

из электронной библиотеки / 93525013187900.pdf
.pdfсистематизацию информации и т.д. Попробуйте оценить, где больше информации: в формуле Энштейна E=mc2, лежащей в основе физики водородной бомбы, в картине Айвазовского “Девятый вал” или в ежедневной телевизионной передаче “Новости”.
Видимо, проще всего оценить количество информации по тому, сколько необходимо места для ее хранения, выбрав какой-нибудь единый способ представления и хранения информации.
Определить понятие «количество информации» довольно сложно. В решении этой проблемы существуют два основных подхода. Исторически они возникли почти одновременно. В конце 40-х годов XX века один из основоположников кибернетики американский математик Клод Шеннон развил вероятностный подход к измерению количества информации, а работы по созданию ЭВМ привели к «объемному» подходу.
Вероятностный подход Введем в рассмотрение численную величину, измеряющую неопределенность —
энтропию (обозначим ее H). Величины N и H связаны между собой некоторой
функциональной зависимостью: |
|
H = f(N), |
(1.1) |
а сама функция f является возрастающей, неотрицательной и определенной (в рассматриваемом нами примере) для N = 1, 2, … 6.
Следующим важным моментом является определение вида функции f в формуле (1.1). Если варьировать число граней N и число бросаний кости (обозначим эту величину через M), то общее число исходов (векторов длины M, состоящих из знаков 1, 2, …, N) будет равно N в степени М:
X = NМ . |
(1.3) |
Так, в случае двух бросаний кости с шестью гранями имеем: X = 62 = 36. Фактически каждый исход X есть некоторая пара (X1, X2), где X1 и X2 — соответственно исходы первого и второго бросаний (общее число таких пар — X).
H = log2 N. — формула Хартли.
Важным при введение какой-либо величины является вопрос о том, что принимать за единицу ее измерения. Очевидно, H будет равно единице при N = 2. Иначе говоря, в качестве единицы принимается количество информации, связанное с проведением опыта, состоящего в получении одного из двух равновероятных исходов (примером такого опыта может служить бросание монеты при котором возможны два исхода: “орел”, “решка”). Такая единица количества информации называется “бит”.
Объемный подход В двоичной системе счисления знаки 0 и 1 будем называть битами (от английского
выражения Binary digiTs — двоичные цифры). Отметим, что создатели компьютеров отдают предпочтение именно двоичной системе счисления потому, что в техническом устройстве наиболее просто реализовать два противоположных физических состояния:
некоторый физический элемент, имеющий два различных состояния: намагниченность в двух противоположных направлениях, прибор, пропускающий или нет электрический ток, конденсатор, заряженный или незаряженный и т.п. В компьютере бит является наименьшей возможной единицей информации. Объем информации, записанной двоичными знаками в памяти компьютера или на внешнем носителе информации, подсчитывается просто по количеству требуемых для такой записи двоичных символов. При этом, в частности, невозможно нецелое число битов (в отличие от вероятностного подхода).
Для удобства использования введены и более крупные, чем бит, единицы количества информации. Так, двоичное слово из восьми знаков содержит один байт
51
информации. 1024 байта образуют килобайт (Кбайт), 1024 килобайта — мегабайт (Мбайт), а 1024 мегабайта — гигабайт (Гбайт).
Между вероятностным и объемным количеством информации соотношение неоднозначное. Далеко не всякий текст, записанный двоичными символами, допускает измерение объема информации в кибернетическом смысле, но заведомо допускает его в объемном. Далее, если некоторое сообщение допускают измеримость количества информации в обоих смыслах, то это количество не обязательно совпадает, при этом кибернетическое количество информации не может быть больше объемного.
При всем многообразии подходов к определению понятия информации, с позиций измерения информации нас интересуют два из них: определение К. Шеннона, применяемое в математической теории информации, и определение А. Н. Колмогорова, применяемое в отраслях информатики, связанных с использованием компьютеров
(computer science).
В содержательном подходе возможна качественная оценка информации: новая, срочная, важная и т.д. Согласно Шеннону, информативность сообщения характеризуется содержащейся в нем полезной информацией - той частью сообщения, которая снимает полностью или уменьшает неопределенность какой-либо ситуации. Неопределенность некоторого события - это количество возможных исходов данного события. Так, например, неопределенность погоды на завтра обычно заключается в диапазоне температуры воздуха и возможности выпадения осадков.
