

Процесс проектирования цифровых устройств с использованием плис
Процесс проектирования цифровых устройств представляет собой итерационный процесс, основанный на принципах функциональной декомпозиции.
Проектирование традиционно разделяют на этапы:
системный,
структурно-алгоритмический,
функционально-логический,
конструкторско-технологический.
На системном этапе весь проект разбивается на части, определяются их назначение и взаимосвязь, принимается решение о способах реализации частей. Решение об использовании ПЛИС, принятое на системном этапе, позволяет выполнять конструкторско-технологическое проектирование модуля верхнего уровня параллельно с выполнением других этапов. Например, при проектировании контроллера шины принимается решение о реализации логики взаимодействия с шиной на основе ПЛИС. Это позволяет приступить к конструированию печатной платы сразу после определения номенклатуры ПЛИС и множеств входных и выходных сигналов.
Структурно-алгоритмический и функционально-логический этапы проектирования на ПЛИС представляют из себя итерационный процесс ввода описаний параллельно функционирующих процессов с последующей их верификацией.
Современные САПР поддерживают несколько способов описания устройства:
Описание с использованием языков описания аппаратных средств (VHDL, Verilog, AHDL и других) при помощи специализированного текстового редактора.
Схемотехнический способ с помощью программы визуального проектирования, в которой разработчик помещает на рабочую область функциональные блоки и производит их соединение. По окончании визуального проектирования схема преобразуется в языковое описание.
Графическое представление цифровых автоматов в специализированном редакторе, обеспечивающем преобразование полученного графического представление в языковое описание.
Описание комбинационной логики с помощью таблиц истинности, карт Карно, функций алгебры логики.
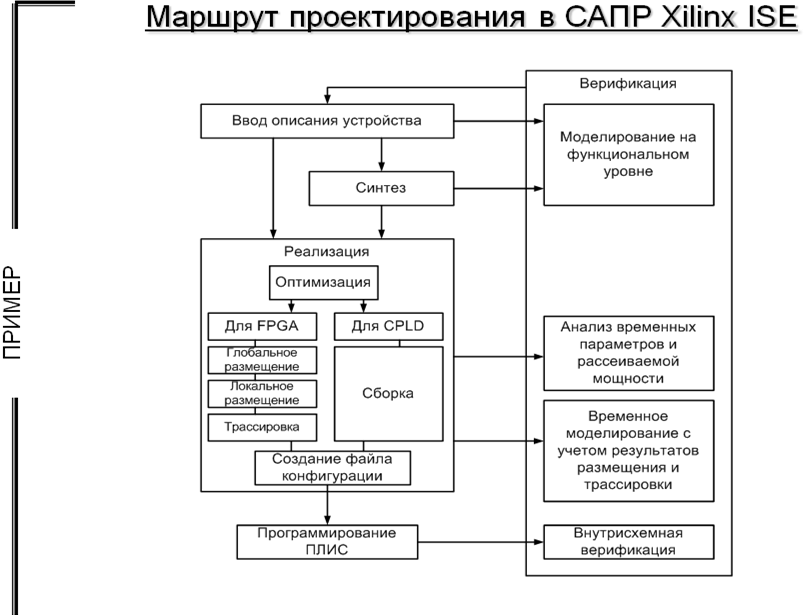
Конструкторско-технологический этап проектирования с использованием ПЛИС разделяется на связанные подзадачи:
Синтез (Synthesis).
Глобальное размещение (Mapping).
Локальное размещение (Placement).
Трассировку (Routing).
Синтез (Synthesis) – отображение схемы в базис логических ресурсов ПЛИС. Цель синтеза – преобразование исходного схемотехнического или высокоуровневого описания устройства в описание, оптимально реализуемое на выбранной ПЛИС, а также пригодное для дальнейшего размещения и трассировки. На стадии синтеза и после нее используются различные методы оптимизации описания, направленные на достижение наилучших результатов с точки зрения минимума требуемых ресурсов кристалла, максимума частоты синхросигнала, минимума потребляемой мощности. Например, на стадии синтеза принимается решение о способе кодирования состояний цифровых автоматов: кодирование One-Hot обеспечивает наибольшее быстродействие, в то время как иные способы требуют меньших ресурсов (код Грея, двоичное кодирование).
Глобальное размещение (Mapping) – назначение частям схемы макрообластей ПЛИС, представляющих из себя группы соседних логических блоков, макроячеек и блоков ввода/вывода. Цель глобального размещения: создание наилучших условий для локального размещения и трассировки. Для достижения этого используется информация о назначении сигналам внешних выводов, в большой мере влияющая на назначение свободных областей ПЛИС частям схемы. Как правило, назначение логических ресурсов кристалла макрообластям производят с избыточностью, облегчающей последующую трассировку.
