

Экзамен,чтоб тебя
.pdf1.Определение понятия архитектура и организация вычислительных систем
Вычислительная машина – комплекс технических и программных средств, предназначенный для автоматизации подготовки и решения задач пользователей.
Вычислительная система – совокупность взаимосвязанных и взаимодействующих процессоров или вычислительных машин, периферийного оборудования и программного обеспечения, предназначенная для подготовки и решения задач пользователя.
Основной отличительной чертой вычислительных систем является наличие в них средств, реализующих параллельную обработку за счет построения параллельных ветвей в вычислениях.
Под архитектурой вычислительных машин, как правило, понимается логическое построение ВМ, то есть то, какой представляется машина программисту, разрабатывающему программу на машинноориентированном языке. Это определение архитектуры в “узком” смысле.
Оно охватывает следующее:
перечень и формат команд,
формы представления данных,
механизмы ввода-вывода,
способы адресации памяти,
назначение и состав регистров общего назначения, а также других адресуемых регистров.
Однако при таком подходе из рассмотрения выпадают такие важные вопросы как состав устройств, сложность процессора, емкость памяти, тактовая частота. Круг этих вопросов принято определять понятием организация или
структурная организация.
Более часто применительно к ВМ используется понятие архитектуры в “широком“ смысле или просто архитектуры,
объединяющее в себе как архитектуру в “узком” смысле, так и организацию ВМ.
Термин “архитектура” применительно к вычислительным системам дополнительно включает в себя вопросы выделения составляющих ВС (иерархии ВС), распределения функций между ними и определение взаимодействия между составляющими.
2.Компьютерные сети. Основные понятия
Компьютерной сетью называют систему обработки данных, состоящую из распределенных по некоторой территории ЭВМ, комплексов и других средств вычислительный техники ,связанную между собой каналами передачи данных.
Главное назначение компьютерных вычислительных сетей - упростить и ускорить процесс взаимодействия между конечными пользователями, т.е. клиентами сети, а так же организация доступа пользователей к общим сетевым ресурсам.
Компьютерные сети бывают различных видов: например, по их масштабу и территории они подразделяются на локальные(LAN) и глобальные(WAN), по уровню организации: одноранговые и на основе сервера, по скорости передачи информации на низко-, средне- и высокоскоростные, по типу соединения: на коаксиальные, на витой паре,
оптоволоконные, с передачей информации по радиоканалу и в инфракрасном диапазоне, по топологии сети т.е. структуре связей между ее основными функциональными элементами: звездная, шинная, кольцевая.
Функции компьютеров, входящих в сеть:
-Организация доступа к сети,
-Управление передачей информации,
-Предоставление вычислительных ресурсов и услуг абонентам сети.
Любая компьютерная сеть характеризуется: топологией, протоколами, интерфейсами, сетевыми техническими и программными средствами, используемыми в этой сети:
-Сетевые технические средства представляют собой различные электронные устройства, обеспечивающие объединение компьютеров в вычислительную сеть (кабеля, коммутаторы, концентраторы(Hab), серверы, маршрутизаторы);
-Протокол-это набор определенных правил взаимодействия и обмена информации между компьютерами и другими функциональными элементами данной сети;
-Сетевые программные средства обеспечивают корректную работу сети, осуществляют программное управление работой сети и интерфейс с конечным пользователем (сетевая операционная система, программное обеспечение управления сетью);
-Интерфейс – это средства сопряжения функциональных элементов сети. Интерфейсы разделяются на аппаратные и программные.
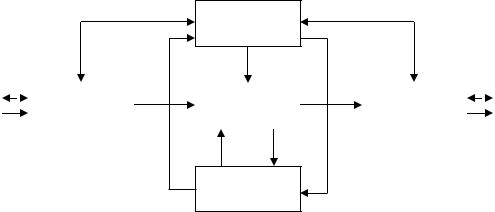
3. Фон-неймановская архитектура
Для современных ВМ исходной является концепция Дж. фон Неймана, согласно которой определяется автономно работающая универсальная машина, объединяющая устройство управления, двоичное арифметическое устройство,
память, устройства ввода и вывода.
