

33. Марковский пульсирующий процесс фазного типа ph-mrp вводится для анализа умных систем с непульсирующей загрузкой порта.
Чтобы ввести процесс PH-MRP, необходимо, во-первых, рассмотреть распределение фазного типа PH. В Марковской цепи непрерывного времени с r кратковременными состояниями и одним (r+1)-ым абсорбирующим (поглощающим) состоянием полагаем, что вступающий в абсорбирующее состояние процесс мгновенно перескакивает к кратковременному состоянию j, j = 1, 2, … , r, с вероятностью j. Распределение PH определяется как распределение времени между посещениями абсорбирующего состояния и характеризуется как (, T), где T является матрицей, которая представляет собой несократимую rr матрицу темпов перехода среди кратковременных состояний. Вектор-строка с компонентом j называется начальным вектором вероятности. Вектор-столбец T, определенный как
T = Te, (55)
представляет темп перехода от кратковременных состояний к абсорбирующему состоянию, где e есть единичный вектор-столбец, у которого все компоненты равны 1. Говорят, что распределение PH должно быть в фазе j, если Марковский процесс, лежащий в основании этого процесса, находится в состоянии j. Распределение PH включает гиперэкспоненциальное (Hn), Эрланговое (Ek), экспоненциальное (M) и т.д., как особые случаи. Пульсирующий процесс с распределением промежутков времени между поступлениями вызовов согласно распределению PH называется пульсирующим процессом фазного типа (PH-RP).
Во-вторых, модифицируем вышеуказанную Марковскую цепь для того, чтобы иметь n абсорбирующих состояний с вероятностью перескоков ij от адсорбирующего состояния i, i = r + 1, r + 2, … , r + n, к переходному состоянию j, j = 1, 2, … , r. Отсюда следующие один за другим посещения адсорбирующих состояний составляет процесс PH MRP, в котором промежутки времени между указанными посещениями соответствуют распределениям PH, в общем, не идентичными, но коррелированными друг другу. Говорят, что процесс PH MRP должен быть в фазе j, если Марковский процесс, лежащий в основании этого процесса, находится в состоянии j. Процесс PH MRP характеризуется представлением (, T, T ). Матрица , размером n r, с компонентами ij и матрица T, размером r n, являются расширениями векторов, рассмотренных выше. Отсюда мы получим соотношение:
T е = Te. (56)
Процесс PH MRP включает процесс PH RP, как особый случай, и может быть использован для представления подвижных пульсирующих и не пульсирующих процессов появляющихся в современных телекоммуникационных системах, таких как ATM для BISDN. Темп поступления (усредняющий каждое распределение PH) задается как
= T е, (57)
где – вектор стационарной вероятности от T + T , удовлетворяющий условиям
(T + T ) = 0, е = 1. (58)
Модель системы PH-MRP/M/s(m), в которой вызовы поступают в потоке PH-MRP с представлением (, T, T ), характеризуется процессом квази-рождения и гибели (QBD) с бесконечно малым генератором. Процесс QBD является расширением процесса B-D, описанного ранее, для которого компоненты расширяются до формы матрицы с заданными уровнями от 0 до s + m.
Мультисервер со
схемой частично-преимущественного
права на приоритет с порогом n
M![]() PH-MRP/M1,M2/s(,0)
PPP(n)
работает следующим образом. Когда все
s
серверов
заняты, вызов по входу с запаздыванием
ожидает в бесконечно большом буфере с
порядком обслуживания FIFO.
Вызов по входу с потерями прерывает
обслуживание вызова по входу с
запаздыванием, если k
(1
k
n)
вызовов по входу с запаздыванием
находятся в обслуживании, в противном
случае теряется. Значение n
называется порогом преимущественного
права на приоритет. Необходимо изучить
порядок определения пространства
состояний, порядок разбиения этого
пространства на уровни и подуровни,
порядок моделирования системы процессом
с бесконечно малым генератором QBD
и выполнение надлежащих измерений.
