

Модели параллельных компьютеров (классификация Флинна)
«Один поток команд — один поток данных» (SISD - "Single Instruction Single Data")
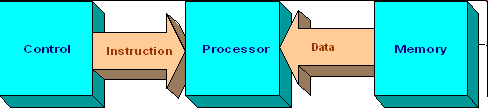
Относится к фон-Неймановской архитектуре. SISD компьютеры это обычные, "традиционные" последовательные компьютеры, в которых в каждый момент времени выполняется лишь одна операция над одним элементом данных (числовым или каким-либо другим значением). Большинство современных персональных ЭВМ попадает именно в эту категорию.
«Один поток команд — много потоков данных» (SIMD — "Single Instruction — Multiplе Data")
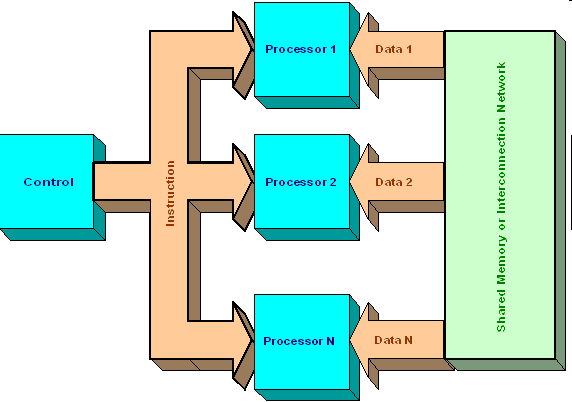
SIMD (англ. Single Instruction, Multiple Data) — принцип компьютерных вычислений, позволяющий обеспечить параллелизм на уровне данных. SIMD компьютеры состоят из одного командного процессора (управляющего модуля), называемого контроллером, и нескольких модулей обработки данных, называемых процессорными элементами. Управляющий модуль принимает, анализирует и выполняет команды.
Если в команде встречаются данные, контроллер рассылает на все процессорные элементы команду, и эта команда выполняется на нескольких или на всех процессорных элементах. Каждый процессорный элемент имеет свою собственную память для хранения данных. Одним из преимуществ данной архитектуры считается то, что в этом случае более эффективно реализована логика вычислений. SIMD процессоры называются также векторными.
«Много потоков команд — один поток данных» (MISD — "Multiple Instruction — Single Data")
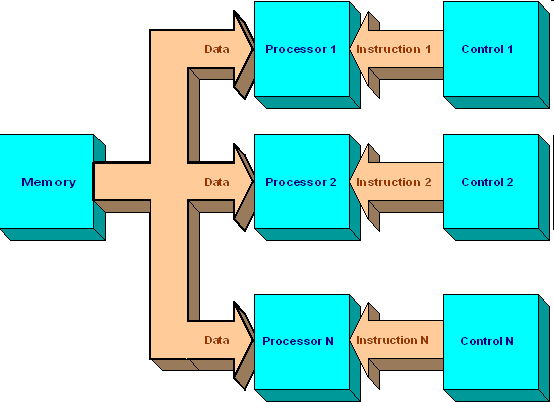
Вычислительных машин такого класса практически нет и трудно привести пример их успешной реализации. Один из немногих - систолический массив процессоров, в котором процессоры находятся в узлах регулярной решетки, роль ребер которой играют межпроцессорные соединения. Все процессорные элементы управляются общим тактовым генератором. В каждом цикле работы каждый процессорный элемент получает данные от своих соседей, выполняет одну команду и передает результат соседям.
Массивы ПЭ с непосредственными соединениями между близлежащими ПЭ называются систолическими. Такие массивы исключительно эффективны, но каждый из них ориентирован на решение весьма узкого класса задач. Рассмотрим, как можно построить систолический массив для решения некоторой задачи. Пусть, например, требуется создать устройство для вычисления матрицы D=C+AB, где
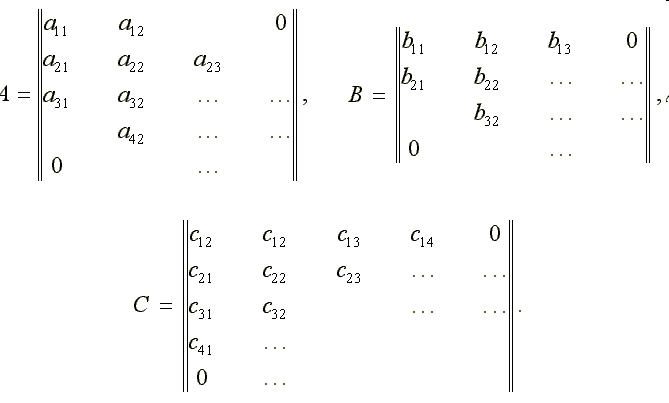
Здесь все матрицы - ленточные, порядка n. Матрица A имеет одну диагональ выше и две диагонали ниже главной; матрица B - одну диагональ ниже и две диагонали выше главной; матрица C по три диагонали выше и ниже главной. Пусть каждый ПЭ может выполнять скалярную операцию c+ab и одновременно осуществлять передачу данных. Каждый ПЭ, следовательно, должен иметь три входа: a, b, c и три выхода: a, b, c. Входные (in) и выходные (out) данные связаны соотношениями
aout = ain, bout = bin, cout = cin + ain*bin;
Если в момент выполнения операции какие-то данные не поступили, то будем считать, что они доопределяются нулями. Предположим далее, что все ПЭ расположены на плоскости и каждый из них соединен с шестью соседними . Если расположить данные, как показано на рисунке, то схема будет вычислять матрицу D.
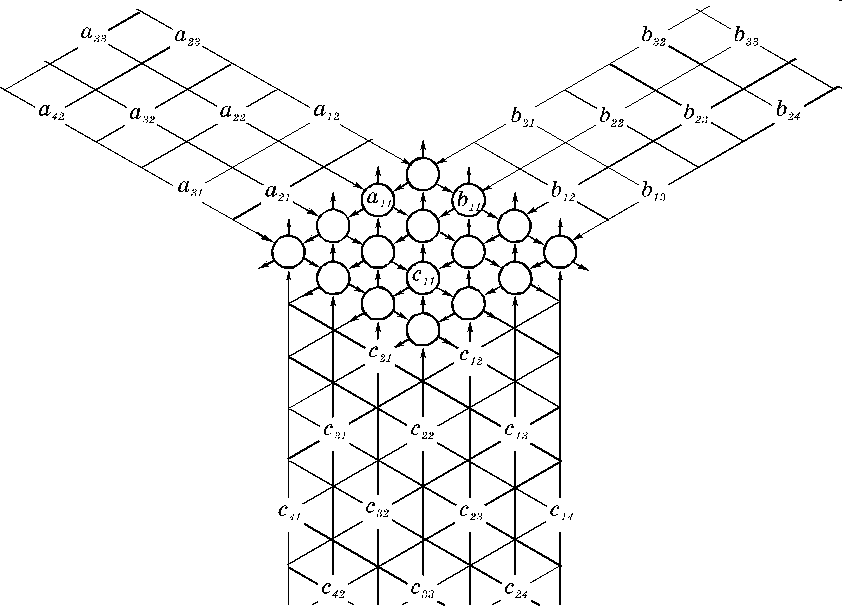
Массив работает по тактам. За каждый такт все данные перемещаются в соседние узлы по направлениям, указанным стрелками.
На рисунке показано состояние систолического массива в некоторый момент времени. В следующий такт все данные переместятся на один узел и элементы a11, b11, c11 окажутся в одном ПЭ, находящемся на пересечении штриховых линий. Следовательно, будет вычислено выражение c11+a11b11.В этот же такт данные a12 и b21 вплотную приблизятся в ПЭ, находящемся в вершине систолического массива.
В следующий такт все данные снова переместятся на один узел в направлении стрелок и в верхнем ПЭ окажутся a12 и b21 и результат предыдущего срабатывания ПЭ, находящегося снизу, т.е. c11+a11b11. Следовательно, будет вычислено выражение c11+a11b11+a12b21. Это есть элемент d11 матрицы D.
Продолжая потактное рассмотрение процесса, можно убедиться, что на выходах ПЭ, соответствующих верхней границе систолического массива, периодически через три такта выдаются элементы матрицы D, при этом на каждом выходе появляются элементы одной и той же диагонали. Примерно через 3n тактов будет закончено вычисление всей матрицы D. При этом загруженность каждой систолической ячейки асимптотически равна 1/3.
«Много потоков команд — много потоков данных» (MIMD — "Multiple Instruction — Multiple Data")
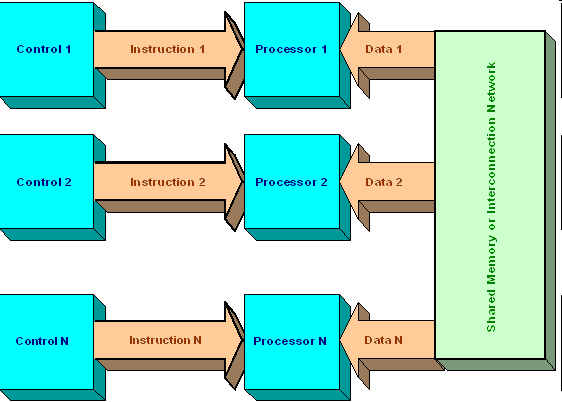
Эта категория архитектур вычислительных машин наиболее богата, если иметь в виду примеры ее успешных реализаций. В нее попадают симметричные параллельные вычислительные системы, рабочие станции с несколькими процессорами, кластеры рабочих станций и т.д.
Гигантская производительность параллельных компьютеров и супер-ЭВМ с лихвой компенсируется сложностями их использования. Начнем с самых простых вещей. У вас есть программа и доступ, скажем, к 256-процессорному компьютеру. Что вы ожидаете? Да ясно что: вы вполне законно ожидаете, что программа будет выполняться в 256 раз быстрее, чем на одном процессоре. А вот как раз этого, скорее всего, и не будет.