

Обработка данных в среде MATLAB
.pdfМИНОБРНАУКИ РОССИИ
––––––––––––––––––––––––––––––––––––
Санкт-Петербургский государственный электротехнический университет «ЛЭТИ»
––––––––––––––––––––––––––––––––––––
ОБРАБОТКА ДАННЫХ В СРЕДЕ MATLAB
Методические указания к практическим и лабораторным занятиям
Санкт-Петербург Издательство СПбГЭТУ «ЛЭТИ»
2013
УДК 615.47:004.93
Обработка данных в среде MATLAB: Методические указания к практическим и лабораторным занятиям / Сост.: А. П. Немирко, Л. А. Манило. СПб.: Изд-во СПбГЭТУ «ЛЭТИ», 2013. 35 с.
Содержат описания лабораторных работ по выполнению математических расчетов, связанных с автоматическим анализом биомедицинских данных, с использованием программного пакета MATLAB.
Предназначены для студентов, обучающихся по направлению подготовки бакалавров и магистров 201000 «Биотехнические системы и технологии», а также могут быть полезны научным работникам и инженерам, специализирующимся в области компьютерной обработки биомедицинских данных.
Утверждено редакционно-издательским советом университета
в качестве методических указаний
© СПбГЭТУ «ЛЭТИ», 2013
2

Данные методические указания1 предназначены для помощи студентам при выполнении практических и лабораторных занятий по обработке данных в среде MATLAB. Основное направление работ – анализ объектов, описываемых многомерными данными. Поэтому в данные указания включено описание методов сравнения одномерных и многомерных данных, сведение многомерного описания к одномерному и двумерному случаю (метод главных компонент и дискриминантный анализ Фишера), методы классификации данных. Для успешного выполнения работ учащимся может потребоваться использование дополнительных учебных пособий (см. список рекомендуемой литературы). Студентам необходима предварительная подготовка к каждому занятию, включающая ознакомление с рассматриваемыми методами обработки биомедицинских данных, а также с теми функциями и возможностями MATLAB, которые используются в данной работе.
Перед началом занятий необходимо организовать на жестком диске компьютера отдельную папку, которая будет использоваться в качестве рабочей. В эту папку перед началом работы должны записываться необходимые для её выполнения исходные файлы, а в ходе выполнения работы – создаваемые программы, а также полученные результаты (графики и файлы с данными). Ввиду того что пакет MATLAB не адаптирован к русскому шрифту, следует избегать использования русских букв как в именах переменных или файлов, так и в текстовых надписях, а также в комментариях к программам. Кроме того, имена файлов не должны начинаться с цифр.
1. ПРЕДСТАВЛЕНИЕ ДАННЫХ
Цели работы: получение навыков работы с массивами данных в системе MATLAB; вычисление статистических параметров массивов и исследование статистической связи между массивами.
Основные положения
В дальнейшем будут использоваться два вида данных: искусственные статистические данные, генерируемые системой MATLAB, и реальные данные, также извлекаемые из пакета MATLAB.
1 Работа выполнялась при финансовой поддержке РФФИ (гранты № 12-01-00583 и 13-01-00540) и Министерства образования и науки РФ (государственный контракт № 16.522.12.2016 от 10.10.2012 г.).
3
Статистические данные
Пример 1.1
Данные (по 10 реализаций каждого класса) по трем классам генерируются с помощью функции генерации из нормального закона R = normrnd(MU, SIGMA,m,n), где MU – среднее, SIGMA – среднеквадратичное отклонение (СКО), m, n – количества строк и столбцов матрицы R. Параметры распределений по трем классам назначим так, как показано в табл. 1.1.
|
|
|
|
|
Таблица 1.1 |
|
|
|
|
|
|
|
|
Класс |
|
Среднее значение |
|
СКО |
||
1-й признак |
2-й признак |
3-й признак |
4-й признак |
|||
|
|
|||||
1-й класс, A |
m = 5 |
m = 4 |
m = 7 |
m = 2 |
δ = 1 |
|
2-й класс, B |
m = 3 |
m = 5 |
m = 4 |
m = 3 |
δ = 2 |
|
3-й класс, C |
m = 7 |
m = 6 |
m = 3 |
m = 2 |
δ = 1 |
|
Могут использоваться и другие генераторы случайных чисел, например randn(n,m), в результате которого выдается матрица размерностью (n × m), в каждом столбце которой генерируются отсчеты нормального распределения с нулевым средним и единичной дисперсией.
1-й класс формируется следующим образом:
a11=normrnd(5,1,10,1); % генерация столбца 1-го признака a12=normrnd(4,1,10,1); % генерация столбца 2-го признака a13=normrnd(7,1,10,1); % генерация столбца 3-го признака a14=normrnd(2,1,10,1); % генерация столбца 4-го признака a1=[a11 a12 a13 a14] % матрица 10 х 4 первого класса
Аналогично для 2-го и 3-го классов формируются матрицы a2 и a3.
a21=normrnd(3,2,10,1);
a22=normrnd(5,2,10,1);
a23=normrnd(4,2,10,1);
a24=normrnd(3,2,10,1);
a2=[a21 a22 a23 a24]; % матрица 10 х 4 второго класса a31=normrnd(7,1,10,1);
a32=normrnd(6,1,10,1);
a33=normrnd(3,1,10,1);
a34=normrnd(2,1,10,1);
a3=[a31 a32 a33 a34]; % матрица 10 х 4 третьего класса
Объединив все матрицы в одну a=[a1;a2;a3], получим результирующую матрицу a размерностью 30 × 4, первые 10 строк которой описывают 1-й класс, вторые – 2-й класс и третьи 3-й, причем все объекты описываются по 4-м признакам:
4
a=[a1;a2;a3];
Теперь получим групповую матрицу g, в которой запишем соответствующие наименования классов для каждого наблюдения. Классов всего три: A, B, C.
gg=['A'; 'A'; 'A'; 'A'; 'A'; 'A'; 'A'; 'A'; 'A'; 'A'; 'B'; 'B'; 'B'; 'B'; 'B'; 'B'; 'B'; 'B'; 'B'; 'B'; 'C';'C'; 'C'; 'C'; 'C'; 'C'; 'C'; 'C'; 'C'; 'C'];
%gg – символьная матрица g=cellstr(gg);
%cellstr – функция, преобразующая символьную матрицу
%в матрицу строк
%g – матрица элементов (строк); ее размерность равна 30х1;
%первые 10 строк матрицы g равны ‘A’, вторые – ‘B’, третьи –
%‘C’
Получение экспериментальных данных из пакета MATLAB («Ирисы Фишера»)
Пример 1.2
Ирисы Фишера – это набор данных для задачи классификации, на примере которого Рональд Фишер (английский ученый, один из основоположников математической генетики) в 1936 г. продемонстрировал работу разработанного им метода дискриминантного анализа. Ирисы Фишера состоят из данных о 150 экземплярах ириса, по 50 экземпляров трёх видов – ириса щетинистого, ириса виргинского и ириса разноцветного. Для каждого экземпляра измерялись четыре характеристики: длина чашелистика; ширина чашелистика; длина лепестка; ширина лепестка. Данные по ирисам Фишера вошли в состав системы MATLAB и могут использоваться для иллюстраций работы алгоритмов классификации. В матрицах системы MATLAB, содержащих статистические данные, строки используются для представления наблюдений, а столбцы – для представления измеренных переменных.
Строка
load fisheriris % Данные по ирисам Фишера
загружает переменную измерений (meas) и переменную видов (species) в рабочую область MATLAB. Переменная измерений представляет собой числовую матрицу размерностью 150 × 4, в которой представлены 150 наблюдений 4 различных измеренных переменных (по столбцам: длина чашелистика, ширина чашелистика, длина лепестка, ширина лепестка соответственно). Наблюдения в измерениях принадлежат трем различным видам ирисов: щетинистый (setosa), разноцветный (versicolor) и виргинский (virginica). Данные
5
по видам могут быть разделены один от другого с использованием строковой матрицы видов – species (150 × 1)
setosa_indices = strcmp('setosa',species); setosa = meas(setosa_indices,:);
Результирующая переменная setosa представляет собой матрицу (50 × 4) 50 наблюдений 4 измеренных переменных для ирисов setosa. Чтобы получить и отобразить первые 5 наблюдений данных по setosa, используем поясняющее индексирование:
SetosaObs = setosa(1:5,:) SetosaObs =
5.1000 3.5000 1.4000 0.2000
4.9000 3.0000 1.4000 0.2000
4.7000 3.2000 1.3000 0.2000
4.6000 3.1000 1.5000 0.2000
5.0000 3.6000 1.4000 0.2000
Эти данные организованы в таблицу с подразумеваемыми названиями колонок «Длина чашелистика», «Ширина чашелистика», «Длина лепестка» и «Ширина лепестка». Подразумеваемые названия строк – это «Наблюдение 1», «Наблюдение 2», «Наблюдение 3» и т. д.
Аналогично, по 50 наблюдений по ирисам разноцветным – versicolor, и ирисам виргинским – virginica, могут быть выделены из контейнерной переменной измерений (meas):
versicolor_indices = strcmp('versicolor',species); versicolor = meas(versicolor_indices,:);
virginica_indices = strcmp('virginica',species); virginica = meas(virginica_indices,:);
Так как множества данных для этих трех видов имеют один и тот же размер, они могут быть переформатированы в один многомерный массив iris с размерностью 50 × 4 × 3.
iris = cat(3,setosa,versicolor,virginica);
Полученный массив iris по ирисам представляет собой трехслойную таблицу с одинаковыми подразумеваемыми заголовками строк и столбцов: массивы setosa, versicolor и virginica. Вдоль третьей размерности – подразумеваемые имена слоев «Setosa», «Versicolor» и «Virginica». Чтобы получить и отобразить данные в многомерном массиве, надо использовать
6
поясняющую индексацию, как и для двумерных массивов. Получим первые 5 наблюдений признака длина лепестка (sepal lengths) в данных по setosa:
SetosaSL = iris(1:5,1,1) SetosaSL =
5.1000
4.9000
4.7000
4.6000
5.0000
Многомерные массивы обеспечивают естественный путь к организации числовых данных, для которых наблюдения или конструкции экспериментов имеют много размерностей. Если бы, например, данные со структурой ирисов были бы собраны многими наблюдателями в множестве мест в множестве разных дат, то полные данные могли бы быть организованы в единственный многомерный массив с размерностями для «Наблюдатель», «Местоположение» и «Дата». Подобно этому экспериментальный план для m наблюдений и n p-мерных переменных может быть запомнен как массив m × n × p.
Задание
1.Освоить генерацию и ввод матриц данных в системе MATLAB. Освоить способы расчета статистических параметров массива данных.
2.Освоить основы расчета статистической связи между массивами
данных.
Порядок выполнения работы
1.Запустите систему MATLAB. В главном окне (в поле Current Directory, расположенном в верхнем правом углу) установите путь к рабочей папке.
2.Создайте 2 массива из 10 случайных чисел каждый по нормальному
закону с параметрами, представленными в табл. 1.2
Таблица 1.2
Массив |
V1 |
V2 |
V3 |
V4 |
V5 |
V6 |
V7 |
V8 |
V9 |
V10 |
1 |
m = 2 |
m = 3 |
m = 4 |
m = 5 |
m = 6 |
m = 3 |
m = 5 |
m = 6 |
m = 7 |
m = 8 |
|
σ = 1 |
σ = 1 |
σ = 1 |
σ = 2 |
σ = 2 |
σ = 2 |
σ = 1 |
σ = 1 |
σ = 2 |
σ = 3 |
2 |
m = 6 |
m = 8 |
m = 7 |
m = 2 |
m = 2 |
m = 7 |
m = 2 |
m = 7 |
m = 3 |
m = 4 |
|
σ = 2 |
σ = 4 |
σ = 3 |
σ = 1 |
σ = 1 |
σ = 4 |
σ = 1 |
σ = 1 |
σ = 2 |
σ = 2 |
3.Вычислите выборочные оценки среднего значения и среднеквадратического отклонения каждого массива.
4.Вычислите коэффициент корреляции между вашими двумя массивами.
7
5. Вычислите выборочные статистические параметры двух первых признаков ирисов «Setosa» и коэффициент корреляции между ними.
Содержание отчета
1.Название, цель и задачи работы.
2.Тексты программ, которые требовалось сохранять в ходе выполнения
работы.
3.Объяснение полученных результатов и выводы.
2. СРАВНЕНИЕ ОДНОМЕРНЫХ ДАННЫХ
Цель работы: получение навыков сравнения одномерных данных в системе MATLAB.
Основные положения
Визуально близость и различие двух и более групп одномерных данных можно оценить с помощью графиков (plot), гистограмм (hist) и коробочковых диаграмм (boxplot).
Гистограммы
Функция n = hist(Y) разбивает элементы вектора Y на 10 одинаковых и равномерно распределенных интервалов и возвращает число элементов, попавших в каждый интервал в виде вектора-строки. Функция n = hist(Y,x), где x – вектор, возвращает распределение Y по ячейкам переменной x, причем центры этих ячеек равны значениям переменной x. Функция hist показывает распределение элементов Y в виде гистограммы с одинаковыми и равномерно распределенными ячейками между минимальным и максимальным значениями Y.
3000 |
|
|
|
|
|
|
2500 |
|
|
|
|
|
|
2000 |
|
|
|
|
|
|
hist(yn) |
|
|
|
|
|
|
(yn) |
|
|
|
|
|
|
1500 |
|
|
|
|
|
|
hist |
|
|
|
|
|
|
1000 |
|
|
|
|
|
|
500 |
|
|
|
|
|
|
00 |
|
|
|
|
|
yn5 |
-4 |
- |
- |
-1 |
0 1 2 |
3 4 |
|
–4 –3 |
–2 |
–1 |
x |
|||
|
|
|
|
x |
|
|
|
|
|
Рис. 2.1 |
|
|
|
|
30000 |
|
|
|
|
|
|
|
|
|
25000 |
|
|
|
|
|
|
|
|
|
20000 |
|
|
|
|
|
|
|
|
hist(yn) |
(yn) |
|
|
|
|
|
|
|
|
15000 |
|
|
|
|
|
|
|
|
|
hist |
|
|
|
|
|
|
|
|
|
|
10000 |
|
|
|
|
|
|
|
|
|
5000 |
|
|
|
|
|
|
|
|
|
0 |
|
|
|
|
|
|
|
|
|
0 |
|
|
|
|
|
|
|
yn 10 |
|
1 |
2 |
3 |
4 |
5 x 6 |
7 |
8 |
9 |
|
|
x |
||||||||
|
|
|
|
|
Рис. 2.2 |
|
|
|
|
8 |
|
|
|
|
|
|
|
|
|
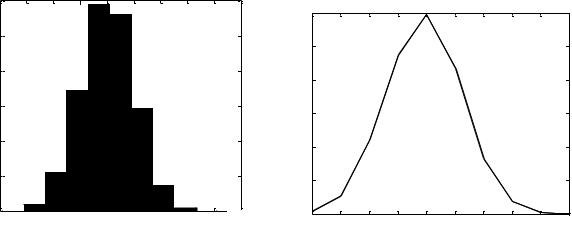
Пример 2.1
Выражение
yn = randn(10000,1); hist(yn)
генерирует 10 000 случайных чисел и создает гистограмму с 10 ячейками, распределенными вдоль оси x между минимальным и максимальным значениями yn, как показано на рис. 2.1.
Если нужно отредактировать график то, используя plot, вместо последней строки нужно написать:
plot (hist(yn))
В этом случае можно получить сплошной график, как на рис. 2.2.
Пример 2.2
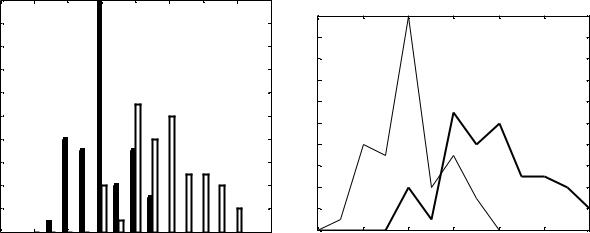
Сравним два вида ирисов (setosa и versicolor) по первому признаку c помощью их гистограмм (рис. 2.3):
load fisheriris
setosa_indices = strcmp('setosa',species);
S = meas(setosa_indices,:); % Результирующая переменная S
%представляет собой матрицу (50 х 4) 50 наблюдений 4 измеренных
%признаков для ирисов setosa.