Содержательный подход часто называют субъективным, так как разные люди (субъекты) информацию об одном и том же предмете оценивают по-разному. Но если число исходов не зависит от суждений людей (случай бросания кубика или монеты), то информация о наступлении одного из возможных исходов является объективной.
Алфавитный подход основан на том, что всякое сообщение можно закодировать с помощью конечной последовательности символов некоторого алфавита. С позиций computer science носителями информации являются любые последовательности символов, которые хранятся, передаются и обрабатываются с помощью компьютера. Согласно Колмогорову, информативность последовательности символов не зависит от содержания сообщения, а определяется минимально необходимым количеством символов для ее кодирования. Алфавитный подход является объективным, т.е. он не зависит от субъекта, воспринимающего сообщение. Смысл сообщения учитывается на этапе выбора алфавита кодирования либо не учитывается вообще. На первый взгляд определения Шеннона и Колмогорова кажутся разными, тем не менее, они хорошо согласуются при выборе единиц измерения.
Единицы измерения информации
Решая различные задачи, человек вынужден использовать информацию об окружающем нас мире. И чем более полно и подробно человеком изучены те или иные явления, тем подчас проще найти ответ на поставленный вопрос. Так, например, знание законов физики позволяет создавать сложные приборы, а для того, чтобы перевести текст на иностранный язык, нужно знать грамматические правила и помнить много слов.
Часто приходится слышать, что сообщение или несет мало информации или, наоборот, содержит исчерпывающую информацию. При этом разные люди, получившие одно и то же сообщение (например, прочитав статью в газете), по-разному оценивают количество информации, содержащейся в нем. Это происходит оттого, что знания людей об этих событиях (явлениях) до получения сообщения были различными. Поэтому те, кто знал об этом мало, сочтут, что получили много информации, те же, кто знал больше, чем написано в статье, скажут, что информации не получили вовсе. Количество информации в
52
сообщении, таким образом, зависит от того, насколько ново это сообщение для получателя.
Однако иногда возникает ситуация, когда людям сообщают много новых для них сведений (например, на лекции), а информации при этом они практически не получают (в этом нетрудно убедиться во время опроса или контрольной работы). Происходит это оттого, что сама тема в данный момент слушателям не представляется интересной.
Итак, количество информации зависит от новизны сведений об интересном для получателя информации явлении. Иными словами, неопределенность (т.е. неполнота знания) по интересующему нас вопросу с получением информации уменьшается. Если в результате получения сообщения будет достигнута полная ясность в данном вопросе (т.е. неопределенность исчезнет), говорят, что была получена исчерпывающая информация. Это означает, что необходимости в получении дополнительной информации на эту тему нет. Напротив, если после получения сообщения неопределенность осталась прежней (сообщаемые сведения или уже были известны, или не относятся к делу), значит, информации получено не было (нулевая информация).
Если подбросить монету и проследить, какой стороной она упадет, то мы получим определенную информацию. Обе стороны монеты "равноправны", поэтому одинаково вероятно, что выпадет как одна, так и другая сторона. В таких случаях говорят, что событие несет информацию в 1 бит. Если положить в мешок два шарика разного цвета, то, вытащив вслепую один шар, мы также получим информацию о цвете шара в 1 бит. Единица измерения информации называется бит (bit) - сокращение от английских слов binary digit, что означает двоичная цифра.
В компьютерной технике бит соответствует физическому состоянию носителя информации: намагничено - не намагничено, есть отверстие - нет отверстия. При этом одно состояние принято обозначать цифрой 0, а другое - цифрой 1. Выбор одного из двух возможных вариантов позволяет также различать логические истину и ложь. Последовательностью битов можно закодировать текст, изображение, звук или какуюлибо другую информацию. Такой метод представления информации называется двоичным кодированием (binary encoding).
Винформатике часто используется величина, называемая байтом (byte) и равная 8 битам. И если бит позволяет выбрать один вариант из двух возможных, то байт, соответственно, 1 из 256 (28). В большинстве современных ЭВМ при кодировании каждому символу соответствует своя последовательность из восьми нулей и единиц, т. е. байт. Соответствие байтов и символов задается с помощью таблицы, в которой для каждого кода указывается свой символ. Так, например, в широко распространенной кодировке Koi8-R буква "М" имеет код 11101101, буква "И" - код 11101001, а пробел - код
00100000.
