

Рекомендации по созданию таблиц

Когда вы создаете таблицу, обязательно нужно указать имя таблицы, имена столбцов и их типы данных. Имена столбцов должны быть уникальны в пределах одной таблицы. Ограничения:
В БД может быть более 2 млрд объектов, в том числе таблиц.
В таблице может быть до 1024 столбца
Строка может занимать не более 8 Kb (это не относится к типам LOB и типам данных со спецификатором max)
Для каждого столбца можно указать, может ли он принимать Null-значения. Если этого не указать, то умолчание определяется опцией ANSI_NULL_DEFAULT на уровне базы данных или сессии. Если эта опция ON, то по умолчанию считается NULL. Иначе – NOT NULL. В SQL Server 2005 опция ANSI_NULL_DEFAULT равна OFF. Не следует полагаться на умолчания, а следует всегда явно указывать, может ли столбец принимать NULL-значения.
Существуют специальные типы столбцов:
Вычисляемые (computed columns). Это виртуальные столбцы, которые физически не хранятся в таблице. Их значения вычисляются по указанной формуле на основе значений других столбцов этой же таблицы. Использование вычисляемых столбцов может упростить синтаксис запроса.
Счетчики (identity columns). Можно использовать свойство Identity, чтобы создать столбец, который содержит последовательно сгенерированные значения, идентифицирующие каждую строку, вставляемую в таблицу. Свойство identity обычно используется для первичных ключей таблиц.
Столбцы с типом timestamp. В столбцы с типом данных timestamp автоматически вставляется текущая дата и время.
Столбцы с типом uniqueidentifier. Эти столбцы используются для хранения глобального уникального идентификатора с помощью функции NEWID языка Transact-SQL.
Пример создания таблицы:
CREATE TABLE Sales.CustomerOrders
(OrderID int identity NOT NULL,
OrdderDate datetime NOT NULL,
CustomerID NOT NULL,
Notes nvarchar(200) NULL)
Можно также создать таблицу с помощью Object Explorer в SQL Server Management Studio.
Изменение и удаление таблиц
Можно изменить или удалить таблицу, используя команды Transact SQL или Object Explorer в SQL Server Management Studio. Пример изменения таблицы:
ALTER TABLE Sales.CustomerOrders
ADD SalesPersonID int NOT NULL
GO
ALTER TABLE Sales.CustomerOrders
ALTER Notes nvarchar(200) NOT NULL
GO
Для удаления таблицы используется команда DROP TABLE.
Создание секционированных таблиц
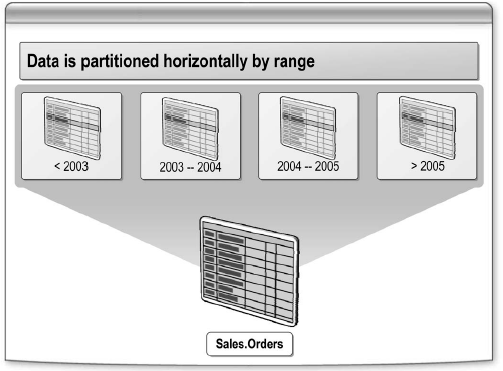
Секционированная таблица – таблица, данные которой физически разделены горизонтально на основе ранжирования значений определенного столбца. Физическое расположение для секций определено в файловых группах. Например, можно разделить информацию таблицы заказов по дате: заказы до 2003 года хранить в одной секции, с 2003 по 2004 – в другой секции, 2004-2005 – в третьей и т.д. Эта техника делает возможным управлять физическим расположением строк одной таблицы.
Преимущества в управлении:
Возможность выполнять различные стратегии резервирования. Различные наборы данных могут иметь различные требования к резервированию. Например, недавние данные о заказах могут часто обновляться и требовать регулярного резервирования., в то время как старые заказы изменяются крайне редко и требуют более редкого резервирования.
Возможность управлять хранением. Секционирование таблиц позволяет выбрать подходящее хранилище для данных. Например, исторические неизменяемые данные можно хранить в сжатых файловых группах, в то время как текущие данные – на высокопроизводительных файловых группах в RAID.
Лучшее управление индексами. Дополнительно к секционированию таблиц, можно секционировать индексы. Это позволяет реорганизовывать, оптимизировать и перестраивать индексы по секциям, что выполнится гораздо быстрее, чем для целого индекса. Кроме того, секционирование индекса может уменьшить фрагментацию. Например, старые данные о заказах меньше изменяются и соответствующие индексные страницы стабильны.
Преимущества в производительности:
Более быстрый индексный поиск. Секционирование результатов в малых индексных деревьях для каждой секции выполняется быстро, особенно когда количество строк ограничено фразой WHERE.
Быстрее выполняются операции JOIN, когда соединяются таблицы, секционированные по одному и тому же принципу.
Уменьшается количество блокировок на уровне секции, значительно уменьшая риск взаимоблокировок.