

5 курс / ОЗИЗО Общественное здоровье и здравоохранение / Статистический_анализ_данных_в_медицинских_исследованиях_в_2_ч_Красько
.pdfy
yˆ1
yˆ
1
yˆ
0
yˆ 0
|
|
x0 |
|
x |
|
|
x1 |
|
|
x |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
Рис.16–3. Различия |
в средних двух групп с |
учетом ковариаты. |
|
|
|
||||||||
Модель с учетом конфаундера запишется как |
|
|
|
||||||||||
E y | x β0 β1z β2x . |
Предполагая, |
что |
переменная |
z бинарная, можно |
|||||||||
переписать уравнение следующим образом: |
|
|
|
|
|
||||||||
|
β0 β2x, |
z 0; |
|
|
|
|
|
|
|
|
|
||
E y|x |
|
|
|
|
|
|
|
|
|
|
|
|
|
β0 β1 β2x, |
z 1. |
|
|
|
|
|
|
|
|
|
|||
Тогда |
разность |
в |
средних |
в |
двух |
|
группах |
составит |
|||||
E y|z 1 E y|z 0 β0 β1 |
β2x1 |
β0 β2x0 β1 β2 x1 x0 |
. |
Это означает, что |
|||||||||
при сравнении двух групп в разности присутствует не только истинная разность между группами β1 , но и дополнительный компонент β2 x1 x0 , связанный с
различием в средних конфаундера. Дополнительный компонент равен нулю в двух случаях: если параметр β2 значимо не отличается от нуля, или x1 x0 значимо не
отличается от нуля. Иначе необходимо рассчитать скорректированную (adjusting) разницу в эффектах. Оценка различий производится при значении ковариаты, которая равна взвешенному среднему x . Как видно на рис. 16.3 разность в средних
при скорректированном значении ковариаты равна yˆ yˆ .
1 0
Все эти рассуждения верны только в случае выполнения предположений ковариационного анализа об одинаковых уклонах и линейной связи ковариаты с зависимой переменной.
16.6.Взаимодействие предикторов в линейной модели
Если предположения ковариационного анализа не выполняются, то это может означать, что эффект предиктора в модели меняется в зависимости от уровня (значений) другого предиктора или конфаундера. Конфаундер в этом случае называют модификатором эффекта (effect modifier).
В медико-биологических исследованиях часто встречаются такие взаимодействия как:
Лечение степень тяжести заболевания; Возраст факторы риска; Возраст тип заболевания; Пол факторы риска; Пол тип заболевания;
141
Раса заболевание; Измерения состояние пациента в момент измерения;
Географическое положение заболевание и др.
С точки зрения математических основ статистических моделей – какая из переменных является предиктором, а какая конфаундером, не имеет значения. В модель включаются компоненты более высокого порядка, которые описывают взаимодействие между переменными. Интерпретация зависит от проводимого исследования.
Модель строится следующим образом:
Предположим, у нас два предиктора: x1 и x2 . В этом случае |
модель |
|
записывается как: |
E y|x – среднее значение |
|
E y | x β0 β1x1 β2x2 β3x1x2 , |
y при |
|
определенных значениях x , x – вектор наблюдений, т.е. x1 , x2 . Такая модель носит
также название модели со взаимодействием второго порядка.
Рассмотрим модель с количественной переменной-предиктором и бинарной переменной-предиктором.
Поскольку очень часто вмешивающимися переменными выступают возраст и пол, рассмотрим эту модель взаимодействия на примере этих переменных: возраст и пол.
Пусть x1 age , x2 sex , sex 0 – мужcкой пол (male), sex 1 – женский пол
(female).
