

5 курс / ОЗИЗО Общественное здоровье и здравоохранение / Статистический_анализ_данных_в_медицинских_исследованиях_в_2_ч_Красько
.pdf6. Основные виды распределений
Цель статистического анализа – сделать некоторые выводы о совокупности (популяции), используя выборку из нее. Большинство методов основано на предположении, что используются случайные выборки. В основе выборочных данных лежит некоторое распределение. Его идентификация по выборочным значениям дает возможность более точного анализа, установления некоторых характеристик выборочной совокупности и пр.
В теории статистических выводов используются величины, рассчитанные по выборке, которые называются статистики. Это, например, выборочное (т.е. рассчитанное по выборке) среднее, выборочная дисперсия и т.п. Часто оказывается возможным найти распределение вероятностей данной статистики, если известно распределение для совокупности, из которой была взята выборка. Распределение вероятностей статистики называется выборочным распределением.
Ремарка: Прежде, чем начать анализ данных, необходимо определить вид распределения переменных исследования.
Рассмотрим в общих чертах некоторые виды распределений.
6.1.Непрерывные распределения
Нормальное (Гауссовское) распределение и его основные свойства
Нормальное распределение играет исключительно важную роль в теории вероятностей и математической статистике.
Считается, что случайная ошибка измерений распределена по закону нормального распределения (“нормально”). В большинстве случаев значения данных будут группироваться вокруг некоторого значения, такого как среднее или медиана. Рассеяние данных (определяется как сумма квадратов расстояний от данных до среднего) называют дисперсией или вариацией. Распределение с большой вариацией будет более разбросано, чем с малой вариацией (Рис. 6–1).
Нормальное распределение является непрерывным распределением, обозначается N μ;σ 2 , где μ – среднее, σ 2 дисперсия. Стандартное нормальное распределение имеет следующие характеристики: μ 0, σ 1. Записывается как
NID 0;1 . |
Случайная величина x , распределенная нормально, может быть |
||||
преобразована к стандартизированной (нормированной) |
случайной величине |
||||
z |
x μ |
|
. Т.е. если есть переменная x ~ N μ;σ 2 , то z x μ |
~ NID 0;1 . |
|
σ |
|||||
|
σ |
|
|||
`
41
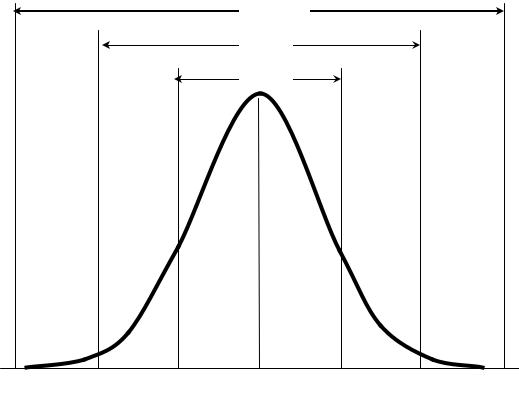
Рис.6–1. Нормальное распределение с различной вариацией
Свойства нормального распределения: Имеет колоколообразную форму. Симметрично относительно среднего. Среднее, медиана и мода равны.
Дисперсия или разброс значений относительно среднего выражается стандартным отклонением.
68% значений попадают в интервал x s . 95% значений попадают в интервал x 2s . 99,7% значений попадают в интервал x 3s .
99,7%
95%
68%
-3 |
-2 |
-1 |
0 |
1 |
2 |
3 |
Среднее
Медиана
Мода
Рис. 6–2. Свойства нормального распределения
Для многих методов статистики исходным является допущение, что случайная переменная распределена по закону нормального распределения. Обоснованием такого допущения часто служит центральная предельная теорема. Утверждение этой теоремы состоит в том, что сумма n независимых случайных переменных распределена приближенно по закону нормального распределения. Фактически, это означает, что мы можем сравнивать средние выборочных распределений, даже если сами распределения отклоняются от нормального. Однако размер выборок может варьироваться в каждом конкретном случае. Иногда хватает 10 наблюдений, иногда нужно более 100.
В медицинских исследованиях количественные данные нечасто распределены нормально.
42

Симметричные распределения
В симметричном распределении среднее, медиана и мода равны между собой. Нормальное распределение симметрично. Однако существуют и другие виды симметричных распределений, отличных от нормального распределения. Даже если распределение выглядит симметричным, необходимо провести оценку соответствия данных определенному виду распределения.