Наряду с байтами для измерения количества информации используются более крупные единицы:
1 Кбайт (один килобайт) = 210 байт = 1024 байта; 1 Мбайт (один мегабайт) = 210 Кбайт = 1024 Кбайта;
1 Гбайт (один гигабайт) = 210 Мбайт = 1024 Мбайта.
Впоследнее время в связи с увеличением объёмов обрабатываемой информации входят в употребление такие производные единицы, как:
1 Терабайт (Тб) = 1024 Гбайта = 240 байта, 1 Петабайт (Пб) = 1024 Тбайта = 250 байта.
Рассмотрим, как можно подсчитать количество информации в сообщении, используя содержательный подход.
53
Пусть в некотором сообщении содержатся сведения о том, что произошло одно из N равновероятных событий. Тогда количество информации х, заключенное в этом сообщении, и число событий N связаны формулой: 2x = N. Решение такого уравнения с неизвестной х имеет вид: x=log2N. То есть именно такое количество информации необходимо для устранения неопределенности из N равнозначных вариантов. Эта формула носит название формулы Хартли. Получена она в 1928 г. американским инженером Р. Хартли. Процесс получения информации он формулировал примерно так: если в заданном множестве, содержащем N равнозначных элементов, выделен некоторый элемент x, о котором известно лишь, что он принадлежит этому множеству, то, чтобы найти x, необходимо получить количество информации, равное log2N.
Если N равно целой степени двойки (2, 4, 8, 16 и т.д.), то вычисления легко произвести "в уме". В противном случае количество информации становится нецелой величиной, и для решения задачи придется воспользоваться таблицей логарифмов либо определять значение логарифма приблизительно (ближайшее целое число, большее ).
При алфавитном подходе, если допустить, что все символы алфавита встречаются в тексте с одинаковой частотой (равновероятно), то количество информации, которое несет каждый символ (информационный вес одного символа), вычисляется по формуле: x=log2N, где N - мощность алфавита (полное количество символов, составляющих алфавит выбранного кодирования). В алфавите, который состоит из двух символов (двоичное кодирование), каждый символ несет 1 бит (21) информации; из четырех символов - каждый символ несет 2 бита информации(22); из восьми символов - 3 бита (23) и т.д. Один символ из алфавита мощностью 256 (28) несет в тексте 8 битов информации. Как мы уже выяснили, такое количество информации называется байт. Алфавит из 256 символов используется для представления текстов в компьютере. Один байт информации можно передать с помощью одного символа кодировки ASCII. Если весь текст состоит из K символов, то при алфавитном подходе размер содержащейся в нем информации I определяется по формуле: , где x - информационный вес одного символа в используемом алфавите.
Например, книга содержит 100 страниц; на каждой странице - 35 строк, в каждой строке - 50 символов. Рассчитаем объем информации, содержащийся в книге.
Страница содержит 35 x 50 = 1750 байт информации. Объем всей информации в книге (в разных единицах):
1750 x 100 = 175000 байт.
175000 / 1024 = 170,8984 Кбайт.
170,8984 / 1024 = 0,166893 Мбайт.
Вероятностный подход к измерению информации
Формулу для вычисления количества информации, учитывающую неодинаковую вероятность событий, предложил К. Шеннон в 1948 году. Количественная зависимость между вероятностью события р и количеством информации в сообщении о нем x выражается формулой: x=log2 (1/p). Качественную связь между вероятностью события и количеством информации в сообщении об этом событии можно выразить следующим образом - чем меньше вероятность некоторого события, тем больше информации содержит сообщение об этом событии.
Рассмотрим некоторую ситуацию. В коробке имеется 50 шаров. Из них 40 белых и 10 черных. Очевидно, вероятность того, что при вытаскивании "не глядя" попадется белый шар больше, чем вероятность попадания черного. Можно сделать заключение о вероятности события, которые интуитивно понятны. Проведем количественную оценку вероятности для каждой ситуации. Обозначим pч - вероятность попадания при вытаскивании черного шара, рб - вероятность попадания белого шара. Тогда:
54

рч=10/50=0,2; рб40/50=0,8. Заметим, что вероятность попадания белого шара в 4 раза больше, чем черного. Делаем вывод: если N - это общее число возможных исходов какогото процесса (вытаскивание шара), и из них интересующее нас событие (вытаскивание белого шара) может произойти K раз, то вероятность этого события равна K/N. Вероятность выражается в долях единицы. Вероятность достоверного события равна 1 (из 50 белых шаров вытащен белый шар). Вероятность невозможного события равна нулю (из 50 белых шаров вытащен черный шар).
