

23.Предсказание переходов в современных процессорах.
Модуль предсказания условных переходов (англ. Branch Prediction Unit) — устройство, входящее в состав микропроцессоров, имеющих конвейерную архитектуру, определяющее направление ветвлений (предсказывающее, будет ли выполнен условный переход) в исполняемой программе. Предсказание ветвлений позволяет осуществлять предварительную выборку инструкций и данных из памяти, а также выполнять инструкции, находящиеся после условного перехода, до того, как он будет выполнен. Предсказатель переходов является неотъемлемой частью всех современных суперскалярных микропроцессоров, так как в большинстве случаев (точность предсказания переходов в современных процессорах превышает 90 %) позволяет оптимально использовать вычислительные ресурсы процессора.
Существует два основных метода предсказания переходов: статический и динамический.
Статическое предсказание
Статические методы предсказания ветвлений являются наиболее простыми. Суть этих методов состоит в том, что различные типы переходов либо выполняются всегда, либо не выполняются никогда. В современных процессорах статические методы используются лишь в том случае, когда невозможно использование динамического предсказания.Примерами статического предсказания могут служить тривиальное предсказание переходов, применявшееся в ранних процессорах архитектуры SPARC и MIPS (предполагается, что условные переходы никогда не выполняются), а также статическое предсказание, использующееся в современных процессорах в качестве «подстраховки» (предполагается, что любой обратный переход, т.е. переход на более младшие адреса, является циклом и выполняется, а любой прямой переход, т.е. на более старшие адреса, не выполняется).
Динамическое предсказание
Динамические методы, широко используемые в современных процессорах, подразумевают анализ истории ветвлений. Примером динамического предсказания может служить двухуровневый адаптивный исторический алгоритм (англ. Bimodal branch prediction), использовавшийся процессорами архитектуры P6 (анализируется таблица истории переходов, содержащая младшие значимые биты адреса инструкции и соответствующую им вероятность условного перехода: «скорее всего, будет выполнен», «возможно, будет выполнен», «возможно, не будет выполнен», «скорее всего, не будет выполнен» и обновляемая после каждого перехода).
Механизм предсказания переходов выполняет две основные функции — предсказание программного адреса инструкции, на которую производится переход (для всех инструкций перехода), и предсказание направления ветвления (для инструкций условного перехода). Оба предсказания должны быть выполнены заблаговременно — раньше, чем начнётся декодирование и обработка инструкции перехода — для того, чтобы выборка нового блока инструкций была произведена без потерь лишних тактов либо с минимальными потерями. Необходимость предсказания адреса «целевой» инструкции вызвана тем, что этот адрес может быть извлечён из x86-инструкции перехода и вычислен только на финальной стадии декодирования, с большой задержкой. Более того, даже простое выделение инструкций переменной длины из считанного блока и поиск среди них инструкций перехода займёт какое-то время. Поэтому в процессорах архитектуры x86 предсказание производят по целому блоку, без разбиения его на составляющие инструкции. В современных процессорах для предсказания адреса перехода обычно используют специальную таблицу адресов переходов BTB (Branch Target Buffer). Эта таблица устроена подобно кэшу и содержит адреса инструкций, на которые ранее производились переходы. Например, в процессоре P-III таблица BTB имеет размер 512 элементов и организована в виде 128 наборов с ассоциативностью 4. Для адресации набора используются младшие разряды адреса 16-байтового блока инструкций (b10-4). Если в этом блоке есть инструкции перехода, и если эти инструкции отрабатывали ранее, то алгоритм предсказания может очень быстро найти адрес целевой инструкции в таблице BTB и начать считывание блока, содержащего эту инструкцию. Адреса целевых инструкций помещаются в BTB в момент отставки соответствующих инструкций перехода. В других современных процессорах размер таблицы BTB достигает 2048 элементов (K8) и 4096 элементов (P-4). Организация данной подсистемы в процессоре K8 несколько отличается от классической и основывается на предварительной разметке блоков инструкций в так называемых массивах селекторов перед помещением их в I-кэш. Эти селекторы привязаны к положению инструкций в I-кэше и при их вытеснении оттуда сохраняются в L2-кэше (в так называемых ECC-битах, предназначающихся для коррекции ошибок). Элементы таблицы BTB также привязаны к положению инструкций в I-кэше и теряются при их вытеснении. Это несколько снижает эффективность предсказания адресов переходов в процессоре K8.Для предсказания направления условного перехода используется другой механизм, основанный на изучении поведения переходов в программе в процессе её выполнения (своего рода «сбор статистики»). Этот механизм учитывает как локальное поведение конкретной инструкции перехода (например, «как правило, переходит», «как правило, не переходит»), так и глобальные закономерности («чередуется по определённому закону» и т.п.). История поведения инструкций условного перехода записывается в специальных структурах, обычно называемых «таблицами истории переходов» (Branch History Table, BHT). Современные механизмы предсказания переходов обеспечивают правильное предсказание более чем в 90 процентах случаев.