Асимметричные распределения
Если в симметричном распределении среднее, медиана и мода равны между собой, то в ассиметричном эти величины разновелики. Если среднее меньше медианы, а медиана в свою очередь меньше моды, то распределение называют скошенным влево или имеющим отрицательный уклон. Если медиана больше моды, а среднее больше медианы, то распределение скошено вправо или имеет положительный уклон(Рис.6–3).
Среднее |
Среднее |
Медиана |
Медиана |
Мода |
Мода |
Рис. 6–3. Скошенные (ассиметричные) распределения |
|
Ремарка: Если распределение случайной величины мультмодальное (т.е. мода не одна, а несколько, это может быть признаком того, что или не учтен некоторый фактор в исследовании, или (что с неопытным исследователем происходит чаще) исследование не продумано, например, произошло слияние данных по двум подтипам заболевания, которые, возможно, различаются по этому фактору.
Логнормальное распределение
Это распределение часто встречается в медико-биологических исследованиях. Оно имеет скошенную к одному хвосту форму (Рис. 6–4). Логнормальное распределение ограничено нулем и имеет более длинный хвост, чем нормальное. Это распределение связано с нормальным распределением соотношением: если x распределено по закону логнормального распределения, то y ln x распределено
нормально.
43

Рис. 6–4. Логнормальное распределение
В дальнейшем, если используются некоторые модели и тесты, с данными, не отвечающими нормальному распределению, может быть выполнено преобразование, которое их нормализует. Если такого преобразования нельзя найти, то данные “понижаются в шкале”, и к ним относятся как к порядковым данным. Преобразовывать данные не всегда нужно (и не всегда можно). Есть ряд непараметрических тестов (критериев), которые работают с порядковыми данными без преобразования. Если преобразование выполнено, и преобразованные данные нормальны, то все дальнейшие выводы, построенные на этих преобразованных данных, касаются именно их, а не первоначальных.
Таким образом, после проверки на нормальность распределения количественных данных, исследователю становится понятно, вправе ли он использовать параметрические тесты (которые используют параметры распределения при вычислении статистик), или непараметрические, для которых вид распределения не установлен.
Критерии (тесты) проверки данных на нормальность распределения присутствуют в статистических пакетах. Эти критерии также носят название критериев согласия.
6.2.Дискретные распределения
Биномиальное распределение
Биномиальное распределение – это распределение количества “успехов” в последовательности из n независимых случайных экспериментов, таких что вероятность “успеха” в каждом из них равна π .
В медицинских исследованиях предполагается, что биноминальные данные подчиняются закону биноминального распределения. Биномиальное распределение описывают n – число испытуемых в выборке (или число повторений испытания), и π – вероятность наступления события (успешного лечения, неблагоприятного исхода и пр.) каждого испытуемого (или при каждом испытании). Свойства биномиального распределения можно использовать, чтобы сделать выводы относительно пропорций в выборке. Пропорция – предполагается распределенной по закону биноминального распределения.
Биноминальное распределение аппроксимируется нормальным распределением и некоторыми другими при достаточном объеме выборки, что позволяет использовать соответствующие тесты.
44

Распределение Пуассона
Распределение Пуассона моделирует случайную величину, представляющую собой число событий, произошедших за фиксированное время, при условии, что данные события происходят с некоторой фиксированной средней интенсивностью λ и независимо друг от друга. Например, число госпитализаций в день типичная переменная, отвечающая распределению Пуассона.
В выборке такие данные могут быть представлены как количество событий за время наблюдения, или время до момента свершения события.
И в одном, и в другом случае – это распределение Пуассона, однако в первом случае, когда количество событий есть у каждого исследуемого, такие данные могут быть аппроксимированы нормальным распределением, при условии, что время наблюдения одинаково у всех случаев. Если время наблюдения одинаково для всей выборки или не играет роли в исследовании, данные представляются как количество событий – целые числа (например, количество детей у исследуемого, число госпитализируемых за сутки и т.п.).
χ2 распределение
Кважным выборочным распределениям, которые могут быть определены через нормальные случайные переменные, относится распределение χ 2 (хи-
квадрат) распределение. Если z1 ,z2 , ,zk – независимые случайные переменные, распределенные нормально с нулевым средним и единичной дисперсией NID 0;1 , то случайная переменная χk2 z12 z22 zk2 (сумма квадратов случайных величин) подчиняется χ 2 -распределению с k степенями свободы.