Тогда интерпретация коэффициентов следующая:
E y |age 0& sex male β0 ; |
|
|
|
|
E y |age x 1 & sex male E y |age x & sex male β1 ; |
|
|
||
E y |age 0& sex female β2 |
; |
|
|
|
E y |age x 1 & sex female |
E y |age x & sex female |
|
|
|
E y |age x 1 & sex male E y |age x & sex male β3 . |
|
|
||
Иными словами, среднее |
значение y при age 0 и sex male |
есть |
β0 ; |
|
изменение в среднем значении |
y при увеличении age на 1 и sex male |
есть β1 ; |
||
среднее значение y при age 0 |
и sex female есть β2 ; при увеличении age |
на 1 |
||
значение y изменилось для мужчин и для женщин, разность между |
изменениями y |
||
есть β3 ,т.е., |
β3 – это разность |
в уклонах двух регрессионных |
уравнений: для |
x2 male и |
x2 female . На рис. |
16–4 приведена геометрическая интерпретация |
|
коэффициентов. Предположение о рандомизации геометрически обозначает, что ковариата (age ) имеет одинаковое распределение для уровней x2 male и
x2 female.
142

y |
|
|||
|
|
|
|
|
|
x2 male |
|
|
β1 |
|
|
|
|
|
β2 |
|
|||
β0 |
β1 β3 |
|||
|
|
|
|
|
|
x2 female |
|
||
|
|
|
||
|
|
|
1 |
x1 age |
|
|
|
||
Рис.16–4. Геометрическая интерпертация модели со взаимодействием переменных
Если существует модель со взаимодействиям второго порядка, нужно интерпретировать эффекты первого порядка в условиях, которые сводят эффект взаимодействия к нулю. В нашем случае эффект взаимодействия ( β3x1x2 ) равен
нулю либо при age 0, либо при sex male .
Какие гипотезы о параметрах имеет смысл тестировать?
H0 : β1 0 – означает, что ассоциируется ли возраст с переменной y для мужчин.
H0 : β2 0 – ассоциируется ли пол с переменной y для возраста 0 лет.
Такие гипотезы не являются подходящими для исследования. Представим отношения и взаимодействия в табл.16–2:
Таблица 16–2. Гипотезы при подгонке модели со взаимодействием переменных
Варианты гипотез |
Математическое |
|
|
утверждение |
|
|
|
|
Эффект пола независим от эффекта возраста |
H0 : β3 0 |
|
Эффект возраста независим от эффекта пола |
|
|
Пол и возраст аддитивны (нет эффекта |
|
|
наложения) |
|
|
Эффекты возраста для мужчин и женщин |
|
|
параллельны |
|
|
|
|
|
Возраст и пол взаимодействует друг с другом |
HA : β3 0 |
|
(совместный эффект) |
|
|
Возраст модифицирует эффект пола |
|
|
Пол модифицирует эффект возраста |
|
|
|
|
|
Возраст не ассоциируется с y |
H0 : β1 β3 0 |
|
|
|
|
Возраст ассоциируется с y |
HA :β1 0 или β3 |
0 |
Возраст ассоциируется с y или для мужчин или |
|
|
для женщин |
|
|
|
|
|
Пол не ассоциируется с y |
H0 : β2 β3 0 |
|
|
|
|
Пол ассоциируется с y |
HA : β2 0 или β3 |
0 |
Пол ассоциируется с y для некоторых значений |
|
|
143

возраста |
|
|
|
|
|
|
|
Ни возраст ни пол не ассоциируются с y |
H0 : β1 β2 β3 |
0 |
|
|
|
|
|
Или возраст или пол ассоциируются с y |
HA : β1 0 или |
β2 0 |
|
|
или β3 0 |
|
|
|
|
|
|
Последний тест в таблице – тест отсутствия |
глобальной ассоциации |
||
(отсутствия взаимодействия).
Геометрически отсутствие взаимодействия выглядит как показано на рис. 16– 5. Уклоны линий регрессии одинаковы, разность между ними β3 0 . В этом случае
мы можем говорить об эффекте пола независимо от возраста, поскольку регрессионные линии параллельны, находятся на одинаковом расстоянии друг от друга во всей области изменения переменной x . Эффект возраста присутствует, но не зависит от пола. Проще говоря, обе линии регрессии параллельно возрастают (убывают) под одним углом. Модель приводится к модели ковариационного анализа.
y
x2 |
male |
β1 |
|
|
β1 β3 β1 0
β0
β2  x2 female
x2 female
1 |
x1 age |
Рис. 16–5. Геометрическая интерпретация модели с отсутствием взаимодействия
Теперь рассмотрим случай, когда оба предиктора бинарные. Предположим некоторое гипотетическое исследование: экспериментальное лечение, которое контролирует уровень гемоглобина в крови. Предполагается, что есть некоторая зависимость между уровнем гемоглобина и давлением; лечение действует как на гемоглобин, так и на давление.
