

Создание Схем (Schemas)
Объекты базы данных, такие как таблицы, индексы, представления, хранимые процедуры всегда создаются внутри некоторой схемы.
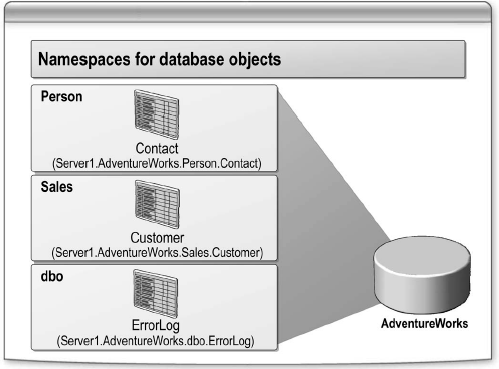
Схема – это пространство имен объектов базы данных. Внутри схемы все имена объектов уникальны. Каждый объект базы данных имеет полную спецификацию из четырех частей:
сервер.база данных.схема.объект
Внутри базы данных спецификацию можно сократить:
схема.объект
Пример.
Преимущества:
Упрощается управление правами, т.к. право может быть дано на схему, а не каждый объект БД в отдельности.
Удаление пользователя не ведет к переименованию всех объектов, которыми он владел.
В базе данных AdwentureWorks используются следующие схемы:
HumanResources
Person
Production
Purchaising
Sales
Например, к таблице Employee из схемы HumanResources можно обратиться как HumanResources.Employee.
Каждая база данных содержит схему dbo. Схема dbo является схемой по умолчанию для всех пользователей, которые не имеют своей схемы, определенной для них по умолчанию.
Чтобы создать схему, можно использовать Object Explorer в SQL Server Management Studio или оператор CREATE SCHEMA
Use AdventureWorks
GO
CREATE SCHEMA Sales
GO
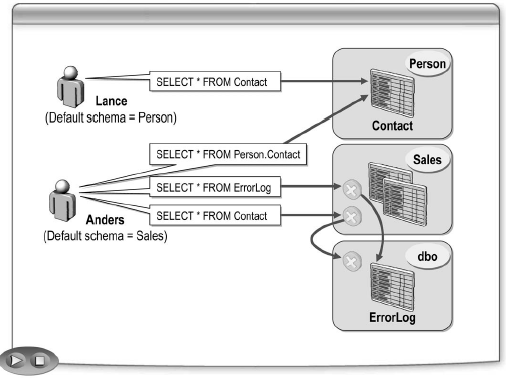
Когда БД содержит множество схем, автоматическое определение имени объекта может быть неожиданным для пользователя. Например, база данных может содержать две таблицы Order в разных схемах, например в Sales и dbo. Тогда к каждой из этих таблиц рекомендуется обращаться как Sales.Order и dbo.Order соответственно. Иначе, если обратиться только по имени, результат может быть неожиданным – запрос пользователя может быть обращен не к той таблице, к которой он ожидал обратиться. Можно назначить пользователю схему по умолчанию.
Используется следующий процесс определения неквалифицированного имени объекта:
Если пользователь имеет схему по умолчанию, SQL Server пытается найти объект в схеме по умолчанию.
Если объект не найден в схеме по умолчанию, или пользователь не имеет схемы по умолчанию, то SQL Server пытается найти объект в схеме dbo.
Например, пользователь со схемой Person выполняет следующий запрос:
SELECT * FROM Contact
Сначала таблица Contact ищется в схеме Person. Если в схеме Person нет таблицы Contact, то таблица ищется в схеме dbo.
Если пользователь без схемы по умолчанию выполняет тот же запрос, то SQL Server сразу же ищет объект dbo.Contact.
