантиль-квантиль (нормальный Q-Q график) используется для того, чтобы примерно определить, насколько хорошо данные соответствует модели нормального распределения. Присутствует практически во всех статистических пакетах. На нем по горизонтальной оси откладываются квантили нормального распределения(которое строится на основе расчетов среднего и стандартного отклонения по наблюдаемым значениям), по вертикальной – квантили наблюдаемых значений (эмпирические данные – как есть в исследовании). Если полученный график – прямая линия, данные распределены нормально. Если график не является прямой, уходы от прямой линии дают важную информацию о том, как распределение данных отклоняется от нормального распределения. Если график нормальной вероятности не линеен, график может использоваться для того, чтобы определить степень симметрии (или асимметрии).
Если данные в верхнем хвосте ниже линии квартилей, а в нижнем хвосте – выше линии квартилей, то на хвостах меньше данных, чем ожидалось при нормальном распределении. Если данные в верхнем хвосте выше линии, а данные в
1 Если приводятся распределения нескольких групп на одном рисунке, то ширина “ящика с усами”может характеризовать размер групп.
57

нижнем хвосте ниже линии квартилей, то данные на хвостах больше, чем ожидалось бы при нормальном распределении. Q-Q график может использоваться для идентификации потенциальных выбросов в данных. Значение данных (или несколько значений данных) намного бóльшее или намного меньшее, чем остальные значения данных влекут за собой эффект сжатия данных в середине графика искажая линию (Рис.7–3).
|
|
|
|
0,01 |
0,05 |
|
0,25 |
0,50 |
0,75 |
0,90 |
|
0,99 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
100 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
0,01 |
|
0,05 |
|
0,25 |
|
0,50 |
|
0,75 |
0,90 |
|
|
0,99 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
70 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
80 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
60 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Наблюдаемые |
60 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Наблюдаемые |
50 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
40 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
40 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
30 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
20 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
20 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
0 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
10 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
-20 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
0 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
-40 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
-10 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Т еоретические |
|
|
|
|
|
|
|
|
|
|
|
|
|
Теоретические |
|
|
|
|
|
|
||||
|
35 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
50 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
30 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
45 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
40 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
наблюдений |
25 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
35 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
наблюдений |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
20 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
30 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Количество |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Количество |
25 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
15 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
20 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
10 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
15 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
10 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
5 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
5 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
0 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
0 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
-5 |
0 |
5 |
10 |
15 |
20 |
25 |
30 |
35 |
40 |
45 |
50 |
55 |
60 |
65 |
|
-5 |
0 |
5 |
10 |
15 |
20 |
25 |
30 |
35 |
40 |
45 |
50 |
55 |
60 |
65 |
|
|
Рис.7–3. Примеры Q-Q графиков и соответствующих гистограмм |
|
|
|
|
|
|
|
|
|
||||||||||||||||||||
Ко л и ч е ств о н а б л юд е н и й
На б л юд а е мо е
50
45
40
35
30
25
20
15
10
5
0
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
Пе р е ме н н н а я 1
8
7
6
5
4
3
2
1
0
Пе р е ме нна я 1 Но р ма ль но е р а спр е де л е ние
1 .0
0 .8
0 .6
0 .4
0 .2
0 .0 |
|
|
|
|
|
0 .0 |
0 .2 |
0 .4 |
0 .6 |
0 .8 |
1 .0 |
Те о р е тич е ск о е
|
350 |
|
300 |
наблюдений |
250 |
200 |
|
Количество |
150 |
|
100 |
50
0 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
-0.2 |
0.0 |
0.2 |
0.4 |
0.6 |
0.8 |
1.0 |
1.2 |
1.4 |
1.6 |
1.8 |
2.0 |
2.2 |
2.4 |
2.6 |
|
|
|
|
|
|
Перем енная 2 |
|
|
|
|
|
|
||
2 .6
2 .4
2 .2
2 .0
1 .8
1 .6
1 .4
1 .2
1 .0
0 .8
0 .6
0 .4
0 .2
0 .0 -0 .2
Норм альное распределение Перем енная2
|
3.0 |
|
2.5 |
|
2.0 |
ые |
1.5 |
Наблюдаем |
0.5 |
|
1.0 |
0.0 -0.5 -1.0
-4 |
-3 |
-2 |
-1 |
0 |
1 |
2 |
3 |
4 |
Теоретическое
Рис.7–4. Примеры визуализации количественных данных
58