В качестве бинарного предиктора может быть использована и количественная переменная, если ее по некоторому принципу представили как бинарную, например, давление (Presure) норма (0) и выше нормы (1). Второй предиктор бинарный (Treatment): пациент получал плацебо (0), пациент получал лечение (1).
E y | x β0 β1 Presure β2 Treatment β3 Presure Treatment .
Составим таблицу комбинаций бинарных предикторов и соответствующего вида уравнения регрессии (Табл. 16–3).
Таблица 16–3. Уравнение регрессии при двух бинарных переменных
|
|
|
|
|
Группы |
Presure |
Treatment |
P x T |
E y|x |
|
|
|
|
|
1 |
0 |
0 |
0 |
β0 |
|
|
|
|
|
2 |
1 |
0 |
0 |
β0 β1 |
|
|
|
|
|
144
|
|
|
3 |
|
0 |
|
1 |
|
0 |
β0 β2 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
4 |
|
1 |
|
1 |
|
1 |
β0 β1 β2 β3 |
|
|
|
|
|
|
|||||
В табл.16–3: β1 – эффект, связанный с нарушением давления в группе |
||||||||||
плацебо; |
β2 |
– эффект, связанный с лечением в группе с нормальным давлением; |
||||||||
разность |
в |
лечении |
в группе с высоким |
давлением |
будет определяться как |
|||||
β0 β1 β2 |
β3 β0 |
β1 β2 β3 ; β3 |
– даст разницу в эффектах лечения в двух |
|||||||
группах.
Гипотеза H0 : β3 0 – гипотеза об эквивалентных эффектах лечения в группе с высоким и нормальным давлением.
Вариант линейной регрессии с двумя бинарными предикторами полностью аналогичен двухфакторной ANOVA. Это регрессионный подход к многофакторной
ANOVA.
Все предположения, касающиеся остатков (ошибки модели) остаются в силе и для моделей с взаимодействием нескольких переменных.
16.7.F-критерий в линейной регрессии
Влинейной регрессии оценка значимости коэффициента уклона исследуется
спомощью анализа таблицы вариаций (дисперсионного анализа). Эта таблица разделяет общую сумму квадратов отклонений наблюдений от их средних на две части: сумма квадратов отклонений наблюдений от линии регрессии RSS (остаточная сумма квадратов) и сумма квадратов отклонений прогнозируемых значений на основе регрессионной модели от среднего (или регрессионная сумма квадратов, сумма квадратов модели). Это просто удобный способ отображения сравнения наблюдаемых и прогнозных значений по двум моделям. В линейной регрессии сравнения наблюдаемых и предсказанных значений базируется на основе квадрата расстояния между ними.
Если yi –это i -е наблюдение, yˆi – и обозначает предсказанное значение i -го наблюдения , то это сравнение может осуществляться на базе статистики
N
RSS yi yˆ i 2 .
i 1
Если модель не содержит независимых переменных, а только параметр β0 , то βˆ0 y , т.е. среднее значение y . RSS в этом случае была равна общей вариации,
N |
N |
2 |
N |
RSS yi yˆi 2 |
yi βˆ0 |
yi y 2 TSS . |
|
i 1 |
i 1 |
|
i 1 |
Изменения в общей вариации могут снижаться при использовании модельного уравнения, содержащего независимые переменные. Большое снижение означает значимое влияние независимой переменной. Таким образом, когда мы включаем предиктор в модель, любое значимое снижение RSS будет связано с тем, что уклон (параметр регрессии) для этого предиктора не равен нулю.
