

Определение основной тенденции в рядах динамики методом аналитического выравнивания.
Основным содержанием метода аналитического выравнивания в рядах динамики является то, что общая тенденция развития рассчитывается как функция времени. Определение теоретических (расчетных) уровней производится на основе, так называемой, адекватной математической модели, которая наилучшим образом аппроксимирует (отображает) основную тенденцию развития ряда динамики. Выбор типа модели зависит от цели исследования и должен быть основан на теоретическом анализе, выявляющем характер развития явления во времени, а также на графическом изображении ряда динамики (линейной диаграмме).
После выяснения характера кривой развития необходимо определить ее параметры, что можно сделать различными методами:
решением системы уравнений по известным уровням ряда динамики;
методом средних значений (линейных отклонений), который заключается в следующем: ряд расчленяется на две, примерно, равные части и вводятся преобразования, чтобы сумма выровненных значений в каждой части совпала с суммой фактических значений, например, в случае выравнивания по прямой;
методом наименьших квадратов - это некоторый прием получения оценки детерминированной компоненты, характеризующей тренд или ряд изучаемого явления;
выравниванием ряда динамики с помощью метода конечных разностей.
Порядок проведения группировки статистических данных.
Наиболее распространенным методом обработки и анализа первичной статистической информации является группировка.
Под группировкой понимают расчленение единиц статистической совокупности на группы, однородные в каком-либо существенном отношении, и характеристику таких групп системой показателей в целях выделения типов явлений, изучения структуры и взаимосвязей. С помощью группировок решаются три задачи:
разделение всей совокупности на качественно однородные группы. Эти группировки называются типологическими (например, группировки хозяйственных объектов туризма по формам
характеристика структуры явления и структурных сдвигов. Эти группировки называются структурными (например, определение значения каждого вида туризма в балансе отрасли, изучение состава туристов по полу, возрасту и другим признакам):
изучение взаимосвязей между отдельными признаками изучаемого явления. Такие группировки называются аналитическими (например, группировка предприятий туризма по уровню производительности труда для выявления ее влияния на себестоимость продукции (работ, услуг).
Билет №15.
Индекс переменного состава.
Индексом переменного состава называют отношение двух средних уровней.
Индекс переменного состава – индекс, выражающий соотношение средних уровней изучаемого явления, относящихся в разным периодам времени. Например, индекс переменного состава себестоимости продукции:
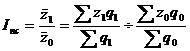
Отражает изменение не только изменение индексируемой величины (в данном случае, себестоимости), но и структуры совокупности весов (объем).
Система взаимосвязанных индексов при анализе динамики средней себестоимости имеет следующий вид:
![]()
Расчёт средней трудоемкости изготовления изделия через относительные величины.
1. Средняя трудоемкость изготовления изделия одного и того же вида несколькими рабочими (t):
n n dT
7 = £ t, • dq или t = 1 / I ,
1=1 ' 1=1 t,
где t, — трудоемкость изготовления единицы продукции конкретным рабочим;
dq — доля рабочего в общем объеме произведенной продукции;
dT — доля рабочего в общих затратах рабочего времени.
Например, 4 рабочих изготавливают одинаковую продукцию, но с различными индивидуальными затратами: t, = 0,5 ч/шт., t2 = 0,6 ч/шт., t3 = 1,2 ч/шт. и t„ = 1 ч/шт. Если каждый из них отработал ровно по 6 часов, то и доля их в общих трудозатратах будет одинакова: dT = dT = dT = dT = 0,25. Средняя трудоемкость изготовления изделия составит
/ 0,25 0,25 0,25 0,25 \
t= 1/ + + + = 0,727 ч/шт.
\ 0,5 0,6 1,2 1 j
Если же затраты времени каждого конкретного рабочего не известны, но имеются данные о вкладе каждого в общий объем продукции: d„ = 0,364; d = 0,303; d = 0,151 и d = 0,182, то
* Ч, Чг Чз Ч, 1
средняя трудоемкость рассчитывается следующим образом:
Т= 0,5 • 0.364 + 0,6 • 0,303 + 1,2 • 0,151 + 1 • 0,182 = = 0,727 ч/шт.