Ремарка. В некоторых статистических пакетах при построении графика нормальной вероятности по оси Х отображается наблюдаемое распределение, по оси Y теоретическое (ожидаемое). Будьте внимательны.
Можно построить Q-Q график не только для нормальной вероятности, но и любого другого распределения, и посмотреть, как данные соотносятся с теоретическим распределением. Можно также построить график по двум переменным, приняв одну из них за основу для другой.
Примеры визуализации представлены на Рис.7–4: один и тот же набор данных представлен в разных видах. Как видно, распределение переменной 2 скошено вправо. Переменная 1 скорее всего распределена нормально.
Важность визуального представления данных сложно переоценить. Для понимания этого момента можно привести следующий пример1 – квартет Анскомба
(Anscombe's quartet).
Таблица 7–1. Данные квартета Анскомба
набор 1 |
набор 2 |
набор 3 |
набор 4 |
||||
x |
y |
x |
y |
x |
y |
x |
y |
10,0 |
8,04 |
10,0 |
9,14 |
10,0 |
7,46 |
8,0 |
6,58 |
8,0 |
6,95 |
8,0 |
8,14 |
8,0 |
6,77 |
8,0 |
5,76 |
13,0 |
7,58 |
13,0 |
8,74 |
13,0 |
12,74 |
8,0 |
7,71 |
9,0 |
8,81 |
9,0 |
8,77 |
9,0 |
7,11 |
8,0 |
8,84 |
11,0 |
8,33 |
11,0 |
9,26 |
11,0 |
7,81 |
8,0 |
8,47 |
14,0 |
9,96 |
14,0 |
8,10 |
14,0 |
8,84 |
8,0 |
7,04 |
6,0 |
7,24 |
6,0 |
6,13 |
6,0 |
6,08 |
8,0 |
5,25 |
4,0 |
4,26 |
4,0 |
3,10 |
4,0 |
5,39 |
19,0 |
12,50 |
12,0 |
10,84 |
12,0 |
9,13 |
12,0 |
8,15 |
8,0 |
5,56 |
7,0 |
4,82 |
7,0 |
7,26 |
7,0 |
6,42 |
8,0 |
7,91 |
5,0 |
5,68 |
5,0 |
4,74 |
5,0 |
5,73 |
8,0 |
6,89 |
Это четыре набора данных (табл.7–1), которые практически не различаются в средних, дисперсиях, корреляциях (в этом можно убедиться самостоятельно). Однако, их визуализация дает четкое понимание, что наборы совершенно различны
(Рис.7–5).
Рис.7–5. Квартет Анскомба
1 F.J. Anscombe, "Graphs in Statistical Analysis," American Statistician, 27 (February 1973), 17-21.
59

7.2.2. Качественные данные
Качественные данные также можно представить графически с помощью столбиковой или круговой диаграммы с указанием числа случаев в категории, или процентного соотношения. Также существуют более сложные и интересные представления качественных данных, которые можно найти в любом статистическом пакете.
14 |
|
|
12 |
|
|
|
|
|
|
|
|
|
|
|
|
12 |
|
|
|
|
|
К5 |
К1 |
|
|
|
|
|
9 |
16% |
|
10 |
|
|
|
|
24% |
||
|
|
|
|
|
|
|
|
8 |
6 |
7 |
|
|
|
|
|
|
|
|
|
|
|
К2 |
|
6 |
|
|
|
|
|
К4 |
|
|
|
|
|
|
|
19% |
|
4 |
|
|
|
3 |
|
8% |
|
|
|
|
|
|
|||
2 |
|
|
|
|
|
|
К3 |
|
|
|
|
|
|
|
|
0 |
|
|
|
|
|
|
33% |
|
К1 |
К2 |
К3 |
К4 |
К5 |
|
|
Рис. 7–6. Примеры визуализации качественных данных
7.3.Описание переменной исследования
Схемы описания переменной исследования в унивариантном анализе приведены на рис. 7–7.
количественная переменная |
порядковая |
|
(нормальное распределение) |
переменная |
|
|
|
|
|
|
|
|
|
|
Медиана, Среднее, дисперсия, размах, квартили интервальные оценки
номинальная переменная
Связана со |
|
Не связана |
|
|||
временем |
|
со временем |
|
|||
наблюдения |
|
наблюдения |
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Интенсивность, |
|
Пропорция, |
|
|||
доверительные |
|
доверительные |
|
|||
интервалы |
|
интервалы |
|
|||
|
|
|
|
|
|
|
Рис. 7–7. Схемы описания исследуемой характеристики данных
Статистические задачи – описание одной выборки, проверка соответствия эмпирического и теоретического законов распределения, проверка предположения о характере распределения. В таблице 7–2 приведена сводная информация по описанию переменных исследования.
60