Устройство
управления
Устройство |
|
Арифметико- |
|
Устройство |
ввода |
|
логическое |
|
вывода |
|
|
|
|
|
Память
Вычисления осуществляются последовательно под централизованным управлением от команд. Набор команд составляет машинный язык низкого уровня реализации простых операций над элементарными операндами. Память достаточно большой емкости, хранящая как команды, так и данные, состоит из ячеек фиксированного размера, линейно организованных в линейном пространстве.
Концепция неймановской архитектуры предусматривает единственное арифметическое устройство и одну глобальную основную память, что обуславливает последовательную обработку и тем самым ограничивает скорость выполнения вычислений. Это узкое место последовательной неймановской архитектуры призваны устранить параллельные архитектуры. Для этих архитектур во всех случаях независимо от формы реализации обработка распараллеливается по нескольким процессорам и осуществляется с совмещением по времени.
4. Классификация вычислительных систем по Флинну.
Общепринятой является классическая систематика Флинна.
Классификация базируется на понятии потока( последовательность команд или данных, обрабатываемая процессором).
На основе числа потоков команд и потоков данных Флинн выделяет четыре класса архитектур: SISD,MISD,SIMD,MIMD.
SISD (single instruction stream / single data stream) - одиночный поток команд и одиночный поток данных. К этому классу относятся классические последовательные машины или, иначе, машины фон-неймановского типа. В таких машинах есть только один поток команд, все команды обрабатываются последовательно друг за другом и каждая команда инициирует одну операцию с одним потоком данных.
Увеличение скорости вычислений в системах достигается следующим образом.
1.Совмещением во времени различных этапов решения различных задач, при котором в системе одновременно работают различные устройства: ввода, вывода и собственно обработки информации.
2.Введением конвейера команд.
3.Использованием конвейера арифметических и логических операций, в котором команды разбиваются на
некоторое число микроопераций, образуя, таким образом, несколько потоков микрокоманд.
MISD (multiple instruction stream / single data stream) - множественный поток команд и одиночный поток данных.
Определение подразумевает наличие в архитектуре многих процессоров, обрабатывающих один и тот же поток данных.
Однако не существует такого класса задач, в которых одна и та же последовательность данных подвергалась бы обработке по нескольким разным программам. По этой причине в чистом виде такая схема до настоящего времени не реализована.
SIMD (single instruction stream / multiple data stream) - одиночный поток команд и множественный поток данных. В
архитектурах подобного рода сохраняется один поток команд, включающий векторные команды. Это позволяет выполнять одну арифметическую операцию сразу над многими данными - элементами вектора. Обработка элементов вектора может производиться либо процессорной матрицей, либо с помощью конвейера.
MIMD (multiple instruction stream / multiple data stream) - множественный поток команд и множественный поток данных.
Этот класс предполагает, что в вычислительной системе есть несколько устройств обработки команд, объединенных в единый комплекс и работающих каждое со своим потоком команд и данных.
Типичные представители каждого из этих классов.
В SISD входят однопроцессорные последовательные компьютеры типа VAX 11/780. Векторно-конвейерные машины
(если рассматривать вектор как одно неделимое данное для соответствующей команды): CRAY-1, CYBER 205, машины семейства FACOM VP и многие другие.
Представителями класса SIMD считаются матрицы процессоров: ILLIAC IV, ICL DAP, Goodyear Aerospace MPP, Connection Machine 1. В этот же класс можно включить классические процессорные матрицы и векторно-конвейерные машины, например, CRAY-1.
Класс MIMD чрезвычайно широк, поскольку включает в себя всевозможные мультипроцессорные системы: Cm*, C.mmp, Denelcor HEP, BBN Butterfly, Intel Paragon, CRAY T3D и многие другие.
Такой классификации присущи некоторые недостатки. В частности, некоторые архитектуры, например dataflow и
векторно-конвейерные машины, четко не вписываются в данную классификацию.
Другой недостаток - это чрезмерная заполненность класса MIMD. Недостатком можно считать также наличие пустого класса (MISD).
5.Общие понятия и определения, структурная схема микропроцессора.
Микропроцессор – функционально законченное устройство обработки информации, управляемое хранимой в памяти программой. Появление микропроцессоров (МП) стало возможным благодаря развитию интегральной электронике. Это позволило перейти от схем малой и средней степени интеграции к большим и сверхбольшим интегральным микросхемам (БИС и СБИС).
По логическим функциям и структуре МП напоминает упрощенный вариант процессора обычных ЭВМ. Описание структурной схемы микропроцессора.
