

•стоимость.
Если в отношении стоимости все понятно, то остальные характеристики процессоров нуждаются в комментариях.
ПРОИЗВОДИТЕЛЬНОСТЬ
Под производительностью процессора принято понимать скорость выполнения им той или иной задачи, то есть чем меньше времени затрачивает процессор на ее реализацию, тем выше его производительность. Одни процессоры демонстрируют более высокую производительность на одном наборе приложений, а какие-то — на другом. В этом смысле более корректно говорить не об абсолютной производительности процессора (как о некой безусловной истине), а о производительности на наборе приложений.
На производительность процессора оказывают непосредственное влияние его микроархитектура, размер кэша, тактовая частота и количество ядер процессора. Переход от одноядерных процессоров к многоядерным — это современная тенденция развития процессоров и причина состоит в том, что энергопотребление процессоров сегодня достигло уже той критической отметки, когда дальнейшее увеличение тактовой частоты невозможно,
поскольку подобные одноядерные процессоры просто нечем охлаждать.
При переходе к многоядерным не просто меняется архитектура процессоров, но и требуется изменение программного обеспечения. Многоядерные процессоры могут дать выигрыш по производительности если только используется оптимизированное под многоядерность, хорошо распараллеливаемое программное обеспечение.
ЭНЕРГОЭФФЕКТИВНОСТЬ
Процессоры принято характеризовать энергоэффективностью, то есть производительностью в расчете на ватт потребляемой им электроэнергии. Ранее, когда потребляемая процессором мощность составляла всего несколько десятков ватт, на такую характеристику, как энергоэффективность, просто не обращали внимание. Однако при достижении потребляемой процессором мощности рубежа в 100 Вт, а тем более его превышении энергоэффективность стала одной из важнейших характеристик процессора. Дело в сложности охлаждения процессора. Приходится использовать массивные и шумные кулеры, что исключает возможность создания малошумных ПК.
Энергоэффективность зависит от таких характеристик, как микроархитектура процессора, технологический процесс производства,
тактовая частота, потребляемая мощность и поддержка процессором функций энергосбережения.
ФУНКЦИОНАЛЬНЫЕ ВОЗМОЖНОСТИ
Современные процессоры характеризуются набором поддерживаемых технологий. Так, нынешние процессоры Intel и AMD поддерживают следующие технологии: виртуализации (VT), защиты от вирусов, 64-разрядных вычислений (Intel EM64T), защиты от перегрева,
энергосбережения.
В компьютерных технологиях под термином "виртуализация" обычно понимается абстракция вычислительных ресурсов и предоставление пользователю системы, которая "инкапсулирует" (скрывает в себе) собственную реализацию. Проще говоря, пользователь работает с удобным для себя представлением объекта, и для него не имеет значения, как объект устроен в действительности. Различают:
-виртуализация платформ, продуктом этого вида виртуализации являются виртуальные машины — некие программные абстракции, запускаемые на платформе реальных аппаратно-программных систем.
-виртуализация ресурсов, преследует своей целью комбинирование или упрощение представления аппаратных ресурсов для пользователя и получение неких пользовательских абстракций оборудования, пространств имен, сетей и т.п. Например, виртуальная память делит физическую память на блоки и
распределяет их между различными задачами. При этом она предусматривает некоторую схему защиты, которая ограничивает задачу теми блоками, которые ей принадлежат.
Процессорная технология защиты от вирусов. Сегодня она реализована во всех новых процессорах Intel и AMD. Суть этой технологии состоит в аппаратном обеспечении антивирусной защиты, заключается в перехватывании зловредного кода и сведении к минимуму опасности умышленного переполнения буфера (Buffer Overflow).
Переполнение буфера (buffer overflows) - название самой распространенной уязвимости в области безопасности программного обеспечения. Первая атака с применением данной уязвимости использовалась в вирусе-черве Морриса в 1988 году. Переполнение буфера является наиболее популярным способом взлома компьютерных систем, так как большинство языков высокого уровня используют технологию стекового кадра — размещение данных в стеке процесса, смешивая данные программы с управляющими данными (в том числе адреса начала стекового кадра и адреса возврата из исполняемой функции). Переполнение в стековом кадре, позволяют злоумышленнику загрузить и выполнить произвольный машинный код от имени программы и с правами учетной записи, от которой она выполняется.Майкрософт разработала механизм защиты стека, предназначенный для Windows Server 2003. Стек помечается с помощью так называемых «осведомителей» (canary), целостность которых затем проверяется. Если «осведомитель» был изменён, значит, стек повреждён.