Количественная зависимость между вероятностью события р и количеством
информации в сообщении о нем x выражается формулой: . 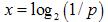
В задаче о шарах количество информации в сообщении о попадании белого шара и черного шара получится: .
Рассмотрим некоторый алфавит из m символов: 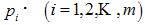 и вероятность выбора из этого алфавита какой-то i-й буквы для описания (кодирования) некоторого состояния объекта. Каждый такой выбор уменьшит степень неопределенности в сведениях об объекте и, следовательно, увеличит количество информации о нем. Для определения среднего значения количества информации, приходящейся в данном случае
и вероятность выбора из этого алфавита какой-то i-й буквы для описания (кодирования) некоторого состояния объекта. Каждый такой выбор уменьшит степень неопределенности в сведениях об объекте и, следовательно, увеличит количество информации о нем. Для определения среднего значения количества информации, приходящейся в данном случае
на один символ алфавита, применяется формула . 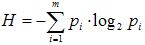
В случае равновероятных выборов p=1/m. Подставляя это значение в исходное равенство, мы получим
Рассмотрим следующий пример. Пусть при бросании несимметричной четырехгранной пирамидки вероятности выпадения граней будут следующими: p1=1/2, p2=1/4, p3=1/8, p4=1/8, тогда количество информации, получаемое после броска, можно рассчитать по формуле:
Для симметричной четырехгранной пирамидки количество информации будет: H=log24=2(бит).
Заметим, что для симметричной пирамидки количество информации оказалось больше, чем для несимметричной пирамидки. Максимальное значение количества информации достигается для равновероятных событий.
Кодирование текстовой информации Начиная с конца 60- х годов, компьютеры все больше стали использоваться для
обработки текстовой информации и в настоящее время большая часть персональных компьютеров в мире заняты обработкой текстовой информации.
Кодирование заключается в том, что каждому символу ставится в соответствие уникальный десятичный код от 0 до 255 или соответствующий ему двоичный код от
55
00000000 до 11111111. С помощью 1 байта можно получить 256 разных двоичных кодовых комбинаций и отобразить с их помощью 256 различных символов.
Таким образом, человек различает символы по их начертанию, а компьютер - по их
коду.
При вводе в память компьютера текстовой информации происходит ее двоичное кодирование, символ преобразуется в его двоичный код.
Впроцессе вывода символа на экран компьютера производится обратный процесс - декодирование, т.е. преобразование кода символа в его изображение.
Важно, что присвоение символу конкретного кода - это вопрос соглашения, которое фиксируется в кодовой таблице.
Кодовая таблица - это внутреннее представление символов в компьютере. Во всем мире в качестве стандарта принята таблица ASCII (American Standard Code for Information Interchange - Американский стандартный код для обмена информацией).
Первые 33 кода (с 0 до32) соответствует не символам, а операциям (перевод строки, ввод пробела и т.д.).
Коды с 33 по 127 являются интернациональными и соответствуют символам латинского алфавита, цифрам, знакам арифметических операций и знакам препинания.
Коды со 128 по 255 являются национальными, т.е. в национальных кодировках одному и тому же коду соответствуют различные символы.
Внастоящее время существуют пять различных кодовых таблиц для русских букв:
СР1251; СР866; КОИ-8; Мас; ISO.
Закодируем слово COMPUTER в кодах ASCII.
Вдвоичном представлении для кодирования каждого символа используется один байт (8- ми разрядный двоичный код), поэтому получится двоичный код длиной в 64 бит.
C |
O |
M |
P |
U |
T |
E |
R |
06 |
07 |
07 |
08 |
08 |
08 |
06 |
08 |
7 |
9 |
7 |
0 |
5 |
4 |
9 |
2 |
01 |
01 |
01 |
01 |
01 |
01 |
01 |
01 |
000011 |
001111 |
001101 |
010000 |
010101 |
010100 |
000101 |
010010 |
Кодирование графической информации До недавнего времени на компьютерах в основном обрабатывалась числовая и
текстовая информация. Но большую часть информации о внешнем мире человек получает в виде изображения и звука. При этом более важным оказывается изображение. Поэтому сегодня компьютеры все больше и активнее начинают работать с изображением и звуком.