PH-MRP/M1,M2/s(,0)
PPP(n)
работает следующим образом. Когда все
s
серверов
заняты, вызов по входу с запаздыванием
ожидает в бесконечно большом буфере с
порядком обслуживания FIFO.
Вызов по входу с потерями прерывает
обслуживание вызова по входу с
запаздыванием, если k
(1
k
n)
вызовов по входу с запаздыванием
находятся в обслуживании, в противном
случае теряется. Значение n
называется порогом преимущественного
права на приоритет. Необходимо изучить
порядок определения пространства
состояний, порядок разбиения этого
пространства на уровни и подуровни,
порядок моделирования системы процессом
с бесконечно малым генератором QBD
и выполнение надлежащих измерений.
Изучите особые случаи на примерах управления приемом вызова в сетях ATM, где пакетная коммутация данных (с запаздыванием) и цепь коммутируемых телефонных вызовов (без запаздывания) интегрируются со схемой PPP и подвергаются s процедурам CLADs (сборки- разборки ячеек).
34.
35. М арковская
модуляция Пуассоновского процесса
(MMPP)
представляет собой сдвоенный Пуассоновский
процесс с поступающими скоростями,
зависящими от фаз (состояний), которые
составляют Марковскую цепь непрерывного
времени. Модуляция MMPP
является особым случаем процесса
PH-MRP
и, благодаря ее податливости (удобности),
широко используется при моделировании
бурлящих потоков транспортной нагрузки,
таких как пакетированный речевой сигнал
в сетях ATM.
Поток MMPP
может быть проанализирован с использованием
метода аналитических матриц. На рис.14
показан двухфазный MMPP,
как самый простой случай, имеющий
Пуассоновский темп поступления j
в фазе
j,
j
= 1,2, которая
появляется поочередно с экспоненциально
распределенным временем жизни с
математическим ожиданием rj1.
Это характеризуется как (R,
),
где R
есть бесконечно малый генератор
Марковской цепи, лежащей в основе, а
матрица скорости поступления, определенные
как
арковская
модуляция Пуассоновского процесса
(MMPP)
представляет собой сдвоенный Пуассоновский
процесс с поступающими скоростями,
зависящими от фаз (состояний), которые
составляют Марковскую цепь непрерывного
времени. Модуляция MMPP
является особым случаем процесса
PH-MRP
и, благодаря ее податливости (удобности),
широко используется при моделировании
бурлящих потоков транспортной нагрузки,
таких как пакетированный речевой сигнал
в сетях ATM.
Поток MMPP
может быть проанализирован с использованием
метода аналитических матриц. На рис.14
показан двухфазный MMPP,
как самый простой случай, имеющий
Пуассоновский темп поступления j
в фазе
j,
j
= 1,2, которая
появляется поочередно с экспоненциально
распределенным временем жизни с
математическим ожиданием rj1.
Это характеризуется как (R,
),
где R
есть бесконечно малый генератор
Марковской цепи, лежащей в основе, а
матрица скорости поступления, определенные
как
![]() (59)
(59)
Модель системы MMPP/G/1 позволяет определить функцию распределения виртуального времени ожидания с использованием интегрального уравнения Вольтера. Изучите особенности вычисления виртуального среднего времени ожидания и действительного (настоящего) среднего времени ожидания.
Модель системы MMPP/Ek/1(m) вводится для того, чтобы аппроксимировать модель системы MMPP/D/1(m), применяемой для анализа ATM систем с постоянной длиной ячейки и с размером буфера m.
36.
37. В цифровых сетях интегрального обслуживания ISDN мультимедиа нагрузки на порт, такие как голос, данные, видео и т. д., передаются в форме пакетов. В системе пакетной коммутации стандарта X.25, пакет имеет переменную длину, в то время как в системе ATM для широкополосной сети ISDN пакет становится ячейкой постоянной длины. Так как пакетированный процесс имеет скачкообразно бурлящую природу, то процесс суперпозиции (наложенный один на другой) многих источников становится не пульсирующим. Поэтому процесс MMPP получил широкое распространение при исследовании бурлящих потоков в сетях пакетной коммутации.