N |
N |
MSS TSS RSS yi y 2 |
yi yˆi 2 – разность в сумме квадратов |
i 1 |
i 1 |
вариации модели без предикторов и сумме квадратов вариации модели с предикторами. Больше значение MSS будут свидетельствовать о том, что предиктор (предикторы), включенные в модель значимо снижают вариацию и действительно могут предсказать значения y .
145
Оценить значимость можно с помощью статистики Фишера.
Статистика |
F |
N q |
|
MSS |
, где |
q |
– количество оцениваемых параметров |
|
q 1 |
RSS |
|||||||
|
|
|
|
|
|
|||
модели, N – количество |
наблюдений |
|
подчиняется распределению Фишера с |
|||||
q 1;N q степенями свободы. Статистика F проверяет общую гипотезу о том, что
между предикторами и зависимой переменной нет связи. Альтернативная гипотеза гласит, что хотя бы для одной переменной связь существует. F-критерий покажет, значимо ли снижается вариация в результате использования модели, т.е. моделирования зависимости переменной y от предикторов. Однако, насколько
модель подходит вашим данным – на это F-критерий не ответит. Вполне возможно, что использование другой модели, отличной от линейной, даст тоже значимое снижение вариации. F-критерий в этом случае сравнивает модель с переменными и модель, где β1 β2 βp 0 , т.е. модель без предикторов.
Также F-критерий может использоваться для тестирования включения дополнительной переменной/нескольких переменных в модель или исключения переменной/нескольких переменных из модели, т.е. насколько значимо изменится вариация при таком включении/исключении. Могут сравниваться только модели, построенные на одном наборе данных. Сравнение моделей с помощью F-критерия (или других критериев: критерия отношения правдоподобия, критерия Вальда и пр.) покажет, какая из них лучше объясняет поведение y . Но сравнение не покажет,
выполняются ли условия, лежащие в основе модели (см. 16.8), адекватны ли модели данным и пр.
Роль F-критерия очень высока при построении модели последовательно, т.е. при экспериментах по включению одних предикторов, исключению других. Каждый раз мы можем оценить значимость изменений в двух последовательных моделях, используя этот критерий.
F-критерий также используется для тестирования линейных гипотез, когда мы можем проверить равенство или комбинацию нескольких параметров регрессии, но обсуждение этой темы выходит за рамки пособия.
16.8.Анализ остатков
Для того, чтобы проверить предположения модели об ошибке, используются методы анализа остатков (resudual analysis). Этот анализ является обязательным. Без него нельзя определить, действительно ли модель подобрана в соответствии с имеющимися данными.
16.8.1. Предположение линейности модели
Напомним, что линейность для регрессионных моделей интересна с точки зрения ее свойства: приращение зависимой переменной пропорционально приращению независимой переменной. Соответственно, речь идет о количественных переменных. Для категорий понятие приращения не имеет смысла, только оценка различий между группами.
Нарушение предположения линейности крайне серьезны – если вы используете линейную модель данных, которые на самом деле нелинейно связаны между собой, ваши прогнозы на основании такой модели, вероятно, будут ошибочны, особенно, если прогноз экстраполируется за пределы данных выборки.
146
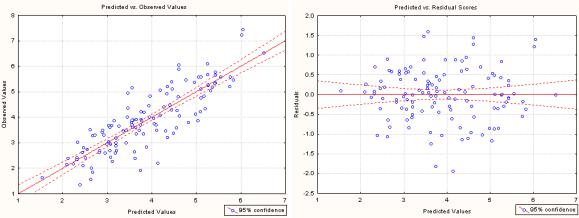
Нелинейность, как правило, наиболее заметна, если построить точечный график наблюдаемых значений в зависимости от предсказанных значений (observed versus predicted values), а также график остатков в зависимости от предсказанных значений (residuals versus predicted values). На первом графике точки должны быть симметрично распределены вокруг диагональной линии, на втором – симметрично горизонтальной линии. На рис 16–6 изображены графики, которые свидетельствуют об отсутствии нарушения предположения о линейности.