24. Основные архитектуры Многопроцессорных систем (ОКОД, ОКМД, МКОД, МКМД). Принципы управления в многопроцессорных системах.
Многопроцессорность (Мультипроцессорность, Многопроцессорная обработка, англ. Multiprocessing) — использование пары или большего количества физических процессоров в одной компьютерной системе. Термин также относится к способности системы поддержать больше чем один процессор и/или способность распределить задачи между ними. Существует много вариантов данного понятия, и определение многопроцессорности может меняться в зависимости от контекста, главным образом в зависимости от того, как определены процессоры (много ядер в одном кристалле, множество чипов в одном корпусе, множество корпусов в одном системном модуле, и т. д.).
Многопроцессорностью иногда называют выполнение множественных параллельных программных процессов в системе в противоположность выполнению одного процесса в любой момент времени. Однако термины многозадачность или мультипрограммирование являются более подходящими для описания этого понятия, которое осуществлено главным образом в программном обеспечении, тогда как многопроцессорная обработка является более соответствующей, чтобы описать использование множественных аппаратных процессоров. Система не может быть и многопроцессорной и мультипрограммированной, только одной из двух, или ни той и ни другой.
Большое разнообразие структур ВС затрудняет их изучение. Поэтому вычислительные системы классифицируют с учетом их обобщенных характеристик. С этой целью вводится понятие «архитектура системы».
Архитектура ВС — совокупность характеристик и параметров, определяющих функционально-логическую и структурную организацию системы. Понятие архитектуры охватывает общие принципы построения и функционирования, наиболее существенные для пользователей, которых больше интересуют возможности систем, а не детали их технического исполнения. Поскольку ВС появились как параллельные системы, то и рассмотрим классификацию архитектур под этой точкой зрения.
С появлением систем, ориентированных на потоки данных и использование ассоциативной обработки, данная классификация может быть некорректной.
Согласно этой классификации существует четыре основных архитектуры ВС, представленных на рис. 11.3:
• одиночный поток команд — одиночный поток данных (ОКОД), в английском варианте — Single Instruction Single Data (SISD) — одиночный поток инструкций — одиночный поток данных;
• одиночный поток команд — множественный поток данных (ОКМД), или Single Instruction Multiple Data (SIMD) — одиночный поток инструкций — одиночный поток данных;
• множественный поток команд — одиночный поток данных (МКОД), или Multiple Instruction Single Data (MISD) — множественный поток инструкций — одиночный поток данных;
• множественный поток команд — множественный поток данных (МКМД), или Multiple Instruction Multiple Data (MIMD) — множественный поток инструкций — множественный поток данных (MIMD).
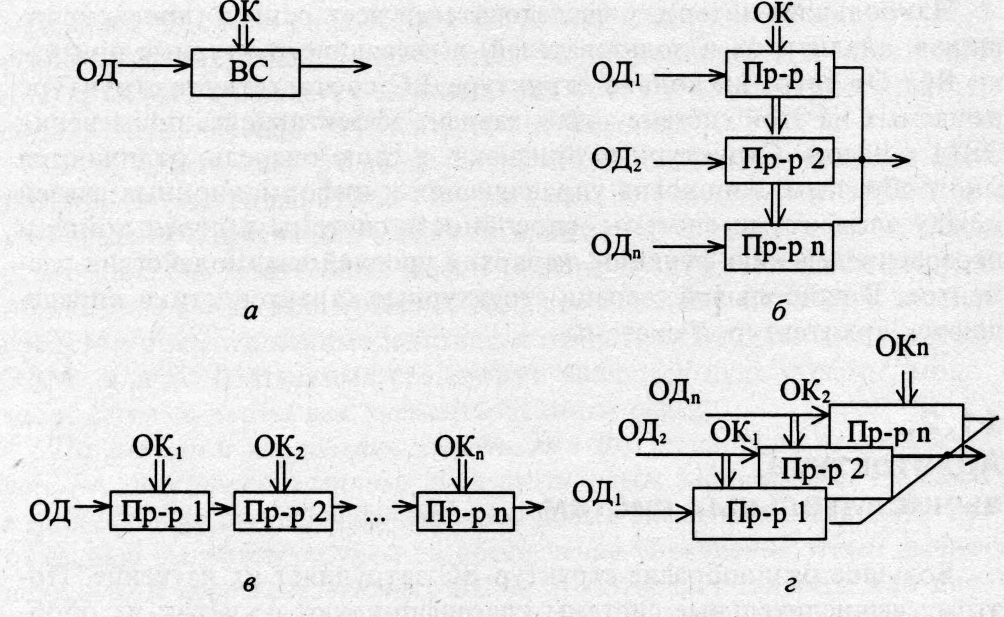
Коротко рассмотрим отличительные особенности каждой из архитектур.