М одель
пакетированного голоса (видео) показана
на рис.15 как релейная (ON-OFF
model).
одель
пакетированного голоса (видео) показана
на рис.15 как релейная (ON-OFF
model).
Для одиночного звукового источника полагают, что периоды речевого высказывания и молчания распределяются экспоненциально со средними величинами 1 и 1 , соответственно, а пакеты (ячейки) порождаются за период T в течение речевого высказывания. Отсюда определяют темп поступления , SCV Ca2 и асимметрию Sk.
Бурлящие потоки принято характеризовать индексами дисперсии и асимметрии числа пакетов, поступающих за интервал времени (0, t]. Индексы вводятся как отношения соответствующих центральных моментов к математическому ожиданию поступающих пакетов за время t. Для индексов дисперсии и асимметрии выполняется закон сохранения индексов: индексы единичного релейного источника равны соответствующим индексам суперпозиции процесса поступления пакетов от n независимых источников.
Бурлящий поток (суперпозицию пакетов от n независимых источников) можно аппроксимировать двухфазным процессом MMPP. При этом неизвестные параметры процесса MMPP (темпы поступления вызовов в разных фазах и распределения времени жизни в разных фазах) определяются по измеренным индексам дисперсии и асимметрии бурлящего потока.
Смешанные модели бурлящей нагрузки порта от n независимых источников аппроксимируют 2-фазным процессом MMPP. Полагаем, что суперпозиция n индивидуальных 2-фазных процессов MMPPi образует смешанный 2n-фазный процесс MMPP, который мы вновь аппроксимируем двухфазным процессом MMPP. Ознакомьтесь с моделью MMPP+M/G/1, изучите показатели качества однолинейной смешанной системы обслуживания бурлящего трафика (индивидуальные средние времена ожидания по нагрузкам MMPP и Пуассоновской, соответственно; среднее виртуальное время ожидания процесса MMPP в фазе l, l=1, 2; средние виртуальное и действительное времена ожидания для смешанной нагрузки со схемами приоритета; индивидуальная скорость потери ячеек по нагрузкам MMPP и Пуассоновской, соответственно; виртуальная скорость потери ячеек процесса MMPP в фазе l, l=1, 2).
38-39. Эстафетное кольцо the Token Ring LAN является стандартным протоколом типа последовательного управления доступом к услугам и службам локальной вычислительной сети. В этом протоколе сигнал разрешения передачи, названный маркером, циркулирует между узлами, размещенными по контуру кольца. Узел, имеющий данные для передачи, осуществляет занятие освобожденного маркера и преобразует его в занятый маркер, который и переносит пакет данных по адресу его пункта назначения. После того, как пакет данных был принят стороной пункта назначения, маркер возвращается к исходящему узлу, указанному как порождающая сторона, где он вновь освобождается и начинает опять циркулировать по кругу. Необходимо познакомиться с моделью «ходящего» сервера, уметь определять структурные параметры (среднее значение и дисперсию времени хода, занятие узла и занятие сервера, время цикла и общее время хода по кольцу). Особое внимание здесь следует уделить типам освобождения маркера и особенностям расчета показателя качества работы (симметричная и асимметричная системы) эстафетного кольца.
При расчете показателя качества (среднего времени ожидания для узла j) асимметричной (разнородные условия транспортировки на узле) системы через время хода требуется большой расход машинного времени. Поэтому получают формулу аппроксимации среднего времени ожидания путем введения времени каникул (промежутка времени между посещениями одного и того же узла j) «ходящего» сервера.