Вы можете назначить схему по умолчанию, используя диалоговое окно свойств пользователя БД или с помощью фразы DEFAULT_SCHEMA операторов CREATE USER или ALTER USER языка Transact-SQL. Например,
ALTER USER Anders WITH DEFAULT_SCHEMA = Sales
Создание Снапшотов (Snapshots)
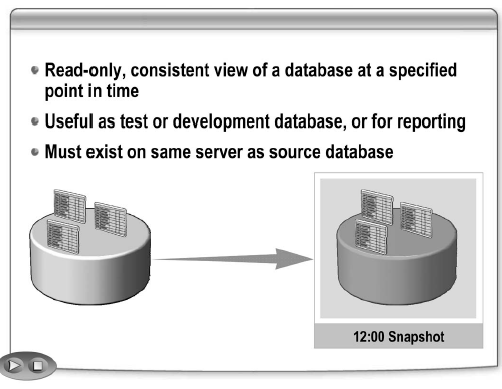
Существует множество сценариев, в которых полезна простая копия базы данных – снапшот. Например, для тестирования и разработки БД или просто для создания отчета. Вы можете использовать фразу AS SNAPSHOT OF оператора CREATE DATABASE, чтобы создать снапшот.
Снапшот БД – это предназначенное только для чтения, статическое представление БД в определенный момент времени.
Снапшот БД может быть полезен при повреждении данных в базе. Однако снапшоты не могут быть использованы для восстановления БД, так как содержат не все записи БД.
Существуют ограничения на использование снапшотов.
Снапшоты не могут быть созданы для системных баз данных model, master, tempdb.
Снапшоты не могут резервироваться или восстанавливаться.
Снапшоты не могут присоединяться или отсоединяться.
Все снапшоты БД должны быть удалены перед удалением БД
SQL Server Management Studio не поддерживает создание снапшотов, они создаются только командами Transact-SQL.
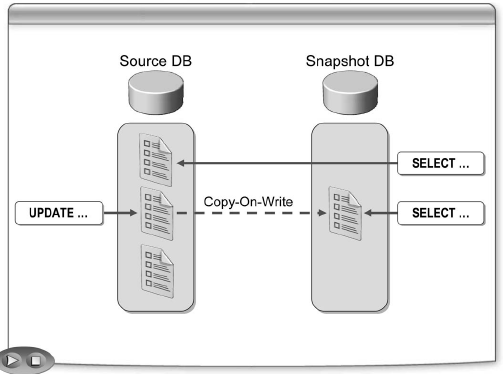
Снапшоты БД поддерживают статическое представление БД с помощью копирования данных перед их модификацией.
SQL Server использует технологию copy-on-write для выполнения снапшотов БД, при которой не требуется хранить полную копию базы данных. После создания снапшот вначале пустой. Когда страница базы данных-источника модифицируется, то исходное состояние этой страницы копируется в снапшот. Если страница никогда не изменялась, то она не хранится в снапшоте.
Копирование в снапшот выполняется на уровне страниц, даже если изменилась всего одна строка. Использование страниц вместо строк более эффективно. Страница содержит множество строк, если изменяются несколько строк одной страницы, то производится всего одна операция копирования. Такой механизм эффективен даже для часто изменяющихся баз данных.
Пользователь, обращающийся к снапшоту БД, увидит копию страницы в снапшоте, если эта страница была модифицирована после создания этого снапшота. Иначе, пользователь перенаправляется к соответствующей странице в базе-источнике. Это перенаправление выполняется автоматически и невидимо (прозрачно) для пользователя.
Пример.
Создается снапшот базы данных AdventureWorks:
CREATE DATABASE AdventureWorks_Snapshot1200 ON ( NAME = N’AdventureWorks_Data’, FILENAME= N’C:\ Program Files\Microsoft SQL Server\MSSQL.1\MSSQL\Data\AW1200.ss’) AS SNAPSHOT OF AdventureWorks
После создания снапшота обе следующие команды дадут идентичный результат:
SELECT * FROM AdventureWorks.Person.Address WHERE AddressID=1
SELECT * FROM AdventureWorks_Snapshot1200.Person.Address WHERE AddressID=1
Изменим строку:
UPDATE AdventureWorks SET Address=’1000 Napa Ct.’ WHERE AddressID=1
Если теперь выполнить предыдущие команды SELECT, то они вернут разный результат. В первом случае будет обновленная строка, а во втором – строка до обновления.