Рис 16–6. Tочечные графики для проверки линейности модели
Безусловно, эти графики не единственные для диагностики линейности. Но они легко доступны практически в каждом статистическом пакете. Для отображения более специфических графиков иногда приходится производить определенные расчеты, иногда они генерируются статистическим пакетом по вашему запросу. Поэтому внимательно читайте разделы помощи по диагностике линейности модели в вашем статистическом пакете.
Если нелинейность существует, то можно рассмотреть вопрос о применении нелинейного преобразования для зависимых и/или независимых переменных.
16.8.2. Предположение независимости остатков
Нарушения независимости также очень серьезно, особенно если модель включает такую переменную как время. Анализ временных рядов – это специальные модели регрессионного анализа. В этом пособии анализ временных рядов не рассматривается, но тем не менее можно упомянуть, что определить автокорреляцию остатков можно с помощью критерия Дарбина-Уотсона (DurbinWatson test).
Корректировка такой модели зависит от того, положительна автокорреляция или отрицательна. Возможно, в вашей модели присутствует эффект отставания или опережения предикторов от переменной y во времени.
16.8.3. Предположение о гомоскедастичности
Нарушения предположения о гомоскедастичности усложняет оценку истинного стандартного отклонения ошибки прогноза, в результате доверительные интервалы прогнозного значения становятся либо слишком широкими, либо слишком узкими. Гетероскедастичность также может изменять оценку коэффициентов модели.
147
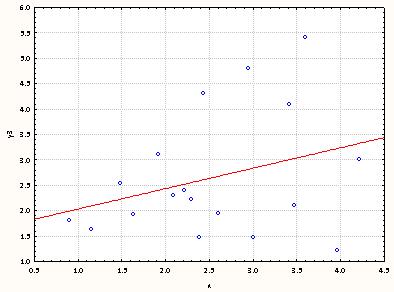
Определить это нарушение можно, построив график остатков в зависимости от предсказанных значений. Если модель включает переменную, связанную со временем, то также можно использовать график остатков в зависимости от времени. Если с увеличением предсказанных значений (времени) остатки становятся более рассеянными вокруг горизонтальной линии, то предположение о гомоскедастичности остатков нарушается (см.рис. 16–7).
Рис 16–7. Пример нарушения гомоскедастичности в линейной регрессии
Гетероскедастичность также может быть побочным продуктом существенного нарушения предположений линейности и/или независимости, поэтому сначала надо удостоверится, что эти предположения не нарушены.
16.8.4. Предположение о нормальности распределения ошибки
Нарушение предположения о нормальности ведет к скошенным оценкам параметров модели и влияет на расчет доверительных интервалов. Иногда распределение остатков "скошено" из-за наличия нескольких крупных выбросов в данных. Так как оценка параметров основывается на минимизации квадратов ошибки, выбросы (крайние значения) могут оказать непропорциональное влияние на оценки параметров. Расчет доверительных интервалов и различные тесты значимости для коэффициентов основаны на предположении нормально распределенной ошибки. Если ошибка существенно отклоняется от нормального распределения, доверительный интервал может быть слишком широким или слишком узким.
Наиболее подходящая проверка – это нормальный вероятностный график остатков (Q-Q график). В идеале – это прямая диагональная линия. Дугообразная картина отклонений от диагонали указывает, что остатки имеют чрезмерный перекос (то есть, они не симметричны, с большим количеством больших ошибок в одном направлении). S-образная кривая остатков показывает, что остатки имеют чрезмерный эксцесс, т.е. есть или слишком мало или слишком много больших остатков в обоих направлениях (см. раздел 6).
Нарушения нормальности часто возникают либо потому, что (а) распределения y и/или предикторов значительно отклоняются от нормального,
и/или (б) нарушается предположение о линейности. В таких случаях, нелинейные
148

преобразования переменных могут помочь в решении этих проблем. Часто проблема с остатками связана с одним или двумя очень большими выбросами в данных. Такие значения нужно внимательно проанализировать: являются ли они подлинными (т.е. не являются результатом ошибок при вводе данных), объяснимы ли они с медикобиологической точки зрения, могут ли такие наблюдения произойти в будущем, и как они влияют на подгонку модели?
