

Морфологический анализ.
под морфологическим анализом понимается обработка словоформ вне связей с контекстом.
Функцией морфологического анализа является идентификация каждой текущей словоформы и приписывание ей комплекса морфологической информации служащей в дальнейшем входной информацией для следующего этапа.
Алгоритмы морфологического анализа (ма).
декларативный МА (простейшие операции поиска в словаре).
процедурный МА.
Обобщённый алгоритм процедурного МА.

1-ый этап:
А не принадлежит ли текущая словоформа к числу неизменяемых, например, «ножницы».
2-ой этап:
В каждой входящей словоформе справа налево, производится отсечение аффикса, в соответствии с таблицей аффиксов. Также, лингвисты используют эвристики, например:
Аффиксы полных прилагательных включают аффиксы кратких прилагательных.
3-ий этап:
При поиске производится посимвольное сравнение.
Проблемы:
Омонимия:
Чередование согласных.
4-ый этап:
Склеивание отдельных словоформ (предсинтаксическая фильтрация):
будем строить → построим
В настоящее время разработаны очень хорошие алгоритмы МА, позволяющие распознать около 99% морфологических основ русского языка.
Синтаксический анализ (сиа).
Задача СИА заключается в том, чтобы, используя морфологическую информацию, полученную на этапе МА и сведения из словаря, построить синтаксическую структуру входящего текста рассматриваемого предложения.
Пусть:
x– некоторая непустая цепочка (последовательность словоформ),
X– множество точек (вхождений словоформ).
Тогда, произвольное бинарное отношение →X, при котором граф <→X> является деревом, называют отношением зависимости или подчинения.
Само дерево <→X> называют деревом зависимости.

( β зависит от α, α влечёт β)
Размеченное дерево зависимостей для цепочки x– это четвёрка:
<→, X, Z, Ψ>
→ - дерево зависимости
Х – множество вхождений словоформ.
Z– конечное множество, элементами которого являются СИО.
Ψ– отображение множества дуг.
Алгоритмы сиа.
(основаны на концепции фильтров, то есть правил, которые выделяют правильные и запрещённые конструкции).
В отличие от МА, не существует универсального алгоритма СИА для русского языка, синтаксис русского языка семантичен, а семантика синтаксична.
Обобщённый алгоритм СИА.
Этапы СИА:
СИА всегда начинается с процедуры установления первых трёх отношений:
предикативные
комплетивные
обстоятельные
Для этого в предложении выделяются словоформы не входящие в различные обороты: причастные, деепричастные и придаточные предложения. Эти словоформы образуют основной уровень предложения.
Среди этих словоформ в любом месте предложения выделяются предикаты, то есть словоформы, имеющие МУ.
Для каждого предиката из синтаксической зоны МУ выделяются и последовательно обрабатываются соответствующие ему групповые, ядерные и индивидуальные МУ.
Для каждого индивидуальной МУ определяется список кандидатов, которые удовлетворяют требованиям МУ в части речи, падеже и семантических категориях (см. таблицу МУ).
Информация о найденных отношениях запоминается.
С помощью отсеивающих фильтров, которые устраняют все словоформы (которые не могут быть подчинёнными для каждого предиката), осуществляется формирование матрицы кандидатов для каждого столбца каждой индивидуальной МУ.
Устанавливаются обстоятельственные синтаксические отношения (аналогично, но с другими фильтрами) и определительные отношения.
Фильтры необходимы, например:
Тетрадь лежит на столена четырёх ножках.
После обработки основного уровня предложения обрабатывается вспомогательный.
Пример:
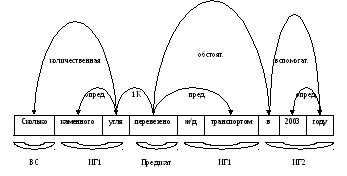
Построение VиG(как транслятор разметит синтаксическое дерево в семантический граф) для лексического компилятора. Построение словарной компоненты.
G– используем декларативный способ хранения информации.
V– БНФ.
Выделяем предикат: перевезено
Выделяем именные группы:
Именная группа 1: каменного угля
Именная группа 1: железнодорожным транспортом
Именная группа 2: в 2003 году
Вопросительное слово: сколько
Все версии предложения из этих слов:
<предложение> ::= <ВС><ИГ1><П><ИГ1><ИГ2> | <ВС><ИГ2><П>{<ИГ1>} | …
Если несколько предложений, то требуется тип:
<предложение> → <вопросительное_предложение>
<G> ::= <предложение_типа_вопрос> | <предложение_типа_сообщение>
То есть синтаксический анализатор.
В конце:
<ИГ1> ::= <прилагательное><существительное>
<ИГ2> ::= <предлог><число><существительное>
V:
<описание_словаря> ::= <имя_словаря>{<тело_словаря>}
<имя_словаря> ::= QST|PREDIC|CON|CHAR|PRE|NUM
где:
QST– вопросительное слово,
PREDIC– предикаты,
PRE– предлоги,
NUM– числительные, и т. п.
<тело_словаря> ::= <номер_словаря><словоформа><словарная_статья>
<словарная_статья> ::= <словарная_статья_вопросительных_слов> <словарная_статья_предикатов><словарная_статья_существительных(понятий)> | …
<словарная_статья_понятий> ::= <род><число>{<падеж>} {<семантическая_категория>}<семантический_признак>
<род> ::= М
Если в предложениях присутствует только мужской род, в словаре указываем лишь его.
<число> ::= E
Подразумевается единственное число, например, 2003.
<падеж> ::= Р | Тв | Предл
Указываются только присутствующие падежи.
и т. д. (предикат – расписывается его семантическая МУ).
К к/р:
Тематика предложений:
Сдача экзамена
Диагностика компьютера
Покупка компьютера
Бронирование билета
Тип предложений:
Вопрос
Сообщение
Повествовательное
Пример предложений:
Гражданин сдаёт экзамен по курсу ИИ в аудитории 406 12-ого числа.
Срочно купи компьютер марки iRU.