В состав МП входят АЛУ, устройство управление и блок внутренних регистров.
АЛУ состоит из двоичного сумматора со схемами ускоренного переноса, сдвигающего регистры и регистров для временного хранения операндов. Обычно это устройство выполняет по командам несколько простейших операций: сложение, вычитание, сдвиг, пересылку, логическое сложение (ИЛИ), логическое умножение (И), сложение по модулю 2.
УУ управляет работой АЛУ и внутренних регистров в процессе выполнения команды. Согласно коду операций, содержащемуся в команде, оно формирует внутренние сигналы управления блоками МП. Адресная часть команды совместно с сигналами управления используется для считывания данных из определенной ячейки памяти или для записи данных в ячейку. По сигналам УУ осуществляется выборка каждой новой, очередной команды.
Блок внутренних регистров БВР, расширяющий возможности АЛУ, служит внутренней памятью МП и используется для временного хранения данных и команд. Он также выполняет некоторые процедуры обработки информации.
6. Иерархия памяти. Организация кэш-памяти. Принципы организации основной памяти в современных
компьютерах
В основе реализации иерархии памяти современных компьютеров лежат два принципа: принцип локальности обращений и соотношение стоимость/производительность. Иерархия памяти современных компьютеров строится на нескольких уровнях, причем более высокий уровень меньше по объему, быстрее и имеет большую стоимость в пересчете на байт, чем более низкий уровень. Минимальная единица информации, которая может либо присутствовать, либо отсутствовать в двухуровневой иерархии, называется блоком. Размер блока может быть либо фиксированным, либо переменным. Если этот размер зафиксирован, то объем памяти является кратным размеру блока.
Успешное или неуспешное обращение к более высокому уровню называются соответственно попаданием (hit) или промахом (miss). Попадание - есть обращение к объекту в памяти, который найден на более высоком уровне, в то время как промах означает, что он не найден на этом уровне. Доля попаданий (hit rate) или коэффициент попаданий (hit ratio) есть доля обращений, найденных на более высоком уровне. Иногда она представляется процентами. Доля промахов (miss rate) есть доля обращений, которые не найдены на более высоком уровне.
Поскольку повышение производительности является главной причиной появления иерархии памяти, частота попаданий и промахов является важной характеристикой.
Принципы размещения блоков в кэш-памяти определяют три основных типа их организации:
Если каждый блок основной памяти имеет только одно фиксированное место, на котором он может появиться в кэш-памяти, то такая кэш-память называется кэшем с прямым отображением. Это наиболее простая организация кэш-памяти, при которой для отображения адресов блоков основной памяти на адреса кэш-памяти просто используются младшие разряды адреса блока. Т.о., все блоки основной памяти, имеющие одинаковые младшие разряды в своем адресе, попадают в один блок кэш-памяти, т.е.
(адрес блока кэш-памяти) =
(адрес блока основной памяти) mod (число блоков в кэш-памяти)
Если некоторый блок основной памяти может располагаться на любом месте кэш-памяти, то кэш называется полностью ассоциативным.
Если некоторый блок основной памяти может располагаться на ограниченном множестве мест в кэш-памяти, то кэш называется множественно-ассоциативным. Обычно множество представляет собой группу из двух или большего числа блоков в кэше. Если множество состоит из n блоков, то такое размещение называется множественно-ассоциативным с n каналами. Для размещения блока необходимо определить множество. Множество определяется младшими разрядами адреса блока памяти (индексом):
(адрес множества кэш-памяти) =
(адрес блока основной памяти) mod (число множеств в кэш-памяти)
Когда выполняется запись в кэш-память, имеются две базовые возможности:
сквозная запись - информация записывается в два места: в блок кэш-памяти и в блок более низкого уровня памяти.
запись с обратным копированием - информация записывается только в блок кэш-памяти. Модифицированный блок кэш-памяти записывается в основную память только когда он замещается. Для сокращения частоты копирования блоков при замещении обычно с каждым блоком кэш-памяти связывается так называемый бит модификации (dirty bit). Этот бит состояния показывает был ли модифицирован блок, находящийся в кэшпамяти. Если он не модифицировался, то обратное копирование отменяется, поскольку более низкий уровень содержит ту же самую информацию, что и кэш-память.