Память (кэш, оперативная, ЖД (винчестеры), СD(DVD), твердотельная, флэш)
Кэш — это некая особенная разновидность памяти, которая является своего рода «буфером» между контроллером памяти и процессором.
Служит для увеличения скорости работы с ОЗУ. Любая считываемая из памяти информация попадает не только в процессор, но и в кэш. И если эта же информация (тот же адрес в памяти) нужна снова, сначала процессор проверяет: а нет ли её в кэше? Если есть — информация берётся оттуда, и обращения к памяти не происходит вовсе. Аналогично с записью: информация, если её объём влезает в кэш — пишется именно туда, и только потом, когда процессор закончил операцию записи, и занялся выполнением других команд, данные, записанные в кэш, параллельно с работой процессорного ядра «потихоньку выгружаются» в ОЗУ.
Скорость обмена данными процессора Pentium 4 со своим кэшам более чем в 10 раз (!) превосходит скорость его работы с памятью. Фактически, в полную силу современные процессоры способны работать только с кэшем. Систему кэширования приходится делать многоуровневой. Кэш первого уровня (самый «близкий» к ядру) традиционно разделяется на две половины, кэш инструкций (L1I) и кэш данных (L1D). Это разделение предусматривается «гарвардской архитектурой» процессора, которая является самой популярной теоретической разработкой для построения современных CPU. Кэш второго и третьего уровня больше по объёму, и является уже «смешанным» — там располагаются и команды, и данные. Если ни на одном уровне кэша информация не найдена — идёт обращение к основной памяти (ОЗУ).
Trace cache – идея сохранять в кэше инструкций первого уровня (L1I) не команды, а уже декодированные последовательности.
Латентность памяти - время, которое требуется для того, чтобы начать считывать информацию с определённого адреса. C момента, когда процессор посылает контроллеру памяти команду на считывание (запись) и до момента, когда эта операция осуществляется, проходит определённое количество времени. Если данные в программе расположены «хаотично» и «небольшими кусками», скорость их считывания становится намного менее важной, чем скорость доступа к «началу куска». Латентность подсистемы памяти зависит не только от неё самой, но и от контроллера памяти и места его расположения. Понятия «скорость чтения / записи» и «латентность», применимы к любому типу памяти —к классической DRAM
(SDR, Rambus, DDR, DDR2) и к Кэшу.
В качестве элементов оперативной памяти используют ячейки, представляющие собой конденсаторы. Заряженный конденсатор хранит "1", разряженный — "0". Заряд в конденсаторе из-за утечки хранится ограниченное время (несколько миллисекунд). Поэтому необходима подзарядка, которая выполняется в процессе регенерации информации. Это обстоятельство обусловило название памяти подобного типа — динамическая память или DRAM (Dynamic RAM).
С целью повышения быстродействия DRAM разработано несколько модификаций этого типа памяти. Синхронная память типа SDRAM
(Synchronous DRAM) отличается от асинхронной памяти типа DRAM тем, что такты работы памяти засинхронизированы с тактами работы процессора. Это позволяет исключить циклы ожидания, имеющие место в DRAM.
По сравнению с обычной SDRAM в памяти типа DDR SDRAM (Double Date Rate SDRAM) при одной и той же частоте шины памяти быстродействие
удалось увеличить вдвое за счет того, что обращения к памяти происходят дважды за такт — как по переднему, так и по заднему фронту тактовых сигналов. В памяти типа DDR2 в отличие от DDR возможна работа на больших тактовых частотах. Например, в памяти DDR2-1066 при частоте шины 266 обеспечивается частота обращений к памяти 1066 МГц. Память типа DDR3 имеет меньшее потребление энергии по сравнению с
DDR2.
В современных настольных компьютерах используется оперативная память двух типов - DDR и DDR2. Старые типы памяти вроде SDRAM сегодня практически не применяются, за исключением устаревших машин и некоторых встраиваемых систем. Поддержка того или иного типа оперативной памяти осуществляется на уровне набора системной логики, как в случае с платформой Intel, либо на уровне самого процессора, как в случае с чипами
AMD Athlon 64.
Распараллеливание.
Распараллелить решение задачи можно на нескольких уровнях. Между этими уровнями нет четкой границы и конкретную технологию распараллеливания бывает сложно отнести к одному из них. Для нескольких ядер программист явным образом указывает, какие функции на каких ядрах(компьютерах) должны выполняться, — это физически параллельная система. Простота идеи программирования физически параллельных систем выливается на практике в целый ряд сложных методик и условий.
-алгоритм должен допускать распараллеливание.
-при вычленении параллельных участков приходится придавать алгоритму специальную форму. Например, на первом шаге одновременно суммируются соседние четные и нечетные элементы массива, а на втором попарно суммируются результаты, полученные на первом шаге, и т. д. Процесс создания максимально эффективного параллельного алгоритма практически не автоматизируется и связан с большими трудозатратами
-в многопроцессорной системе разбиение на слишком крупные части не позволяет равномерно загрузить процессоры и добиться минимального времени вычислений, а излишне мелкая "нарезка" означает рост непроизводительных расходов на связь и синхронизацию.
Распараллеливание на уровне задач нам демонстрирует операционная система Windows на примере «Диспетчера задач». Если первая программа показывает нам фильм, а вторая является файлообменным клиентом, то операционная система спокойно сможет организовать их параллельную работу с помощью планировщика задач. Другими примерами распараллеливания является параллельная компиляция файлов в Visual Studio 2008, обработка данных в пакетных режимах, например, в сетевых сервисах .NET Framework4.
Что бы распараллелить однородные задачи, нужно спуститься на уровень ниже. «Параллелизм данных» заключается в применении одной и той же операции к множеству элементов. Параллелизм данных демонстрирует архиватор, использующий для упаковки несколько ядер процессора. Данные разбиваются на блоки, которые единообразным образом упаковываются на разных узлах. Данный вид параллелизма широко используется при решении задач численного моделирования. Счетная область представлена в виде ячеек, описывающих состояние среды в соответствующих точках пространства — давление, плотность, процентное соотношение газов, температура и так далее. Количество таких ячеек может быть огромным — миллионы и миллиарды. В математической физике такой тип параллелизма называют геометрическим параллелизмом.
Параллелизм на уровне команд (конвейеры и суперскалярная архитектура) обычно повышают скорость работы в 5-10 раз. Чтобы увеличить производительность в 50, 100 и более раз, нужно создавать компьютеры с несколькими процессорами. Матричный (а также векторный) процессор как раз состоит из большого числа сходных процессоров, которые выполняют одну и ту же последовательность команд применительно к разным наборам данных.
Матричный процессор
Параллельная программа содержит несколько процессов, работающих совместно над выполнением некоторой задачи. Осуществить взаимодействие можно через разделяемую память: на каждом процессоре мультипроцессорной системы запускается поток исполнения, который принадлежит одному процессу. Потоки обмениваются данными через общий для данного процесса участок памяти. Данный вид параллельного программирования обычно требует какой-то формы захвата управления (семафоры, мониторы) для координации потоков между собой.
Взаимодействие c помощью передачи сообщений: на каждом процессоре запускается однопоточный процесс, который обменивается данными с другими процессами, работающими на других процессорах, с помощью сообщений. Обмен сообщениями может происходить асинхронно, либо c использованием метода «рандеву», при котором отправитель блокирован до тех пор, пока его сообщение не будет доставлено. Параллельные системы, основанные на обмене сообщениями, более просты для понимания, чем системы с разделяемой памятью, и рассматриваются как более совершенный метод параллельного программирования.
При любом виде взаимодействия процессам необходима взаимная синхронизация. Существуют два основных вида синхронизации - взаимное исключение и условная синхронизация. Взаимное исключение предполагает, чтобы критические секции операторов не выполнялись одновременно. Например, взаимодействие процессов производителя и потребителя обеспечивается буфером в разделяемой памяти. Производитель записывает в буфер, потребитель читает из него. Чтобы предотвратить одновременное использование буфера и производителем, и потребителем (тогда может быть считано не полностью записанное сообщение), используется взаимное исключение. Условная синхронизация задерживает процесс до тех пор, пока не выполнится определенное условие, например, подтверждение полученного сообщения.
Следующий уровень, это распараллеливание отдельных процедур и алгоритмов. Сюда можно отнести алгоритмы параллельной сортировки, умножение матриц, решение системы линейных уравнений. На этом уровне абстракций удобно использовать такую технологию параллельного программирования, как OpenMP.
*) Open Multi-Processing - это набор директив компилятора, библиотечных процедур и переменных окружения, предназначенных для программирования многопоточных приложений на многопроцессорных системах. В основу положена идея использования специальных компиляторов, "знающих" про параллельное программирование и что следует делать параллельно, а что - последовательно. Если вы пишете на С/С++ — советую попробовать OpenMP, он очень прост. Грубо говоря, перед началом работы указываете, какие данные shared, какие — private и... и все. Оно само все распараллелит. Но заботиться о доступе к памяти и блокировках приходится программисту.
Компилятоp - системная программа, выполняющая преобразование программы, написанной на одном алгоритмическом языке, в программу на языке, близком к машинному. Некоторые компиляторы (например, Java) переводят программу не в машинный код, а в программу на некотором специально созданном низкоуровневом языке. Такой байт-код можно считать языком машинных команд, поскольку он подлежит интерпретации виртуальной машиной. Для каждой целевой машины (IBM, Apple и т.д.) и каждой операционной системы требуется написание своего компилятора. Компилятор содержит две части - транслятор и компоновщик, именно последний помогает решать задачи распараллеливания. Основной задачей компоновки является настройка внешних ссылок объектных модулей на точки входа функций переменных, которые определены в других объектных модулях программы и стандартных библиотеках системы программирования.
Например, компилятор GCC содержит следующие инструментальные программные компоненты: препроцессор, транслятор, ассемблер, компоновщик (редактор связей - линковщик), которые реализуют выполнение одноименных фаз компиляции. Препроцессор вставляет в исходный текст программы заголовочные файлы, указанные директивой # include stdlib;, # define Macros( ) подставляет значения макросов, заданные директивой . Транслятор выполняет грамматический разбор программы на данном языке (С, С++) для проверки синтаксических ошибок. Ассемблер конвертирует текст программы на языке ассемблера в объектный код из машинных инструкций.
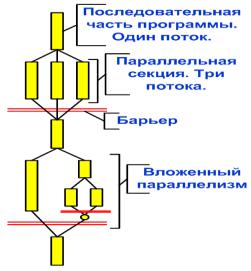
OpenMP позволяет работать на нескольких уровнях - либо задавать низкоуровневые объекты вручную, либо указывать, какие переменные являются "общими" и требуют синхронизации, передоверяя собственно синхронизацию компилятору. Разработчик не создает новую параллельную программу, а последовательно добавляет в текст последовательной программы директивы. В OpenMP используется модель параллельного выполнения «ветвлениеслияние». Программа OpenMP начинается как единственный начальный поток выполнения. Когда поток встречает параллельную конструкцию, он создает новую группу потоков, состоящую из себя и некоторого числа дополнительных потоков, и становится главным в новой группе. Все члены новой группы (включая главный поток) выполняют код внутри параллельной конструкции. В конце параллельной конструкции имеется неявный барьер. После параллельной конструкции выполнение пользовательского кода продолжает только главный поток.
Недостатков у OpenMP два. Первый - относительно жесткая модель программирования, навязываемая программисту - не очевидно, как заставить OpenMP-программу работать в режиме "системы массового обслуживания", когда некий "главный" поток принимает поступающие извне задания (скажем, запрос к веб-серверу) по отдельным потокам. А вручную подобная система делается элементарно. Второй - только сейчас появляющаяся поддержка сообщества Open Source.
Первая спецификация компилятора OpenMP появилась в 1997 году и предназначалась для одного из древнейших языков программирования Fortran, на котором некогда было написано большинство "серьезных" вычислительных приложений. В 1998 году появились варианты OpenMP для языков C/C++; стандарт прижился, получил распространение и к настоящему моменту дорос до версии 2.5. Поддержка спецификации есть во всех компиляторах Microsoft и GNU-систем типа Linux.
Наиболее низкий уровень параллелизма осуществляется на уровне параллельной обработки процессором нескольких инструкций (технологии MMX, SSE, SSE2 ит.д.). Для реализации данного вида параллелизма в микропроцессорах используется несколько конвейеров команд, технологии предсказание команд, переименование регистров. Программист редко заглядывает сюда. Интерес этот уровень может представлять только для узкой группы специалистов.
MMX (Multimedia Extensions) — коммерческое название дополнительного набора инструкций, выполняющих характерные для процессов кодирования/декодирования потоковых аудио/видео данных действия за одну машинную инструкцию. SSE (Streaming SIMD Extensions) включает в архитектуру процессора восемь 128-битных регистров и набор инструкций, работающих со скалярными и упакованными типами данных. SSE работает с вещественными числами, MMX – с целыми. В SSE2 регистры по сравнению с MMX удвоились, там стало помещаться не, например, 8 чисел, а 16. Поскольку скорость выполнения инструкций не изменилась, при оптимизации под SSE2 программа запросто получала двукратный прирост производительности.
Параллелизм на уровне битов. Эта форма параллелизма основана на увеличении размера машинного слова. Увеличение размера машинного слова уменьшает количество операций, необходимых процессору для выполнения действий над переменными, чей размер превышает размер машинного слова. К примеру: на 8-битном процессоре нужно сложить два 16-битных целых числа. Для этого вначале нужно сложить нижние 8 бит чисел, затем сложить верхние 8 бит и к результату их сложения прибавить значение флага переноса. Итого 3 инструкции. С 16-битным процессором можно выполнить эту операцию одной инструкцией.