Локальное размещение (Placement) – детальное назначение логических ресурсов макрообластей, выбранных на стадии глобального размещения, частям схемы. При этом преследуются цели: равномерное заполнение макрообластей элементами и трассами, минимизация суммарной длинны линий связи и другие. Основная цель локального размещения – создание наилучших условий для трассировки.
Трассировка (Routing) – определение связей между логическими блоками, макроячейками и блоками ввода-вывода в виде коммутированных участков трасс. На данной стадии преследуются цели: выбора трасс, обеспечивающих заданное время распространения сигнала; минимизации суммарного количества программируемых точек связи; минимизация времени распространения сигнала по самой длинной линии связи. Важной задачей стадии трассировки является определение временных параметров полученного варианта устройства и сравнение их с заданными ограничениями.
Процесс проектирования является итерационным. После выполнения каждой стадии производится верификация полученного описания, для чего применяются различные средства моделирования и анализа.
В современных САПР обычно предусматривается моделирования на следующих уровнях:
Моделирование поведенческого описания.
Моделирование описания на языке регистровых передач.
Моделирование технологического описания (после синтеза).
Моделирование на вентильном уровне.
Моделирование после размещения.
Моделирование после трассировки.
После выполнения трассировки и верификации результатов может быть автоматически генерирован файл c конфигурационной последовательностью, содержащий информацию о коммутации и функциональности всех ресурсов кристалла. На заключительном этапе маршрута проектирования выполняется программирование ПЛИС и последующая внутрисхемная верификация устройства (проверка работоспособности на макетной ПЛИС). При этом разработчик может использовать дополнительное оборудование (осциллографы, логические анализаторы, генераторы сигналов), или воспользоваться специализированными, встраиваемыми в ПЛИС логическими анализаторами.
Предисловие к вопросам о конвейерных суперскалярных процессорах.
Архитектура традиционных последовательных компьютеров основана на идеях Джона фон Неймана и включает в себя центральный процессор, оперативную память - адресное пространство с линейной адресацией и блок управления. Быстродействие такого традиционного компьютера определяется быстродействием его центрального процессора и временем доступа к оперативной памяти. Быстродействие центрального процессора может быть увеличено за счет увеличения тактовой частоты, величина которой зависит от плотности элементов в интегральной схеме, способа их "упаковки" и быстродействия микросхем оперативной памяти.
Другие методы повышения быстродействия последовательного компьютера основаны на расширении традиционной неймановской архитектуры, а именно:
применении RISC процессоров, то есть процессоров с сокращенным набором команд. В RISC процессорах большая часть команд выполняется за 1-2 такта;
применении суперскалярных процессоров;
применении конвейеров.
Конвейерная архитектура (pipelining) была введена в центральный процессор с целью повышения быстродействия и максимального использования всех его возможностей. Выполнение каждой команды складывается из ряда последовательных этапов (шагов, стадий), суть которых не меняется от команды к команде, например: выборка команды из ОЗУ, дешифрация команды, адресация операнда в ОЗУ, выборка операнда из ОЗУ, выполнение команды, запись результата в ОЗУ. Каждую из этих операций сопоставляют одной ступени конвейера. Количество операций называют глубиной конвейера. В каждый момент времени процессор работает над различными стадиями выполнения нескольких команд, причем на выполнение каждой стадии выделяются отдельные аппаратные ресурсы. По очередному тактовому импульсу каждая команда в конвейере продвигается на следующую стадию обработки, выполненная команда покидает конвейер, а новая поступает в него.
Конвейеры применяются как при обработке команд, так и в арифметических операциях. Для эффективной реализации конвейера должны выполняться следующие условия:
эта операция может быть разделена на независимые части;
трудоемкость подопераций примерно одинакова.
Так как в каждом такте могут выполняться различные стадии обработки команд, то длительность такта выбирается исходя из максимального времени выполнения всех стадий. Кроме того, следует учитывать, что для передачи команды с одной стадии на другую требуется определенное дополнительное время (Δt), связанное с записью промежуточных результатов обработки в буферные регистры. Конвейеризация увеличивает пропускную способность процессора (количество команд, завершающихся в единицу времени), но она не сокращает время выполнения отдельной команды.
Важным условием нормальной работы конвейера является отсутствие конфликтов, то есть данные, подаваемые в конвейер, должны быть независимыми.
В том случае, когда очередной операнд зависит от результата предыдущей операции, возникают такие периоды работы конвейера, когда он пуст. Это еще одна проблема в работе конвейерных систем.
В конвейерах команд также могут возникать простои, источником которых является зависимость между командами. Такие ситуации возникают при наличии в циклах ветвлений, то есть условных операторов.