Решение принимается после анализа моделей с выбросами и с исключением выбросов. Возможно, что крайние значения обеспечивают более реалистичную величину ошибки прогноза, и исключать выбросы из данных будет неправильно.
16.8.5. Диагностика выбросов и аномальных наблюдений в регрессии
Выбросы (outliers) в данных – это значения в данных, которые не согласуются с остальными данными. В регрессионной модели как минимум две переменные: предиктор x и зависимая переменная y . Выбросы могут быть как по x , так и по y .
Для регрессии понятие выброса связано с большим остатком, т.е. величиной yi yˆi . Однако, большое абсолютное значение остатка еще не говорит о том, что
точка данных xi , yi влияет на коэффициент регрессии (на связь между x и y ).
Рис. 16–8. Изменения линии регрессии при различном расположении влияющих точек
На рис. 16–8 слева показано, что одно и то же значение y при различных значениях x может влиять и не влиять на оценку коэффициента корреляции (оценку коэффициента βˆ1 ). Точки данных, которые оказывают чрезмерное влияние на оценки коэффициентов регрессии называют влияющими точками (influential points). В первом случае точка, влияющая на изменение оценки коэффициента βˆ1
149
имеет крайние значения как по y , так и по x . Во втором случае точка является влияющей, но не является выбросом ни по y , так и по x . В третьем случае точка является выбросом как по регрессионному остатку, так и по переменной y , однако она не оказывает влияния на βˆ1 . В четвертом – выброс по предиктору x вызвал
изменение в оценке коэффициента βˆ1 , при этом регрессионный остаток у данной
точки не самый большой. Выбросы значений предиктора x , которые потенциально могут влиять на оценки коэффициентов регрессии называют точками сильного воздействия (high leverage points).
Выбросы в данных, включенные в модель с относительно большими значениями остатков могут очень сильно влиять на модель, а именно увеличивать вариации оценок коэффициентов, что может снижать статистическую значимость эффектов.
Причины появления выбросов различны:
1.Человеческие ошибки или ошибки приборов измерения. В этом случае надо попытаться получить правильное значение, если это невозможно, то придется отказаться от этой точки данных.
2.Неадекватность модели. В этом случае именно наличие выбросов будет свидетельством неправильных предположений о связи предикторов и зависимой переменной. Отказ от точки данных, которую посчитали выбросом, может быть катастрофичным.
3.Если исследуемая выборка значений попала в хвост распределения, которое считается распределением с тяжелыми хвостами. Это может означать неправильный или неграмотный дизайн выборки. Также может означать наличие двух или более различных групп с различной вариацией (дисперсией), которые не учитываются в дизайне.
Различные статистические пакеты считают диагностики для изучения остатков, выбросов, влияющих наблюдений. Внимательно читайте руководство пользователя, чтобы понять, что именно считает тот или иной пакет. Поскольку большинство пакетов англоязычные, ниже даны распространенные наименования диагностик на английском языке.
Для выявления влияющих наблюдений используется следующая диагностика: влияющие значения (Leverage Values/Hat Diag). Для i -го наблюдения обозначается как hi , рассчитывается на основе значений предикторов набора
наблюдений.
Математическое описание этой диагностики достаточно сложно. Если в пространстве предикторов (переменная y не участвует) найти центр, то влияние
(leverage) – это расстояние от центра до точки данных, представленной значениями предикторов. Чем больше расстояние, тем более влияющим может быть наблюдение. Второе название Hat Diag связано с матричным представлением предикторов по всем наблюдениям, после определенных преобразований диагональные элементы полученной матрицы и являются стандартизированными расстояниями до центра пространства предикторов. Эта диагностика определяет выбросы в независимых переменных (предикторах) регрессии.
Выбросами считаются наблюдения, для которых значение влияния (leverage) больше, чем 2q N , где q – количество параметров модели (включая и β0 ), N –
N , где q – количество параметров модели (включая и β0 ), N –
количество наблюдений.
150