Множественный доступ с опросом несущей и разрешением конфликтов CSMA/CD LAN является стандартным протоколом типа параллельного управления доступом в условиях состязаний на общей шине локальной вычислительной сети. Согласно этому протоколу узел, имеющий пакет, передает его после подтверждения неактивного состояния общей шины, не обнаружив несущей на ней. Благодаря задержке распространения несущей, однако, существует возможность конфликта. Если это случается, то конфликтующие узлы ретранслируют пакеты после предрешенного времени. Такая процедура называется операцией (back-off) поддержки прерванной связи.
При расчете показателя качества (среднее время ожидания для узла j) определяют сумму среднего времени доступа благодаря механизму управления доступом CSMA/CD и времени ожидания в очереди на узле j типа M/G/1. При расчете последней составляющей требуется оценка математического ожидания и второго момента первой составляющей для узла j.
40. Возможности точных аналитических решений в теории телетрафика иногда ограничиваются по способности проведения анализа большой размерности в сетях средств сообщения, системах управления коммутацией с комплексом включенных в расписание стратегий управления перегрузкой и управления маршрутизацией и т.д. Поэтому к аналитическому решению может быть приложено компьютерное моделирование, как альтернативное приближение. Моделирование используется не только для тех случаев, когда аналитического решения не получено, но и в тех случаях, где численные вычисления аналитических решений затруднены. На различных стадиях планирования и управления системами телетрафика моделирование используется также
в ситуациях, разъясняющих проблемы телетрафика для того, чтобы внедрить реализацию обратно в системотехнику;
в ситуациях, оценивающих реализацию, чтобы подтверждать системный прикладной диапазон;
в ситуациях, оценивающих ответ на ошибку и переполнение, чтобы определять контрмеры.
Для пункта (1), в системотехнике должно быть более важным получить результат быстро и своевременно, а не тратить впустую время, чтобы в ущерб прибыли преследовать цель получить более высокую точность. Поэтому часто используются модели с ограниченным масштабом имитаций. Такие модели могут быстро строиться и легко изменяться, используя имитационный язык. С другой стороны для пунктов (2) и (3), требуется полномасштабное моделирование, чтобы получить точные характеристики трафика для задания емкости системы.
Н а
рис.16 показан процесс моделирования от
планирования до решения проблемы. На
первом шаге формулируется проблема, и
в системе специфицируются (подробно
обозначаются) мероприятия по ее
претворению в жизнь. Например, в системе
управления электронной коммутацией
мероприятиями вышеуказанной спецификации
являются измерения времени установления
соединения и пропускной способности
системы. Как только проблема описана,
последует системный анализ согласно
заведенному порядку для того, чтобы
получать информацию для моделирования
системы. Модель, основанная на этой
информации, строится для того, чтобы
решать поставленную проблему. Процедуры
вплоть до этого этапа наиболее важные.
а
рис.16 показан процесс моделирования от
планирования до решения проблемы. На
первом шаге формулируется проблема, и
в системе специфицируются (подробно
обозначаются) мероприятия по ее
претворению в жизнь. Например, в системе
управления электронной коммутацией
мероприятиями вышеуказанной спецификации
являются измерения времени установления
соединения и пропускной способности
системы. Как только проблема описана,
последует системный анализ согласно
заведенному порядку для того, чтобы
получать информацию для моделирования
системы. Модель, основанная на этой
информации, строится для того, чтобы
решать поставленную проблему. Процедуры
вплоть до этого этапа наиболее важные.
После того, как построена модель, остается только, чтобы преобразовывать ее в программу для выполнения моделирования. Для этого процесса необходимо составить разумный план для распределения вычислительного времени и памяти для данных и программ, согласно бюджету компьютера. При выполнении моделирования должно быть рассмотрено заданное время исполнения и количество операций, особенно если бюджет для вычисления ограничен.
Когда получен имитационный результат, он используется для оценки реализации и анализа системы в вопросе, о чем идет речь. В этом процессе, это – наиболее важное, чтобы определять выполнено ли предполагаемое моделирование и правильный ли результат получен. Полученные данные используются для того, чтобы анализировать и оценивать систему, чтобы достигать оптимального решения.