Считается, что наш человеческий глаз способен различать около 16 млн. оттенков цвета. Возникает естественный вопрос, как объяснить компьютеру, что один объект красного цвета, а другой розового? В чем между ними разница, так хорошо различимая нами на глаз. Для формального описания цвета придумано несколько цветовых моделей и соответствующих им способов кодирования.
Цветовая модель RGB
Название происходит от трех базовых цветов, используемых в модели — Red, Green, Blue (красный, зеленый, синий). Эта цветовая модель описывает способ получения цвета на экране монитора или телевизора — устройств на основе электронно-лучевой трубки. Эта модель аддитивная. Слово аддитивная (сложение) подчеркивает, что цвет получается при сложении точек трех базовых цветов, каждая своей яркости. Яркость каждого базового цвета может принимать значения от 0 до 255 (256 значений), таким образом, модель позволяет кодировать 2563 или около 16,7 млн. цветов. Эти тройки
56
базовых точек (светящиеся точки) расположены очень близко друг к другу, так что каждая тройка сливается для нас в большую точку определенного цвета. Чем ярче цветная точка (красная, зеленая, синяя), тем большее количество этого цвета добавится к результирующей (тройной) точке.
Если яркость всех трех базовых цветов минимальна (равна нулю), получается черная точка. Если яркость всех трех цветов максимальна (255), при их сложении получается белая точка. Если яркость каждого базового цвета одинакова, получается серая точка (чем больше значение яркостей, тем светлее). Точка какого-нибудь красивого, сочного цвета получается в том случае, если при смешении одного (или двух) цветов гораздо меньше, чем двух (одного) других. Например, сиреневый цвет получается, если мы возьмем по максимуму красного и синего цветов и не возьмем зеленого, а желтый цвет
— достигается смешением красного и зеленого.
Так как яркость каждого компонента цвета изменяется от 0 до 255, то для кодирования всех возможных значений яркости одного цвета достаточно одного байта или 8 бит. Действительно, 28=256. Для трех компонент (трех базовых цветов) нам достаточно 3-х байт или 24 бита.
Для создания и хранения графических объектов в компьютере используется два формата:
Растровый формат Векторный формат.
Растровый формат Принцип кодирования графической информации в точечной графике был
изобретен и использовался людьми за много веков до появления компьютеров, мониторов и сканеров. Это и рисование "по клеточкам" - продуктивный способ переноса изображения с подготовительного картона на стену, предназначенную для фрески. Это мозаика, витраж, вышивка: в любой из этих техник изображение строится из дискретных элементов.
При работе с графической информацией на компьютере используется свойство человеческого глаза, которое дает возможность воспринимать изображение, состоящее из отдельных мелких деталей как одно целое, непрерывное. То есть используется ограниченность "разрешения" глаза.
Если картинку разбить на маленькие прямоугольники, то получится двумерный массив, который называется растром, а каждый прямоугольник из него - пикселем (pixel). Слово "пиксель" - аббревиатура от английских слов picture element (элемент изображения).
Другими словами, экран телевизора или монитора - это большая матрица, каждая ячейка которой независимо от других излучает определенную яркость, а все ячейки вместе отображают один кадр изображения.
Разрешение экрана монитора, определяемое как число точек (пикселей) на единицу длины, обычно дюйм, обозначают ppi (pixel per inch - пикселей на дюйм). Разрешение экрана современных мониторов составляет, как правило, 72 ppi или 96 ppi.
Разрешение цифрового изображения
Разрешением цифрового изображения (image resolution) также принимают число пикселей на единицу длины. Его количественной единицей можно считать ppi.
Изображение с большим разрешением содержит больше пикселей, которые имеют меньший размер, чем у изображения с меньшим разрешением, у которого пиксели имеют больший размер. Например, в одном квадратном дюйме изображение, предназначенное
57
для вывода на экран монитора, с разрешением 96 ppi содержит 9216 пикселей. В том же квадратном дюйме изображение, предназначенное для вывода на лазерный принтер, с разрешением 600 ppi содержит 360000 пикселей. Очевидно, что во втором случае пиксели будут в 7 раз меньше.
Более высокое разрешение позволяет передавать больше деталей и более точно репродуцировать оригинал. Таким образом, величина разрешения в значительной степени определяет качество цифрового изображения.