Заметим, что расчет средней трудоемкости по формуле средней арифметической простой: (0,5 + 0,6 + 1,2 + 1):4 = 0,825 ч/шт. — дает заведомо неверный результат. Такое решение справедливо лишь в том случае, если бы каждый рабочий изготовил по одному изделию (или равному числу изделий). Тогда и доля первого рабочего в общих трудозатратах была бы равна 0,5 : 3,3 = 0,152, второго — 0,6 : 3,3 = 0,182 и т. д.
Еще проще определяется средняя трудоемкость, когда известны общие трудозатраты и общее количество выработанной продукции. В нашем примере Т = 6 • 4 = 24 ч, а общее количество произведенной продукции составляет 33 шт., следовательно,
Т= 24 : 33 = 0,727 ч/шт.
Расчет ошибки для доли (тетрадь)
Билет №16.
Индекс себестоимости постоянного состава.
![]()
За счет изменения структуры цены средняя себестоимость увеличилась на 8%. Если бы структура реализации товара по рынкам не изменилась, средняя себестоимость возросла бы на 8%.
Применение средней хронологической.
средняя, рассчитанная из значений, изменяющихся во времени. Используется для расчета среднего уровня моментного ряда. В том случае, если имеющиеся данные относятся к фиксированным моментам времени c равными интервалами, то используется следующая формула:
Х – значение уровней ряда,
n – число имеющихся показателей.
Порядок проведения группировки статистических данных.
Наиболее распространенным методом обработки и анализа первичной статистической информации является группировка.
Под группировкой понимают расчленение единиц статистической совокупности на группы, однородные в каком-либо существенном отношении, и характеристику таких групп системой показателей в целях выделения типов явлений, изучения структуры и взаимосвязей. С помощью группировок решаются три задачи:
разделение всей совокупности на качественно однородные группы. Эти группировки называются типологическими (например, группировки хозяйственных объектов туризма по формам
характеристика структуры явления и структурных сдвигов. Эти группировки называются структурными (например, определение значения каждого вида туризма в балансе отрасли, изучение состава туристов по полу, возрасту и другим признакам):
изучение взаимосвязей между отдельными признаками изучаемого явления. Такие группировки называются аналитическими (например, группировка предприятий туризма по уровню производительности труда для выявления ее влияния на себестоимость продукции (работ, услуг).
Билет №17.
Индекс структурных сдвигов.
Индекс структурных сдвигов рассчитывается как отношение среднего уровня индексируемого показателя базисного периода, определенного на отчетную структуру, к фактической средней этого показателя в базисном периоде. Он нужен для измерения влияния только структурных изменений в исследуемый средний показатель. Индекс структурных сдвигов рассчитывается по формуле:
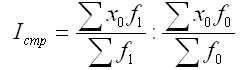
Моментные и интервальные ряды динамики.
Ряды динамики - это значения статистических показателей, которые представлены в определенной хронологической последовательности.
Динамический интервальный ряд содержит значения показателей за определенные периоды времени. В интервальном ряду уровни можно суммировать, получая объем явления за более длительный период, или так называемые накопленные итоги.
Динамический моментный ряд отражает значения показателей на определенный момент времени (дату времени). В моментных рядах исследователя может интересовать только разность явлений, отражающая изменение уровня ряда между определенными датами, поскольку сумма уровней здесь не имеет реального содержания. Накопленные итоги здесь не рассчитываются.
Расчет ошибки для средней при повторном и бесповторном отборе.
расчетные формулы средней ошибки при случайном повторном отборе будут выглядеть таким образом:
Так как в процессе бесповторной выборки сокращается численность единиц генеральной совокупности, то в представленных выше формулах расчета средних ошибок выборки нужно подкоренное выражение умножить на 1- (n/N).
Расчетные формулы для такого вида выборки будут выглядеть так: