

2 Вида планирования:
Оптимизация по времени поиска цилиндра
Оптимизация по времени поиска записи на дорожке
Цели и критерии планирования.
Критерии:
Пропускная способность
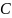
Среднее время ответа на запрос
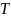
Разброс (дисперсия) времени ответа
Цели:
Максимизировать
Минимизировать
Минимизировать
на множестве запросов.
Стратегии оптимизации поиска цилиндра:
FCFS – обслуживание в порядке поступления.
Метод справедливый ( имеет хорошие значения).
и при больших нагрузках неудовлетворительны.
Используется в настольных системах при малых нагрузках.
SSTF – Shortest Seek Time First.
С наименьшим временем поиска – первый.
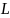 (между следующим запросом и текущим
положением) минимальный.
(между следующим запросом и текущим
положением) минимальный.
и имеют лучшие значения.
велика.
Обращения к МД имеют тенденцию концентрироваться о области текущего расположения МГ.
Результат – запросы, далеко отстоящие от центра концентрации, игнорируются.
Используются в системах пакетной обработки.
Плохо подходит для интерактивных систем.
SCAN – сканирование.
Каретка с МГ движется от внешнего цилиндра к внутреннему, затем обратно, обслуживая запросы по пути следования.
– высокая
– низкая
– лучше второй, но имеется дискриминация некоторых запросов
Возможно бесконечное откладывание.
N-Step-SCAN
Модификация SCAN
Каретка с МГ движется туда-сюда, но обслуживаются запросы, накопленные к моменту изменения направления движения.
– высокая
– низкая
– мала (нет бесконечного откладывания запросов)
Но имеет место дискриминация крайних дорожек (цилиндров), т.к. разворот может произойти раньше.
C-SCAN – циклическое сканирование
Рабочий ход только в одном направлении, затем резко переходим к началу (либо к первому запросу).
Исключает дискриминацию крайних цилиндров.
Возможна модификация (In-Step-C-SCAN).
Схема Эшенбаха – движение происходит так же, как в схеме C-SCAN, но при этом обслуживаются запросы, расположенные на одной дорожке (даже если есть обращения к другим дорожкам цилиндра), остальные запросы откладываются на следующий раз.
Оптимизация по времени поиска записи – SLTF (Shortest Latency Time First). Запросы упорядочиваются в соответствии с угловым положением секторов, на которых расположены записи. Аналог SSTF.
Конфигурирование ВС.
Возможные узкие места:
Недостаточная мощность контроллера. => Перераспределение МД
Недостаточная пропускная способность отдельного канала. => Переключение части контроллеров на другие каналы.
Организация в/в и файловые системы.
Файл – физическое представление информации о совокупности объектов.
Файл состоит из записей. Свойства объектов кодируются в полях наших записей.
Система управления файлами (СУФ) – часть ОС, реализующая работу с файлами.
Должна обеспечивать:
Эффективное распределение внешней памяти.
Гибкий доступ к данным.
Максимальную маскировку механизмов реализации СУФ от пользователей (скрывается специфика внешних устройств).
Максимальная независимость от типа ЭВМ и ОС.
Возможность совместного использования общих файлов.
Безопасность и целостность файлов (информации).
Эффективная работа с файлами (согласование работы по скоростям – буферизация и кэширование).
Именование объектов (файлов).
Пользователи создают свои пространства имен для разделяемых файлов.
Имя файла определяет функцию отображения адресов в объекты внутри файла.
СУФ хранит управляющую информация о файлах в справочниках.
Содержание справочника:
Пользовательское имя файла.
Уникальный идентификатор файла.
Местоположение файла.
Тип доступа к объектам, разрешенный пользователем.
Дата последнего использования.
Дата создания файла.
Частота использования.
Обращение к записям файла:
По имени файла находим UID.
Определяется местоположение файла.
Реализуется доступ к записям.
Генерация команд в/в.
СУФ имеет многоуровневую структуру:
Система в/в – нижний уровень.
Система в/в (СВВ) – реализует специфику работы с конкретным внешним устройством (ВУ).
Составляющие:
Иерархическая система каналов.
Устройства управления внешними устройствами.
Устройства в/в.
Программы канала, управляющие в/в.
Реализует:
Стандартную связь ЦП и аппаратуры в/в.
Управление внешними устройствами с помощью асинхронным процессов.
Контроль ошибок.
Локализация на своем уровне специфики работы с ВУ.
Базисная система управления файлами (UID – местоположение).
Осуществляет преобразование UID в местоположение.
Реализует команду расчленения файла на более мелкие подфайлы.
Размещение файлов в пределах тома.
Логическая СУФ (имя – UID).
Реализует команды:
Создать файл (имя, размер, имя тома).
Уничтожить файл (имя).
Открыть файл (имя).
Закрыть файл (имя).
Читать запись (имя, что читать, сколько читать, куда читать)
Писать запись (имя, что, сколько, куда)
Методы доступа к объектам файла.
Логические методы, которые могут отличаться от физической реализации.
Характеристики:
Тип синхронизации
Пользовательская
Базисные МД.
Команды:
read
write
check (для синхронизации)
Системная
С очередями.
Команды:
put
get
Возможна буферизация записей (при чтении/записи).
Тип доступа
Последовательный
Прямые (адрес блока/записи)
Задача пользователя – правильно интерпретировать блок.
Произвольный
СУБД – расширение СУФ.
Принципы оценки производительности систем.
Различают 3 цели исследования производительности:
Оценка для выбора ВС среди альтернатив для приобретения.
Планирование производительности – оценка производительности разрабатываемой ВС (компонента ВС) (Проектирование с заданной производительностью)
Контроль производительности – сбор и накопление данных о работе имеющейся ВС для прогноза влияния на производительность каких-то планируемых изменений.
В общем случае для оценки производительности необходимо:
Предсказать характер прикладных задач, решаемых на ВС.
Предсказать нагрузку на ВС.
Возможные направления использования результатов оценки:
Наилучшее конфигурирование ВС.
Подбор стратегий управления ресурсами ВС.
Настройка параметров ВС на требования пользователей.
Показатели производительности:
Средний цикл выполнения заданий – время от начала поступления задания в систему до его выполнения и выдачи результатов – для систем пакетной обработки.
Время ответа – время от момента ввода некоторых данных с клавиатуры до момента начала ответа – для диалоговых систем.
Время реакции системы – время от момента ввода данных до момента выделения времени ЦП – для систем реального времени.
Дисперсия времени ответа/времени реакции – мера разброса от среднего – мера предсказуемости.
Пропускная способность – количество задач/запросов/транзакций в единицу времени.
Загрузка ресурсов ВС – неоднозначный показатель – для дорогих устройств.
Методы оценки производительности:
Измерение элементарных времен – измерение аппаратной производительности – количество команд в единицу времени.
Измерение времени выполнения смеси команд – в зависимости от характера задач смесь различна.
Измерение времени образцовой программы – типичной для данной системы – используются для построения оптимизирующих компиляторов.
Измерение времени выполнения измерительной программы, типичной для решаемого класса задач – применяется при миграции на другие ВС или ОС.
Измерение времени выполнения синтетических программ – совмещают черты образцовых измерительных – используется при смене ВС (с другой архитектурой).
Аналитические модели – математическая формализация процесса решения задач – позволяют быстро и наглядно увидеть плюсы и минусы ВС.
Этапы моделирования:
Анализ системы
Формализация (идеализация объекта) – решаем вопрос об адекватности
Решение (аналитические соотношения, численные результаты) – оба способа могут не подойти (возврат на этап анализа)
Интерпретация результатов – не всегда возможно (ограничение диапазона значений, для которых работает формализация, возврат на этап анализа)
Среди аналитических моделей различают:
Вероятностные модели (событийные) – дерево исходов поведения системы
Модели систем массового обслуживания – потоковые модели, изучается влияние интенсивности потоков на вычислительные характеристики
Конвейерные модели
Модели взаимно дополняют друг друга.
Имитационное моделирование ВС – позволяет исследовать трудно формализуемые моменты при аналитическом моделировании.
Все эти методы позволяют выявить:
Узкие места системы
Насыщение ресурсов
Различают пиковую и реальную производительность.
Пиковая достигается при:
Бесконечной последовательности несвязанных команд, которые не конфликтуют при доступе к памяти.
Все операнды выбираются из КЭШа первого уровня.
Все команды выбираются из КЭШа команд первого уровня.
При оценке производительности на тестах возникает 3 проблемы:
Проблема достоверности оценок (выбор показателей, которым можно доверять)
Проблема адекватности полученных оценок (выбор тестов, которые дадут наиболее точную характеристику вычислителя при решении заданного класса задач).
Проблема интерпретации оценок (правильное истолкование результатов тестирования).
Существует 3 группы тестов:
Тесты производителей средств вычислительной техники (СВТ)
Сравнение однотипных компьютеров. Оценивают производительность ВС с одной архитектурой, но с различными средствами реализации.
#Тест ICOMP – сравнение ВС с архитектурой x86 (Intel, AMD, IBM)
Стандартные тесты
Создается независимыми аналитиками. Позволяет сравнивать производительность ВС с различной архитектурой.
#Тест Linpack (Джек Донгарра) – тест сравнивает многопроцессорные ВС при решении научных задач
ТОП-500
#SPEC (Standard Performance Evaluation Corporation) – группа экспертов от различных производителей средств вычислительной техники
#TPC (Transaction Processing Performance Council) – тестирование класса задач обработки данных в ИС.
Пользовательские тесты
Учитывают конкретную специфику применения ВС.
ПТ создаются крупными компаниями (интеграторами), которые специализируются на внедрении компьютерных технологий.
ПТ применяются для выбора ВС и ПО для решения определенных прикладных задач.
Тест Linpack.
Параметры теста:
Размерность задачи (порядок матрицы – 100x100, 1000x1000)
Точность вычислений (формат значений элементов матрицы) – одинарная, двойная
Способ компиляции (с оптимизацией/без оптимизации)
Применение/нет оптимизирующей библиотеки специальных функций.
Тест SPEC.
1989, 1992, 1995, 1998, 2000,…
Включает 2 тестовых набора:
Сint – целочисленная арифметика
Cfp – арифметика с плавающей точкой
Оба набора включают в себя несколько программ (n и m), написанных либо на C, либо на Fortran.
Cint:
Задача из теории сетей.
Интерпретатор языка Lisp.
Задача логического проектирования.
Утилита упаковки текстов.
Компилятор языка C.
Операции со строками и столбцами электронной таблицы.
…
N
Индекс быстродействия SPECratioI(i) = время выполнения i задачи на ВС.
Cint = среднее геометрическое всех индексов.
Cfp:
Программа схемного проектирования
Программа моделирования термодинамики ядерного реактора (методом Монте-Карло)
Задачи квантовой химии и физики
Решение уравнений Максвела
Решение уравнений Навье-Стокса
…
M
Индекс вычисляется так же (SPECrationFp(i)).
Тест TPC.
Используется при оценке производительности при работе с БД.
Различают тесты TPC-A, B, C, D
Оценка – соотношение стоимость (заданного периода эксплуатации)/производительность (max число транзакций в единицу времени).
Тесты отличаются характером задач.
TPC-A – оценивает задачи, в которых используются транзакции типа «дебет-кредит» (задача «операционный зал»).
TPC-B – похож на A (использует те же транзакции), но стоимость не включает стоимость конечных терминалов.
TPC-C – задачи OLTP (On-line Transaction Processing) – функционирование нескольких филиалов банка/множества складов, на которых имеется K участков, каждый участок имеет множество клиентов (1000-10000), каждый склад имеет на участках более 10000 наименований товаров. Операции агрегирования, селекции и т.д.
TPC-D – позволяет оценивать эффективность систем поддержки принятия решений. Поддерживает операции соединения, селекции, агрегирования, сортировки.
Аналитическая отчетность.
WebStore
Позволяют оценивать эффективность веб-ориентированных сервисов.
И еще очень-очень много тестов…
Защита объектов ОС.
Механизмы защиты различны для различных частей ОС.
 :
:
Аутентификация – идентифицирует субъект
Авторизация – что может делать субъект
Аудит – что сделано
Задача защиты – организовать защиту информации, разделив пространство адресов различных устройств на области (ОЗУ, файлы).
Каждая область должна быть защищена от незаконного изменения, чтения со стороны окружения.