Формула для среднего времени доступа к памяти в системах с кэш-памятью выглядит следующим образом: Среднее время доступа = Время обращения при попадании + Доля промахов x Потери при промахе

7. Конвейерная организация. Что такое конвейерная обработка. Простейшая организация конвейера и оценка его производительности. Примеры
Конвейеризация (или конвейерная обработка) в общем случае основана на разделении подлежащей исполнению функции на более мелкие части, называемые ступенями, и выделении для каждой из них отдельного блока аппаратуры. Так обработку любой машинной команды можно разделить на несколько этапов (несколько ступеней), организовав передачу данных от одного этапа к следующему. Производительность при этом возрастает благодаря тому, что одновременно на различных ступенях конвейера выполняются несколько команд.
Простейшая организация конвейера:
1.Выборка команды (чтение очередной команды из памяти и занесение ее в регистр команды)
2.Декодирование команды (определение кода операции и способов адресации операндов)
3.Вычисление адресов (вычисление адреса операнда)
4.Выборка операндов (извлечение операндов из памяти. Эта операция не нужна для операндов, находящихся в регистрах)
5.Исполнение команды (непосредственное выполнение команды)
6.Запись результата
Конвейеризация увеличивает пропускную способность процессора (количество команд, завершающихся в единицу времени), но она не сокращает время выполнения отдельной команды.

8. Методы адресации, Типы команд и типы данных
В машинах с регистрами общего назначения метод (или режим) адресации объектов, с которыми манипулирует команда,
может задавать константу, регистр или ячейку памяти. Для обращения к ячейке памяти процессор прежде всего должен вычислить действительный или эффективный адрес памяти, который определяется заданным в команде методом адресации. Адресация непосредственных данных и литеральных констант обычно рассматривается как один из методов адресации памяти.
Использование сложных методов адресации позволяет существенно сократить количество команд в программе, но при этом значительно увеличивается сложность аппаратуры.
Метод адресации |
|
Пример |
|
Смысл команды |
|
команды |
|
метода Использование |
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
Регистровая |
|
Add R4,R3 |
|
R4(R4+R5 Требуемое значение в регистре |
|
|
|
|
|
|
|
|
|
|
Непосредственная или литеральная |
|
Add R4,#3 |
|
R4(R4+3 Для задания констант |
|
|
|
|
|
|
|
|
|
|
Базовая со смещением |
|
Add R4,100(R1) |
|
R4(R4+M[100+R1] Для обращения к |
|
|
локальным переменным |
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Косвенная регистровая |
|
Add R4,(R1) |
|
R4(R4+M[R1] Для обращения по указателю или |
|
|
вычисленному адресу |
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Индексная |
|
Add R3,(R1+R2) |
|
R3(R3+M[R1+R2] Иногда полезна при работе с |
|
|
массивами: R1 - база, R3 - индекс |
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Прямая или |
|
Add R1,(1000) |
|
R1(R1+M[1000] Иногда полезна для обращения к |
абсолютная |
|
|
статическим данным |
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
Косвенная |
|
Add R1,@(R3) |
|
R1(R1+M[M[R3]] Если R3-адрес указателя p, то |
|
|
выбирается значение по этому указателю |
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
R1(R1+M[R2] |
Автоинкрементная |
|
Add R1,(R2)+ |
|
R2(R2+d Полезна для прохода в цикле по массиву с |
|
|
шагом: R2 - начало массива |
||
|
|
|
|
|
|
|
|
|
В каждом цикле R2 получает приращение d |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
R2(R2-d |
Автодекрементная |
|
Add R1,(R2)- |
|
R1(R1+M[R2] Аналогична предыдущей |
|
|
|
|
Обе могут использоваться для реализации стека |
|
|
|
|
|
Базовая индексная со смещением и |
|
Add |
масштабированием |
|
R1,100(R2)[R3] |
|
|
|
R1(
R1+M[100]+R2+R3*d Для индексации массивов
|
|
Типы команд |
|
|
Команды традиционного машинного уровня можно разделить на несколько типов |
|
|||
|
|
|
|
|
Тип операции |
|
Примеры |
|
|
|
|
|
|
|
|
|
|
|
|
Арифметические и |
|
Целочисленные арифметические и логические операции: сложение, вычитание, логическое |
|
|
логические |
|
сложение, логическое умножение и т.д. |
|
|
|
|
|
|
|
|
|
|
|
|
Пересылки данных |
|
Операции загрузки/записи |
|
|
|
|
|
|
|
|
|
|
|
|
Управление потоком |
|
Безусловные и условные переходы, вызовы процедур и возвраты |
|
|