Уровень качества изображения закладывается в процессе сканирования в зависимости от устанавливаемого разрешения. Последующее увеличение разрешения цифрового изображения в любом графическом редакторе не способствует улучшению качества изображения. Это связано с тем, что программа не способна добавить новую изобразительную информацию (добавить новые более мелкие детали), а может только перераспределить уже имеющиеся данные на большее число пикселей. В этом случае, как правило, происходит ухудшение некоторых параметров изображения, например, резкости.
Правильный выбор величины разрешения зависит от назначения изображения и способа его использования. Необходимо найти разумный баланс между качеством, размером файла и временем его обработки, а также учесть возможности системы обработки.
Объем растрового изображения определяется умножением количества точек на информационный объем одной точки, который зависит от количества возможных цветов.
Для черно-белого изображения информационный объем одной точки равен 1 биту, т.к. она может быть либо черной, либо белой, что можно закодировать двумя цифрами - 0 или 1.
Основными достоинствами точечной графики являются:
1. Простота и, как следствие, техническая реализуемость автоматизации ввода (оцифровки) изобразительной информации в компьютер. Для этого используется развитая система внешних устройств - сканеры, видеокамеры, цифровые фотоаппараты, графические планшеты.
2. Фотореалистичность. Можно получать живописные эффекты, например, туман или дымку, добиваться тончайшей нюансировки цвета, создавать перспективную глубину, размытость и т.д.
Недостатки точечной графики:
1.Объем файла в точечной графике определяется произведением площади изображения на выбранное разрешение и на глубину цвета (если они приведены к единой размерности).
2.При попытке слегка повернуть изображение на небольшой угол (например, рисунок с четкими тонкими вертикальными линиями). Сразу обнаружится, что четкие линии превращаются в "ступеньки". Это означает, что при любых трансформациях (поворотах, масштабировании, наклонах и т.д.) в точечной графике невозможно обойтись без искажений.
Векторный формат
Векторные графические изображение являются оптимальным средством для хранения высокоточных графических объектов (чертежи, схемы и т.д.), для которых имеет значение сохранение чётких и ясных контуров.
Векторное изображение представляет собой графический объект (точка, линия, окружность, прямоугольник и т.д.), которые хранятся в памяти компьютера в виде графических примитивов и описывающих их математических формул. Например, графический примитив точка задаётся своими координатами (Х, У), линия - координатами
58
начала (Х1,У1) и конца (Х2,У2), окружность - координатами центра (Х, У) и радиусом (R), прямоугольник - величиной сторон и координатами левого верхнего угла (Х1, У1) и правого нижнего угла (Х2, У2) и т.д. Кроме того, для каждой линии указывается ее тип (сплошная, пунктирная), толщина и цвет. Информация о векторном изображении кодируется как обычная буквенно-цифровая и обрабатывается специальными программами.
Достоинства векторной графики:
1.Она экономна в плане объемов дискового пространства, необходимого для хранения изображений: это связано с тем, что сохраняется не само изображение, а только некоторые основные данные, используя которые, программа всякий раз воссоздает изображение заново.
2.Объекты векторной графики легко трансформируются, и ими просто манипулировать, что не оказывает практически никакого влияния на качество изображения. В тех областях графики, где принципиальное значение имеет сохранение ясных и четких контуров, векторные программы незаменимы.
3.Векторная графика максимально использует разрешающие способности любого выводного устройства (изображение всегда будет выглядеть настолько качественно, насколько способно его отобразить данное устройство).
4.Векторная графика может включать в себя и фрагменты точечной графики. Фрагмент становится таким же объектом, как и все остальные (правда, с весьма значительными ограничениями при обработке).
Недостатки:
Векторная графика может показаться чрезмерно жесткой. Она ограничена в живописных средствах. В программах векторной графики практически невозможно создавать фотореалистические изображения.
Кодирование звуковой информации
Звук представляет собой звуковую волну с непрерывно меняющейся амплитудой и частотой. Чем больше амплитуда, тем он громче для человека, чем больше частота сигнала, тем выше тон. Программное обеспечение компьютера в настоящее время позволяет непрерывный звуковой сигнал преобразовывать в последовательность электрических импульсов, которые можно представить в двоичной форме
Звуковая информация может быть представлена последовательностью элементарных звуков (фонем) и пауз между ними. Каждый звук кодируется и хранится в памяти. Вывод звуков из компьютера осуществляется синтезатором речи, который считывает из памяти хранящийся код звука.