2 проблемы защиты:
Эффективность защиты
Эффективность доступа
Области адресного пространства защищаются с помощью «стен», окружающих адресное пространство и эти стены должны иметь «ворота».
Ворота – это коммуникационное средство, через которое внешний мир получает доступ к объектам внутри стен.
Ворота должны охраняться (должны иметь механизм контроля доступа к объектам).
Адресный механизм объектов в ОЗУ – ворота к данным.
Стены и ворота для файлов – система управления файлов.
Способы возведения стен:
Права доступа – описываются в механизмах адресации объектов ОЗУ (СУФ)
Обеспечение секретности пути к объекту. Доступ осуществляется через проводника, знающего путь к объекту (не является абсолютно непроницаемым).
Применение методов кодирования. Все объекты доступны, но в закодированном виде. Ворота – ключ и дешифратор.
Реализация защиты
Часто реализуется с помощью мониторов защиты. Можно реализовать монитор для каждого объекта. МЗ реализуется для классов сходных объектов.
Домены и возможности
В ОС различают:
Активные субъекты
Пассивные объекты
Субъект может превратиться в объект (возможность смены ролей).
Обычно субъекты получают права в отношении некоторых субъектов.
Полезно выделять классы прав доступа в отношении тех или иных объектов в домены.
Субъект:
Админ ОС | Домен 1
Простой смертный | Домен 2
Субъект идентифицирует себя в некотором домене, входит в него и получает определенную возможность доступа.
Описание статуса защиты
Множество доменов
Множество объектов
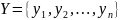
Описание статуса:
Статус защиты – отображение
 – атрибуты доступа к некоторому объекту
в конкретном домене.
– атрибуты доступа к некоторому объекту
в конкретном домене.
Если отображение
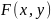 к объекту зависит только от имен
к объекту зависит только от имен
 и
и
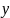 ,
то описать статус можно с помощью
матрицы.
,
то описать статус можно с помощью
матрицы.
Матричная модель менее гибкая, чем отображение.
При использовании процедур в элементах матрицы, зависящих от внешних параметров, гибкость восстанавливается.
Основная проблема – расширение и сужение прав доступа.
Идея реализации – сделать из доменов объекты и обращаться с ними соответствующим образом.
Надо добавить дополнительные атрибуты для управления содержанием доменов.
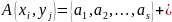
Управление доменом
Владелец объекта
Признак копирования прав доступа
Правила изменения статуса защиты:
Правила расширения:
Домен
 может скопировать атрибут доступа
может скопировать атрибут доступа
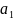 в элемент матрицы
в элемент матрицы
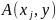 в том случае, если атрибут
находится в элементе матрицы
в том случае, если атрибут
находится в элементе матрицы
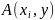 в отношении этого объекта, и для него
установлен признак копирования.
в отношении этого объекта, и для него
установлен признак копирования.Домен может передавать атрибуты доступа и устанавливать признак копирования элементу матрицы в том случае, если имеет атрибут владелец по отношению к объекту .
Правила сужения:
Домен может удалить атрибуты доступа из элемента , если имеет атрибут управления над
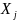 (как над объектом).
(как над объектом).Домен может удалить атрибуты доступа из элемента , если домен имеет атрибут владелец по отношению к объекту и домен не имеет защищенного доступа к объекту .
Дополнительно необходимо:
Обеспечить связь субъектов и доменов.
Обеспечить возможность перемещения субъектов от домена к домену.
Обеспечить возможность создания новых доменов.
Обеспечить возможность удаления ненужных объектов, доменов из описания статуса защиты.
Схемы реализации защиты.
Требования к схеме:
Необходимо минимизировать накладные расходы.
Рационально использовать ресурс памяти.
Гибкость описания (доступ, деформация).
Схемы:
Таблица описания защиты
Минус – имеет большие размеры.
Операции в таблице – объединение объектов или доменов в группы.
Списки возможностей – множество списков строк, в одной строке – все объекты, принадлежащие конкретному домену.
Списки управления доступом – множество списков столбцов.
Механизм «Замок-Ключ»
Криптосистема.
Все объекты доступны, но в зашифрованном виде.
2 преобразования – шифрование и дешифрование.
Шифрование с 1 ключом – DES
Шифрование с 2 ключами – RSA
Криптоустойчивость – сохранение свойств секретности при известном алгоритме и тексте.
Повторяющиеся группы ОТ – будут наверняка повторяться в ШТ.
Для устранения используется метод сцепления.
Шифрование с 2-мя ключами (открытыми ключами):
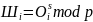 – большое число
– большое число

s – публичный ключ
t – секретный ключ
Многопроцессорные ВС.
Количество потоков данные (один, много).
Количество потоков команд (один, много).
MIMD (Multi instructions multi data).
Связь с ОП:
С сильной связью (SMP)
Со слабой связью (MPP, вычислительные кластеры)
Модель программирования.
UMA – Unified Memory Access
Все операнды и команды равноудалены от всех ЦП
Модель UMA – при разработке приложения не нужно заботиться о том, где расположены данные и команды.
SMP, CHP, CC-NUMA.
NUMA – Non UMA – неоднородный доступ к памяти.
Распределение по узлам. Ближняя и дальняя память. Отличаются временем доступа.
Разработка приложения зависит от расположения данных.
MPP, вычислительные кластеры, средства программирования MPI
SMP:
Многоуровневая память.
Механизмы обеспечения когерентности – одинаковость различных копий 1 экземпляра данных.
MPP:
«рисунок»
CMP – Cellular Multi Processing
CMP – Chip MP (многоядерный процессор)
CC-NUMA (Cache Coherent NUMA)
Для ускорения доступа к объектам все данные кэшируются => многоуровневая система памяти.
КЭШ:
Общий/раздельный
Со сквозной и обратной записью
КПО, ПАК, МАК
SMP, CMP, CC-NUMA, COMA (Cache only memory access)
Протоколы когерентности могут быть реализованы:
Явно (программист)
Аппаратно
Аппаратно-программная реализация
Реализация многоуровневой памяти в многопроцессорных ВС характеризуется следующими признаками:
Способ реализации протокола когерентности
Типы разделяемых объектов многоуровневой памяти (слово, кэш-строка, страница, сегмент)
Модель состоятельности – определяет последовательности доступа к памяти (SRSW, MRSW, MRMW)
Политика обеспечения когерентности
Модификация
Объявление несостоятельности
Управление распределением памяти и размещением данных
Модели состоятельности памяти.
Строгая модель состоятельности – каждая операция возвращает последнее значение.
Последовательная модель – все ЦП соблюдают один порядок выполнения операций чтения/записи. Процессор, выполнивший операцию записи, ждет подтверждения от других ЦП (об объявлении копии несостоятельной либо обновленной).
Слабая модель состоятельности – вводится разграничение между разными способами доступа к данным (обычный и синхронизированный). Разрешается рассинхронизация данных все точек синхронизации.
Свободная модель – уточняет слабую, вводятся скобки, в рамках которых осуществляется синхронизированная обработка (acquire и release).
Неторопливо-свободная – в рамках нее модификация разделяемой памяти откладывается до непосредственного обращения к памяти (при открывании синхронной скобки).
Нетерпеливо-свободная – модификация происходит во время закрытия синхронного доступа.
Реализация когерентности:
Явная – программная
Неявная – аппаратная
Методы реализации когерентности для сосредоточенной памяти.
Когерентность реализуется между ОЗУ и ближайшим к ОЗУ КЭШем.
Необходим механизм слежения за операциями процессора над данными.
Протокол MESI (Modified, Exclusive, Shared, Invalid) – состояния строк кэша.
M – строка КЭШа модифицирована и доступна к чтению и записи только в данном процессоре.
E – строка, которая была монопольно скопирована, доступна в данном ЦП и ОЗУ.
S – строка, которая была множественно скопирована в несколько ЦП, она доступна для чтения и записи в данном процессоре, в других процессорах и в ОЗУ.
I – строка, невозможная к использованию.
Для управления режимом доступа используется бит WT – бит Write Through (1 – сквозная запись, 0 – обратная запись)
Изменения состояния строк КЭШа при выполнения чтения и записи.
Табличка
Заполнение КЭШа только при промахе чтения
При промахе записи транзакция записи реализует изменение в ОЗУ.
Сигнал управления состояний строк других процессоров.
INV = { 0, 1 }
Табличка
Реализация механизма когерентности с распределенной памятью:
CC-NUMA, CMP, COMA (единое адресное пространство)
При промахе в кэш исходного узла инициируется запрос к резидентной памяти – памяти с адресуемым объектом.
Каждая строка резидентной памяти имеет список узлов, скопировавших данную строку.
Запись:
Измененная строка некоторым ЦП посылается в резидентную память (узел).
Резидентный узел посылает измененную строку всем узлам, разделяющим строку (для изменения содержимого КЭШей).
Резидентный узел ожидает подтверждения от узлов о доставке изменений.
Резидентный узел разрешает продолжение вычислений узлу, выполнившему вычисление.
Очень трудоемкий алгоритм.
Более совершенный алгоритм DASH.
Протокол когерентности DASH для распределения памяти.
Каждая резидентная строка ОЗУ имеет 3 глобальных состояния:
NC – не кешированная – копии строки нет удаленных узлах, но может быть в резидентном узле.
RS – удаленно-разделенная – копии строки имеются в удаленных узлах.
RM – удаленно-измененная – строка изменена операцией записи в нерезидентном узле.
Локальные состояния строк КЭШа (3 штуки):
NU – невозможная к использованию.
S – разделяемая – строка КЭШа не изменена и ее копии имеются в других узлах.
M – измененная – строка изменена операцией записи в данном узле.
Чтение:
Чтение из своего кэша при локальном состоянии S/M
При промахе чтения или локальном состоянии NU – посылается запрос «Промах чтения» в резидентный узел.
При глобальном состоянии NC/RS копия строки посылается в запрашиваемый узел.
При глобальном состоянии RM запрос из резидентного узла посылается в узел, содержащий измененную строку. Данный узел возвращает измененную копию строки резидентному узлу, устанавливается глобальное состояние RS. Резидентный узел возвращает запросившему узлу измененную строку.
Все узлы, разделяющие строку КЭШа, организуют список.
<рисунок>
Право записи имеет головной узел.
Перед выполнением операции записи узел S переместиться.
Запись:
При локальном состоянии M вычисления продолжаются сразу после выполнения операции записи.
При локальном состоянии NU/S операция записи начинается с посылки в резидентный узел запроса на захват строки в исключительное пользование. Ожидается подтверждение о переводе локального состояния строки в состояние NU (во всех узлах списка).
При глобальном состоянии строки NC строка посылается в запросивший узел, узел продолжает вычисления.
<таблица>
Применение явной когерентности обусловлено:
Слишком большим временем реализации.
Слишком высокие аппаратные затраты на реализацию.
SCI – кэши в узлах строятся на памяти резидентного узла (и кэширует удаленную память)
<у Арсентия>
Средства виртуализации ВС.
Аппаратные – доменная архитектура многопроцессорных ВС – SMP архитектура (IBM, HP).
Доменная архитектура допускает разбиение ВС на системные разделы.
Системный раздел (один или несколько серверов-лезвий) содержит:
Свое подмножество ЦП.
Собственный объем оперативной памяти.
Ввод/вывод.
Собственный экземпляр ОС.
Плюсы:
Изоляция ошибок (ОС, приложений) и пределах СР.
Отсутствие конкуренции за ресурсы между СР.
Упрощение управления системой ВС. Снижение эксплуатационных расходов.
Упрощение масштабирования серверных платформ (возможна кластеризация приложений).
Выполнение различных этапов создания и эксплуатации приложения на одной технической платформе.
Разбиение на системные разделы:
Статически – до запуска ОС.
Динамически – во время работы ОС.
Разбиение на прикладные разделы на уровне ОС включает:
Свой набор ЦП.
Свой объем ОЗУ.
Свой ввод/вывод.
 для достижения QoS для приложения.
для достижения QoS для приложения.
Системный раздел может быть разбит на несколько прикладных.
Следующий уровень виртуализации (разбиения) – разбиение на классы пользователей/приложений.
Ограничения на использование ресурсов:
Объем виртуальной памяти.
Пропускная способность сетевого соединения.
Объем дисковой памяти.
Мультипроцессорные ОС.
Для многопроцессорных ВС с UMA-моделью (SMP, CC-NUMA, CMP).
Центральная проблема – взаимодействие.