команд |
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Системные операции |
|
Системные вызовы, команды управления виртуальной памятью и т.д. |
|
|
|
|
|
|
|
|
|
|
|
|
Операции с плавающей |
|
Операции сложения, вычитания, умножения и деления над вещественными числами |
|
|
точкой |
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|

|
|
|
Десятичные операции |
|
Десятичное сложение, умножение, преобразование форматов и т.д. |
|
|
|
|
|
|
Операции над строками |
|
Пересылки, сравнения и поиск строк |
|
|
|
|
|
|
Команды управления потоком команд Можно выделить четыре основных типа команд для управления потоком команд: условные переходы, безусловные
переходы, вызовы процедур и возвраты из процедур. Для команд перехода адрес перехода должен быть всегда заранее известным. Наиболее простой способ определения адреса перехода заключается в указании его положения относительно текущего значения счетчика команд (с помощью смещения в команде), и такие переходы называются переходами относительно счетчика команд. Реализация возвратов и переходов по косвенному адресу, в которых адрес не известен во время компиляции программы, требует методов адресации, отличных от адресации относительно счетчика команд. В
этом случае адрес перехода должен определяться динамически во время работы программы. Наиболее простой способ заключается в указании регистра для хранения адреса возврата, либо для перехода может разрешаться любой метод адресации для вычисления адреса перехода.
9.Классы конфликтов возникающих в конвейерах и способы их устранения
Существуют три класса конфликтов:
1.Структурные конфликты, которые возникают из-за конфликтов по ресурсам, когда аппаратные средства не могут поддерживать все возможные комбинации команд в режиме одновременного выполнения с совмещением Чтобы разрешить эту ситуацию, можно просто приостановить конвейер на один такт, когда происходит обращение к памяти за данными. Подобная приостановка часто называются "конвейерным пузырем" (pipeline bubble) или просто пузырем, поскольку пузырь проходит по конвейеру, занимая место, но не выполняя никакой полезной работы.
2.Конфликты по данным, возникающие в случае, когда выполнение одной команды зависит от результата выполнения предыдущей команды. Проблема может быть разрешена с помощью достаточно простой аппаратной техники, которая называется пересылкой или продвижением данных (data forwarding), обходом
(data bypassing), иногда закороткой (short-circuiting). Результат операции АЛУ с его выходного регистра всегда снова подается назад на входы АЛУ. Если аппаратура обнаруживает, что предыдущая операция АЛУ записывает результат в регистр, соответствующий источнику операнда для следующей операции АЛУ, то логические схемы управления выбирают в качестве входа для АЛУ результат, поступающий по цепи "обхода",
а не значение, прочитанное из регистрового файла. Эта техника "обходов" может быть обобщена для того,
чтобы включить передачу результата прямо в то функциональное устройство, которое в нем нуждается:
результат с выхода одного устройства "пересылается" на вход другого, а не с выхода некоторого устройства только на его вход.
Известны три возможных конфликта по данным в зависимости от порядка операций чтения и записи.
Рассмотрим две команды i и j, при этом i предшествует j. Возможны следующие конфликты:
RAW (чтение после записи) - j пытается прочитать операнд-источник данных прежде, чем i туда запишет. Таким образом, j может некорректно получить старое значение. Это наиболее общий тип конфликтов, способ их преодолениямеханизм «обходов»
WAR (запись после чтения) - j пытается записать результат в приемник прежде, чем он считывается оттуда командой i, так что i может некорректно получить новое значение.
WAW (запись после записи) - j пытается записать операнд прежде, чем будет записан результат команды i, т.е.
записи заканчиваются в неверном порядке, оставляя в приемнике значение, записанное командой i, а не j. Этот тип конфликтов присутствует только в конвейерах, которые выполняют запись со многих ступеней (или позволяют команде выполняться даже в случае, когда предыдущая приостановлена).
3.Конфликты по управлению, которые возникают при конвейеризации команд переходов и других команд,
которые изменяют значение счетчика команд.
Конфликты в конвейере приводят к необходимости приостановки выполнения команд (pipeline stall).