Гораздо сложнее преобразовать речь человека в код, т. к. живая речь имеет большое разнообразие оттенков. Каждое произнесенное слово должно сравниваться с предварительно занесенным в память компьютера эталоном, и при их совпадении происходит его распознавание и запись.
Приемы и методы работы со звуковой информацией пришли в вычислительную технику наиболее поздно. К тому же, в отличие от числовых, текстовых и графических данных, у звукозаписей не было столь же длительной и проверенной истории кодирования. В итоге методы кодирования звуковой информации двоичным кодом далеки от стандартизации. Множество отдельных компаний разработали свои корпоративные стандарты, но если говорить обобщенно, то можно выделить два основных
направления:
1.Метод FM (Frequency Modulation)
2.Метод таблично волнового (Wave-Table) синтеза
Метод FM (Frequency Modulation) основан на том, что теоретически любой сложный звук можно разложить на последовательность простейших гармонических
59
сигналов разных частот, каждый из которых представляет собой правильную синусоиду, а, следовательно, может быть описан числовыми параметрами, то есть кодом. В природе звуковые сигналы имеют непрерывный спектр, то есть являются аналоговыми. Их разложение в гармонические ряды и представление в виде дискретных цифровых сигналов выполняют специальные устройства - аналогово-цифровые преобразователи (АЦП). Обратное преобразование для воспроизведения звука, закодированного числовым кодом, выполняют цифро-аналоговые преобразователи (ЦАП). При таких преобразованиях неизбежны потери информации, связанные с методом кодирования, поэтому качество звукозаписи обычно получается не вполне удовлетворительным и соответствует качеству звучания простейших электромузыкальных инструментов с окрасом, характерным для электронной музыки. В то же время данный метод кодирования обеспечивает весьма компактный код, и потому он нашел применение еще в те годы, когда ресурсы средств вычислительной техники были явно недостаточны.
Метод таблично-волнового (Wave-Table) синтеза лучше соответствует современному уровню развития техники. Если говорить упрощенно, то можно сказать, что где-то в заранее подготовленных таблицах хранятся образцы звуков для множества различных музыкальных инструментов (хотя не только для них). В технике такие образцы называют сэмплами. Числовые коды выражают тип инструмента, номер его модели, высоту тона, продолжительность и интенсивность звука, динамику его изменения, некоторые параметры среды, в которой происходит звучание, а также прочие параметры, характеризующие особенности звука. Поскольку в качестве образцов используются "реальные" звуки, то качество звука, полученного в результате синтеза, получается очень высоким и приближается к качеству звучания реальных музыкальных инструментов.
С начала 90-х годов персональные компьютеры получили возможность работать со звуковой информацией. Каждый компьютер, имеющий звуковую плату, микрофон и колонки, может записывать, сохранять и воспроизводить звуковую информацию
Аудиоадаптер (звуковая плата) – специальное устройство, подключаемое к компьютеру, предназначенное для преобразования электрических колебаний звуковой частоты в числовой двоичный код при вводе звука и для обратного преобразования (из числового кода в электрические колебания) при воспроизведении звука.
В процессе записи звука аудиоадаптер с определенным периодом измеряет амплитуду электрического тока и заносит в регистр двоичный код полученной величины. Затем полученный код из регистра переписывается в оперативную память компьютера. Качество компьютерного звука определяется характеристиками аудиоадаптера: частотой
дискретизации и разрядностью.
Частота дискретизации – это количество измерений входного сигнала за 1 секунду. Частота измеряется в герцах (Гц). Одно измерение за одну секунду соответствует частоте 1 Гц. 1000 измерений за 1 секунду – 1 килогерц (кГц). Характерные частоты дискретизации аудиоадаптеров: 11 кГц, 22 кГц, 44,1 кГц и др.
Разрядность регистра – число бит в регистре аудиоадаптера. Разрядность определяет точность измерения входного сигнала . Чем больше разрядность, тем меньше погрешность каждого отдельного преобразования величины электрического сигнала в число и обратно. Если разрядность равна 8 (16) , то при измерении входного сигнала может быть получено 28= 256 (216=65536) различных значений. Очевидно, 16-разрядный аудиоадаптер точнее кодирует и воспроизводит звук, чем 8-разрядный.
Звуковой файл - файл, хранящий звуковую информацию в числовой двоичной
форме.
Раздел 3.Теоретические основы построения ПК
60