Модель при имитации должна абстрактно ощущать систему в заданном вопросе, и быть простой по возможности для того, чтобы облегчить моделирование. В основном рассматриваются два вида имитаций: непрерывные и дискретные. Но моделирование трафика классифицируется как дискретно-случайная имитация. На рис.17 показаны три точки зрения для моделирования при дискретно-случайной имитации: событие, процесс и деятельность.

В зависимости от точки зрения различают три случая моделирования: событийно-ориентированное моделирование, процессно-ориентированное моделирование, деятельно-ориентированное моделирование.
При событийно-ориентированном моделировании имитационная модель формулируется, описывая как события, такие как порождение или завершение (освобождение) вызова, изменяют состояние системы. В этих случаях используются универсальные языки программирования, такие как FORTRAN и PL/1.
При процессно-ориентированном моделировании имитационная модель описывает поведение предмета (вызова), существующего в действительности в рассматриваемой системе. Такая имитация называется еще предметно-ориентированным моделированием, и применяется в случаях, когда имитационные языки, такие как GPSS и SLAM II, используются для описания имитационных моделей.
При деятельно-ориентированном моделировании описывают моменты времени инициации и завершения деятельности, такой как длительность вызова и занятие линии. Это соответствующий метод для моделирования систем, у которых время удержания зависит от состояния системы (количества существующих вызовов). Однако так как имитация выполняется подробным рассмотрением активных действий системы, то время ее исполнения становится длиннее, чем у событийно-ориентированного моделирования.
Программирование выполняется на двух классах языков для моделирования: имитационного языка и универсального языка. Имитационный класс включает языки GPSS, SIMSCRIPT и SLAM II, а универсальный класс включает языки FORTRAN, PL/1 и ALGOL.
Имитационные языки содержат следующие функции: генерацию случайных чисел, исполнение расписаний по времени, сохранение данных, статистический анализ, преобразование выходного формата. Преимущество от использования имитационных языков состоит в избавлении от нужды программировать вышеперечисленные функции, и легкости программирования на однажды сформулированной процессно-ориентированной модели.
Универсальные языки более гибкие, чем имитационные языки. Сверх того, они могут ускорять время исполнения. Выбор языка зависит от таких факторов, как удобство обращения, знания программиста, характеристик модели и т.д.
Наиболее популярным имитационным языком является GPSS (general purpose simulation system) – универсальная имитационная система. Язык GPSS описывает имитационную программу для процессно-ориентированного моделирования, использующего около 40 блоков диаграмм, написанных специальными символами. Перемещение объекта на один шаг согласно диаграмме называется транзакцией (сделкой), которые сцепляются друг с другом по одной из двух цепей: цепь текущего события и цепь будущего события.
Транзакции цепи текущего события, чьи запланированные времена перемещения являются прежде или около настоящего точного времени, сцепляются согласно порядку приоритета или запланированному времени перемещения. Они не могут быть еще перемещены из-за некоторых, еще не выполненных, условий и сохраняются, ожидая перемещения.
Транзакции цепи будущего события, чьи запланированные времена перемещения являются после настоящего точного времени, сцепляются в порядке согласно времени перемещения.
Универсальные языки программирования, используемые при имитациях, реализуют два метода исполнения: метод Марковской цепи и метод отслеживающего (следа) времени.
Метод Марковской цепи, называемый моделью рулетки, прямо имитирует Марковскую цепь, представляющую состояния изменений системы, не считающиеся со временем продвижения вперед. Метод основан на том факте, что состояние системы (количество вызовов) повышается или уменьшается на один, благодаря поступлению или завершению (освобождению) вызова, соответственно.
Метод следа времени отслеживает время эпох, в которые вызов поступил или завершил занятие. Программирование окружающей обстановки предусматривает некоторый календарь событий как макет таблицы событий, которую заполнят в будущем. Обычно время поступления первого вызова записывается в календарь событий как начальное значение. В течение продвижения вперед имитации время эпох поступления следующего вызова или завершения обслуживания вызовов определяются как случайное число, и записывается в календарь. Согласуя календарь, программа отправляет точное время к ближайшему событию и повторяет процесс исполнения имитации.
Метод следа времени можно рассматривать как произвольное распределение промежутков времени и времени обслуживания, и отсюда этот метод может быть применен для выполнения оценки систем, включающей в себя стратегии комплексного планирования.
Хотя метод Марковской цепи применяется только для систем, в которых изменения состояния описываются Марковской цепью, для имитации здесь требуется меньше времени и памяти компьютера, по сравнению с методом отслеживающего времени. Поэтому данный метод является эффективным для моделирования систем без задержки, представляющих речевую часть сетей.
41. Методы генерации случайных чисел делятся на два класса: случайные арифметические числа, генерируемые компьютером; случайные физические числа, генерируемые феноменом, таким как радиоактивные вещества и космические лучи.
Случайное арифметическое число определяется как некоторое неслучайное число в серии строгой последовательности с чрезвычайно длинным периодом повторения. Таким образом, они являются псевдослучайными числами, произвольность которых должна быть контролируема.
Случайное физическое число генерируется, например, с использованием гамма лучей, излучающих последовательность щелчков с Пуассоновским распределением интервалов времени между распадами радионуклидов. Из-за трудности генерации случайных статистически идентичных чисел, однако, это не пригодно для имитаций трафика, который требует регулярных реализаций.
Требуемые условия для генерации псевдослучайных чисел:
может быть сгенерировано достаточно много произвольных чисел;
достаточная произвольность выборки чисел, достигаемая необходимой длиной периода повторения;
статистически произвольные идентичные числа могут генерироваться многократно;
статистическая характеристика отвечает имитационным целям.
Однородным случайным числом называется произвольное число, равномерно распределенное в заданном диапазоне. Типовыми методами генерации однородных случайных чисел являются: метод среднего квадрата, мультипликативный конгруэнтный (многосвязный) метод, смешанный конгруэнтный (равный и подобный) метод и метод М-последовательности.
Метод среднего квадрата был введен фон Нейманом. Согласно методу берется произвольное n-разрядное число и обозначается x0. Квадрат числа x0 содержит 2n знаков, из которого выбираем из середины новое n-разрядное число и обозначаем его x1. Повторяя подобные операции, мы получим серию случайных чисел: x0, x1, x2, … . Например, при n = 2
x0 = 2 061, x1 = 2 477, x3 = 1 355
x02 = 04247721, x12 = 06135529.
Так как данный метод имеет сравнительно короткий повторяющийся период, то он для получения длинной серии случайных чисел не используется.
Многосвязный метод позволяет сгенерировать серию случайных чисел x0, x1, x2, … , полученных путем вычисления итерационного выражения:
xn = k xn – 1(mod M), (60)
где (mod M) – представляет собой остаток по модулю М при делении числа на М.
Известно, что максимум периода повторения 2b–2 достигается при k = 3 (mod 8), x0 = 1 (mod 2) и М = 2b.
Смешанный конгруэнтный метод позволяет сгенерировать серию случайных чисел x0, x1, x2, … , полученных путем вычисления итерационного выражения:
xn = (k xn – 1 + ) (mod M). (61)
Максимум периода повторения 2b достигается при k = 3 (mod 8), x0 = 1 (mod 2) и М = 2b.
Метод М-последовательности позволяет сгенерировать серию случайных чисел x0, x1, x2, … , полученных путем вычисления следующего выражения:
![]() (62)
(62)
где c1, c2, … , ck – 1 = 0 или 1, а ck = 1, максимум периода 2k – 1.
Выполняя двоичные преобразования десятичной последовательности l ( k) чисел, взятых из серии {xj}, составляют случайные числа с равномерным распределением в интервале (0, 1). Данный метод требует некоторого количества повторных операций для получения случайного числа, так как только одно двоичное число может быть сгенерировано на вычисление. Хотя это кажется невыгодным с точки зрения скорости, но так как операция по модулю 2 эквивалентна логической операции «исключающая ИЛИ», то генерация случайного числа может быть ускорена параллельным исполнением логической операции.
П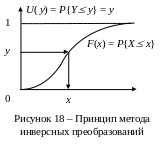 роизвольные
случайные числа часто требуются при
имитациях. К несчастью, однако, еще не
разработан универсальный метод, который
дает алгоритм, обеспечивающий программу
для заданной функции распределения. К
типовым методам генерации произвольных
случайных чисел относят метод инверсных
преобразований, метод отрицания и метод
композиции.
роизвольные
случайные числа часто требуются при
имитациях. К несчастью, однако, еще не
разработан универсальный метод, который
дает алгоритм, обеспечивающий программу
для заданной функции распределения. К
типовым методам генерации произвольных
случайных чисел относят метод инверсных
преобразований, метод отрицания и метод
композиции.
Метод инверсных преобразований использует некоторый алгоритм для генерации случайных чисел, следующих за некоторой функцией распределения F(), для которой существует инверсная функция F – 1 (). Принцип этого метода показан на рис.18.
Положив, что Y есть случайная переменная, соответствующая равномерному распределению в интервале (0, 1), мы получим
U(y) = P{Y y} = y, 0 < y < 1. (63)
Сгенерируем однородное случайное число Y методом, описанным выше, и положим
X = F – 1(Y). (64)
Тогда X соответствует функции распределения F(x). В этом удостоверяются из соотношения:
P{X x} = P{F – 1(y) x} = P{Y F(x)} = F(x). (65)
Метод отрицания применяется к распределениям, для которых функция плотности f(x) ограничена некоторым контуром. Пусть A будет областью между y = f(x) и осью x. Тогда координата x произвольного шаблона, взятого из области A, становится случайным числом, следующим за f(x).
Пусть g(x) будет функцией, которая больше чем или равна f(x), и предположим, что случайная переменная генерируется как
![]() (x)
=
C
–
1g(x),
(66)
(x)
=
C
–
1g(x),
(66)
где C
=
![]() – контурный интеграл.
– контурный интеграл.
Произвольное число, следующее за f(x), генерируется согласно алгоритму:
генерируются случайные числа X и Y, следующие за (x) и U(0, 1), соответственно;
если Y > f(X) / g(X), то возвращаемся к пункту (а); в противном случае X является искомым произвольным числом.
Имя данного метода пришло от того факта, что X отрицается до тех пор, пока точка, принадлежащая области A, пробуется. К.п.д. этого метода для генерации произвольных чисел зависит от следующих факторов:
среднего числа (C – 1) отрицаний для того, чтобы получить произвольное число;
скорости генерации произвольного числа, следующего за (x);
вычислительного процесса от f(X) / g(X).
В порядке повышения к.п.д. выбор подходящей функции g() является более важным, а также пункт (е) имеет еще значительное влияние. Если функция плотности не обрисовывается, то подходящее изображение функции плотности находят путем преобразования переменной, а затем может применяться метод отрицания для того, чтобы очертить функцию.
Метод композиции применяется к распределениям, где вероятность функции плотности f(x) выражается в форме интеграла с членами типа f(x, ) и g( ) как
f(x)
=
![]() (67)
(67)
Если мы генерируем первое произвольное число 0, следующее за g( ), а другое произвольное число x0, следующее за f(x, ), то становится ясным, что x0 следует за f(x). На практике, если g( ) дискретна, очень часто используется запись вероятности функции плотности как
![]() (68)
(68)
Если мы используем относительно большой вес rk, соответствующий функции fk(x), то следующее за ней некоторое произвольное число легко генерируется (например, равномерное распределение) и требуемое произвольное число может генерироваться продуктивно.