Суперскалярный процессор представляет собой нечто большее, чем обычный последовательный (скалярный) процессор. В отличие от последнего, он может выполнять несколько операций за один такт. Основными компонентами суперскалярного процессора являются устройства для интерпретации команд, снабженные логикой, позволяющей определить, являются ли команды независимыми, и достаточное число исполняющих устройств. В исполняющих устройствах могут быть конвейеры. Суперскалярные процессоры реализуют параллелизм на уровне команд. Т.о. суперскалярная архитектура - это способность выполнения нескольких машинных инструкций за один такт процессора.
Появление этой технологии привело к существенному увеличению производительности. При этом можно использовать конвейерную обработку для совмещения этапов выполнения разных команд. Производительность при этом возрастает благодаря тому, что одновременно на различных ступенях конвейера выполняются несколько команд.
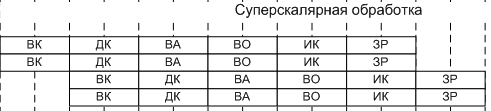
При реализации конвейерной обработки возникают ситуации, которые препятствуют выполнению очередной команды из потока команд в предназначенном для нее такте. Такие ситуации называются конфликтами. Конфликты снижают реальную производительность конвейера, которая могла бы быть достигнута в идеальном случае. Существуют три класса конфликтов:
Структурные конфликты, которые возникают из-за конфликтов по ресурсам, когда аппаратные средства не могут поддерживать все возможные комбинации команд в режиме одновременного выполнения с совмещением.
Конфликты по данным, возникающие в случае, когда выполнение одной команды зависит от результата выполнения предыдущей команды.
Конфликты по управлению, которые возникают при конвейеризации команд переходов и других команд, которые изменяют значение счетчика команд.
Конфликты в конвейере приводят к необходимости приостановки выполнения команд (pipeline stall). Обычно в простейших конвейерах, если приостанавливается какая-либо команда, то все следующие за ней команды также приостанавливаются. Команды, предшествующие приостановленной, могут продолжать выполняться, но во время приостановки не выбирается ни одна новая команда.
Структурные конфликты

Структурные конфликты возникают в том случае, когда аппаратные средства процессора не могут поддерживать все возможные комбинации команд в режиме одновременного выполнения с совмещением.
Причины структурных конфликтов.
Не полностью конвейерная структура процессора, при которой некоторые ступени отдельных команд выполняются более одного такта.
Эту ситуацию можно было бы ликвидировать двумя способами. Первый предполагает увеличение времени такта до такой величины, которая позволила бы все этапы любой команды выполнять за один такт. Однако при этом существенно снижается эффект конвейерной обработки, так как все этапы всех команд будут выполняться значительно дольше, в то время как обычно нескольких тактов требует выполнение лишь отдельных этапов очень небольшого количества команд. Второй способ предполагает использование таких аппаратных решений, которые позволили бы значительно снизить затраты времени на выполнение данного этапа (например, использовать матричные схемы умножения). Но это приведет к усложнению схемы процессора и невозможности реализации на этой БИС других, функционально более важных, узлов.
Недостаточное дублирование некоторых ресурсов.
Одним из типичных примеров служит конфликт из-за доступа к запоминающим устройствам. В случае, когда операнды и команды находятся в одном запоминающем устройстве работу конвейера придется постоянно приостанавливать, поскольку различные команды в одном и том же такте обращаются к памяти на считывание команды, выборку операнда, запись результата.
Борьба с конфликтами такого рода проводится путем увеличения количества однотипных функциональных устройств, которые могут одновременно выполнять одни и те же или схожие функции. Например, в современных микропроцессорах обычно разделяют кэш-память для хранения команд и кэш-память данных, а также используют многопортовую схему доступа к регистровой памяти, при которой к регистрам можно одновременно обращаться по одному каналу для записи, а по другому - для считывания информации. Конфликты из-за исполнительных устройств обычно сглаживаются введением в состав микропроцессора дополнительных блоков.
Недостатком суперскалярных микропроцессоров является необходимость синхронного продвижения команд в каждом из конвейеров. Следовательно, для обеспечения правильной работы суперскалярного микропроцессора при возникновении затора в одном из конвейеров должны приостанавливать свою работу и другие. В противном случае может нарушиться исходный порядок завершения команд программы. Но такие приостановки существенно снижают быстродействие процессора. Разрешение этой ситуации состоит в том, чтобы дать возможность выполняться командам в одном конвейере вне зависимости от ситуации в других конвейерах. Это приводит к неупорядоченному выполнению команд. При этом команды, стоящие в программе позже, могут завершиться ранее команд, стоящих впереди. Аппаратные средства микропроцессора должны гарантировать, что результаты выполненных команд будут записаны в приемник в том порядке, в котором команды записаны в программе. Для этого в микропроцессоре результаты этапа выполнения команды обычно сохраняются в специальном буфере восстановления последовательности команд. Запись результата очередной команды из этого буфера в приемник результата проводится лишь после того, как выполнены все предшествующие команды и записаны их результаты.