Это распределение исключительно важно, поскольку через сумму квадратов определяется выборочная дисперсия; методы анализа таблиц сопряженности
основываются на критериях типа χ 2 .
Распределение Стьюдента
Если z и χ k2 независимые случайные переменные со стандартизированным
нормальным и χ 2 -распределением, то случайная величина t |
|
|
|
z |
|
|
подчиняется |
k |
|
|
|
|
|||
χ 2 |
|
||||||
|
|
|
k |
||||
|
|
|
|
||||
|
|
|
|
k |
|
|
|
t -распределению (распределению Стьюдента) с k степенями свободы. При k распределение переходит в стандартизированное нормальное распределение.
Таким образом, если x |
|
,x |
|
, ,x |
|
случайная выборка из N μ;σ 2 |
|
, то |
t |
x |
μ |
||
1 |
2 |
n |
|
|
|
||||||||
s n |
|||||||||||||
|
|
|
|
|
|
|
|||||||
подчиняется t -распределению с n 1 степенями свободы. |
|
|
|
||||||||||
|
|
|
|
|
|
||||||||
На этом распределении построены критерии типа Стьюдента.
F-распределение |
|
|
|
|
|
|
Если χ u2 и χ v2 |
– независимые случайные переменные |
χ 2 распределения со |
||||
|
|
|
χ |
2 |
u |
|
степенями свободы u |
и v соответственно, то отношение Fu,v |
|
u |
|
починяется F- |
|
χ |
2 |
v |
||||
|
|
|
|
v |
|
|
распределению с u степенями числителя и v степенями знаменателя.
Это распределение играет важную роль в анализе вариаций ANOVA и других методах анализа данных планируемых экспериментов.
Безусловно, есть и другие распределения, которые лежат в основе случайных величин. Но без знания основных свойств вышеприведенных распределений сложно
45
понимать, как “работают” основные статистические параметрические критерии. Непараметрические критерии отличаются от параметрических тем, что не требуют знания распределения случайной величины при их расчете.
Основные аспекты
Свойства распределений и возможности анализа, которые они предоставляют очень активно используются в практическом анализе. Фактически, большая часть рассуждений в статистических критериях и выводах базируется именно на свойствах вышеописанных распределений.
46

7. Предварительный анализ данных
Предварительный анализ данных так иногда называют унивариантым анализом данных. В медицинской литературе наиболее распространено следующие виды унивариантного анализа:
1.Описательное исследование, в котором исследуется одна выборка. Как правило, анализ носит описательный характер. Цель такого анализа – учесть влияние случая в измерениях переменной. Например, описывается серия случаев одного заболевания, рассматриваются демографические и патофизиологические характеристики этих пациентов. Крайне редко используется сам по себе.
2.Второй распространенный вид: выборка описывается для включения в исследование. Например, перед рандомизацией в клиническом исследовании, исследователь может описать общие характеристики всей выборки исследования: средний возраст, процент женщин и мужчин и пр.
Вобоих видах унивариантного анализа интерес представляют описательные характеристики, а не значимость статистических тестов. Также часто унивариантный анализ может использоваться как вспомогательный инструмент при анализе отдельной переменной, для того, чтобы понять, по какому закону она распределена, как она себя ведет в исследовании, для последующего выбора соответствующего теста.
Прежде чем начать анализ данных, необходимо определить, какие типы данных у переменных исследования.
Для каждого столбца вашей таблицы (переменной исследования, фактора) необходимо найти характеристики, которые помогут взглянуть на ваши данные в целом. Значения переменной рассматриваются как некоторое эмпирическое распределение. Очень желательно определить закон распределения этой величины, описать это распределение некоторыми характеристиками.
7.1. Основные характеристики данных в предварительном анализе
Предварительный анализ часто называют описательными, дескриптивными статистиками данных (descriptive statistics).
Переменная в исследовании характеризуется набором своих значений для каждого случая. Для того, чтобы работать с набором данных целиком – нужны некоторые характеристики этого набора, которые в обобщенной форме отражали все значения этого набора. Этими характеристиками и являются дескриптивные статистики.
7.1.1. Количественные переменные
Для характеристики количественных переменных сначала нужно определить, по какому закону они распределены. Критерии, которые используются для определения закона распределения, носят общее название критериев согласия. Количественные переменные в исследовании часто проверяются на "нормальность" распределения.
Ремарка: Проверка предположения о характере распределения переменной очень часто нужна не сама по себе, а как вспомогательная часть анализа при проверке гипотез. Некоторые критерии основываются на предположениях о характере распределения и верны только тогда, когда предположения выполняются.
47

Есть приблизительный быстрый способ оценки того, можно ли использовать нормальное распределение для обработки количественных данных. Рассчитываются основные статистики – выборочное среднее, выборочное среднеквадратическое отклонение, медиана, мода. Если мода, медиана и среднее расположены далеко друг от друга, то маловероятно, что данные распределены нормально. Если мода не одна, то возможно, что дизайн исследования построен неправильно, возможно наблюдения взяты из двух и более различных распределений.
Рассчитывается коэффициент вариации по выборке: CV s x , где s –
x , где s –
выборочное среднеквадратическое отклонение, x – выборочное среднее. Если CV 1,0, то данные нельзя обрабатывать, как нормально распределенные данные.
Однако, если CV 1,0 нужны дальнейшие исследования о нормальности данных.
Для проверки гипотезы о нормальности распределения наиболее часто используются тест Шапиро-Уилка (если размер выборки менее 50, n 50 ; в некоторых статистических пакетах тест рассчитывается при n 5000 ), тест Лиллиефорса, тест Шапиро-Франсиа и др. Нулевая гипотеза, которая выдвигается при проверке – данные согласуются с законом нормального распределения, альтернативная – данные не согласуются с законом нормального распределения. Если результат применения критерия имеет значимость p α , то нулевая гипотеза
не отвергается, вероятно, что данные распределены нормально.
Проверка на нормальность нужна часто не сама по себе, а как предположение, лежащее в основе статистических тестов. Однако, прежде чем окончательно выбрать подходящий тест (критерий) для вашего исследования, необходима проверка на наличие выбросов.
Выбросы – это аномальные значения в выборочных наблюдениях, которые отличаются от основной части данных и несовместимы с остальными данными.
Чтобы приблизительно оценить выбросы, используются графические представления данных: гистограмма, “ящик с усами”, Q-Q-график и др. Графические представления – хороший инструмент для визуального анализа данных (см. раздел
7.2).
Один из самых простых способов обнаружить выброс в значениях одной переменной – это рассчитать интеквартильный размах IR (см.6.1.4), умножить его на 1,5. Далее определить границы, нижнюю как L Q25 1,5 IR , верхнюю как
U Q75 1,5 IR. Точки, лежащие вне этого диапазона, могут рассматриваться как выбросы в данных.
Например: есть данные: 2, 8, 10, 11, 14.
Q25 8,Q75 11, IR 3, L 8 1,5 3 3,5, L 11 1,5 3 15,5.
Сравнивая имеющиеся данные с границами, получаем, что значение 2 является выбросом.
Выбросом могут считаться данные, которые отклоняются более чем на два стандартных отклонения от среднего выборки1; не согласуются с поведением остальных данных в выборке.
Кроме того, для анализа выбросов существуют статистические тесты и процедуры, которые подскажут вам, какие значения переменной являются
1 Существует эмпиричесское правило “трех сигм”. σ – стандартное отколенение. Величина, отстоящая от среднего более чем на 3σ считается крайне маловероятной (см Раздел 6.1).
48
выбросами. Анализируются обычно крайние значения упорядоченного набора значений переменной (крайне малые и крайне большие).
Ни один из тестов не подскажет вам, что делать с такими значениями. Если значение данных является выбросом, то исследователь может:
–скорректировать точку данных: если возможно, перепроверить значение по исходному оригиналу (журналу анализов, карточке пациента и др., убедиться, если использовался некоторый прибор для измерений, что он исправен; иногда, если сохранился материал, анализ повторяют);
–исключить из анализа эту точку, однако исключение выброса из данных должно быть сделано с особой осторожностью, если выброс исключается из данных, весь статистический анализ данных должен быть применен к полным и урезанным данным так, чтобы оценить эффект от исключенных наблюдений. Такое исключение должно быть задокументировано;
–использовать эту точку данных в анализе.
По отношению к количественной переменной вы должны убедиться, что она подчиняется или не подчиняется закону нормального распределения, чтобы в дальнейшем использовать соответствующие критерии. Для данных, которые могут принимать только положительные значения и не подчиняются закону нормального распределения – может быть сделана проверка на логнормальное распределение. Данные преобразовываются по формуле y ln x , далее выполняется
предварительный анализ на нормальность.
При записи результатов предварительного анализа нормально распределенные данные чаще всего характеризуют размером выборки, выборочными средним и среднеквадратичным отклонением или дисперсией, иногда среднеквадратичной ошибкой среднего; данные, которые не распределены нормально – размером выборки, медианой, минимальным и максимальным значением, 25% и 75% перцентилями (квартилями).
7.1.2. Номинальные и категориальные переменные
Характеристика номинальных и категориальных переменных в исследовании отличается от характеристики количественных переменных.
Для расчета их характеристик нужно подсчитать количество появлений каждой категории в столбце, которым представлена такая переменная. Обычно вычисляется процент каждой категории представленных данных от общего количества наблюдений (размера выборки). Выполняются также расчеты доверительных интервалов, когда это необходимо для более углубленного описания данных.
7.1.3. Характеристика времен наблюдения
Если речь идет об обработке наблюдений, которые связаны со временем наблюдения до наступления события (или до окончания исследования), то время наблюдений характеризуют медианой и размахом (сами по себе времена наблюдения – количественная переменная, не распределена нормально). Например: медиана наблюдений составила 35(2…68) дней, цифры в скобках означают минимальное и максимальное время наблюдений в вашей выборке. Обычно такие данные характерны в открытых когортных исследованиях. Для анализа времен наблюдения и связанных с ними событий используются методы с общим названием “анализ выживаемости” (см. раздел 18).
49

7.1.4. Точечные оценки и доверительные интервалы
Точечные оценки и доверительные интервалы – это распространенный прием в статистических исследованиях, который позволяет оценить параметры распределения случайной величины. Этими параметрами можно описать переменную в исследовании. При работе с выборкой по некоторой переменной исследования мы характеризуем выборку этими параметрами на основе точечных оценок параметров распределения, которому подчиняется данная переменная (случайная величина). Точечная оценка параметра распределения – это некоторое число, которое интегрально характеризует весь набор значений переменной в исследовании (выборочные среднее, медиана, дисперсия и др.). Доверительный интервал – это интервальная оценка параметра распределения. 95% доверительный интервал означает, что если исследование повторить много раз, то параметр будет лежать в интервале в 95% случаев. Чаще всего в доказательной медицине используется 95% двусторонний доверительный интервал.
Ширина доверительного интервала зависит от дисперсии (вариации, изменчивости) выборки. Расчет доверительного интервала зависит от закона распределения случайной величины.
Ремарка: Точечная оценка – это одна величина, значение которой вычисляется на основе данных выборки. Интервальная оценка – это два значения (нижнее и верхнее значения интервала), которые также вычисляются на основе выборочных данных. Для некоторых параметров распределений существует много вариантов расчетов их доверительных интервалов. В данном пособии приводятся наиболее простые формулы.
Среднее значение
Точечная оценка. Используется для количественных переменных, распределенных по закону нормального распределения. Является мерой положения.
Выборочное среднее значение (т.е. оценка среднего по имеющейся выборке) рассчитывается как:
1 n
x n i 1 xi
где n – численность выборки,
xi , i 1,2, ,n – значения переменной в выборке по каждому случаю.
Доверительный интервал для среднего
Интервальная оценка. Нижняя (индекс L – lower) и верхняя (индекс U – upper) границы доверительного интервала определяются как:
xL x tγ ; n 1 |
s |
|
; xU x tγ ; n 1 |
|
s |
|
, |
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
||||
|
|
|
|
|
|||||||||
|
|
|
n |
|
n |
|
|
|
|||||
где x – выборочное среднее; |
|
|
|
|
|
|
|
||||||
s – выборочное среднеквадратичное отклонение; |
|
|
|
||||||||||
tγ ; n 1 – значение -квантиля распределения Стьюдента с |
n 1 степенями |
||||||||||||
свободы, γ 1 α |
2 |
для двустороннего интервала, т.е. |
для α 0,05 |
γ 0,975, для |
|||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
одностороннего интервала γ 1 α ; |
|
|
|
|
|
|
|
||||||
n – численность выборки. |
|
|
|
|
|
|
|
||||||
|
|
||||||||||||
Ремарка: Фактически, этот интервал покрывает |
1 α % распределения исследуемого параметра |
||||||||||||
выборки. Для среднего – это распределение среднего, а не выборки, на основе которой рассчитано среднее.
50