Архитектура ОКОД охватывает все однопроцессорные и одномашинные варианты систем, т.е. с одним вычислителем. Все ЭВМ классической структуры попадают в этот класс. Здесь параллелизм вычислений обеспечивается путем совмещения выполнения операций отдельными блоками АЛУ, а также параллельной работы устройств ввода-вывода информации и процессора. Закономерности организации вычислительного процесса в этих структурах достаточно хорошо изучены.
Архитектура ОКМД предполагает создание структур векторной или матричной обработки. Системы этого типа обычно строятся как однородные, т.е. процессорные, элементы, входящие в систему, идентичны, и все они управляются одной и той же последовательностью команд. Однако каждый процессор обрабатывает свой поток данных. Под эту схему хорошо подходят задачи обработки матриц или векторов (массивов), задачи решения систем линейных и нелинейных, алгебраических и дифференциальных уравнений, задачи теории поля и др. В структурах данной архитектуры желательно обеспечивать соединения между процессорами, соответствующие реализуемым математическим зависимостям. Как правило, эти связи напоминают матрицу, в которой каждый процессорный элемент связан с соседними.
По этой схеме строились системы: первая суперЭВМ — ILLIAC-IV, отечественные параллельные системы — ПС-2000, ПС-3000. Идея векторной обработки широко использовалась в таких известных суперЭВМ, как Cyber-205 и Gray-I, II, III. Узким местом подобных систем является необходимость изменения коммутации между процессорами, когда связь между ними отличается от матричной. Кроме того, задачи, допускающие широкий матричный параллелизм, составляют достаточно узкий класс задач. Структуры ВС этого типа, по существу, являются структурами специализированных суперЭВМ.
Третий тип архитектуры МКОД предполагает построение своеобразного процессорного конвейера, в котором результаты обработки передаются от одного процессора к другому по цепочке. Выгоды такого вида обработки понятны. Прототипом таких вычислений может служить схема любого производственного конвейера. В современных ЭВМ по этому принципу реализована схема совмещения операций, в которой параллельно работают различные функциональные блоки, и каждый из них делает свою часть в общем цикле обработки команды.
В ВС этого типа конвейер должны образовывать группы процессоров. Однако при переходе на системный уровень очень трудно выявить подобный регулярный характер в универсальных вычислениях. Кроме того, на практике нельзя обеспечить и «большую длину» такого конвейера, при которой достигается наивысший эффект. Вместе с тем конвейерная схема нашла применение в так называемых скалярных процессорах суперЭВМ, в которых они применяются как специальные процессоры для поддержки векторной обработки.
Архитектура МКМД предполагает, что все процессоры системы работают по своим программам с собственным потоком команд. В простейшем случае они могут быть автономны и независимы. Такая схема использования ВС часто применяется на многих крупных вычислительных центрах для увеличения пропускной способности центра. Больший интерес представляет возможность согласованной работы ЭВМ (процессоров), когда каждый элемент делает часть общей задачи. Общая теоретическая база такого вида работ практически отсутствует. Но можно привести примеры большой эффективности этой модели вычислений. Подобные системы могут быть многомашинными и многопроцессорными. Например, отечественный проект машины динамической архитектуры (МДА) — ЕС-2704, ЕС-2127 — позволял одновременно использовать сотни процессоров.