versicolor_indices = strcmp('versicolor',species);
V = meas(versicolor_indices,:); % Результирующая переменная V
%представляет собой матрицу (50 х 4) 50 наблюдений
%4 измеренных признаков для ирисов versicolor. s1=S(:,1); % Первый столбец (признак) переменной S. v1=V(:,1); % Первый столбец (признак) переменной V.
s1v1=[s1 v1]% Объединение двух матриц в виде двух столбцов.
|
20 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
18 |
|
|
|
|
|
|
|
|
|
20 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
16 |
|
|
|
|
|
|
|
|
|
18 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
16 |
|
|
|
|
|
|
|
14 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
t) |
|
|
|
|
|
|
|
|
|
|
14 |
|
|
|
|
|
|
12 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
(s1v1,hist |
|
|
|
|
|
|
|
|
|
12 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
s1v1h |
|
|
|
|
|
|
||
10 |
|
|
|
|
|
|
|
|
10 |
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
8 |
|
|
|
|
|
|
|
|
|
8 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
6 |
|
|
|
|
|
|
|
|
|
6 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
4 |
|
|
|
|
|
|
|
|
|
4 |
|
|
|
|
|
|
|
2 |
|
|
|
|
|
|
|
|
|
2 |
|
|
|
|
|
|
|
0 |
|
|
|
|
|
|
|
|
|
0 |
|
|
|
|
|
|
|
3.5 |
4 |
4.5 |
5 |
5.5 |
6 |
6.5 |
7 |
7.5 |
|
4 |
4.5 |
5 |
5.5 |
6 |
6.5 |
7 |
|
|
|
|
|
t |
|
|
|
|
|
|
|
|
t |
|
|
|
|
|
|
|
Рис. 2.3 |
|
|
|
|
|
|
|
|
Рис. 2.4 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
9 |
|
|
|
|
|
|
|
svmax=max(s1v1);
svmin=min(s1v1);
t=4:0.25:7 % Назначение последовательности t, которая % устанавливает центры ячеек для построения гистограмм. hist(s1v1,t)% Построение гистограмм
Для получения линейного графика (рис. 2.4) вместо последней строки надо написать:
s1v1h=hist(s1v1,t) % Формирование гистограммы plot(t,s1v1h) % построение графика гистограммы
Коробочковая диаграмма
Коробочковая диаграмма (boxplot) – способ представления выборки в виде одной или нескольких коробочек с рисками (усами).
boxplot(X) выдает график, состоящий из прямоугольных коробочек и рисок для каждого столбца матрицы Х. Коробочка имеет линии на значениях нижнего квартиля, медиане и верхнего квартиля. Риски представляют собой линии, расположенные за концами прямоугольника и показывающие основное распространение остальных данных. Выбросы – это данные, имеющие значения за пределами концов рисок. Если за пределами рисок данных нет, то на нижней риске ставится точка.
boxplot(x,G) выдает график, состоящий из прямоугольных коробочек и рисок для вектора х, образующего группы посредством G – переменной группировки, определенной как вектор, строковая матрица или матрица строк.
boxplot(...,'Param1', val1, 'Param2', val2,...) задает дополни-
тельные (необязательные) пары имя/значение параметра. В табл. 2.1 описаны некоторые параметры и их значения.
|
Таблица 2.1 |
|
|
|
|
Наименование параметра |
Значения параметра |
|
'notch' |
'on' для включения зазубрин (по умолчанию 'off') |
|
'whisker' |
Максимальная длина риски в единицах межквартильного |
|
размаха (по умолчанию 1,5) |
||
|
||
|
Буквенный массив или матрица строк, содержащие |
|
'labels' |
обозначения столбцов (если Х – матрица, то обозначения |
|
|
по умолчанию – это номер столбца) |
На графике с зазубринами зазубрины представляют робастную оценку неопределенности по поводу медиан при сравнении коробочек друг с другом. Коробочки, зазубрины которых не пересекаются (не накладываются), указывают, что медианы данных двух групп отличаются при уровне значимости 5 %.
10